Recognition: unknown
ReSS: Learning Reasoning Models for Tabular Data Prediction via Symbolic Scaffold
Pith reviewed 2026-05-10 13:54 UTC · model grok-4.3
The pith
ReSS extracts decision paths from trees to scaffold LLM fine-tuning for tabular prediction with faithful reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
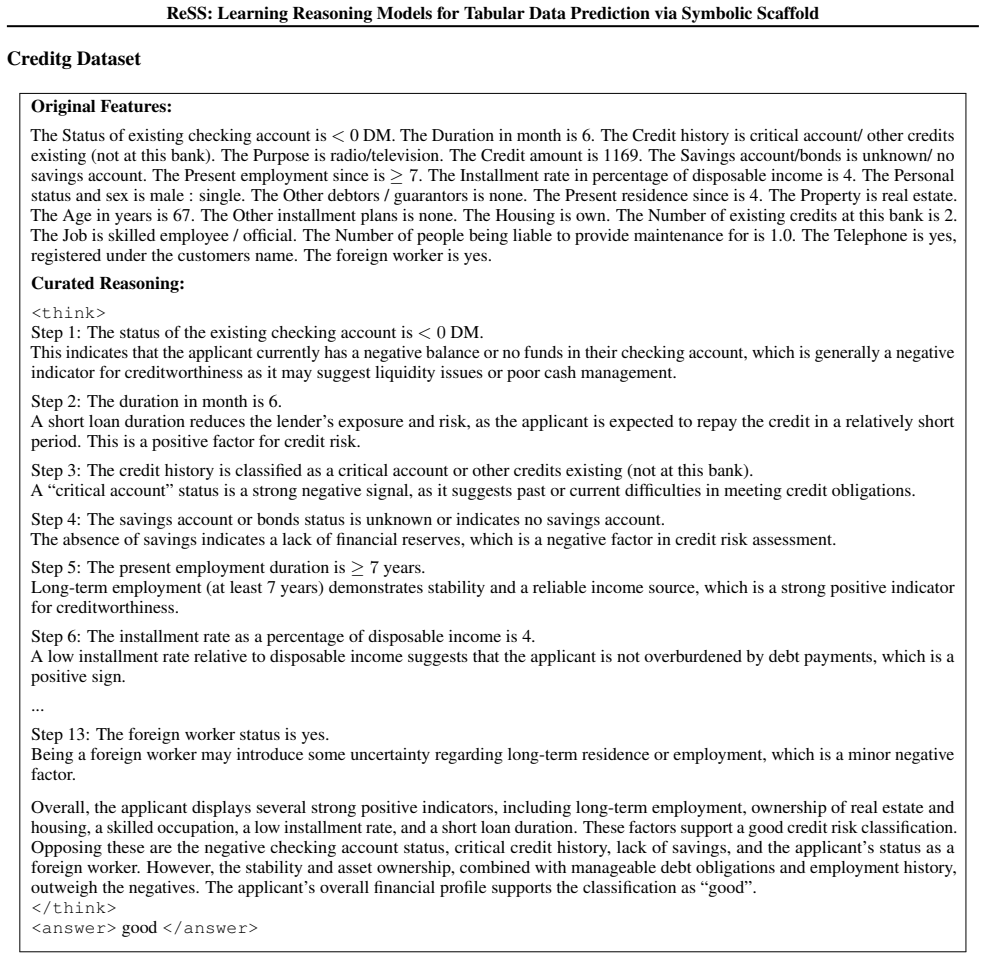
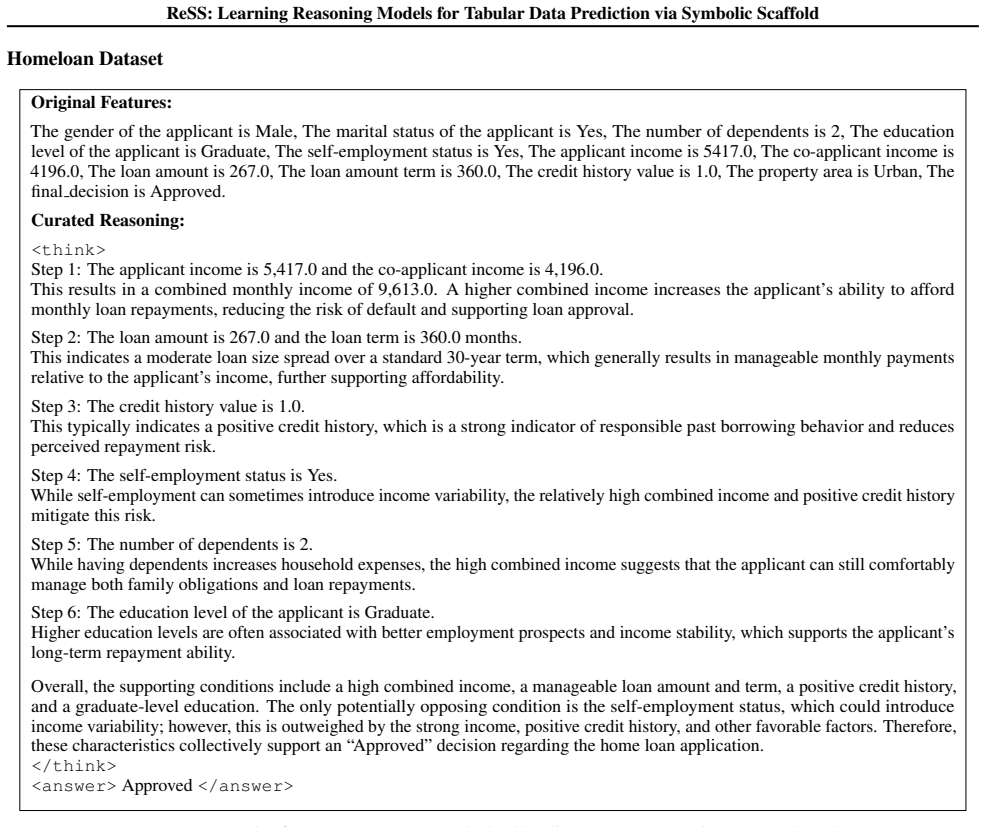
ReSS leverages decision-tree models to extract instance-level decision paths as symbolic scaffolds. These scaffolds guide an LLM to generate grounded natural-language reasoning that adheres to the decision logic. The resulting dataset fine-tunes a pretrained LLM into a tabular reasoning model, enhanced by scaffold-invariant augmentation. This produces models that improve accuracy up to 10% on medical and financial tasks compared to decision trees and standard fine-tuning, while ensuring faithful and consistent reasoning as measured by hallucination rate, explanation necessity, and explanation sufficiency.
What carries the argument
The symbolic scaffold, consisting of instance-level decision paths extracted from a decision tree, which guides an LLM to produce reasoning that strictly follows the tree's logic.
If this is right
- ReSS-trained models achieve up to 10% higher accuracy than traditional decision trees and standard fine-tuned LLMs on medical and financial benchmarks.
- The generated reasoning exhibits low hallucination rates and high scores on explanation necessity and sufficiency metrics.
- Scaffold-invariant data augmentation improves generalization and explainability of the fine-tuned models.
- The approach produces consistent reasoning that adheres exactly to the underlying decision logic.
Where Pith is reading between the lines
- This scaffolding approach could extend to other symbolic structures like rule lists for generating training data in structured prediction tasks.
- It suggests a route for making neural models on tabular data more robust to distribution shifts by anchoring them to extracted logic.
- Future applications might include using the scaffolds for debugging or editing model behavior by altering the source tree.
Load-bearing premise
That decision-tree paths extracted from the data can serve as sufficient scaffolds forcing an LLM to generate reasoning which is both logically faithful and semantically useful without introducing inconsistencies or losing predictive power.
What would settle it
