Recognition: unknown
TLoRA+: A Low-Rank Parameter-Efficient Fine-Tuning Method for Large Language Models
Pith reviewed 2026-05-10 14:14 UTC · model grok-4.3
The pith
Incorporating the TLoRA+ optimizer into pre-trained weight matrices improves low-rank adaptation performance on language tasks without significant added cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that integrating the TLoRA+ optimizer into the weight matrices of pre-trained models preserves the efficiency of low-rank adaptation, including no added inference latency, while further enhancing task performance without substantially increasing computational cost, as evidenced by consistent numerical results on the GLUE benchmark across diverse model architectures.
What carries the argument
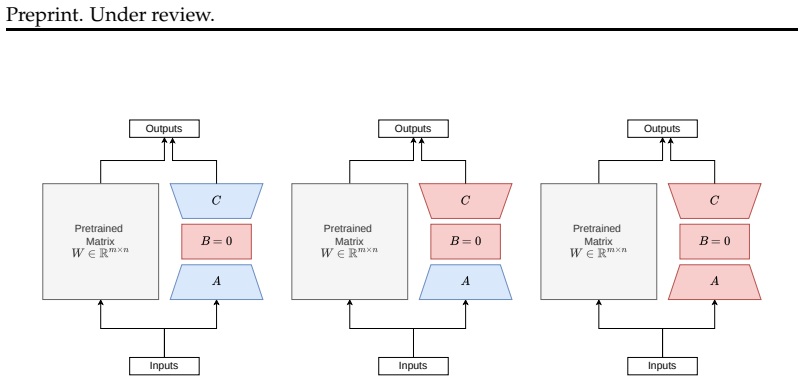
The TLoRA+ optimizer, which is incorporated into pre-trained weight matrices to augment low-rank updates and drive better adaptation.
If this is right
- GLUE task scores rise relative to plain LoRA while inference latency stays unchanged.
- The method scales across multiple large language model families without architecture-specific redesign.
- Computational overhead during fine-tuning remains comparable to existing low-rank methods.
- Robustness holds under the numerical conditions reported for the tested setups.
Where Pith is reading between the lines
- Similar optimizer integration might improve other parameter-efficient methods beyond low-rank adaptation.
- The approach could be tested on generation or reasoning benchmarks to check if gains extend past classification tasks.
- Practitioners might combine TLoRA+ with existing training schedules to reduce the need for full-parameter updates in constrained environments.
Load-bearing premise
That the TLoRA+ optimizer can be added to pre-trained weight matrices in a manner that produces reliable performance gains across different model architectures and tasks.
What would settle it
A controlled comparison on an untested model architecture or task where TLoRA+ either fails to exceed standard LoRA accuracy or requires markedly more training compute or time.
Figures








read the original abstract
Fine-tuning large language models (LLMs) aims to adapt pre-trained models to specific tasks using relatively small and domain-specific datasets. Among Parameter-Efficient Fine-Tuning (PEFT) methods, Low-Rank Adaptation (LoRA) stands out by matching the performance of full fine-tuning while avoiding additional inference latency. In this paper, we propose a novel PEFT method that incorporates the TLoRA+ optimizer into the weight matrices of pre-trained models. The proposed approach not only preserves the efficiency of low-rank adaptation but also further enhances performance without significantly increasing computational cost. We conduct experiments on the GLUE benchmark across diverse model architectures. Numerical experiments consistently demonstrate the effectiveness and robustness of our proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TLoRA+, a parameter-efficient fine-tuning (PEFT) method that incorporates the TLoRA+ optimizer directly into the weight matrices of pre-trained LLMs. It claims to retain the computational efficiency of standard Low-Rank Adaptation (LoRA) while delivering further performance improvements, with experiments on the GLUE benchmark across diverse model architectures demonstrating consistent effectiveness and robustness.
Significance. If the performance gains are robustly shown to exceed standard LoRA and other PEFT baselines without meaningful added cost, the method could offer a lightweight practical improvement to existing adaptation techniques. However, the manuscript provides no equations defining the optimizer, no ablation studies, no quantitative deltas, and no statistical details, so the significance cannot be assessed from the available text. The work does not include machine-checked proofs, reproducible code, or falsifiable predictions.
major comments (2)
- [Abstract] Abstract: the central claim that TLoRA+ 'further enhances performance' is unsupported; the abstract supplies no equations, ablation details, quantitative deltas, or direct comparisons to LoRA, DoRA, or AdaLoRA, leaving the effectiveness assertion without visible evidence.
