Recognition: unknown
Utilizing Inpainting for Keypoint Detection for Vision-Based Control of Robotic Manipulators
Pith reviewed 2026-05-10 14:31 UTC · model grok-4.3
The pith
Inpainting creates labeled natural images for training keypoint detectors that enable markerless vision-based robot control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
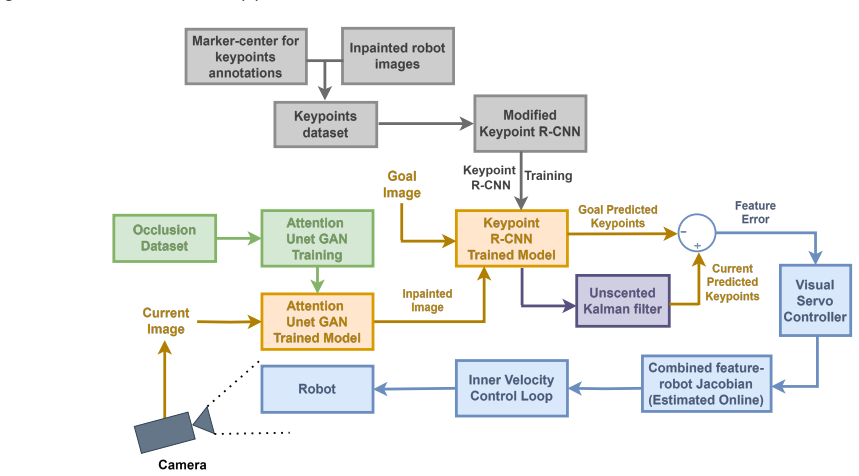
By attaching ArUco markers for automatic labeling and then inpainting to remove them, the method generates training data for a keypoint detector that works on unmarked robot images. At runtime, a second inpainting model handles occlusions in real time, combined with UKF filtering, to achieve robust visual servoing without camera calibration or robot models.
What carries the argument
Dual inpainting pipeline: one for generating markerless labeled training data by removing temporary markers, and another for real-time occlusion removal to sustain keypoint detection.
Load-bearing premise
The inpainting accurately removes markers without distorting the underlying keypoint locations in training images and enables continuous accurate detection under occlusion at runtime.
What would settle it
Demonstration that keypoint predictions deviate substantially from true positions in inpainted images, or that control performance degrades under occlusion despite the runtime inpainter and filter.
Figures























read the original abstract
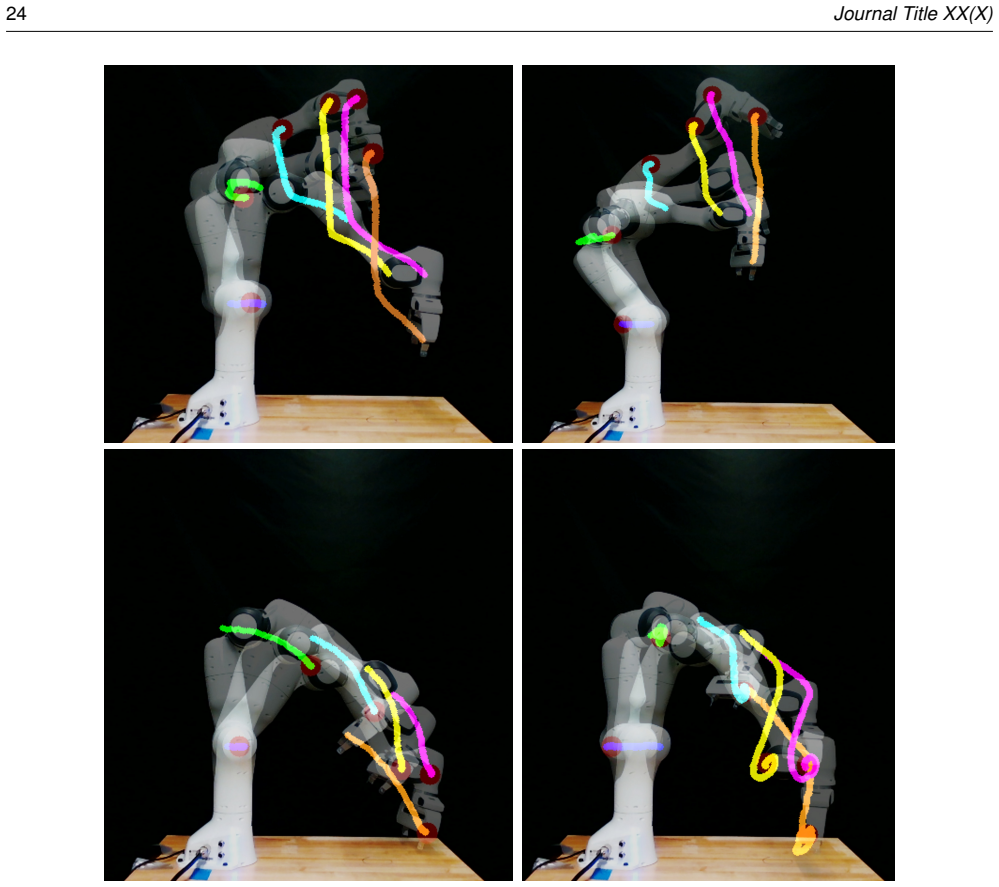
In this paper we present a novel visual servoing framework to control a robotic manipulator in the configuration space by using purely natural visual features. Our goal is to develop methods that can robustly detect and track natural features or keypoints on robotic manipulators that would be used for vision-based control, especially for scenarios where placing external markers on the robot is not feasible or preferred at runtime. For the model training process of our data driven approach, we create a data collection pipeline where we attach ArUco markers along the robot's body, label their centers as keypoints, and then utilize an inpainting method to remove the markers and reconstruct the occluded regions. By doing so, we generate natural (markerless) robot images that are automatically labeled with the marker locations. These images are used to train a keypoint detection algorithm, which is used to control the robot