Recognition: unknown
Classical Machine Learning Baselines for Deepfake Audio Detection on the Fake-or-Real Dataset
Pith reviewed 2026-05-10 12:22 UTC · model grok-4.3
The pith
RBF support vector machines using pitch and spectral features reach 93 percent accuracy detecting deepfake audio on short clips.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
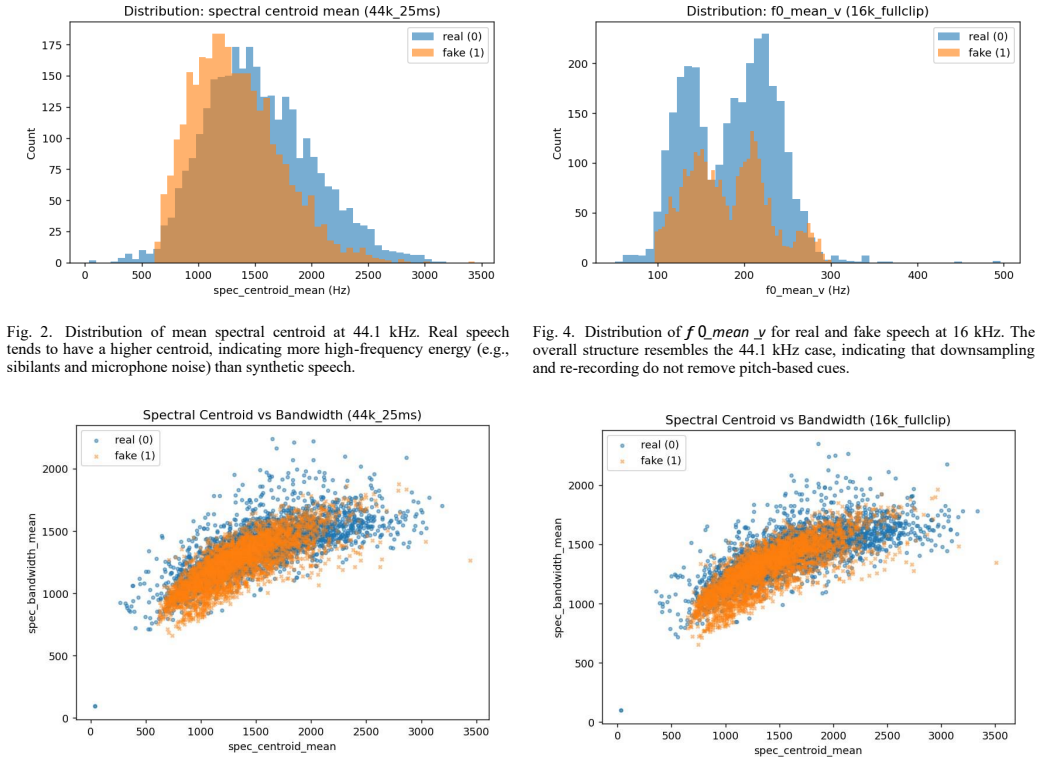
The paper claims that prosodic, voice-quality, and spectral features extracted from two-second audio clips allow classical classifiers to distinguish real from fake speech on the Fake-or-Real dataset, with an RBF support vector machine delivering approximately 93 percent accuracy and 7 percent EER at both 44.1 kHz and 16 kHz sampling rates while statistical tests identify pitch variability and spectral centroid and bandwidth as the primary discriminative cues.
What carries the argument
Extraction of prosodic pitch-related measures, voice-quality indicators, and spectral properties from fixed-length clips, followed by ANOVA-based identification of significant differences and training of multiple classical classifiers including logistic regression, LDA, QDA, naive Bayes, SVM variants, and GMMs.
If this is right
- The RBF SVM outperforms linear models by a wide margin and maintains performance across both high-fidelity and lower-quality sampling rates.
- Pitch variability together with spectral centroid and bandwidth emerge as the most useful cues for separating real from synthetic speech.
- Classical models supply transparent baselines that future deep-learning detectors can be benchmarked against using accuracy, EER, and DET curves.
- Pairwise statistical tests confirm that differences in performance among the tested classifiers are reliable rather than due to chance.
Where Pith is reading between the lines
- Lightweight models based on these features could support real-time detection on devices with limited computation.
- The same cues might be used to interpret which aspects of audio a neural detector has learned to rely on.
