Recognition: unknown
Optimal Predicate Pushdown Synthesis
Pith reviewed 2026-05-10 13:10 UTC · model grok-4.3
The pith
A bisimulation invariant lets synthesis automatically decompose stateful folds into optimal pre- and post-filters for predicate pushdown.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Predicate pushdown for stateful fold computations is formalized as the existence of a bisimulation invariant relating the states of two folds that process different subsets of the input; a relatively complete verification framework checks candidate invariants, and a synthesis procedure searches for the strongest admissible pre-filter and weakest post-filter that together preserve the original semantics.
What carries the argument
Bisimulation invariant relating the internal states of two fold programs that consume different input subsets.
If this is right
- Optimal pushdown decompositions are produced for a larger class of pipelines than prior techniques allow.
- Median synthesis time across 150 real benchmarks is 1.6 seconds.
- End-to-end execution of the optimized pipelines is 2.4 times faster on average, with gains reaching two orders of magnitude.
- The synthesized filters remain inside the language fragment used by practical pandas and Spark user-defined functions.
Where Pith is reading between the lines
- The same bisimulation technique could be applied to other aggregation idioms once suitable state invariants are identified.
- Integration into query planners would allow automatic optimization of pipelines that currently require expert rewriting.
- The method might surface previously unnoticed pushdown opportunities inside complex domain-specific UDFs.
Load-bearing premise
Target computations must be expressible as stateful folds whose bisimulation invariants can be synthesized automatically and whose derived filters lie inside the supported fragment of real-world user-defined functions.
What would settle it
A concrete pipeline for which a semantically correct pushdown exists yet the synthesis procedure either returns no solution or returns a decomposition that changes the observable output.
Figures








read the original abstract
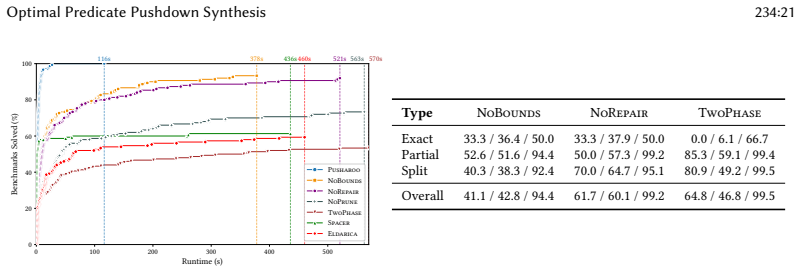
Predicate pushdown is a long-standing performance optimization that filters data as early as possible in a computational workflow. In modern data pipelines, this transformation is especially important because much of the computation occurs inside user-defined functions (UDFs) written in general-purpose languages such as Python and Scala. These UDFs capture rich domain logic and complex aggregations and are among the most expensive operations in a pipeline. Moving filters ahead of such UDFs can yield substantial performance gains, but doing so requires semantic reasoning. This paper introduces a general semantic foundation for predicate pushdown over stateful fold-based computations. We view pushdown as a correspondence between two programs that process different subsets of input data, with correctness witnessed by a bisimulation invariant relating their internal states. Building on this foundation, we develop a sound and relatively complete framework for verification, alongside a synthesis algorithm that automatically constructs optimal pushdown decompositions by finding the strongest admissible pre-filters and weakest residual post-filters. We implement this approach in a tool called Pusharoo and evaluate it on 150 real-world pandas and Spark data-processing pipelines. Our evaluation shows that Pusharoo is significantly more expressive than prior work, producing optimal pushdown transformations with a median synthesis time of 1.6 seconds per benchmark. Furthermore, our experiments demonstrate that the discovered pushdown optimizations speed up end-to-end execution by an average of 2.4$\times$ and up to two orders of magnitude.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a bisimulation-based semantic foundation for predicate pushdown over stateful fold-based UDF computations in data pipelines. It develops a sound and relatively complete verification framework together with a synthesis algorithm that constructs optimal decompositions via strongest admissible pre-filters and weakest residual post-filters. The approach is implemented in the Pusharoo tool and evaluated on 150 real-world pandas and Spark pipelines, reporting a median synthesis time of 1.6 seconds per benchmark together with an average end-to-end speedup of 2.4× (up to two orders of magnitude).
