Recognition: 1 theorem link
· Lean TheoremDesign Conditions for Intra-Group Learning of Sequence-Level Rewards: Token Gradient Cancellation
Pith reviewed 2026-05-13 18:38 UTC · model grok-4.3
The pith
Intra-group objectives for sequence rewards must preserve gradient exchangeability across tokens to enable cancellation on weak-credit high-frequency tokens and block reward-irrelevant drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A necessary condition for algorithm design is that intra-group objectives must maintain gradient exchangeability across token updates; this property enables gradient cancellation on weak-credit and high-frequency tokens, which in turn prevents reward-irrelevant drift during long-term training of reasoning models under sparse rewards.
What carries the argument
Gradient exchangeability across successive token updates, which permits cancellation of gradients from weak-credit tokens inside the shared token space.
If this is right
- Training avoids accumulation of ineffective updates known as learning tax.
- Solution probability remains stable instead of drifting over long runs.
- Output entropy does not collapse, preserving exploration.
- Sample efficiency rises and final performance improves on reasoning tasks.
Where Pith is reading between the lines
- The exchangeability requirement could be checked or enforced in other sequence-level RL methods that use group comparisons.
- Focusing design effort on token-level cancellation properties may reduce reliance on auxiliary regularization for stability.
- The same transformations might be adapted to non-reasoning domains where intra-group reward signals are used.
Load-bearing premise
The observed failures of learning tax, solution probability drift, and entropy collapse arise primarily from loss of token-level gradient exchangeability rather than from reward sparsity or optimizer dynamics alone.
What would settle it
Training runs that apply the proposed exchangeability-preserving transformations yet still exhibit learning tax, drift, or collapse, or runs that retain non-exchangeable objectives yet show none of those failures.
Figures

read the original abstract
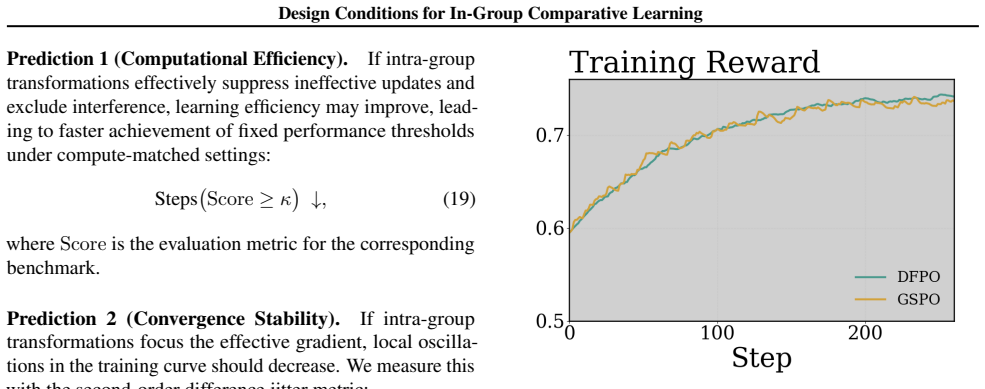
In sparse termination rewards, intra-group comparisons have become the dominant paradigm for fine-tuning reasoning models via reinforcement learning. However, long-term training often leads to issues like ineffective update accumulation (learning tax), solution probability drift, and entropy collapse. This paper presents a necessary condition for algorithm design from a token-level credit assignment perspective: to prevent reward-irrelevant drift, intra-group objectives must maintain gradient exchangeability across token updates, enabling gradient cancellation on weak-credit/high-frequency tokens. We show that two common mechanisms disrupting exchangeability make "non-cancellation" a structural norm. Based on this, we propose minimal intra-group transformations to restore or approximate the cancellation structure in the shared token space. Experimental results demonstrate that these transformations stabilize training, improve sample efficiency, and enhance final performance, validating the value of this design condition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that for intra-group RL objectives with sparse sequence-level rewards, a necessary design condition is to maintain gradient exchangeability across token updates; this enables cancellation on weak-credit/high-frequency tokens and prevents reward-irrelevant drift. It identifies two common mechanisms that structurally break exchangeability, proposes minimal transformations to restore or approximate the cancellation property, and reports that the resulting objectives stabilize training, reduce learning tax and entropy collapse, and improve sample efficiency and final performance on reasoning tasks.
