Recognition: unknown
A Machine Learning Framework for Uncertainty-Calibrated Capability Decision under Finite Samples
Pith reviewed 2026-05-10 13:18 UTC · model grok-4.3
The pith
A hybrid statistical and machine learning framework quantifies misclassification risk for process capability decisions under finite samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reformulating capability approval as a decision-risk calibration problem and solving it with an uncertainty-aware hybrid framework that pairs a statistically grounded baseline for interpretable failure-risk approximation with a data-driven residual learner produces a stable representation of misclassification probability, in contrast to deterministic thresholding of finite-sample estimates which exhibits substantial miscalibration near thresholds.
What carries the argument
The uncertainty-aware hybrid framework, which combines a statistical baseline approximating failure risk with a residual learner capturing systematic deviations, evaluated through nested Monte Carlo to approximate oracle decision risk.
If this is right
- Conventional deterministic thresholding shows substantial miscalibration near capability boundaries.
- The hybrid framework maintains stability under stricter leak-free evaluation protocols.
- The method remains compatible with existing capability metrics and can be deployed in current industrial analytics systems.
- The baseline provides an interpretable starting point while the residual addresses non-normality and measurement effects.
Where Pith is reading between the lines
- The approach could be tested on sequential sampling schemes where new data arrives over time rather than fixed finite batches.
- Similar calibration might improve other quality-control thresholds that currently rely on point estimates.
- If the residual learner generalizes across product lines, it could reduce the need for separate models per process type.
Load-bearing premise
The nested Monte Carlo procedure accurately approximates the true oracle decision risk and the residual learner captures deviations without adding bias or overfitting in the finite-sample regimes of interest.
What would settle it
Compare the framework's predicted misclassification probabilities against the observed frequency of wrong approvals or rejections when the same real manufacturing datasets are repeatedly resampled at the same finite size near the capability threshold.
Figures



read the original abstract
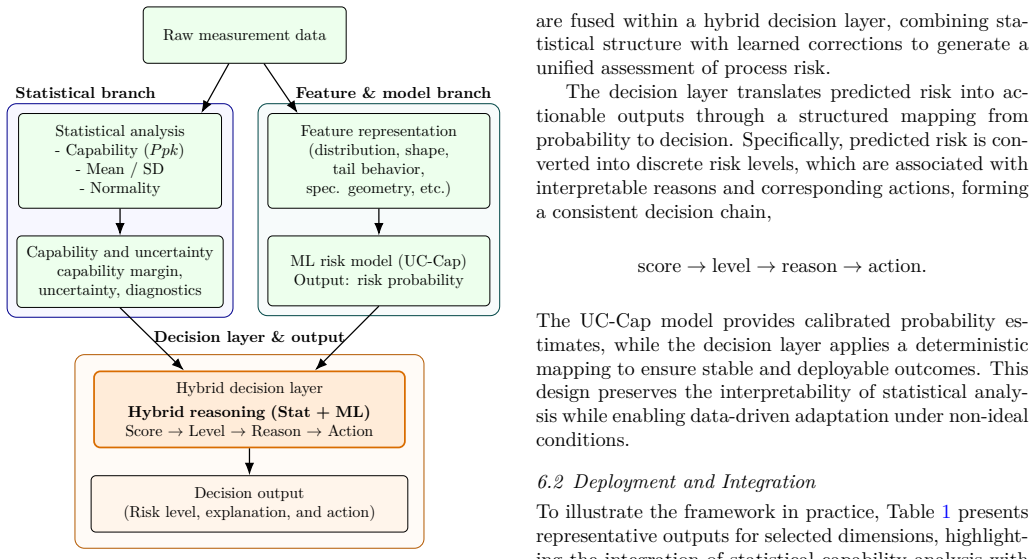
Process capability indices such as $C_{pk}$ are widely used for manufacturing decisions, yet are typically applied via deterministic thresholding of finite-sample estimates, ignoring uncertainty and leading to unstable outcomes near the capability boundary. This paper reformulates capability approval as a decision-risk calibration problem, quantifying the probability of misclassification under finite-sample variability. We propose an uncertainty-aware hybrid framework that combines a statistically grounded baseline with a data-driven residual learner, where the baseline provides an interpretable approximation of failure risk and the residual captures systematic deviations due to non-normality, measurement effects, and finite-sample uncertainty. A nested Monte Carlo procedure is introduced to approximate oracle decision risk under controlled synthetic settings, enabling direct evaluation of probabilistic calibration. Empirical results show that conventional approaches exhibit substantial miscalibration in near-threshold regimes, while the proposed framework provides a structured and uncertainty-aware representation of decision risk that remains stable under stricter leak-free evaluation. The framework is simple, compatible with existing capability metrics, and readily deployable in industrial analytics systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reformulates process capability decisions (e.g., thresholding finite-sample C_pk) as a decision-risk calibration problem. It proposes an uncertainty-aware hybrid framework that pairs a statistically grounded baseline approximation of failure risk with a data-driven residual learner to capture deviations from non-normality, measurement effects, and finite-sample uncertainty. A nested Monte Carlo procedure approximates oracle decision risk under synthetic settings for direct calibration evaluation. Empirical results are claimed to show substantial miscalibration of conventional approaches near thresholds, with the proposed framework yielding more stable, uncertainty-aware risk estimates under leak-free evaluation.