configuration using natural features of the robot. Unlike the prior methods that rely on accurate camera calibration and robot models for labeling training images, our approach eliminates these dependencies through inpainting. To achieve robust keypoint detection even in the presence of occlusion, we introduce a second inpainting model, this time to utilize during runtime, that reconstructs occluded regions of the robot in real time, enabling continuous keypoint detection. To further enhance the consistency and robustness of keypoint predictions, we integrate an Unscented Kalman Filter (UKF) that refines the keypoint estimates over time, adding to stable and reliable control performance. We obtained successful control results with this model-free and purely vision-based control strategy, utilizing natural robot features in the runtime, both under full visibility and partial occlusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a visual servoing framework for controlling robotic manipulators in configuration space using purely natural visual features. It generates training data by attaching ArUco markers, labeling their centers as keypoints, and applying inpainting to remove the markers and produce automatically labeled markerless images. A keypoint detector is trained on these images; at runtime, a second inpainting model reconstructs occluded regions, and an Unscented Kalman Filter (UKF) refines the estimates to enable stable model-free control under both full visibility and partial occlusion.
Significance. If the inpainting steps preserve keypoint geometry without systematic bias and the reported control performance is quantitatively validated, the method would provide a practical route to markerless, calibration-free vision-based control that relies only on natural robot appearance. The combination of runtime inpainting for occlusion handling with temporal filtering via UKF addresses a common robustness gap in visual servoing and could reduce reliance on external markers or kinematic models.
major comments (2)
- [Abstract] Abstract: The claim of obtaining 'successful control results' with the model-free strategy is stated without any quantitative metrics (e.g., end-effector tracking error, success rate over trials, or comparison to baselines), which is load-bearing for evaluating whether the framework actually achieves robust performance under full visibility and partial occlusion.
