Recognition: unknown
Right Regions, Wrong Labels: Semantic Label Flips in Segmentation under Correlation Shift
Pith reviewed 2026-05-10 15:06 UTC · model grok-4.3
The pith
Semantic segmentation models can achieve good overlap but swap plausible foreground labels under correlation shifts between categories and scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In semantic segmentation under correlation shift between category and scene, models exhibit semantic label flips where they assign plausible but incorrect foreground classes to objects whose boundaries are largely preserved, and this behavior increases with correlation strength as quantified by the Flip metric.
What carries the argument
The Flip diagnostic, which counts ground truth foreground pixels assigned the wrong foreground identity while remaining predicted as foreground.
If this is right
- Performance gaps between common and rare conditions increase with correlation strength.
- Within-object label swaps become more common on groups that break the training correlation.
- Foreground errors should be decomposed into correct assignments, flipped identities, and misses to background.
- An entropy-based flip-risk score flags likely label flips without requiring ground truth labels.
Where Pith is reading between the lines
- Overlap-based metrics alone may mask safety issues in applications like medical imaging or autonomous driving where misclassifying an object type matters.
- The flip-risk score could be used to trigger human review or ensemble methods in high-stakes deployments.
- Similar label flip phenomena might appear in other dense prediction tasks such as depth estimation or instance segmentation under distributional shifts.
Load-bearing premise
The artificial correlation between category and scene in the training data generates test conditions representative of real shifts where label flips are both measurable and increase systematically with correlation strength.
What would settle it
Training models with controlled correlation strengths and finding no corresponding rise in the Flip metric on counterfactual test scenes, or observing that the entropy-based score fails to predict actual label flips.
Figures

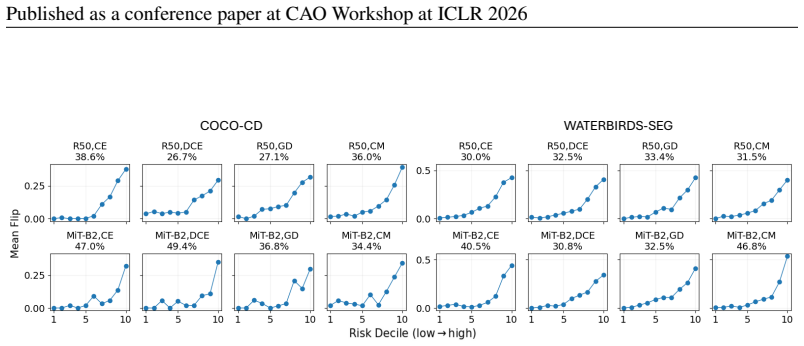


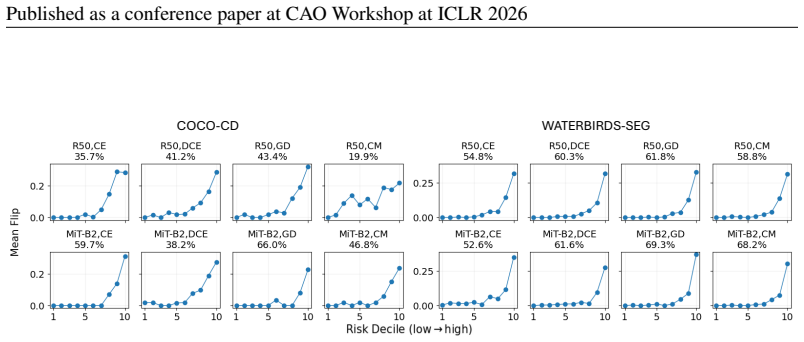
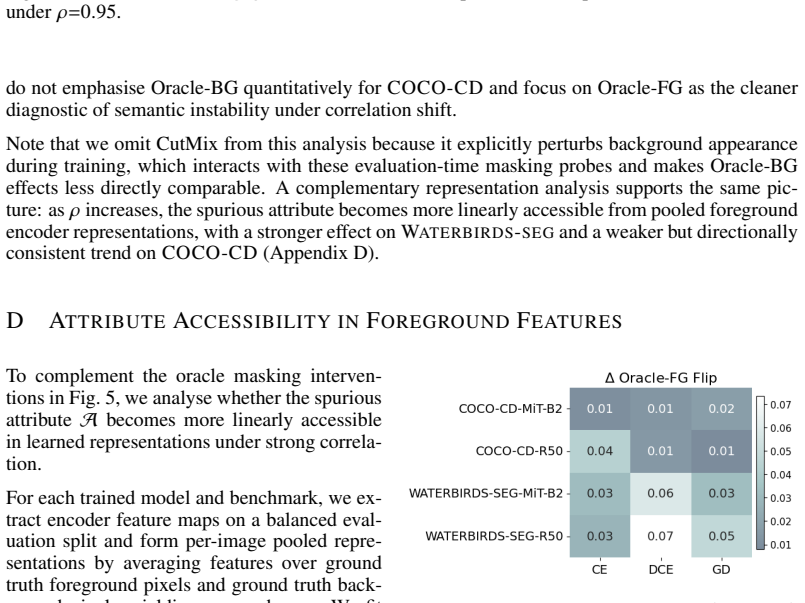


read the original abstract
The robustness of machine learning models can be compromised by spurious correlations between non-causal features in the input data and target labels. A common way to test for such correlations is to train on data where the label is strongly tied to some non-causal cue, then evaluate on examples where that tie no longer holds. This idea is well established for classification tasks, but for semantic segmentation the specific failure modes are not well understood. We show that a model may achieve reasonable overlap while assigning the wrong semantic label, swapping one plausible foreground class for another, even when object boundaries are largely correct. We focus on this semantic label-flip behaviour and quantify it with a simple diagnostic (Flip) that counts how often ground truth foreground pixels are assigned the wrong foreground identity while remaining predicted as foreground. In a setting where category and scene are correlated during training, increasing the correlation consistently widens the gap between common and rare test conditions and increases these within-object label swaps on counterfactual groups. Overall, our results motivate assessing segmentation robustness under distribution shift beyond overlap by decomposing foreground errors into correct pixels, flipped-identity pixels, and missed-to-background pixels. We also propose an entropy-based, ground truth label-free `flip-risk' score, which is computed from foreground identity uncertainty, and show that it can flag flip-prone cases at inference time. Code is available at https://github.com/acharaakshit/label-flips.