Significance. If the soundness and relative completeness claims hold and the synthesis indeed produces optimal transformations, the work would be significant for automatic optimization of modern data-processing pipelines that rely heavily on expensive stateful UDFs. The application of standard bisimulation invariants to this setting, combined with an independent synthesis search, offers a principled alternative to heuristic pushdown techniques. The concrete evaluation on real pipelines and the reported speedups provide evidence of practical utility and greater expressiveness than prior art.
major comments (1)
- Abstract and synthesis section: the claim that the algorithm produces 'optimal' pushdown transformations rests on finding the strongest admissible pre-filters and weakest post-filters; it is unclear whether the search procedure is guaranteed to discover them (via relative completeness) or whether optimality is observed empirically from the particular search strategy employed.
minor comments (3)
- The evaluation reports a median synthesis time of 1.6 s and average 2.4× speedup but does not include a table or figure breaking down results by pipeline type (pandas vs. Spark) or by the complexity of the stateful folds; adding such a breakdown would strengthen the empirical claims.
- The abstract states that Pusharoo is 'significantly more expressive than prior work'; a direct side-by-side comparison table (expressiveness, supported UDF patterns, synthesis success rate) would make this claim easier to verify.
- Notation for the bisimulation invariant and the pre-/post-filter languages should be introduced with a small running example early in the paper to aid readability for readers outside concurrency theory.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation of minor revision. We are glad that the significance of the bisimulation-based approach and the practical speedups on real pipelines are recognized. We address the single major comment below.
read point-by-point responses
-
Referee: [—] Abstract and synthesis section: the claim that the algorithm produces 'optimal' pushdown transformations rests on finding the strongest admissible pre-filters and weakest post-filters; it is unclear whether the search procedure is guaranteed to discover them (via relative completeness) or whether optimality is observed empirically from the particular search strategy employed.
Authors: The optimality guarantee follows directly from the sound and relatively complete verification framework. The synthesis algorithm enumerates candidate pre-filters (and symmetrically post-filters) in a manner that allows the verifier to certify strength: a candidate is accepted as the strongest admissible pre-filter only when the bisimulation invariant holds and any strictly stronger filter falsifies the invariant under the relative-completeness property. Because the predicate language is finite for the UDFs we consider, the search is exhaustive within that language and therefore guaranteed to discover the strongest admissible filter when one exists. The reported speedups are therefore consequences of this certified optimality rather than an artifact of a particular heuristic strategy. To remove any ambiguity in the presentation, we will revise the abstract and the synthesis section to state explicitly that optimality is certified by relative completeness of the verifier. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper's derivation rests on a bisimulation-based semantic foundation for predicate pushdown over stateful folds, which applies a standard concept from concurrency theory to define correctness via invariants relating program states. The sound and relatively complete verification framework and the synthesis algorithm for strongest pre-filters and weakest post-filters follow directly from this relation without reducing to self-defined quantities or fitted parameters. Optimality is established by exhaustive search within the supported language fragment rather than by construction from evaluation data. The reported synthesis times and 2.4× speedups are empirical measurements on 150 independent real-world pipelines, not predictions derived from the paper's own inputs. Assumptions about fold expressibility and invariant synthesis are explicitly scoped, and no load-bearing self-citation chain or ansatz smuggling is present. The central claims therefore remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bisimulation invariants correctly witness equivalence between full-input and filtered-input executions of fold-based programs.