- [Abstract] Abstract (training pipeline description): The automatic labeling procedure assumes that inpainting removes ArUco markers without shifting the true keypoint locations or introducing artifacts that the detector will exploit. No validation is reported, such as mean pixel displacement between original marker centers and post-inpainting detections on held-out frames or reprojection error statistics, which directly undermines the validity of the training labels and the model-free claim.
minor comments (1)
- [Abstract] The abstract would benefit from briefly naming the keypoint detection architecture and the specific inpainting models employed, as these details are central to reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We appreciate the emphasis on strengthening the abstract and validating key assumptions in the training pipeline. Below we respond point by point to the major comments and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of obtaining 'successful control results' with the model-free strategy is stated without any quantitative metrics (e.g., end-effector tracking error, success rate over trials, or comparison to baselines), which is load-bearing for evaluating whether the framework actually achieves robust performance under full visibility and partial occlusion.
Authors: We agree that the abstract would be strengthened by including quantitative metrics. The manuscript body reports experimental results on tracking error and robustness, but these are not summarized numerically in the abstract. In the revised version we will add concise quantitative indicators (e.g., mean end-effector tracking error and trial success rates under both full visibility and partial occlusion) to the abstract while retaining the overall length limit. revision: yes
-
Referee: [Abstract] Abstract (training pipeline description): The automatic labeling procedure assumes that inpainting removes ArUco markers without shifting the true keypoint locations or introducing artifacts that the detector will exploit. No validation is reported, such as mean pixel displacement between original marker centers and post-inpainting detections on held-out frames or reprojection error statistics, which directly undermines the validity of the training labels and the model-free claim.
Authors: We acknowledge that the original submission did not include explicit quantitative validation of keypoint preservation after inpainting. While the training pipeline uses the original marker centers as ground truth before inpainting, we did not report displacement or artifact statistics. In the revision we will add a short validation analysis (mean pixel displacement on held-out frames and qualitative artifact checks) to the methods or results section and reference it briefly in the abstract to support the label quality. revision: yes
Circularity Check
No significant circularity; pipeline relies on external assumptions rather than self-referential reduction
full rationale
The paper's core pipeline attaches ArUco markers, records centers as labels, applies inpainting to create markerless training images, trains a detector, and deploys with runtime inpainting plus UKF. No equations or derivations are shown that equate a 'prediction' to a fitted input by construction, nor are self-citations used to import uniqueness theorems or ansatzes. The claim of eliminating calibration dependencies rests on the empirical performance of inpainting (an external technique), not on any definitional loop within the paper's own steps. This is a standard data-generation assumption whose validity is independent of the reported control results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inpainting can accurately reconstruct robot appearance without markers while preserving keypoint positions for training and runtime use