- Applying the identical feature set and model to deepfake audio produced by newer synthesis methods would test whether the cues generalize beyond the current dataset.
Load-bearing premise
The chosen prosodic, voice-quality, and spectral features extracted from two-second clips fully capture the reliable differences between real and synthetic speech in the Fake-or-Real dataset without missing critical cues or introducing dataset-specific biases.
What would settle it
Generating new synthetic speech that matches the pitch variability and spectral richness statistics of real speech closely enough that the same RBF SVM model drops to near 50 percent accuracy on an independent test set.
Figures



read the original abstract
Deep learning has enabled highly realistic synthetic speech, raising concerns about fraud, impersonation, and disinformation. Despite rapid progress in neural detectors, transparent baselines are needed to reveal which acoustic cues reliably separate real from synthetic speech. This paper presents an interpretable classical machine learning baseline for deepfake audio detection using the Fake-or-Real (FoR) dataset. We extract prosodic, voice-quality, and spectral features from two-second clips at 44.1 kHz (high-fidelity) and 16 kHz (telephone-quality) sampling rates. Statistical analysis (ANOVA, correlation heatmaps) identifies features that differ significantly between real and fake speech. We then train multiple classifiers -- Logistic Regression, LDA, QDA, Gaussian Naive Bayes, SVMs, and GMMs -- and evaluate performance using accuracy, ROC-AUC, EER, and DET curves. Pairwise McNemar's tests confirm statistically significant differences between models. The best model, an RBF SVM, achieves ~93% test accuracy and ~7% EER on both sampling rates, while linear models reach ~75% accuracy. Feature analysis reveals that pitch variability and spectral richness (spectral centroid, bandwidth) are key discriminative cues. These results provide a strong, interpretable baseline for future deepfake audio detectors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents classical machine learning baselines for deepfake audio detection on the Fake-or-Real (FoR) dataset. It extracts prosodic, voice-quality, and spectral features from two-second clips at 44.1 kHz and 16 kHz sampling rates, applies ANOVA and correlation analysis to identify discriminative features, trains classifiers including Logistic Regression, LDA, QDA, Gaussian Naive Bayes, SVMs, and GMMs, and evaluates them with accuracy, ROC-AUC, EER, DET curves, and McNemar's tests. The headline result is that an RBF SVM achieves ~93% test accuracy and ~7% EER on both sampling rates, with pitch variability and spectral richness (centroid, bandwidth) identified as key cues, while linear models reach ~75% accuracy.
Significance. If reproducible, this work supplies a transparent, interpretable baseline that can benchmark future deep learning detectors and clarify which acoustic properties separate real from synthetic speech in the FoR corpus. The multi-rate evaluation and statistical feature analysis are useful for interpretability in the audio forensics community.
major comments (2)
- [Methods / Experimental Setup] Methods section: The manuscript provides no information on the train-test split ratio or stratification, the hyperparameter search procedure (e.g., ranges or method for SVM C and gamma), or the exact settings used for feature extraction (frame length, hop size, pitch tracker, spectral parameters). These omissions render the reported ~93% accuracy and ~7% EER unreproducible and prevent verification of the central performance claims.
- [Results / Feature Analysis] Results / Feature Analysis: ANOVA and correlation heatmaps are used to flag pitch variability and spectral centroid/bandwidth as key cues, yet no ablation studies or cross-dataset evaluations on other deepfake corpora are reported. This leaves open the possibility that the discriminative power is tied to FoR-specific synthesis artifacts rather than generalizable real-vs-fake differences, weakening the claim that these features are broadly reliable cues.
minor comments (2)
- [Abstract] Abstract: Approximate symbols (~) are used for the headline accuracy and EER figures without accompanying exact values, standard deviations, or confidence intervals, reducing the precision of the reported results.
- [Figures] Figures: The correlation heatmaps and DET curves would benefit from clearer axis labels, legends, and captions that explicitly link the plotted quantities to the statistical tests described in the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which helps improve the clarity and reproducibility of our work. We address each major comment point by point below, outlining the revisions we will implement.
read point-by-point responses
-
Referee: [Methods / Experimental Setup] Methods section: The manuscript provides no information on the train-test split ratio or stratification, the hyperparameter search procedure (e.g., ranges or method for SVM C and gamma), or the exact settings used for feature extraction (frame length, hop size, pitch tracker, spectral parameters). These omissions render the reported ~93% accuracy and ~7% EER unreproducible and prevent verification of the central performance claims.