Significance. If the empirical calibration improvements hold after addressing variance and reproducibility concerns, the work could offer a practical, deployable enhancement to industrial capability analysis by reducing unstable decisions near boundaries while remaining compatible with existing C_pk metrics.
major comments (2)
- [Nested Monte Carlo procedure] Nested Monte Carlo procedure (methods section): the inner-loop sample size, convergence diagnostics, effective sample size, or variance bounds for the oracle misclassification probability are not reported. Near the decision boundary the indicator function is highly sensitive to perturbations in the finite-sample C_pk estimate, so modest inner-sample budgets can produce high-variance oracle estimates that confound comparisons of 'substantial miscalibration' versus 'stable' improvement.
- [Empirical results and evaluation] Empirical results and evaluation (results section): no error bars, data-generation details, residual-learner architecture, training procedure, or explicit leak-free protocol are supplied. Without these, the central claim that the hybrid framework outperforms conventional thresholding cannot be assessed or reproduced.
minor comments (1)
- [Abstract] The abstract introduces 'leak-free evaluation' without a definition or reference to the corresponding section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for improving the clarity and reproducibility of our work. We address each major comment below, agreeing where revisions are needed and outlining the changes.
read point-by-point responses
-
Referee: [Nested Monte Carlo procedure] Nested Monte Carlo procedure (methods section): the inner-loop sample size, convergence diagnostics, effective sample size, or variance bounds for the oracle misclassification probability are not reported. Near the decision boundary the indicator function is highly sensitive to perturbations in the finite-sample C_pk estimate, so modest inner-sample budgets can produce high-variance oracle estimates that confound comparisons of 'substantial miscalibration' versus 'stable' improvement.
Authors: We agree that the methods section would benefit from explicit reporting of the inner-loop sample size, convergence diagnostics, effective sample size, and variance bounds for the nested Monte Carlo procedure. In the revised manuscript, we will include these details, along with an analysis of the variance near decision boundaries to confirm the reliability of the oracle estimates. This will directly address concerns about potential high-variance issues in the evaluation. revision: yes
-
Referee: [Empirical results and evaluation] Empirical results and evaluation (results section): no error bars, data-generation details, residual-learner architecture, training procedure, or explicit leak-free protocol are supplied. Without these, the central claim that the hybrid framework outperforms conventional thresholding cannot be assessed or reproduced.
Authors: We acknowledge the absence of these critical details in the results section. We will revise the manuscript to include error bars on all empirical plots, full specifications of the data-generation process, the architecture and hyperparameters of the residual learner, the training procedure, and a clear description of the leak-free evaluation protocol. These additions will enable proper assessment and reproduction of our results. revision: yes
Circularity Check
No circularity detected; empirical framework with independent synthetic validation
full rationale
The paper introduces a hybrid statistical-plus-residual framework for capability decision risk and evaluates it empirically against an oracle approximated by nested Monte Carlo on controlled synthetic data. No equations, fitting procedures, or derivation steps are exhibited in the abstract or described claims that reduce a prediction to its own inputs by construction. The nested Monte Carlo is presented as an external approximation tool for oracle risk rather than a self-fitted quantity renamed as a result. Central claims rest on comparative calibration performance under leak-free evaluation, which remains falsifiable against the synthetic oracle and does not rely on self-citation chains or ansatzes smuggled from prior author work. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Victor E. Kane. Process Capability Indices.Jour- nal of Quality Technology, 18(1):41–52, January
-
[2]