Reference graph
Works this paper leans on
-
[1]
Patch-based image inpainting via two-stage low rank approximation
Guo Q, Gao S, Zhang X, Yin Y and Zhang C. Patch-based image inpainting via two-stage low rank approximation. IEEE Trans on Visualization and Computer Graphics 2017; 24(6): 2023--2036
2017
-
[2]
Image inpainting
Bertalmio M, Sapiro G, Caselles V and Ballester C. Image inpainting. In Proc. ACM SIGGRAPH Conf. on Computer Graphics. pp. 417--424
-
[3]
Region filling and object removal by exemplar-based image inpainting
Criminisi A, Perez P and Toyama K. Region filling and object removal by exemplar-based image inpainting. IEEE Trans on Image Processing 2004; 13(9): 1200--1212. doi:10.1109/TIP.2004.833105
-
[4]
Texture synthesis by non-parametric sampling
Efros A and Leung T. Texture synthesis by non-parametric sampling. In Proc. IEEE Intl. Conf. on Computer Vision , volume 2. pp. 1033--1038 vol.2. doi:10.1109/ICCV.1999.790383
-
[5]
Facial image inpainting with variational autoencoder
Tu CT and Chen YF. Facial image inpainting with variational autoencoder. In 2019 2nd international conference of intelligent robotic and control engineering (IRCE). IEEE, pp. 119--122
2019
-
[6]
Image inpainting using autoencoder and guided selection of predicted pixels
Givkashi MH, Hadipour M, PariZanganeh A, Nabizadeh Z, Karimi N and Samavi S. Image inpainting using autoencoder and guided selection of predicted pixels. In 2022 30th International Conference on Electrical Engineering (ICEE). IEEE, pp. 700--704
2022
-
[7]
Deep learning-based image and video inpainting: A survey
Quan W, Chen J, Liu Y, Yan DM and Wonka P. Deep learning-based image and video inpainting: A survey. Intl J of Computer Vision 2024; 132(7): 2367--2400
2024
-
[8]
Deep learning for image inpainting: A survey
Xiang H, Zou Q, Nawaz MA, Huang X, Zhang F and Yu H. Deep learning for image inpainting: A survey. Pattern Recognition 2023; 134: 109046
2023
-
[9]
Context encoders: Feature learning by inpainting
Pathak D, Krähenbühl P, Donahue J, Darrell T and Efros AA. Context encoders: Feature learning by inpainting. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 2536--2544. doi:10.1109/CVPR.2016.278
-
[10]
Free-form image inpainting with gated convolution
Yu J, Lin Z, Yang J, Shen X, Lu X and Huang T. Free-form image inpainting with gated convolution. In IEEE/CVF Intl. Conf. on Computer Vision . pp. 4470--4479. doi:10.1109/ICCV.2019.00457
-
[11]
Suvorov R, Logacheva E, Mashikhin A, Remizova A, Ashukha A, Silvestrov A, Kong N, Goka H, Park K and Lempitsky V. Resolution-robust large mask inpainting with fourier convolutions. In IEEE/CVF Winter Conf. on Appl. of Computer Vision . pp. 3172--3182. doi:10.1109/WACV51458.2022.00323
-
[12]
Occlusion aware unsupervised learning of optical flow
Wang Y, Yang Y, Yang Z, Zhao L, Wang P and Xu W. Occlusion aware unsupervised learning of optical flow. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 4884--4893
-
[13]
Mask r-cnn
He K, Gkioxari G, Doll \'a r P and Girshick R. Mask r-cnn. In IEEE/CVF Intl. Conf. on Computer Vision . pp. 2961--2969
-
[14]
Rgi: robust gan-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection
Mou S, Gu X, Cao M, Bai H, Huang P, Shan J and Shi J. Rgi: robust gan-inversion for mask-free image inpainting and unsupervised pixel-wise anomaly detection. In Intl. Conf. on Learning Rep
-
[15]
Vcnet: A robust approach to blind image inpainting
Wang Y, Chen YC, Tao X and Jia J. Vcnet: A robust approach to blind image inpainting. In Proc. of the European Conf. on Computer Vision. Springer, pp. 752--768
-
[16]
Inpaint anything: Segment anything meets image inpainting
Yu T, Feng R, Feng R, Liu J, Jin X, Zeng W and Chen Z. Inpaint anything: Segment anything meets image inpainting. arXiv preprint 2023
2023
-
[17]