Authors: We agree that the current Methods section lacks sufficient detail for full reproducibility. In the revised manuscript, we will add a dedicated 'Experimental Setup' subsection specifying: an 80/20 train-test split stratified by class with no speaker overlap; hyperparameter search via grid search with 5-fold cross-validation on the training set (C in {0.1, 1, 10, 100}, gamma in {0.001, 0.01, 0.1, 1}); and precise feature extraction parameters including 25 ms frames with 10 ms hop, YIN pitch tracker, 512-point FFT, and standard Librosa defaults for spectral centroid/bandwidth. These additions will enable exact replication of the RBF SVM results. revision: yes
-
Referee: [Results / Feature Analysis] Results / Feature Analysis: ANOVA and correlation heatmaps are used to flag pitch variability and spectral centroid/bandwidth as key cues, yet no ablation studies or cross-dataset evaluations on other deepfake corpora are reported. This leaves open the possibility that the discriminative power is tied to FoR-specific synthesis artifacts rather than generalizable real-vs-fake differences, weakening the claim that these features are broadly reliable cues.
Authors: The manuscript is explicitly framed as an interpretable baseline for the FoR dataset and does not claim that the identified cues are universally reliable across all deepfake corpora. To strengthen the analysis within this scope, we will add ablation experiments in the revised Results section: we will retrain the RBF SVM after removing pitch variability and spectral features individually and jointly, reporting the resulting accuracy and EER drops to quantify their contribution on FoR. Cross-dataset evaluation is beyond the current scope (requiring new data curation and processing not available in this study); we will add a limitations paragraph acknowledging this and suggesting it for future work. This preserves the paper's focus while addressing the concern about FoR-specific artifacts. revision: partial
Circularity Check
No circularity: purely empirical baseline evaluation
full rationale
The paper performs standard feature extraction from the FoR dataset, applies ANOVA and correlation analysis, trains classifiers (including RBF SVM) on training splits, and reports direct test-set metrics such as accuracy and EER. No mathematical derivations, uniqueness theorems, ansatzes, or self-citations are invoked to justify load-bearing claims. All reported results are empirical outcomes on held-out data rather than quantities that reduce to fitted inputs or prior self-referential statements by construction. The study is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- SVM regularization and kernel parameters
- Feature extraction settings
axioms (2)
- domain assumption The FoR dataset contains representative examples of real and synthetic speech at the stated sampling rates.
- domain assumption The selected prosodic, voice-quality, and spectral features are sufficient to separate real from fake audio.
Reference graph
Works this paper leans on
-
[1]
WaveNet: A generative model for raw audio,
A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, and K. Kavukcuoglu, “WaveNet: A generative model for raw audio,” in Proc. 9th ISCA Speech Synthesis Workshop (SSW9), 2016
2016
-
[2]
Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. Skerrv -Ryan, R. A. Saurous, Y. Agiomvrgian - nakis, and Y. Wu, “Natural TTS synthesis by conditioning WaveNet on mel spectrogram predictions,” in Proc. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018, pp. 4779– 4783
2018
-
[3]
Fooled Twice: People Cannot Detect Deepfakes but Think They Can
J. Yi, C. Fu, R. Tao, Y. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, C. Bai, J. Fan, S. Liang, S. Wen, X. Xu, X. Ke, R. Huang, C. Shen, Y. Ren, and Z. Zhao, “Audio deepfake detection: A survey,” arXiv preprint arXiv:2308.14970, 2023
-
[4]
Deepfake audio detection via MFCC features using machine learning,
A. Hamza, A. R. Javed, F. Iqbal, N. Bitam, T. R. Gadekallu, A. Almo - mani, and Z. Jalil, “Deepfake audio detection via MFCC features using machine learning,” IEEE Access, vol. 10, pp. 134 018–134 028, 2022
2022
-
[5]
ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evans, and H. Delgado, “ASVspoof 2021: Accelerating progress in spoofed and deepfake speech detection,” in Proc. ASVspoof 2021 Workshop, 2021
2021
-
[6]
FoR: A dataset for synthetic speech detection,
R. Reimao and V. Tzerpos, “FoR: A dataset for synthetic speech detection,” in Proc. International Conference on Speech and Dialogue (SpeD), 2019, pp. 1–10
2019
-
[7]
The CMU Arctic speech databases,
J. Kominek and A. W. Black, “The CMU Arctic speech databases,” in Proc. 5th ISCA Speech Synthesis Workshop (SSW5), 2004, pp. 223–224
2004
-
[8]
The LJ speech dataset,
K. Ito and L. Johnson, “The LJ speech dataset,” https://keithito.com/ LJ-Speech-Dataset/, 2017
2017
-
[9]
Free speech recognition,
VoxForge, “Free speech recognition,” http://www.voxforge.org/, ac- cessed: 2024
2024
-
[10]
Descriptor: Voice pre-processing and quality assessment dataset (VPQAD),
A. Ahmed, M. J. A. Khondkar, A. Herrick, S. Schuckers, and M. H. Imtiaz, “Descriptor: Voice pre-processing and quality assessment dataset (VPQAD),” IEEE Data Descriptions, vol. 1, pp. 146–153, 2024
2024
-
[11]
YIN, a fundamental frequency estimator for speech and music,
A. de Cheveigne´ and H. Kawahara, “YIN, a fundamental frequency estimator for speech and music,” Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 2002
1917
-
[12]
I. R. Titze, Principles of Voice Production. Prentice Hall, 1994
1994
-
[13]
Quantifying the relationship between speech quality metrics and biometric speaker recognition performance under acoustic degradation,
A. Ahmed and M. H. Imtiaz, “Quantifying the relationship between speech quality metrics and biometric speaker recognition performance under acoustic degradation,” Signals, vol. 7, no. 1, p. 7, 2026
2026
-
[14]
Vocal acoustic analysis – jitter, shimmer and HNR,
J. P. Teixeira, C. Oliveira, and C. Lopes, “Vocal acoustic analysis – jitter, shimmer and HNR,” Procedia Technology, vol. 9, pp. 1112–1122, 2013
2013
-
[15]
C. M. Bishop, Pattern Recognition and Machine Learning . Springer, 2006
2006
-
[16]
The use of multiple measurements in taxonomic prob - lems,
R. A. Fisher, “The use of multiple measurements in taxonomic prob - lems,” Annals of Eugenics, vol. 7, pp. 179–188, 1936
1936
-
[17]
Support-vector networks,
C. Cortes and V. Vapnik, “Support-vector networks,” Machine Learning, vol. 20, no. 3, pp. 273–297, 1995
1995
-
[18]
Speaker verification using adapted Gaussian mixture models,
D. A. Reynolds, T. F. Quatieri, and R. B. Dunn, “Speaker verification using adapted Gaussian mixture models,” Digital Signal Processing , vol. 10, pp. 19–41, 2000
2000
-
[19]
An introduction to ROC analysis,
T. Fawcett, “An introduction to ROC analysis,” Pattern Recognition Letters, vol. 27, pp. 861–874, 2006
2006
-
[20]
ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu, X. Wang, M. Sahidullah, J. Patino, H. Delgado, T. Kinnunen, M. Todisco, J. Yamagishi, N. Evans, A. Nautsch, and K. A. Lee, “ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2507–2522, 2023
2021
-
[21]
Note on the sampling error of the difference between correlated proportions,
Q. McNemar, “Note on the sampling error of the difference between correlated proportions,” Psychometrika, vol. 12, pp. 153–157, 1947
1947
-
[22]
Approximate statistical tests for comparing supervised classification learning algorithms,
T. G. Dietterich, “Approximate statistical tests for comparing supervised classification learning algorithms,” Neural Computation , vol. 10, pp. 1895–1923, 1998
1923
-
[23]
Comparison of parametric repre - sentations for monosyllabic word recognition,
S. B. Davis and P. Mermelstein, “Comparison of parametric repre - sentations for monosyllabic word recognition,” IEEE Transactions on Acoustics, Speech, and Signal Processing , vol. 28, no. 4, pp. 357 –366, 1980
1980
-
[24]
Constant Q cepstral coef - ficients: A spoofing countermeasure,
M. Todisco, H. Delgado, and N. Evans, “Constant Q cepstral coef - ficients: A spoofing countermeasure,” Computer Speech & Language , vol. 45, pp. 516–535, 2017
2017
-
[25]
FakeAVCeleb: A novel audio-video multimodal deepfake dataset,
H. Khalid, S. Tariq, M. Kim, and S. S. Woo, “FakeAVCeleb: A novel audio-video multimodal deepfake dataset,” in NeurIPS Datasets and Benchmarks Track, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.