Reference graph
Works this paper leans on
-
[1]
Alejandro Aguirre, Gilles Barthe, Marco Gaboardi, Deepak Garg, and Pierre-Yves Strub. 2017. A relational logic for higher-order programs. Proc. ACM Program. Lang. 1, ICFP, Article 21 (Aug. 2017), 29 pages. doi:10.1145/3110265
-
[2]
Aws Albarghouthi, Isil Dillig, and Arie Gurfinkel. 2016. Maximal specification synthesis. SIGPLAN Not. 51, 1 (Jan. 2016), 789–801. doi:10.1145/2914770.2837628
-
[3]
Gilles Barthe, Juan Manuel Crespo, and César Kunz. 2011. Relational verification using product programs. InProceedings of the 17th International Conference on Formal Methods (Limerick, Ireland) (FM’11). Springer-Verlag, Berlin, Heidelberg, 200–214. doi:10.1007/978-3-642-21437-0_17
-
[4]
Stefanos Baziotis, Daniel D. Kang, and Charith Mendis. 2024. Dias: Dynamic Rewriting of Pandas Code. Proc. ACM Manag. Data 2, 1 (2024), 58:1–58:27. doi:10.1145/3639313
-
[5]
Nick Benton. 2004. Simple relational correctness proofs for static analyses and program transformations. SIGPLAN Not. 39, 1 (Jan. 2004), 14–25. doi:10.1145/982962.964003
-
[6]
Blakeley, Per-Åke Larson, and Frank Wm
José A. Blakeley, Per-Åke Larson, and Frank Wm. Tompa. 1986. Efficiently Updating Materialized Views. InProceedings of the 1986 ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, May 28-30, 1986. 61–71. doi:10.1145/16894.16861
-
[7]
James Bornholt, Emina Torlak, Dan Grossman, and Luis Ceze. 2016. Optimizing synthesis with metasketches. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages (St. Petersburg, FL, USA) (POPL ’16). Association for Computing Machinery, New York, NY, USA, 775–788. doi:10.1145/ 2837614.2837666
-
[8]
Paris Carbone, Asterios Katsifodimos, Stephan Ewen, Volker Markl, Seif Haridi, and Kostas Tzoumas. 2015. Apache flink: Stream and batch processing in a single engine. The Bulletin of the Technical Committee on Data Engineering 38, 4 (2015)
2015
-
[9]
Alvin Cheung, Armando Solar-Lezama, and Samuel Madden. 2013. Optimizing database-backed applications with query synthesis. In ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’13, Seattle, W A, USA, June 16-19, 2013, Hans-Juergen Boehm and Cormac Flanagan (Eds.). ACM, 3–14. doi:10.1145/2491956.2462180
-
[10]
Shumo Chu, Brendan Murphy, Jared Roesch, Alvin Cheung, and Dan Suciu. 2018. Axiomatic foundations and algorithms for deciding semantic equivalences of SQL queries. Proc. VLDB Endow. 11, 11 (July 2018), 1482–1495. doi:10.14778/3236187.3236200
-
[11]
Shumo Chu, Konstantin Weitz, Alvin Cheung, and Dan Suciu. 2017. HoTTSQL: proving query rewrites with uni- valent SQL semantics. In Proceedings of the 38th ACM SIGPLAN Conference on Programming Language Design and Implementation (Barcelona, Spain) (PLDI 2017). Association for Computing Machinery, New York, NY, USA, 510–524. doi:10.1145/3062341.3062348
-
[12]
Stephen A. Cook. 1978. Soundness and Completeness of an Axiom System for Program Verification. SIAM J. Comput. 7, 1 (Feb. 1978), 70–90. doi:10.1137/0207005
-
[13]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: an efficient SMT solver. In Proceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems (Budapest, Hungary) (TACAS’08/ETAPS’08). Springer-Verlag, Berlin, Heidelberg, 337–340. doi:10.1007/978-3-540-78800-3_24
- [14]
-
[15]
Venkatesh Emani, Karthik Ramachandra, Subhro Bhattacharya, and S
K. Venkatesh Emani, Karthik Ramachandra, Subhro Bhattacharya, and S. Sudarshan. 2016. Extracting Equivalent SQL from Imperative Code in Database Applications. In Proceedings of the 2016 International Conference on Management of Data, SIGMOD Conference 2016, San Francisco, CA, USA, June 26 - July 01, 2016 , Fatma Özcan, Georgia Koutrika, and Proc. ACM Prog...