- [Experiments] Experimental section (implied by abstract): no information is given on number of random seeds, statistical significance testing, variance across runs, or hyperparameter tuning protocol; single-run point estimates on GLUE would render the 'consistently demonstrate' and 'robustness' statements unreliable.
minor comments (1)
- [Abstract] The abstract and title introduce 'TLoRA+' without defining the optimizer or its relation to standard LoRA; notation and algorithmic description should be added in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the manuscript to better support the claims in the abstract and to include additional experimental details for improved clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TLoRA+ 'further enhances performance' is unsupported; the abstract supplies no equations, ablation details, quantitative deltas, or direct comparisons to LoRA, DoRA, or AdaLoRA, leaving the effectiveness assertion without visible evidence.
Authors: We agree that the abstract, being a concise summary, does not include equations, ablations, or specific deltas, which are presented in the main body. The method section defines the TLoRA+ optimizer (including its integration into the weight matrices) with the relevant equations, and the experiments section reports direct comparisons to LoRA, DoRA, and AdaLoRA along with quantitative GLUE results. To address the concern, we will revise the abstract to include a brief reference to the observed performance gains while respecting length limits. revision: yes
-
Referee: [Experiments] Experimental section (implied by abstract): no information is given on number of random seeds, statistical significance testing, variance across runs, or hyperparameter tuning protocol; single-run point estimates on GLUE would render the 'consistently demonstrate' and 'robustness' statements unreliable.
Authors: The referee is correct that more details on experimental protocol are needed to substantiate robustness claims. In the revised manuscript, we will expand the experimental section to specify the number of random seeds, report mean and standard deviation across runs, describe the hyperparameter tuning protocol, and note any statistical testing performed. This will provide stronger support for the statements on consistent effectiveness. revision: yes
Circularity Check
No circularity in empirical validation of TLoRA+
full rationale
The paper proposes TLoRA+ as an extension of LoRA that inserts an optimizer into pre-trained weight matrices, then reports GLUE benchmark results across architectures to claim preserved efficiency plus performance gains. No derivation chain, mathematical equations, or self-referential steps appear in the abstract or described content. Claims rest on external experimental outcomes rather than any reduction of predictions to fitted inputs, self-citations, or ansatzes by construction. The evaluation uses a standard public benchmark independent of the method definition, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- TLoRA+ optimizer hyperparameters
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:265294736. Samir Yitzhak Gadre, Georgios Smyrnis, Vaishaal Shankar, Suchin Gururangan, Mitchell Wortsman, Rulin Shao, Jean-Pierre Mercat, Alex Fang, Jeffrey Li, Sedrick Scott Keh, Rui Xin, Marianna Nezhurina, Igor Vasiljevic, Jenia Jitsev, Alexandros G. Dimakis, Gabriel Ilharco, Shuran Song, Thomas Kollar, Yai...
-
[2]
Lora+: Efficient low rank adaptation of large models
URLhttps://api.semanticscholar.org/CorpusID:26661612. Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models.ArXiv, abs/2402.12354,
-
[3]
URL https://api.semanticscholar.org/CorpusID: 267750102. Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, E...
work page internal anchor Pith review arXiv
-
[4]
URLhttps://api.semanticscholar.org/CorpusID:247778764. J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
URLhttps://api.semanticscholar.org/CorpusID:235458009. Tanvir Islam. Tlora: Tri-matrix low-rank adaptation of large language models.ArXiv, abs/2504.18735,
-
[6]
Yongle Li, Bo Liu, Sheng Huang, ZHeng ZHang, Xiaotong Yuan, and Richang Hong
URLhttps://api.semanticscholar.org/CorpusID:278164754. Yongle Li, Bo Liu, Sheng Huang, ZHeng ZHang, Xiaotong Yuan, and Richang Hong. Communication-efficient and personalized federated foundation model fine-tuning via tri-matrix adaptation.arXiv preprint arXiv:2503.23869,
-
[7]
Nora: Nested low-rank adaptation for efficient fine-tuning large models.ArXiv, abs/2408.10280,
Cheng Lin, Lujun Li, Dezhi Li, Jie Zou, Wei Xue, and Yi-Ting Guo. Nora: Nested low-rank adaptation for efficient fine-tuning large models.ArXiv, abs/2408.10280,
-
[8]
DoRA: Weight-Decomposed Low-Rank Adaptation
URL https://api.semanticscholar.org/CorpusID:271909569. Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adap- tation.ArXiv, abs/2402.09353,
work page internal anchor Pith review arXiv
-
[9]
Pissa: Principal singular values and singular vectors adaptation of large language models, 2025
URL https://api.semanticscholar.org/CorpusID: 267657886. Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models.ArXiv, abs/2404.02948,
-
[10]
URL https://api.semanticscholar.org/CorpusID:268889493. Chunlin Tian, Zhanying Shi, Zhijiang Guo, Li Li, and Chengzhong Xu. Hydralora: An asymmetric lora architecture for efficient fine-tuning.ArXiv, abs/2404.19245,
-
[11]
URL https://api.semanticscholar.org/CorpusID: 5034059. 10 Preprint. Under review. Shaowen Wang, Linxi Yu, and Jian Li. Lora-ga: Low-rank adaptation with gradient approxi- mation.ArXiv, abs/2407.05000,
-
[12]
Bojia Zi, Xianbiao Qi, Lingzhi Wang, Jianan Wang, Kam-Fai Wong, and Lei Zhang
URL https://api.semanticscholar.org/CorpusID: 266435293. Bojia Zi, Xianbiao Qi, Lingzhi Wang, Jianan Wang, Kam-Fai Wong, and Lei Zhang. Delta- lora: Fine-tuning high-rank parameters with the delta of low-rank matrices.ArXiv, abs/2309.02411,
-
[13]
URLhttps://api.semanticscholar.org/CorpusID:261556652. 11 Preprint. Under review. A Choice of Learning Rate We group the validation loss by learning rate in Figure 7 and observe consistent trends across both datasets and backbone models. A learning rate of 2 × 10−4 leads to rapid initial loss reduction but is followed by clear overfitting, indicating over...