ISSN 0022-4065. doi: 10.1080/00224065.1986. 11978984
-
[3]
Samuel Kotz and Norman L. Johnson. Process Ca- pability Indices—A Review, 1992–2000.Journal of Quality Technology, 34(1):2–19, January 2002. ISSN 0022-4065, 2575-6230. doi: 10.1080/00224065.2002. 11980119
-
[4]
John wiley & sons, 2020
Douglas C Montgomery.Introduction to statistical quality control. John wiley & sons, 2020
2020
-
[5]
Statisticalmethodsinprocessmanagement – capability and performance – part 1: General prin- ciples and concepts
ISO/TR. Statisticalmethodsinprocessmanagement – capability and performance – part 1: General prin- ciples and concepts. ISO/TR 22514-1:2014 (2014)
2014
-
[6]
Statisticalmethodsinprocessmanagement – capability and performance – part 4: Process capa- bility estimates and performance measures
ISO/TR. Statisticalmethodsinprocessmanagement – capability and performance – part 4: Process capa- bility estimates and performance measures. ISO/TR 22514-4:2016 (2016)
2016
-
[7]
Routledge, 2007
John Oakland and John S Oakland.Statistical pro- cess control. Routledge, 2007
2007
-
[8]
Fei Jiang and Lei Yang. Practical process capa- bility indices workflows.The International Jour- nal of Advanced Manufacturing Technology, pages 1–19, 2026. doi: 10.1007/s00170-026-17782-7. URL https://doi.org/10.1007/s00170-026-17782-7
-
[9]
W. L. Pearn, Samuel Kotz, and Norman L. Johnson. Distributional and Inferential Properties of Process Capability Indices.Journal of Quality Technology, 24(4):216–231, October 1992. ISSN 0022-4065, 2575-
1992
-
[10]
doi: 10.1080/00224065.1992.11979403
-
[11]
How reliable is your capability index? Journal of the Royal Statistical Society Series C: Ap- plied Statistics, 39(3):331–340, 1990
AF Bissell. How reliable is your capability index? Journal of the Royal Statistical Society Series C: Ap- plied Statistics, 39(3):331–340, 1990
1990
-
[12]
Mahmoud A. Mahmoud, G. Robin Henderson, Eu- genio K. Epprecht, and William H. Woodall. Esti- mating the Standard Deviation in Quality-Control Applications.Journal of Quality Technology, 42(4): 348–357, October 2010. ISSN 0022-4065, 2575-6230. doi: 10.1080/00224065.2010.11917832
-
[13]
K. S. Chen and W. L. Pearn. An ap- plication of non-normal process capability in- dices.Quality and Reliability Engineering In- ternational, 13(6):355–360, 1997. ISSN 1099-
1997
-
[14]
doi: 10.1002/(SICI)1099-1638(199711/12)13: 6<355::AID-QRE125>3.0.CO;2-V
-
[15]
Process capability calculations for non-normal distributions.Quality progress, 22: 95–100, 1989
John A Clements. Process capability calculations for non-normal distributions.Quality progress, 22: 95–100, 1989
1989
-
[16]
Kuen-Suan Chen and Wen-Lee Pearn. Capability in- dicesforprocesseswithasymmetrictolerances.Jour- nal of the Chinese Institute of Engineers, 24(5):559– 568, July 2001. ISSN 0253-3839, 2158-7299. doi: 10.1080/02533839.2001.9670652
-
[17]
Abbasi Ganji and B
Z. Abbasi Ganji and B. Sadeghpour Gildeh. A class of process capability indices for asymmetric toler- ances.Quality Engineering, 28(4):441–454, October
-
[18]
doi: 10.1080/ 08982112.2016.1168524
ISSN 0898-2112, 1532-4222. doi: 10.1080/ 08982112.2016.1168524
-
[19]
Lai K. Chan, Smiley W. Cheng, and Frederick A. Spiring. A New Measure of Process Capability: C pm .Journal of Quality Technology, 20(3):162– 175, July 1988. ISSN 0022-4065, 2575-6230. doi: 10.1080/00224065.1988.11979102
-
[20]
Russell A. Boyles. The Taguchi Capability Index. Journal of Quality Technology, 23(1):17–26, January
-
[21]
doi: 10.1080/ 00224065.1991.11979279
ISSN 0022-4065, 2575-6230. doi: 10.1080/ 00224065.1991.11979279
-
[22]
A unified approach to capability indices.Statistica Sinica, pages 805–820, 1995
Kerstin Vännman. A unified approach to capability indices.Statistica Sinica, pages 805–820, 1995
1995
-
[23]
Finite-sample decision insta- bility in threshold-based process capability approval
Fei Jiang and Lei Yang. Finite-sample decision insta- bility in threshold-based process capability approval. arXiv:2603.11315, 2026
-
[24]
Using measurement uncer- tainty in decision-making and conformity assess- ment.Metrologia, 51(4):S206–S218, 2014
Leslie R Pendrill. Using measurement uncer- tainty in decision-making and conformity assess- ment.Metrologia, 51(4):S206–S218, 2014
2014
-
[25]
ISO. Geometrical product specifications (gps) – in- spection by measurement of workpieces and mea- suring equipment – part 1: Decision rules for prov- ing conformity or nonconformity with specifications. International Organization for Standardization, ISO 14253-1:2013 (2013)
