Recognition: unknown
Exploration and Exploitation Errors Are Measurable for Language Model Agents
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
A policy-agnostic metric quantifies exploration and exploitation errors in language model agents from observed actions alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that exploration and exploitation errors are measurable for LM agents by designing adjustable grid-and-DAG environments and a metric that extracts the two error types directly from action sequences without any access to the agent's internal policy or additional ground truth.
What carries the argument
The policy-agnostic metric that scores exploration and exploitation errors from the agent's observed actions inside programmatically adjustable grid maps paired with unknown task DAGs.
If this is right
- Frontier LM agents exhibit distinct failure modes when forced to balance exploration and exploitation.
- Reasoning models achieve higher success rates on the designed tasks than non-reasoning models.
- Minimal harness engineering can produce large gains in both exploration and exploitation performance.
- The environments can be tuned to make either exploration or exploitation the dominant difficulty.
Where Pith is reading between the lines
- The metric offers a practical way to diagnose why a deployed agent is failing in real tasks without inspecting its weights or prompts.
- Similar action-only error measures could be adapted to non-LM agents such as reinforcement-learning policies or robotic controllers.
- The observed gains from harness engineering suggest that interface design may be as important as model scale for reliable agent behavior.
Load-bearing premise
The metric can correctly separate exploration mistakes from exploitation mistakes using nothing but the sequence of actions the agent produces in these grid-and-DAG setups.
What would settle it
Run an agent that systematically visits every new grid cell before returning versus one that repeatedly revisits the same cells; check whether the metric assigns markedly higher exploration error to the second agent and higher exploitation error to the first, even when both reach the same final task outcome.
Figures



















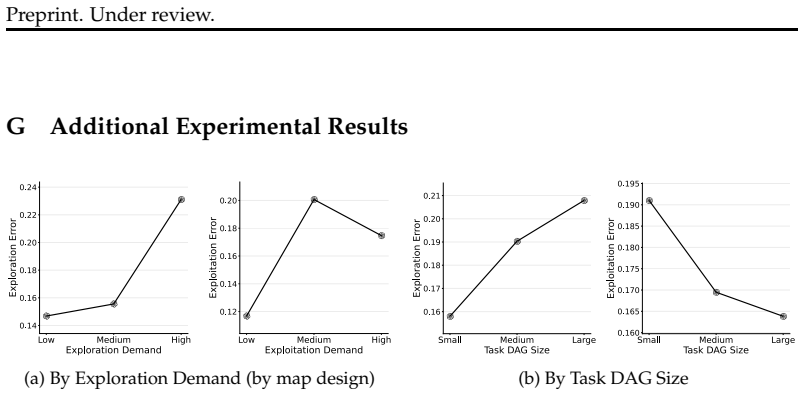
read the original abstract
Language Model (LM) agents are increasingly used in complex open-ended decision-making tasks, from AI coding to physical AI. A core requirement in these settings is the ability to both explore the problem space and exploit acquired knowledge effectively. However, systematically distinguishing and quantifying exploration and exploitation from observed actions without access to the agent's internal policy remains challenging. To address this, we design controllable environments inspired by practical embodied AI scenarios. Each environment consists of a partially observable 2D grid map and an unknown task Directed Acyclic Graph (DAG). The map generation can be programmatically adjusted to emphasize exploration or exploitation difficulty. To enable policy-agnostic evaluation, we design a metric to quantify exploration and exploitation errors from agent's actions. We evaluate a variety of frontier LM agents and find that even state-of-the-art models struggle on our task, with different models exhibiting distinct failure modes. We further observe that reasoning models solve the task more effectively and show both exploration and exploitation can be significantly improved through minimal harness engineering. We release our code \href{https://github.com/jjj-madison/measurable-explore-exploit}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce controllable, partially observable environments consisting of 2D grid maps and unknown task DAGs that can be programmatically tuned for exploration or exploitation difficulty. It proposes a policy-agnostic metric that attributes exploration and exploitation errors directly from an agent's observed actions (without access to its internal policy), evaluates a range of frontier LM agents on these environments, and reports that even state-of-the-art models exhibit distinct failure modes, that reasoning models perform better, and that both error types can be reduced via minimal harness engineering.
Significance. If the metric can be shown to cleanly separate the two error types using only observable trajectories, the work supplies a reproducible benchmark and diagnostic tool for LM-agent decision making in open-ended settings. The code release and programmatic environment generation are concrete strengths that would allow targeted follow-up experiments.
major comments (2)
- [§3] §3 (Environment and metric definition): The central claim that the metric is policy-agnostic and isolates exploration errors (failure to visit relevant states) from exploitation errors (failure to use known information) using only observed actions is load-bearing. In the partially observable grid+DAG setting, an action that appears non-exploratory can be a rational response to the agent's current belief over the hidden DAG; the metric must therefore embed an implicit model of what the agent 'should have known.' If that model is derived from the evaluator's full ground-truth map rather than the agent's observable history alone, the reported error rates become sensitive to the precise observability assumptions chosen in the environment definition.
- [§5] §5 (Evaluation): The reported finding that frontier models 'struggle' and exhibit 'distinct failure modes' is presented without quantitative validation details (error bars, statistical significance, baseline comparisons against non-LM agents or random policies, or explicit controls for prompt/harness variation). These omissions make it impossible to assess whether the observed differences are robust or confounded by implementation choices.
minor comments (2)
- [§4] The abstract and §4 refer to 'minimal harness engineering' that improves both exploration and exploitation; the exact modifications (prompt changes, tool-use wrappers, etc.) should be listed explicitly with before/after numbers.