-
[16]
Dennis Felsing, Sarah Grebing, Vladimir Klebanov, Philipp Rümmer, and Mattias Ulbrich. 2014. Automating regression verification. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering (Vasteras, Sweden) (ASE ’14). Association for Computing Machinery, New York, NY, USA, 349–360. doi:10.1145/2642937.2642987
-
[17]
Cormac Flanagan and K. Rustan M. Leino. 2001. Houdini, an Annotation Assistant for ESC/Java. In Proceedings of the International Symposium of Formal Methods Europe on Formal Methods for Increasing Software Productivity (FME ’01) . Springer-Verlag, Berlin, Heidelberg, 500–517. doi:10.1007/3-540-45251-6_29
-
[18]
Ullman, and Jennifer Widom
Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom. 2008. Database Systems: The Complete Book (2 ed.). Prentice Hall Press, USA
2008
-
[19]
Benny Godlin and Ofer Strichman. 2009. Regression verification. In Proceedings of the 46th Annual Design Automation Conference (San Francisco, California) (DAC ’09). Association for Computing Machinery, New York, NY, USA, 466–471. doi:10.1145/1629911.1630034
-
[20]
Yu Gu, Takeshi Tsukada, and Hiroshi Unno. 2023. Optimal CHC Solving via Termination Proofs. Proc. ACM Program. Lang. 7, POPL, Article 21 (Jan. 2023), 28 pages. doi:10.1145/3571214
-
[21]
Surabhi Gupta, Sanket Purandare, and Karthik Ramachandra. 2020. Aggify: Lifting the Curse of Cursor Loops using Custom Aggregates. In Proceedings of the 2020 International Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020 , David Maier, Rachel Pottinger, AnHai Doan, Wang-Chiew Tan, Abdussalam...
-
[22]
Hossein Hojjat and Philipp Rümmer. 2018. The ELDARICA Horn Solver. In 2018 Formal Methods in Computer Aided Design (FMCAD). 1–7. doi:10.23919/FMCAD.2018.8603013
-
[23]
Eaman Jahani, Michael J. Cafarella, and Christopher Ré. 2011. Automatic Optimization for MapReduce Programs. Proc. VLDB Endow. 4, 6 (2011), 385–396. doi:10.14778/1978665.1978670
-
[24]
Anvesh Komuravelli, Arie Gurfinkel, and Sagar Chaki. 2014. SMT-Based Model Checking for Recursive Programs. In Computer Aided Verification, Armin Biere and Roderick Bloem (Eds.). Springer International Publishing, Cham, 17–34. doi:10.1007/978-3-319-08867-9_2
-
[25]
Lahiri, Chris Hawblitzel, Ming Kawaguchi, and Henrique Rebêlo
Shuvendu K. Lahiri, Chris Hawblitzel, Ming Kawaguchi, and Henrique Rebêlo. 2012. SYMDIFF: A Language-Agnostic Semantic Diff Tool for Imperative Programs. InComputer Aided Verification, P. Madhusudan and Sanjit A. Seshia (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 712–717. doi:10.1007/978-3-642-31424-7_54
-
[26]
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2015. How good are query optimizers, really? Proc. VLDB Endow. 9, 3 (Nov. 2015), 204–215. doi:10.14778/2850583.2850594
-
[27]
Yiming Lin and Sharad Mehrotra. 2024. PLAQUE: Automated Predicate Learning at Query Time. Proc. ACM Manag. Data 2, 1 (2024), 46:1–46:25. doi:10.1145/3639301
-
[28]