A held-out test instance where the fine-tuned model produces a prediction that matches the tree but includes a reasoning step not present in the extracted decision path, or where accuracy on a new tabular benchmark drops below the original decision tree.
Figures













read the original abstract
Tabular data remains prevalent in high-stakes domains such as healthcare and finance, where predictive models are expected to provide both high accuracy and faithful, human-understandable reasoning. While symbolic models offer verifiable logic, they lack semantic expressiveness. Meanwhile, general-purpose LLMs often require specialized fine-tuning to master domain-specific tabular reasoning. To address the dual challenges of scalable data curation and reasoning consistency, we propose ReSS, a systematic framework that bridges symbolic and neural reasoning models. ReSS leverages a decision-tree model to extract instance-level decision paths as symbolic scaffolds. These scaffolds, alongside input features and labels, guide an LLM to generate grounded natural-language reasoning that strictly adheres to the underlying decision logic. The resulting high-quality dataset is used to fine-tune a pretrained LLM into a specialized tabular reasoning model, further enhanced by a scaffold-invariant data augmentation strategy to improve generalization and explainability. To rigorously assess faithfulness, we introduce quantitative metrics including hallucination rate, explanation necessity, and explanation sufficiency. Experimental results on medical and financial benchmarks demonstrate that ReSS-trained models improve traditional decision trees and standard fine-tuning approaches up to $10\%$ while producing faithful and consistent reasoning
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ReSS, a framework that fits a decision tree on tabular data, extracts instance-level decision paths as symbolic scaffolds, uses these (with features and labels) to prompt an LLM to generate grounded natural-language reasoning strictly adhering to the tree logic, augments the resulting dataset in a scaffold-invariant manner, and fine-tunes a pretrained LLM on it. Three new quantitative faithfulness metrics (hallucination rate, explanation necessity, explanation sufficiency) are introduced to evaluate the outputs. Experiments on medical and financial tabular benchmarks are claimed to show up to 10% accuracy gains over both the original decision trees and standard LLM fine-tuning while maintaining faithful reasoning.