Empty cities: Image inpainting for a dynamic-object-invariant space
Bescos B, Neira J, Siegwart R and Cadena C. Empty cities: Image inpainting for a dynamic-object-invariant space. In IEEE Intl. Conf. Robot. Autom. IEEE, pp. 5460--5466
-
[18]
Patch-based image inpainting with generative adversarial networks
Demir U and Unal G. Patch-based image inpainting with generative adversarial networks. arXiv preprint 2018
2018
-
[19]
Wasserstein generative adversarial networks
Arjovsky M, Chintala S and Bottou L. Wasserstein generative adversarial networks. In Intl. Conf. on Machine Learning. PMLR, pp. 214--223
-
[20]
Improved training of wasserstein gans
Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V and Courville AC. Improved training of wasserstein gans. Advances in Neural Information Processing Systems 2017; 30
2017
-
[21]
Image inpainting via context discriminator and u-net
Wei R and Wu Y. Image inpainting via context discriminator and u-net. Math Probs in Engg 2022; 2022(1): 7328045
2022
-
[22]
Globally and locally consistent image completion
Iizuka S, Simo-Serra E and Ishikawa H. Globally and locally consistent image completion. ACM Transactions on Graphics (ToG) 2017; 36(4): 1--14
2017
-
[23]
Image inpainting for irregular holes using partial convolutions
Liu G, Reda FA, Shih KJ, Wang TC, Tao A and Catanzaro B. Image inpainting for irregular holes using partial convolutions. In Proc. of the European Conf. on Computer Vision. pp. 85--100
-
[24]
Repaint: Inpainting using denoising diffusion probabilistic models
Lugmayr A, Danelljan M, Romero A, Yu F, Timofte R and Van Gool L. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11461--11471
-
[25]
A superior image inpainting scheme using transformer-based self-supervised attention gan model
Zhou M, Liu X, Yi T, Bai Z and Zhang P. A superior image inpainting scheme using transformer-based self-supervised attention gan model. Expert Syst with Appl 2023; 233: 120906
2023
-
[26]
T-former: An efficient transformer for image inpainting
Deng Y, Hui S, Zhou S, Meng D and Wang J. T-former: An efficient transformer for image inpainting. In Proc. ACM Intl. Conf. on multimedia. pp. 6559--6568
-
[27]
MViTv2: Improved Multiscale Vision Transformers for Classification and Detection , isbn =
Li W, Lin Z, Zhou K, Qi L, Wang Y and Jia J. Mat: Mask-aware transformer for large hole image inpainting. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 10748--10758. doi:10.1109/CVPR52688.2022.01049
-
[28]
Attention gated networks: Learning to leverage salient regions in medical images
Schlemper J, Oktay O, Schaap M, Heinrich M, Kainz B, Glocker B and Rueckert D. Attention gated networks: Learning to leverage salient regions in medical images. Medical Image Analysis 2019; 53: 197--207
2019
-
[29]
2d human pose estimation: New benchmark and state of the art analysis
Andriluka M, Pishchulin L, Gehler P and Schiele B. 2d human pose estimation: New benchmark and state of the art analysis. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 3686--3693
-
[30]
A flexible new technique for camera calibration
Zhang Z. A flexible new technique for camera calibration. IEEE Trans on Pattern Analysis and Machine Intelligence 2000; 22: 1330--1334
2000
-
[31]
A tutorial on visual servo control
Hutchinson S, Hager GD and Corke PI. A tutorial on visual servo control. IEEE Trans Robot 1996; 12: 651--670. doi:10.1109/70.538972
-
[32]
://docs.opencv.org/4.x/d9/d0c/group__calib3d.html
Camera calibration and 3d reconstruction. ://docs.opencv.org/4.x/d9/d0c/group__calib3d.html
-
[33]
Camera-to-robot pose estimation from a single image
Lee TE, Tremblay J, To T, Cheng J, Mosier T, Kroemer O, Fox D and Birchfield S. Camera-to-robot pose estimation from a single image. In IEEE Intl. Conf. Robot. Autom. pp. 9426--9432
-
[34]
Deeppose: Human pose estimation via deep neural networks