Stephen Mell, Steve Zdancewic, and Osbert Bastani. 2024. Optimal Program Synthesis via Abstract Interpretation. Proc. ACM Program. Lang. 8, POPL, Article 16 (Jan. 2024), 25 pages. doi:10.1145/3632858
-
[29]
Microsoft. 2025. Microsoft SQL Server. https://www.microsoft.com/en-us/sql-server. Accessed June 2025
2025
-
[30]
MySQL. 2025. MySQL. https://www.mysql.com/. Accessed June 2025
2025
-
[31]
Oracle. 2025. Oracle Database. https://www.oracle.com/database/. Accessed June 2025
2025
-
[32]
VLDB Endow.13, 3 (2019), 279–292
Laurel J. Orr, Srikanth Kandula, and Surajit Chaudhuri. 2019. Pushing Data-Induced Predicates Through Joins in Big-Data Clusters. Proc. VLDB Endow. 13, 3 (2019), 252–265. doi:10.14778/3368289.3368292
-
[33]
Shoumik Palkar, Firas Abuzaid, Peter Bailis, and Matei Zaharia. 2018. Filter before you parse: faster analytics on raw data with sparser. Proc. VLDB Endow. 11, 11 (July 2018), 1576–1589. doi:10.14778/3236187.3236207
-
[34]
David Park. 1981. Concurrency and automata on infinite sequences. In Theoretical Computer Science, Peter Deussen (Ed.). Springer Berlin Heidelberg, Berlin, Heidelberg, 167–183. doi:10.1007/BFb0017309
-
[35]
Kanghee Park, Xuanyu Peng, and Loris D’Antoni. 2025. LOUD: Synthesizing Strongest and Weakest Specifications. Proc. ACM Program. Lang. 9, OOPSLA1, Article 114 (April 2025), 28 pages. doi:10.1145/3720470
-
[36]
Meikel Poess, Bryan Smith, Lubor Kollar, and Paul Larson. 2002. TPC-DS, taking decision support benchmarking to the next level. In Proceedings of the 2002 ACM SIGMOD International Conference on Management of Data (Madison, Wisconsin) (SIGMOD ’02). Association for Computing Machinery, New York, NY, USA, 582–587. doi:10.1145/564691. 564759
-
[37]
PostgreSQL. 2025. PostgreSQL. https://www.postgresql.org/. Accessed June 2025
2025
-
[38]
Willard V Quine. 1959. On cores and prime implicants of truth functions. The American Mathematical Monthly 66, 9 (1959), 755–760. doi:10.1080/00029890.1959.11989404
-
[39]
Venkatesh Emani, Alan Halverson, César A
Karthik Ramachandra, Kwanghyun Park, K. Venkatesh Emani, Alan Halverson, César A. Galindo-Legaria, and Conor Cunningham. 2017. Froid: Optimization of Imperative Programs in a Relational Database. Proc. VLDB Endow. 11, 4 (2017), 432–444. doi:10.1145/3186728.3164140
-
[40]
Salman Salloum, Ruslan Dautov, Xiaojun Chen, Patrick Xiaogang Peng, and Joshua Zhexue Huang. 2016. Big data analytics on Apache Spark. International Journal of Data Science and Analytics 1 (2016), 145–164. doi:10.1007/s41060- Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 234. Publication date: June 2026. Optimal Predicate Pushdown Synthesis 234:25 ...
-
[41]
Varun Simhadri, Karthik Ramachandra, Arun Chaitanya, Ravindra Guravannavar, and S. Sudarshan. 2014. Decorrelation of user defined function invocations in queries. In IEEE 30th International Conference on Data Engineering, Chicago, ICDE 2014, IL, USA, March 31 - April 4, 2014 , Isabel F. Cruz, Elena Ferrari, Yufei Tao, Elisa Bertino, and Goce Trajcevski (E...