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that semantic segmentation models can achieve reasonable overlap while committing semantic label flips—assigning an incorrect but plausible foreground class to object pixels whose boundaries are largely preserved—under correlation shifts between object categories and scene context. It introduces a counting-based Flip diagnostic that decomposes foreground errors into correct-identity, flipped-identity, and missed-to-background pixels, shows that stronger category-scene correlations during training widen gaps and increase flips on counterfactual test groups, and proposes a ground-truth-free entropy-based flip-risk score to flag such cases at inference time.
Significance. If the empirical results hold, the work usefully distinguishes label-flip errors from standard boundary or background failures in segmentation robustness, providing a concrete diagnostic and an inference-time risk score that could improve evaluation and deployment under spurious correlations. The emphasis on decomposing foreground predictions and the public code release are positive contributions to the literature on distribution shift in dense prediction tasks.
major comments (2)
- [Experimental Setup / Methods] The abstract states that 'increasing the correlation consistently widens the gap ... and increases these within-object label swaps on counterfactual groups,' yet the precise construction of the correlated training sets, the sampling procedure for common vs. rare conditions, and the definition of counterfactual test groups are not specified. Without these details it is impossible to confirm that the measured rise in Flip scores is caused by the intended category-scene decorrelation rather than incidental shifts in object scale, co-occurrence statistics, or background appearance (see skeptic concern).
- [Proposed Diagnostic] The Flip diagnostic is described only at a high level ('counts how often ground truth foreground pixels are assigned the wrong foreground identity while remaining predicted as foreground'). A formal definition—e.g., an equation that specifies the set of admissible foreground classes, the pixel-wise condition, and any normalization—should be provided so that the metric can be reproduced exactly and its sensitivity to class granularity assessed.
minor comments (2)
- [Abstract] The abstract asserts quantitative trends without reporting any numerical values, dataset names, model architectures, or statistical significance; a brief summary of key numbers and controls would strengthen the abstract.
- [Flip-risk Score] The entropy-based flip-risk score is introduced as 'ground truth label-free' and computed from 'foreground identity uncertainty'; its exact formulation (e.g., which entropy is used, over which softmax outputs, and any thresholding) should be stated explicitly for immediate usability.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the work's significance and for the constructive comments on experimental details and metric formalization. We address each major comment below and will revise the manuscript to enhance clarity and reproducibility.
read point-by-point responses
-
Referee: [Experimental Setup / Methods] The abstract states that 'increasing the correlation consistently widens the gap ... and increases these within-object label swaps on counterfactual groups,' yet the precise construction of the correlated training sets, the sampling procedure for common vs. rare conditions, and the definition of counterfactual test groups are not specified. Without these details it is impossible to confirm that the measured rise in Flip scores is caused by the intended category-scene decorrelation rather than incidental shifts in object scale, co-occurrence statistics, or background appearance (see skeptic concern).