Toshev A and Szegedy C. Deeppose: Human pose estimation via deep neural networks. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 1653--1660
-
[35]
Dynamic visual servoing with kalman filter-based depth and velocity estimator
Chang TY, Chang WC, Cheng MY and Yang SS. Dynamic visual servoing with kalman filter-based depth and velocity estimator. Intl J of Advanced Robotic Syst 2021; 18. doi:10.1177/17298814211016674
-
[36]
Experimental evaluation of uncalibrated visual servoing for precision manipulation
Jagersand M, Fuentes O and Nelson R. Experimental evaluation of uncalibrated visual servoing for precision manipulation. IEEE Intl Conf Robot Autom 1997; 4: 2874--2880. doi:10.1109/robot.1997.606723
-
[37]
Faster R - C N N : Towards real-time object detection with region proposal networks
Ren S, He K, Girshick R and Sun J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans on Pattern Analysis and Machine Intelligence 2017; 39: 1137--1149. doi:10.1109/TPAMI.2016.2577031
-
[38]
How to train a custom keypoint detection model with pytorch, 2021
P A. How to train a custom keypoint detection model with pytorch, 2021
2021
-
[39]
Human pose estimation using keypoint rcnn in pytorch, 2021
Patil C and Gupta V. Human pose estimation using keypoint rcnn in pytorch, 2021
2021
-
[40]
Microsoft coco: Common objects in context
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Doll \'a r P and Zitnick CL. Microsoft coco: Common objects in context. In Computer Vision--ECCV, Zurich, Switzerland, Proceedings, Part V 13. Springer, pp. 740--755
-
[41]
OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields
Cao Z, Hidalgo G, Simon T, Wei SE and Sheikh Y. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Trans on Pattern Analysis and Machine Intelligence 2021; 43: 172--186. doi:10.1109/TPAMI.2019.2929257
-
[42]
Pose estimation for robot manipulators via keypoint optimization and sim-to-real transfer
Lu J, Richter F and Yip MC. Pose estimation for robot manipulators via keypoint optimization and sim-to-real transfer. IEEE Robot Autom Letters 2022; 7: 4622--4629. doi:10.1109/LRA.2022.3151981
-
[43]
Robust jacobian estimation for uncalibrated visual servoing
Shademan A, Farahmand AM and J \"a gersand M. Robust jacobian estimation for uncalibrated visual servoing. In IEEE Intl. Conf. Robot. Autom. pp. 5564--5569
-
[44]
Springer Handbook Of Robotics, volume Springer
Chaumette F, Hutchinson S and Corke P. Springer Handbook Of Robotics, volume Springer. 2016
2016
-
[45]
Versatile visual servoing without knowledge of true jacobian
Hosoda K and Asada M. Versatile visual servoing without knowledge of true jacobian. ISBN 0780319338, pp. 186--193. doi:10.1109/IROS.1994.407392
-
[46]
Introduction to Robotics Mechanics and Control
Craig JJ. Introduction to Robotics Mechanics and Control. 3 ed. Pearson Education International, 2005
2005
-
[47]
Camper's plane localization and head pose estimation based on multi-view rgbd sensors
Wang H, Huang L, Yu K, Song T, Yuan F, Yang H and Zhang H. Camper's plane localization and head pose estimation based on multi-view rgbd sensors. IEEE Access 2022; 10: 131722--131734. doi:10.1109/ACCESS.2022.3227572
-
[48]
Deng X, Liu J, Gong H, Gong H and Huang J. A human-robot collaboration method using a pose estimation network for robot learning of assembly manipulation trajectories from demonstration videos. IEEE Trans on Industrial Informatics 2022; doi:10.1109/TII.2022.3224966
-
[49]
2020 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM) , pages =
Lai J, Huang K, Lu B and Chu HK. Toward vision-based adaptive configuring of a bidirectional two-segment soft continuum manipulator . IEEE/ASME Intl Conf on Adv Intell Mechatronics, AIM 2020; July: 934--939. doi:10.1109/AIM43001.2020.9158975
-
[50]