-
[42]
Marcelo Sousa and Isil Dillig. 2016. Cartesian hoare logic for verifying k-safety properties. In Proceedings of the 37th ACM SIGPLAN Conference on Programming Language Design and Implementation (Santa Barbara, CA, USA) (PLDI ’16). Association for Computing Machinery, New York, NY, USA, 57–69. doi:10.1145/2908080.2908092
-
[43]
Marcelo Sousa, Isil Dillig, Dimitrios Vytiniotis, Thomas Dillig, and Christos Gkantsidis. 2014. Consolidation of queries with user-defined functions. ACM SIGPLAN Notices 49, 6 (2014), 554–564. doi:10.1145/2594291.2594305
-
[44]
Jeffrey D. Ullman. 1990. Principles of Database and Knowledge-Base Systems: Volume II: The New Technologies . W. H. Freeman & Co., USA
1990
-
[45]
Shuxian Wang, Sicheng Pan, and Alvin Cheung. 2024. QED: A Powerful Query Equivalence Decider for SQL. Proc. VLDB Endow. 17, 11 (July 2024), 3602–3614. doi:10.14778/3681954.3682024
-
[46]
Yuepeng Wang, Isil Dillig, Shuvendu K. Lahiri, and William R. Cook. 2017. Verifying equivalence of database-driven applications. Proc. ACM Program. Lang. 2, POPL, Article 56 (Dec. 2017), 29 pages. doi:10.1145/3158144
-
[47]
Ziteng Wang, Ruijie Fang, Linus Zheng, Dixin Tang, and Işı l Dillig. 2025. Homomorphism Calculus for User-Defined Aggregations. Proc. ACM Program. Lang. 9, OOPSLA2, Article 294 (oct 2025), 27 pages. doi:10.1145/3763072
-
[48]
Cong Yan, Yin Lin, and Yeye He. 2023. Predicate Pushdown for Data Science Pipelines. Proc. ACM Manag. Data 1, 2, Article 136 (June 2023), 28 pages. doi:10.1145/3589281
-
[49]
Hongseok Yang. 2007. Relational separation logic. Theor. Comput. Sci. 375, 1–3 (April 2007), 308–334. doi:10.1016/j.tcs. 2006.12.036
-
[50]
Woicik, Yizhou Liu, Xiangyao Yu, Marco Serafini, Ashraf Aboulnaga, and Michael Stonebraker
Yifei Yang, Matt Youill, Matthew E. Woicik, Yizhou Liu, Xiangyao Yu, Marco Serafini, Ashraf Aboulnaga, and Michael Stonebraker. 2021. FlexPushdownDB: Hybrid Pushdown and Caching in a Cloud DBMS. Proc. VLDB Endow. 14, 11 (2021), 2101–2113. doi:10.14778/3476249.3476265
-
[51]
Guoqiang Zhang, Benjamin Mariano, Xipeng Shen, and Işıl Dillig. 2023. Automated Translation of Functional Big Data Queries to SQL. Proc. ACM Program. Lang. 7, OOPSLA1, Article 95 (April 2023), 29 pages. doi:10.1145/3586047
-
[52]
Guoqiang Zhang, Yuanchao Xu, Xipeng Shen, and Işıl Dillig. 2021. UDF to SQL translation through compositional lazy inductive synthesis. Proc. ACM Program. Lang. 5, OOPSLA, Article 112 (Oct. 2021), 26 pages. doi:10.1145/3485489
-
[53]
Robert Zhang, Eric Hayden Campbell, Dixin Tang, and Isil Dillig. 2026. Optimal Predicate Pushdown Synthesis (Software Artifact). doi:10.5281/zenodo.19084858
-
[54]
Robert Zhang, Eric Hayden Campbell, Dixin Tang, and Isil Dillig. 2026. Pusharoo. https://github.com/utopia- group/pushdown
2026
-
[55]
Navathe, William Harris, and Jinpeng Wu
Qi Zhou, Joy Arulraj, Shamkant B. Navathe, William Harris, and Jinpeng Wu. 2021. SIA: Optimizing Queries using Learned Predicates. In SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 2169–2181. doi:10.1145/3448016. 3457262
-
[56]
In2022 IEEE 38th International Conference on Data Engineering (ICDE)
Qi Zhou, Joy Arulraj, Shamkant B. Navathe, William Harris, and Jinpeng Wu. 2022. SPES: A Symbolic Approach to Proving Query Equivalence Under Bag Semantics. In 2022 IEEE 38th International Conference on Data Engineering (ICDE). 2735–2748. doi:10.1109/ICDE53745.2022.00250 Proc. ACM Program. Lang., Vol. 10, No. PLDI, Article 234. Publication date: June 2026...