Significance. If the empirical gains and the faithfulness metrics prove robust, the work would offer a concrete, scalable route to combine the verifiable logic of symbolic models with the semantic flexibility of LLMs for high-stakes tabular prediction, directly addressing the accuracy-interpretability tension in healthcare and finance.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): the central claim of up to 10% improvement over decision trees and standard fine-tuning is stated without any description of the benchmarks, baseline implementations, statistical tests, number of runs, or how the faithfulness metrics were operationalized and validated; these omissions make the empirical support for the framework unverifiable and load-bearing for the paper's contribution.
- [§3] §3 (ReSS framework): the assumption that instance-level decision-tree paths serve as scaffolds that are simultaneously restrictive enough to enforce logical faithfulness and permissive enough to allow semantically useful reasoning (and accuracy gains) is not accompanied by details on prompt construction, adherence enforcement during generation, or ablation studies showing that the scaffolds do not simply cause paraphrasing or introduce undetected inconsistencies; the three proposed metrics cannot be assessed for sufficiency without this information.
minor comments (1)
- [Abstract] The abstract and introduction would benefit from explicit definitions or equations for the three faithfulness metrics rather than only naming them.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify key areas where additional detail will improve verifiability and methodological transparency. We address each point below and commit to revisions that strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): the central claim of up to 10% improvement over decision trees and standard fine-tuning is stated without any description of the benchmarks, baseline implementations, statistical tests, number of runs, or how the faithfulness metrics were operationalized and validated; these omissions make the empirical support for the framework unverifiable and load-bearing for the paper's contribution.
Authors: We agree that the abstract and §4 require expanded description to make the empirical results verifiable. While the manuscript identifies the benchmarks as medical and financial tabular datasets and the baselines as decision trees plus standard LLM fine-tuning, explicit details on run counts, statistical tests, and metric definitions are insufficiently prominent. In revision we will (1) update the abstract to name the benchmark categories and note the 10% gain range, (2) add a dedicated experimental-setup paragraph in §4 listing number of runs (with seed variation), significance testing procedure, and precise operationalization of each faithfulness metric together with its validation protocol. These additions will directly address the verifiability concern. revision: yes
-
Referee: [§3] §3 (ReSS framework): the assumption that instance-level decision-tree paths serve as scaffolds that are simultaneously restrictive enough to enforce logical faithfulness and permissive enough to allow semantically useful reasoning (and accuracy gains) is not accompanied by details on prompt construction, adherence enforcement during generation, or ablation studies showing that the scaffolds do not simply cause paraphrasing or introduce undetected inconsistencies; the three proposed metrics cannot be assessed for sufficiency without this information.
Authors: The manuscript provides a high-level description of prompt construction in §3.2 and places the full template in the appendix, together with a post-generation consistency filter. However, we acknowledge that explicit ablation results and a more granular account of adherence enforcement are absent. In the revision we will expand §3 with the exact prompt template, the rule-based verifier used for adherence, and new ablation experiments that isolate the scaffold component (showing accuracy and hallucination changes when scaffolds are removed). These ablations will also serve as additional validation for the three faithfulness metrics, demonstrating that the scaffolds contribute measurable semantic value beyond paraphrasing. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a forward pipeline: fit a decision tree on tabular data, extract instance-level paths as scaffolds, use them to prompt an LLM for grounded reasoning text, curate a dataset, apply scaffold-invariant augmentation, fine-tune a pretrained LLM, and evaluate predictive accuracy plus new faithfulness metrics (hallucination rate, necessity, sufficiency) on medical/financial benchmarks. None of these steps reduce by construction to prior fitted quantities; the reported up-to-10% gains are empirical comparisons against baselines, the faithfulness metrics are defined separately from the training objective, and no load-bearing self-citation or uniqueness theorem is invoked in the provided text. The central claims therefore remain independently falsifiable on external test sets.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Decision trees produce instance-level paths that capture the essential decision logic for the tabular task.