2013
-
[26]
Uncertainty of measurement and conformity assessment: a re- view.Analytical and Bioanalytical Chemistry, 400 (6):1729–1741, 2011
Elio Desimoni and Barbara Brunetti. Uncertainty of measurement and conformity assessment: a re- view.Analytical and Bioanalytical Chemistry, 400 (6):1729–1741, 2011. 17
2011
-
[27]
Statistical decision functions
Abraham Wald. Statistical decision functions. In Breakthroughs in Statistics: Foundations and Basic Theory, pages 342–357. Springer, 1950
1950
-
[28]
John Wiley & Sons, 2005
Morris H DeGroot.Optimal statistical decisions. John Wiley & Sons, 2005
2005
-
[29]
Springer Science & Business Me- dia, 2013
James O Berger.Statistical decision theory and Bayesian analysis. Springer Science & Business Me- dia, 2013
2013
-
[30]
John Wiley & Sons, 2013
David W Hosmer Jr, Stanley Lemeshow, and Rod- ney X Sturdivant.Applied logistic regression. John Wiley & Sons, 2013
2013
-
[31]
Xgboost: A scal- able tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scal- able tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
2016
-
[32]
Strictly proper scoring rules, prediction, and estimation
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102 (477):359–378, 2007
2007
-
[33]
On calibration of modern neural net- works
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural net- works. InInternational conference on machine learn- ing, pages 1321–1330. PMLR, 2017
2017
-
[34]
Reliable classification: Learning classifiers that distinguish aleatoricandepistemicuncertainty.Information Sci- ences, 255:16–29, 2014
Robin Senge, Stefan Bösner, Krzysztof Dem- bczyński, Jörg Haasenritter, Oliver Hirsch, Norbert Donner-Banzhoff, and Eyke Hüllermeier. Reliable classification: Learning classifiers that distinguish aleatoricandepistemicuncertainty.Information Sci- ences, 255:16–29, 2014
2014
-
[35]
Fei Jiang and Lei Yang. Risk-calibrated process ca- pability approval with finite samples.arXiv preprint arXiv:2603.14479, 2026
work page internal anchor Pith review arXiv 2026
-
[36]
Evaluation of measurement data — the role of measurement uncertainty in conformity assessment,
Joint Committee for Guides in Metrology (JCGM). Evaluation of measurement data — the role of measurement uncertainty in conformity assessment,
-
[37]
JCGM 106:2012
URLhttps://www.bipm.org/documents/ 20126/2071204/JCGM_106_2012_E.pdf. JCGM 106:2012
2012
-
[38]
Iso/iec 17025:2017 — general requirements for the competence of test- ing and calibration laboratories, 2017
International Organization for Standardiza- tion (ISO). Iso/iec 17025:2017 — general requirements for the competence of test- ing and calibration laboratories, 2017. URL https://www.iso.org/standard/66912.html. ISO/IEC 17025:2017
2017
-
[39]
Cambridge university press, 2000
Aad W Van der Vaart.Asymptotic statistics, vol- ume 3. Cambridge university press, 2000
2000
-
[40]
John Wiley & Sons, 2009
Robert J Serfling.Approximation theorems of math- ematical statistics. John Wiley & Sons, 2009
2009
-
[41]
On the gap between theory and prac- tice of process capability studies.International Jour- nal of Quality & Reliability Management, 15(2):178– 191, 1998
Mats Deleryd. On the gap between theory and prac- tice of process capability studies.International Jour- nal of Quality & Reliability Management, 15(2):178– 191, 1998
1998
-
[42]
Springer, 1998
Erich Leo Lehmann and George Casella.Theory of point estimation. Springer, 1998
1998
-
[43]
Chapman and Hall/CRC, 2024
George Casella and Roger Berger.Statistical infer- ence. Chapman and Hall/CRC, 2024
2024
-
[44]
Classifier technology and the illusion of progress
David J Hand. Classifier technology and the illusion of progress. 2006
2006
-
[45]
Stacked regressions.Machine learning, 24(1):49–64, 1996
Leo Breiman. Stacked regressions.Machine learning, 24(1):49–64, 1996
1996
-
[46]
Generalized additive models.Sta- tistical models in S, pages 249–307, 2017
Trevor J Hastie. Generalized additive models.Sta- tistical models in S, pages 249–307, 2017
2017
-
[47]
Automotive Industry Action Group, Southfield, MI, 4th edition, 2010
AIAG.Measurement Systems Analysis (MSA) Ref- erence Manual. Automotive Industry Action Group, Southfield, MI, 4th edition, 2010
2010
-
[48]
Springer Science & Business Media, 2012
JunShaoandDongshengTu.The jackknife and boot- strap. Springer Science & Business Media, 2012. 18
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.