Authors: We agree that the current description lacks sufficient detail on the data construction pipeline, which is essential for reproducibility and for ruling out confounds. In the revised manuscript we will add a dedicated subsection in Methods that specifies: (i) the exact procedure used to induce category-scene correlations (by re-weighting the joint distribution while preserving marginals), (ii) the sampling protocol that defines common versus rare conditions, and (iii) the construction of counterfactual test groups as pairings that violate the training correlation. We will also report auxiliary statistics confirming that object scale, intra-class co-occurrence, and background appearance distributions remain matched across conditions, thereby isolating the effect of the intended correlation shift. revision: yes
-
Referee: [Proposed Diagnostic] The Flip diagnostic is described only at a high level ('counts how often ground truth foreground pixels are assigned the wrong foreground identity while remaining predicted as foreground'). A formal definition—e.g., an equation that specifies the set of admissible foreground classes, the pixel-wise condition, and any normalization—should be provided so that the metric can be reproduced exactly and its sensitivity to class granularity assessed.
Authors: We acknowledge that the Flip diagnostic is currently presented at a descriptive level. In the revision we will insert a formal definition in the Methods section. The definition will be given as an equation that (a) identifies the admissible foreground class set (all classes except background), (b) states the pixel-wise condition (ground-truth foreground pixel predicted as a different foreground class), and (c) normalizes by the total number of ground-truth foreground pixels. We will also add a short discussion of the metric's sensitivity to label granularity. revision: yes
Circularity Check
No significant circularity in empirical metric definitions
full rationale
The paper is empirical and introduces diagnostic metrics (Flip count and entropy-based flip-risk) defined directly from pixel-level predictions, ground-truth labels, and model uncertainty. These definitions stand independently without reducing any claimed result to a fitted parameter, self-referential equation, or load-bearing self-citation. The central observations about label flips under correlation shift are presented as measured outcomes rather than derived predictions that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Correlation between category and scene in training data creates a spurious cue that models exploit, leading to measurable label flips on counterfactual test groups.
invented entities (2)
-
Flip diagnostic
no independent evidence
-
flip-risk score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
ISBN 1- 901725-60-X. doi: 10.5244/C.31.57. URLhttps://dx.doi.org/10.5244/C.31.57. Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.5244/c.31.57
-
[2]
Lee, Esther
9 Published as a conference paper at CAO Workshop at ICLR 2026 Tiarna. Lee, Esther. Puyol-Ant´on, Bram. Ruijsink, Sebastien. Roujol, Theodore. Barfoot, Shaheim. Ogbomo-Harmitt, Miaojing. Shi, and Andrew. King. An investigation into the causes of race bias in artificial intelligence–based cine cardiac magnetic resonance segmentation.European Heart Journal ...
2026
-
[3]
Weixin Liang and James Zou. Metashift: A dataset of datasets for evaluating contextual distribution shifts and training conflicts.arXiv preprint arXiv:2202.06523,
-
[4]
Are we done with object-centric learning?arXiv preprint arXiv:2504.07092,
Alexander Rubinstein, Ameya Prabhu, Matthias Bethge, and Seong Joon Oh. Are we done with object-centric learning?arXiv preprint arXiv:2504.07092,
-
[5]
Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generaliza- tion.arXiv preprint arXiv:1911.08731,
work page internal anchor Pith review arXiv 1911
-
[6]
The caltech-ucsd birds-200-2011 dataset
10 Published as a conference paper at CAO Workshop at ICLR 2026 Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset
2026
-
[7]
Spurious correla- tions in machine learning: A survey.arXiv preprint arXiv:2402.12715,
Wenqian Ye, Guangtao Zheng, Xu Cao, Yunsheng Ma, and Aidong Zhang. Spurious correlations in machine learning: A survey.arXiv preprint arXiv:2402.12715,
-
[8]
Zheyuan Zhang and Yen-chia Hsu. Mitigating spurious correlations in weakly supervised semantic segmentation via cross-architecture consistency regularization.arXiv preprint arXiv:2507.21959,
-
[9]
Table 2 lists the resulting group counts for train/validation/test under both correlation regimes
11 Published as a conference paper at CAO Workshop at ICLR 2026 A DATASETCONSTRUCTIONDETAILS WATERBIRDS-SEG.We use CUB bird masks for dense supervision and follow the WATERBIRDS group construction with𝜌∈ {0.5,0.95}, matching train size across regimes and keeping valida- tion/test balanced across groups. Table 2 lists the resulting group counts for train/v...
2026
-
[10]
ResNet-50 exhibits non-trivial FG-Miss across regimes (and an increase under𝜌=0.95), alongside measurable FG-Flip
On COCO-CD, missed-to-background can be a substantial error mode for weaker models, so the decomposition clarifies whether performance losses stem from identity confusion (FG-Flip) or foreground deletion (FG-Miss). ResNet-50 exhibits non-trivial FG-Miss across regimes (and an increase under𝜌=0.95), alongside measurable FG-Flip. In contrast, MiT-B2 reduces...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.