Calli B and Dollar AM. Vision-based precision manipulation with underactuated hands: Simple and effective solutions for dexterity . In IEEE/RSJ Intl. Conf. Intell. Robots and Syst. , volume Nov. ISBN 9781509037629, pp. 1012--1018. doi:10.1109/IROS.2016.7759173
-
[51]
Imambi S, Prakash KB and Kanagachidambaresan GR. PyTorch. Cham: Springer International Publishing. ISBN 978-3-030-57077-4, 2021. pp. 87--104. doi:10.1007/978-3-030-57077-4_10
-
[52]
Modern Computer Vision with PyTorch: Explore deep learning concepts and implement over 50 real-world image applications
Ayyadevara V and Reddy Y. Modern Computer Vision with PyTorch: Explore deep learning concepts and implement over 50 real-world image applications. Packt Publishing, 2020. ISBN 9781839216534
2020
-
[53]
Densepose: Dense human pose estimation in the wild
G \"u ler RA, Neverova N and Kokkinos I. Densepose: Dense human pose estimation in the wild. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 7297--7306
-
[54]
Hybrid multi-camera visual servoing to moving target
Cuevas-Velasquez H, Li N, Tylecek R, Saval-Calvo M and Fisher RB. Hybrid multi-camera visual servoing to moving target. In IEEE/RSJ Intl. Conf. Intell. Robots and Syst. pp. 1132--1137
-
[55]
Reaching and grasping of objects by humanoid robots through visual servoing
Ard \'o n P, Dragone M and Erden MS. Reaching and grasping of objects by humanoid robots through visual servoing. In Haptics: Science, Technology, and Applications: 11th Intl. Conf., EuroHaptics, Proceedings, Part II 11. Springer, pp. 353--365
-
[56]
Resolution-robust large mask inpainting with fourier convolutions
Suvorov R, Logacheva E, Mashikhin A, Remizova A, Ashukha A, Silvestrov A, Kong N, Goka H, Park K and Lempitsky V. Resolution-robust large mask inpainting with fourier convolutions. In IEEE/CVF Winter Conf. on Appl. of Computer Vision . pp. 2149--2159
-
[57]
Detectron2 2019
Wu Y, Kirillov A, Massa F, Lo WY and Girshick R. Detectron2 2019
2019
-
[58]
Ntire 2022 image inpainting challenge: Report
Romero A, Castillo A, Abril-Nova J, Timofte R, Das R, Hira S, Pan Z, Zhang M, Li B, He D, Lin T, Li F, Wu C, Liu X, Wang X, Yu Y, Yang J, Li R, Zhao Y, Guo Z, Fan B, Li X, Zhang R, Lu Z, Huang J, Wu G, Jiang J, Cai J, Li C, Tao X, Tai YW, Zhou X and Huang H. Ntire 2022 image inpainting challenge: Report. In IEEE Conf. on Computer Vision and Pattern Recogn...
2022
-
[59]
Large scale image completion via co-modulated generative adversarial networks
Zhao S, Cui J, Sheng Y, Dong Y, Liang X, Chang EI and Xu Y. Large scale image completion via co-modulated generative adversarial networks. arXiv preprint arXiv:210310428 2021
2021
-
[60]
Online marker-free extrinsic camera calibration using person keypoint detections
P \"a tzold B, Bultmann S and Behnke S. Online marker-free extrinsic camera calibration using person keypoint detections. In DAGM German Conf. on Pattern Recognition. Springer, pp. 300--316
-
[61]
Robot arm pose estimation through pixel-wise part classification
Bohg J, Romero J, Herzog A and Schaal S. Robot arm pose estimation through pixel-wise part classification. In IEEE Intl. Conf. Robot. Autom. pp. 3143--3150
-
[62]
Keypoints-based adaptive visual servoing for control of robotic manipulators in configuration space
Chatterjee S, Karade AC, Gandhi A and Calli B. Keypoints-based adaptive visual servoing for control of robotic manipulators in configuration space. In IEEE/RSJ Intl. Conf. Intell. Robots and Syst. pp. 6387--6394
-
[63]
Optimizing keypoint-based single-shot camera-to-robot pose estimation through shape segmentation
Lambrecht J, Grosenick P and Meusel M. Optimizing keypoint-based single-shot camera-to-robot pose estimation through shape segmentation. In IEEE Intl. Conf. Robot. Autom. pp. 13843--13849
-
[64]
A vision-based marker-less pose estimation system for articulated construction robots