Significance. If the token-level derivation is sound and the experiments isolate the exchangeability mechanism, the work supplies a concrete, falsifiable design principle that could guide more stable intra-group RL algorithms for long-horizon reasoning models, directly addressing observed failure modes without introducing new hyperparameters.
major comments (2)
- [Abstract and §2] Abstract and §2: the necessity of gradient exchangeability is asserted from a token-level credit-assignment argument, yet the manuscript supplies neither the explicit derivation steps nor the quantitative identification of the two disrupting mechanisms, leaving the central claim without verifiable support.
- [Experimental section] Experimental section: the reported gains in stability and efficiency are presented without ablation isolating the restoration of cancellation from other factors such as reward sparsity or optimizer choice, so it is unclear whether the transformations address the claimed root cause.
minor comments (2)
- [§2] Notation for 'gradient exchangeability' should be defined formally at first use rather than left implicit.
- [Abstract] The abstract's phrasing 'minimal intra-group transformations' would benefit from a one-sentence preview of what those transformations are.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the original submission would benefit from greater explicitness in the derivation and from targeted ablations. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and §2] Abstract and §2: the necessity of gradient exchangeability is asserted from a token-level credit-assignment argument, yet the manuscript supplies neither the explicit derivation steps nor the quantitative identification of the two disrupting mechanisms, leaving the central claim without verifiable support.
Authors: We accept this criticism. The original manuscript presented the necessity claim at a high level without spelling out the intermediate algebraic steps from the token-level credit-assignment objective to the exchangeability condition. In the revision we will insert a self-contained derivation in §2 that begins from the intra-group objective, applies the chain rule to individual token gradients, and arrives at the requirement that gradients remain exchangeable across tokens for cancellation to occur on weak-credit tokens. We will also add a short quantitative subsection that measures the magnitude of the two identified disrupting mechanisms (non-shared token embeddings and position-dependent masking) by reporting the resulting gradient-norm imbalance on controlled synthetic sequences. revision: yes
-
Referee: [Experimental section] Experimental section: the reported gains in stability and efficiency are presented without ablation isolating the restoration of cancellation from other factors such as reward sparsity or optimizer choice, so it is unclear whether the transformations address the claimed root cause.
Authors: We agree that the current experiments do not isolate the exchangeability-restoration mechanism from confounding factors. In the revised manuscript we will add a controlled ablation that (i) fixes reward sparsity level and optimizer hyperparameters across all variants, (ii) compares the proposed transformations against otherwise identical objectives that deliberately retain one or both disrupting mechanisms, and (iii) reports the differential effect on training stability, entropy collapse, and sample efficiency. This will directly test whether the observed improvements are attributable to the restoration of cancellation. revision: yes
Circularity Check
Derivation is self-contained from token-level credit assignment
full rationale
The paper derives its necessary condition directly from a token-level credit assignment perspective, showing that intra-group objectives must preserve gradient exchangeability to enable cancellation on weak-credit tokens. It identifies two common disrupting mechanisms and proposes minimal transformations based on that logic. No step reduces by construction to a fitted parameter, self-citation chain, or renamed input; the central claim is presented as a logical necessity from the stated view, with experiments serving as validation rather than definition. The derivation remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token-level credit assignment is the appropriate lens for analyzing sequence-level reward learning.
Reference graph
Works this paper leans on
-
[1]
Matharena: Evaluating llms on uncontaminated math competitions, February 2025
Balunovi \'c , M., Dekoninck, J., Petrov, I., Jovanovi \'c , N., and Vechev, M. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/
work page 2025
-
[2]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
2025 AIME I and AIME II Problems and Solutions , 2025
Mathematical Association of America . 2025 AIME I and AIME II Problems and Solutions , 2025. URL https://artofproblemsolving.com/wiki/index.php/2025_AIME_I_Problems. Accessed: Jan 6, 2026
work page 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025 a
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
SSPO: Subsentence-level Policy Optimization
Yang, K., Wang, Y., Li, Z., et al. Sspo: Subsentence-level policy optimization. arXiv preprint arXiv:2511.04256, 2025 b
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
Yang, S., Dou, C., Guo, P., Lu, K., Ju, Q., Deng, F., and Xin, R. Dcpo: Dynamic clipping policy optimization. arXiv preprint arXiv:2509.02333, 2025 c
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y., Zuo, X., Yue, Y., Fan, T., Liu, G., Liu, L., Liu, X., et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Group Sequence Policy Optimization
Zheng, C., Liu, S., Li, M., Chen, X.-H., Yu, B., Gao, C., Dang, K., Liu, Y., Men, R., Yang, A., et al. Group sequence policy optimization. arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.