-
[14]
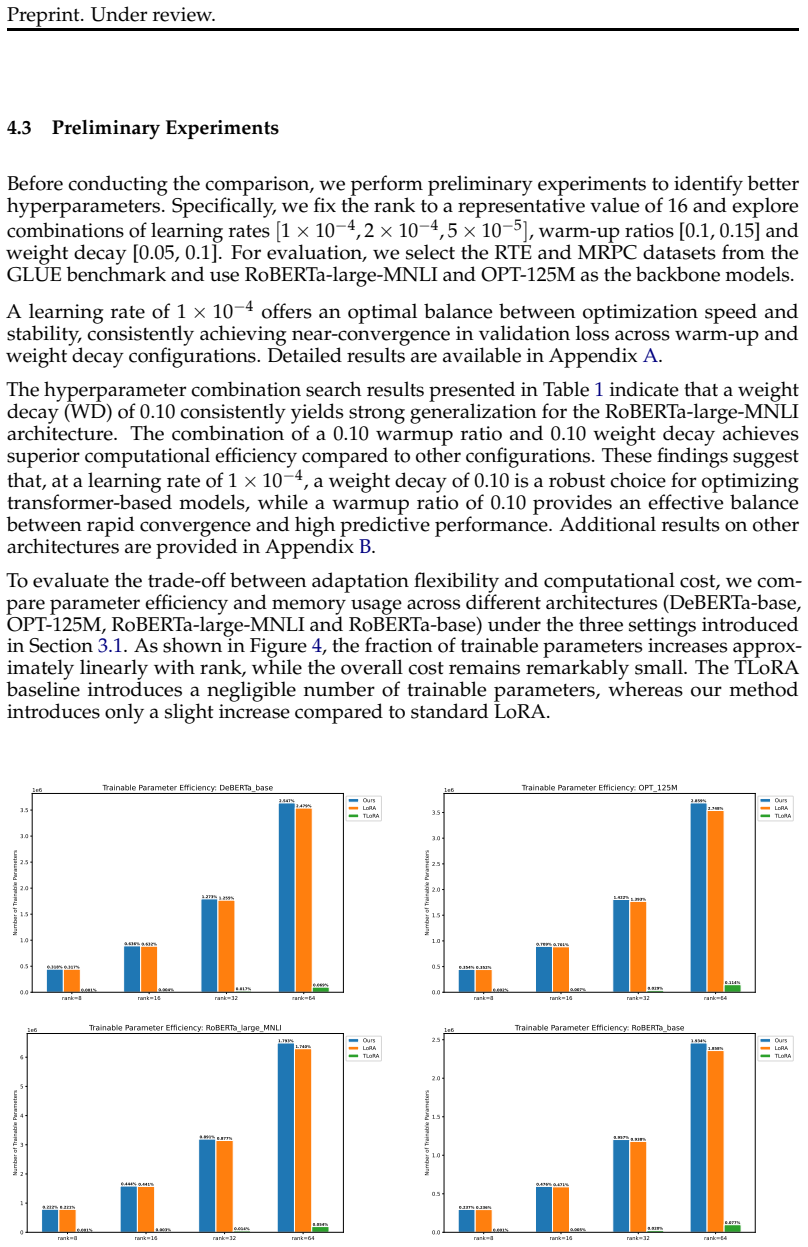
ID Method Model Tr Acc Tr Loss Val Acc Val Loss Val MCC 1 LoRA DeBERTa-base 0.9918 0.04040.90440.38050.7747 2 Ours DeBERTa-base 0.7045 0.4873 0.6887 0.4780 0.1032 3 TLoRA DeBERTa-base 0.6601 0.6762 0.6838 0.6776 0.0000 4 LoRA OPT-125M 0.9957 0.01250.80641.08210.5347 5 Ours OPT-125M 0.8062 0.4326 0.8039 0.4529 0.5211 6 TLoRA OPT-125M 0.6785 0.6225 0.6765 0...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.