- domain assumption An LLM prompted with a symbolic scaffold will produce natural-language text that strictly respects the tree logic.
invented entities (1)
-
ReSS framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Dnf-net: A neural architecture for tabular data, 2020
Abutbul, A., Elidan, G., Katzir, L., and El-Yaniv, R. Dnf-net: A neural architecture for tabular data, 2020. URL https://arxiv.org/abs/2006.06465
-
[3]
Arcuschin, I., Janiak, J., Krzyzanowski, R., Rajamanoharan, S., Nanda, N., and Conmy, A. Chain-of-thought reasoning in the wild is not always faithful, 2025. URL https://arxiv. org/abs/2503.08679, 2025
- [4]
-
[5]
Atanasova, P., Camburu, O.-M., Lioma, C., Lukasiewicz, T., Simonsen, J. G., and Augenstein, I. Faithfulness tests for natural language explanations. arXiv preprint arXiv:2305.18029, 2023
-
[6]
Chain-of-thought is not explainability
Barez, F., Wu, T.-Y., Arcuschin, I., Lan, M., Wang, V., Siegel, N., Collignon, N., Neo, C., Lee, I., Paren, A., et al. Chain-of-thought is not explainability. Preprint, alphaXiv, pp.\ v1, 2025
2025
-
[7]
S., Purohit, S., Reynolds, L., Tow, J., Wang, B., and Weinbach, S
Black, S., Biderman, S., Hallahan, E., Anthony, Q., Gao, L., Golding, L., He, H., Leahy, C., McDonell, K., Phang, J., Pieler, M., Prashanth, U. S., Purohit, S., Reynolds, L., Tow, J., Wang, B., and Weinbach, S. Gpt-neox-20b: An open-source autoregressive language model, 2022. URL https://arxiv.org/abs/2204.06745
-
[8]
Breiman, L. Random forests. Mach. Learn., 45 0 (1): 0 5–32, October 2001. ISSN 0885-6125. doi:10.1023/A:1010933404324. URL https://doi.org/10.1023/A:1010933404324
-
[9]
H., Olshen, R
Breiman, L., Friedman, J. H., Olshen, R. A., and Stone, C. J. Classification and Regression Trees. Wadsworth, 1984. ISBN 0-534-98053-8
1984
-
[10]
Tabr1: Taming grpo for tabular reasoning llms
Cai, P., Gao, Z., and Chen, J. Tabr1: Taming grpo for tabular reasoning llms. arXiv preprint arXiv:2510.17385, 2025
-
[11]
Xgboost: A scalable tree boosting system,
Chen, Tianqi, Guestrin, and Carlos. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’16, pp.\ 785–794. ACM, August 2016. doi:10.1145/2939672.2939785. URL http://dx.doi.org/10.1145/2939672.2939785
-
[12]
Scaling Instruction-Finetuned Language Models
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., Webson, A., Gu, S. S., Dai, Z., Suzgun, M., Chen, X., Chowdhery, A., Castro-Ros, A., Pellat, M., Robinson, K., Valter, D., Narang, S., Mishra, G., Yu, A., Zhao, V., Huang, Y., Dai, A., Yu, H., Petrov, S., Chi, E. H., Dean, J., Devlin, J., Roberts,...