-
[57]
This is the Hoare precondition: from 𝑎1 = 𝐼 and 𝑎2 = 𝐼, the invariant 𝜓 (𝑎1, 𝑎2) must hold before the loop
Initialization. This is the Hoare precondition: from 𝑎1 = 𝐼 and 𝑎2 = 𝐼, the invariant 𝜓 (𝑎1, 𝑎2) must hold before the loop
-
[58]
Corresponds to the Hoare rule for the “then” branch when 𝑄 (𝑟 ) is true
Synchronized-step preservation. Corresponds to the Hoare rule for the “then” branch when 𝑄 (𝑟 ) is true. We require { 𝜓 (𝑎1, 𝑎2) } 𝑎1 := 𝑓 (𝑎1, 𝑟); 𝑎2 := 𝑓 (𝑎2, 𝑟) { 𝜓 (𝑎1, 𝑎2) }, which is exactly our synchronized-step condition
-
[59]
Corresponds to the Hoare rule for the “else” branch when𝑄 (𝑟 ) is false
Stutter-step preservation. Corresponds to the Hoare rule for the “else” branch when𝑄 (𝑟 ) is false. We require { 𝜓 (𝑎1, 𝑎2) } 𝑎1 := 𝑓 (𝑎1, 𝑟) { 𝜓 (𝑎1, 𝑎2) }, with 𝑎2 unchanged, matching our stutter-step condition
-
[60]
Corresponds to the Hoare postcondition
Final-state agreement. Corresponds to the Hoare postcondition. From 𝜓 (𝑎1, 𝑎2) after the loop, we must show Lift(𝑃, 𝑎1) = Lift(𝑃 ′, 𝑎2), which is our final-state agreement condition. By the soundness of Hoare logic, if one discharges these four proof obligations, then the asserted triple is valid, and hence ∀𝑥 . Lift(𝑃, 𝐹 (𝑥)) = Lift(𝑃 ′, 𝐹 (filter𝑄 (𝑥)))...
2026
-
[61]
implies 𝜓min(𝑎′ 1, 𝑎′ 2), we know 𝜓 (𝑎′ 1, 𝑎′
-
[62]
time") { buf(0) = buf.getLong(0) + 1L } else if (in(0) ==
fails, so 𝑄 violates Sync under such 𝜓 on row 𝑟. (b) Stutter failure. In this case, the check 𝜒stutter : 𝜓max (𝑎1, 𝑎2) ∧ ¬ 𝑄 (𝑟 ) ∧ 𝑎′ 1 = 𝑓 (𝑎1, 𝑟) ∧ 𝑎′ 2 = 𝑎2 =⇒ 𝜓min(𝑎′ 1, 𝑎′ 2) is invalid for some (𝑎1, 𝑎2, 𝑟). By the same reasoning, 𝑄 violates Stutter under any 𝜓 where 𝜓min ⊆ 𝜓 ⊆ 𝜓max on row 𝑟. □ Theorem A.5 (Correctness of FindStrongestBisimulation)....
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.