- Notation for the metric (e.g., how an action is labeled 'exploration error' vs. 'exploitation error') should be formalized with a short pseudocode or equation block to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: §3 (Environment and metric definition): The central claim that the metric is policy-agnostic and isolates exploration errors (failure to visit relevant states) from exploitation errors (failure to use known information) using only observed actions is load-bearing. In the partially observable grid+DAG setting, an action that appears non-exploratory can be a rational response to the agent's current belief over the hidden DAG; the metric must therefore embed an implicit model of what the agent 'should have known.' If that model is derived from the evaluator's full ground-truth map rather than the agent's observable history alone, the reported error rates become sensitive to the precise observability assumptions chosen in the environment definition.
Authors: We thank the referee for this important clarification on POMDP challenges. Our metric is computed solely from the agent's observed action sequence and the revealed portions of the DAG (i.e., states and edges encountered during the trajectory). The evaluator uses ground truth only for post-hoc labeling: exploration error counts unvisited prerequisite states required for task completion, while exploitation error counts unused known edges after their observation. No internal policy or belief state is accessed. We have revised §3 to include a formal definition of the metric and added a limitations discussion noting that, without explicit belief modeling, some rational actions may be labeled as errors. This provides a consistent, policy-agnostic diagnostic while remaining reproducible. revision: partial
-
Referee: §5 (Evaluation): The reported finding that frontier models 'struggle' and exhibit 'distinct failure modes' is presented without quantitative validation details (error bars, statistical significance, baseline comparisons against non-LM agents or random policies, or explicit controls for prompt/harness variation). These omissions make it impossible to assess whether the observed differences are robust or confounded by implementation choices.
Authors: We agree that the original evaluation section lacked these details. In the revised manuscript we have added: error bars as standard deviation across 10 runs per condition; paired t-tests with p-values for model comparisons; baselines consisting of random agents, greedy exploitation heuristics, and BFS-based explorers; and ablation studies varying prompt phrasing and harness components (e.g., presence/absence of chain-of-thought). These results appear in §5 and Appendix C, enabling readers to evaluate robustness directly. revision: yes
Circularity Check
No circularity: empirical metric and evaluation are self-contained
full rationale
The paper introduces new controllable environments (partially observable grid + unknown DAG) and defines a policy-agnostic metric directly from observed agent actions to quantify exploration vs. exploitation errors. No equations, derivations, or predictions are presented that reduce by construction to fitted inputs, self-definitions, or self-citation chains. Evaluation of frontier LM agents is purely observational, with results reported as empirical findings rather than forced outputs. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The partially observable 2D grid maps and unknown task DAGs are suitable proxies for practical embodied AI decision-making scenarios.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Calibrate-then-act: Cost-aware exploration in llm agents
Wenxuan Ding, Nicholas Tomlin, and Greg Durrett. Calibrate-Then-Act: Cost-aware explo- ration in LLM agents.arXiv preprint arXiv:2602.16699,
-
[3]
Konstantin Gubernatorov, Artem Voronov, Roman Voronov, Sergei Pasynkov, Stepan Per- minov, Ziang Guo, and Dzmitry Tsetserukou. Anywherevla: Language-conditioned exploration and mobile manipulation.arXiv preprint arXiv:2509.21006,
-
[4]
Should you use your large language model to explore or exploit?arXiv preprint arXiv:2502.00225,
Keegan Harris and Aleksandrs Slivkins. Should you use your large language model to explore or exploit?arXiv preprint arXiv:2502.00225,
-
[5]
Meta-Harness: End-to-End Optimization of Model Harnesses
Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. Meta-Harness: End-to-end optimization of model harnesses.arXiv preprint arXiv:2603.28052,
work page internal anchor Pith review arXiv
-
[6]
Lucas Lehnert, Sainbayar Sukhbaatar, DiJia Su, Qinqing Zheng, Paul Mcvay, Michael Rabbat, and Yuandong Tian. Beyond A*: Better planning with transformers via search dynamics bootstrapping.arXiv preprint arXiv:2402.14083,
-
[7]
Autoflow: Automated workflow generation for large language model agents
Zelong Li, Shuyuan Xu, Kai Mei, Wenyue Hua, Balaji Rama, Om Raheja, Hao Wang, He Zhu, and Yongfeng Zhang. AutoFlow: Automated workflow generation for large language model agents.arXiv preprint arXiv:2407.12821,
-
[8]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminal-Bench: Benchmarking agents on hard, realistic tasks in command kine interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review arXiv
-
[9]
Expanding LLM agent boundaries with strategy-guided exploration.arXiv preprint arXiv:2603.02045,
Andrew Szot, Michael Kirchhof, Omar Attia, and Alexander Toshev. Expanding LLM agent boundaries with strategy-guided exploration.arXiv preprint arXiv:2603.02045,
-
[10]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Under review
13 Preprint. Under review. Appendices Here, we provide additional details that were left out due to limited space. A Additional Related Work Exploration and Exploitation.The exploration–exploitation tradeoff has been extensively studied in reinforcement learning (RL) (Thompson, 1933; Auer et al., 2002; Bellemare et al., 2016; Pathak et al., 2017), and has...
1933
-
[12]
action":
Available directions: up, down, right System Prompt (Base) You are controlling an agent in a partially observed symbolic grid environment. Your objective is to activate the goal state. At each step, you are given your current position, the directions you can legally move, and any newly discovered symbolic states at your current cell. Newly discovered stat...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.