work page internal anchor Pith review arXiv 2022
-
[13]
Diabetes 130-US Hospitals for Years 1999-2008
Clore, J., Cios, K., DeShazo, J., and Strack, B. Diabetes 130-US Hospitals for Years 1999-2008 . UCI Machine Learning Repository, 2014. DOI : 10.24432/C5230J
-
[14]
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks , publisher =
Dinh, T., Zeng, Y., Zhang, R., Lin, Z., Gira, M., Rajput, S., yong Sohn, J., Papailiopoulos, D., and Lee, K. Lift: Language-interfaced fine-tuning for non-language machine learning tasks, 2022. URL https://arxiv.org/abs/2206.06565
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Tabllm: Few-shot classification of tabular data with large language models, 2023
Hegselmann, S., Buendia, A., Lang, H., Agrawal, M., Jiang, X., and Sontag, D. Tabllm: Few-shot classification of tabular data with large language models, 2023. URL https://arxiv.org/abs/2210.10723
-
[17]
Tabpfn: A transformer that solves small tabu- lar classification problems in a second,
Hollmann, N., Müller, S., Eggensperger, K., and Hutter, F. Tabpfn: A transformer that solves small tabular classification problems in a second, 2023. URL https://arxiv.org/abs/2207.01848
-
[18]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Hu, J., Liu, J. K., Xu, H., and Shen, W. Reinforce++: Stabilizing critic-free policy optimization with global advantage normalization, 2025. URL https://arxiv.org/abs/2501.03262
work page internal anchor Pith review arXiv 2025
-
[19]
TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678,
Huang, X., Khetan, A., Cvitkovic, M., and Karnin, Z. Tabtransformer: Tabular data modeling using contextual embeddings, 2020. URL https://arxiv.org/abs/2012.06678
-
[20]
Kambhampati, S., Stechly, K., and Valmeekam, K. (how) do reasoning models reason? Annals of the New York Academy of Sciences, 1547 0 (1): 0 33--40, 2025. doi:https://doi.org/10.1111/nyas.15339. URL https://nyaspubs.onlinelibrary.wiley.com/doi/abs/10.1111/nyas.15339
-
[21]
Lightgbm: A highly efficient gradient boosting decision tree
Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., and Liu, T.-Y. Lightgbm: A highly efficient gradient boosting decision tree. In Guyon, I., Luxburg, U. V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017. URL https://...
2017
-
[22]
T., Kang, D., Moon, S., Lee, J
Kwon, T., iunn Ong, K. T., Kang, D., Moon, S., Lee, J. R., Hwang, D., Sim, Y., Sohn, B., Lee, D., and Yeo, J. Large language models are clinical reasoners: Reasoning-aware diagnosis framework with prompt-generated rationales, 2024. URL https://arxiv.org/abs/2312.07399
-
[23]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.), Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp.\ 1207--1216, Stanford, CA, 2000. Morgan Kaufmann
2000
-
[24]
Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T
Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T. Disco: Reinforcing large reasoning models with discriminative constrained optimization. arXiv preprint arXiv:2505.12366, 2025
-
[25]
Warwick Nash, Tracy Sellers, Simon Talbot, Andrew Cawthorn, and Wes Ford
Moro, S., Rita, P., and Cortez, P. Bank Marketing . UCI Machine Learning Repository, 2014. DOI : 10.24432/C5K306
-
[26]
arXiv preprint arXiv:2402.13950 , year=
Paul, D., West, R., Bosselut, A., and Faltings, B. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. arXiv preprint arXiv:2402.13950, 2024
-
[27]
Si, J., Cheng, W. Y., Cooper, M., and Krishnan, R. G. Interpretabnet: Distilling predictive signals from tabular data by salient feature interpretation. arXiv preprint arXiv:2406.00426, 2024
-
[28]
Slack, D. and Singh, S. Tablet: Learning from instructions for tabular data, 2023. URL https://arxiv.org/abs/2304.13188
-
[29]
Team, K., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting
Turpin, M., Michael, J., Perez, E., and Bowman, S. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. Advances in Neural Information Processing Systems, 36: 0 74952--74965, 2023
2023
-
[31]
Trl: Transformer reinforcement learning
von Werra, L., Belkada, Y., Tunstall, L., Beeching, E., Thrush, T., Lambert, N., Huang, S., Rasul, K., and Gallouédec, Q. Trl: Transformer reinforcement learning. https://github.com/huggingface/trl, 2020
2020
- [32]
-
[33]
H., Le, Q
Wei, J., Wang, X., Schuurmans, D., Bosma, M., brian ichter, Xia, F., Chi, E. H., Le, Q. V., and Zhou, D. Chain of thought prompting elicits reasoning in large language models. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=_VjQlMeSB_J
2022
-
[34]
U., van der Schaar, M., and Agius, R
Werling, M., Seedat, N., Liu, J., Gr nlykke, L., Niemann, C. U., van der Schaar, M., and Agius, R. Tables2traces: Distilling tabular data to improve llm reasoning in healthcare. In EurIPS 2025 Workshop: AI for Tabular Data, 2025
2025
-
[35]
Sub-task decomposition enables learning in sequence to sequence tasks
Wies, N., Levine, Y., and Shashua, A. Sub-task decomposition enables learning in sequence to sequence tasks. In International Conference on Learning Representations, 2023. URL https://openreview.net/pdf?id=BrJATVZDWEH
2023
-
[36]
K., Hajimirsadeghi, H., and Mori, G
Xu, T., Zhang, Z., Sun, X., Zung, L. K., Hajimirsadeghi, H., and Mori, G. Tabreason: A reinforcement learning-enhanced reasoning llm for explainable tabular data prediction. arXiv preprint arXiv:2505.21807, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.