Liang CJ, Lundeen KM, McGee W, Menassa CC, Lee S and Kamat VR. A vision-based marker-less pose estimation system for articulated construction robots. Autom in Construction 2019; 104: 80--94
2019
-
[65]
A review on vision-based control of robot manipulators
Hashimoto K. A review on vision-based control of robot manipulators. Adv Robot 2003; 17(10): 969--991
2003
-
[66]
A tutorial on visual servo control
Hutchinson S, Hager GD and Corke PI. A tutorial on visual servo control. IEEE Trans Robot 1996; 12(5): 651--670
1996
-
[67]
Towards high performance human keypoint detection
Zhang J, Chen Z and Tao D. Towards high performance human keypoint detection. Intl J of Computer Vision 2021; 129(9): 2639--2662
2021
-
[68]
Feature refinement to improve high resolution image inpainting
Kulshreshtha P, Pugh B and Jiddi S. Feature refinement to improve high resolution image inpainting. arXiv preprint arXiv:220613644 2022
2022
-
[69]
Free-form image inpainting with gated convolution
Yu J, Lin Z, Yang J, Shen X, Lu X and Huang TS. Free-form image inpainting with gated convolution. In IEEE/CVF Intl. Conf. on Computer Vision . pp. 4471--4480
-
[70]
Edgeconnect: Generative image inpainting with adversarial edge learning
Nazeri K, Ng E, Joseph T, Qureshi FZ and Ebrahimi M. Edgeconnect: Generative image inpainting with adversarial edge learning. arXiv preprint arXiv:190100212 2019
2019
-
[71]
Image inpainting by end-to-end cascaded refinement with mask awareness
Zhu M, He D, Li X, Li C, Li F, Liu X, Ding E and Zhang Z. Image inpainting by end-to-end cascaded refinement with mask awareness. IEEE Trans on Img Processing 2021; 30: 4855--4866
2021
-
[72]
Contextual residual aggregation for ultra high-resolution image inpainting
Yi Z, Tang Q, Azizi S, Jang D and Xu Z. Contextual residual aggregation for ultra high-resolution image inpainting. In IEEE Conf. on Computer Vision and Pattern Recognition . pp. 7508--7517
-
[73]
Path planning using lazy prm
Bohlin R and Kavraki LE. Path planning using lazy prm. In IEEE Intl. Conf. Robot. Autom. , volume 1. pp. 521--528
-
[74]
Skeleton-based adaptive visual servoing for control of robotic manipulators in configuration space
Gandhi A, Chatterjee S and Calli B. Skeleton-based adaptive visual servoing for control of robotic manipulators in configuration space. In IEEE/RSJ Intl. Conf. Intell. Robots and Syst. pp. 2182--2189
-
[75]
Obstacle avoidance using image-based visual servoing integrated with nonlinear model predictive control
Lee D, Lim H and Kim HJ. Obstacle avoidance using image-based visual servoing integrated with nonlinear model predictive control. In IEEE Conf. on Decision and Control and European Control Conference . pp. 5689--5694
-
[76]
Path planning in image space for robust visual servoing
Mezouar Y and Chaumette F. Path planning in image space for robust visual servoing. In IEEE Intl. Conf. Robot. Autom. , volume 3. pp. 2759--2764
-
[77]
End-to-end training of deep visuomotor policies
Levine S, Finn C, Darrell T and Abbeel P. End-to-end training of deep visuomotor policies. J of Machine Learning Research 2016; 17(39): 1--40. ://jmlr.org/papers/v17/15-522.html
2016
-
[78]
Learning latent dynamics for planning from pixels
Hafner D, Lillicrap T, Fischer I, Villegas R, Ha D, Lee H and Davidson J. Learning latent dynamics for planning from pixels. In Intl. Conf. on Machine Learning. PMLR, pp. 2555--2565
-
[79]
Robot motion planning in learned latent spaces
Ichter B and Pavone M. Robot motion planning in learned latent spaces. IEEE Robot Autom Letters 2019; 4(3): 2407--2414
2019
-
[80]
Probabilistic roadmaps for path planning in high-dimensional configuration spaces
Kavraki LE, Svestka P, Latombe JC and Overmars MH. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans Robot 1996; 12(4): 566--580
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.