Recognition: unknown
Why Multimodal In-Context Learning Lags Behind? Unveiling the Inner Mechanisms and Bottlenecks
Pith reviewed 2026-05-10 13:38 UTC · model grok-4.3
The pith
Multimodal in-context learning matches text-only performance in zero-shot settings but degrades sharply with few-shot demonstrations because models fail to build and transfer aligned task mappings across vision and language.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
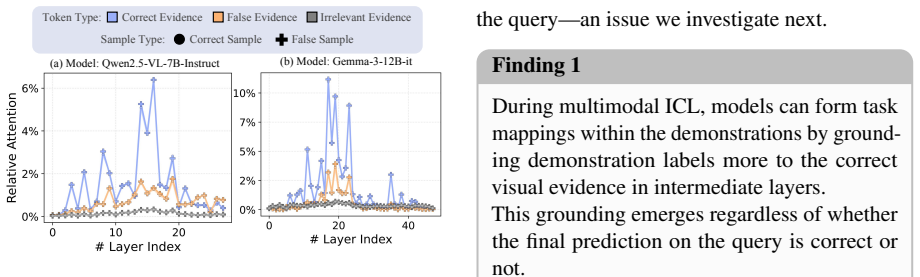
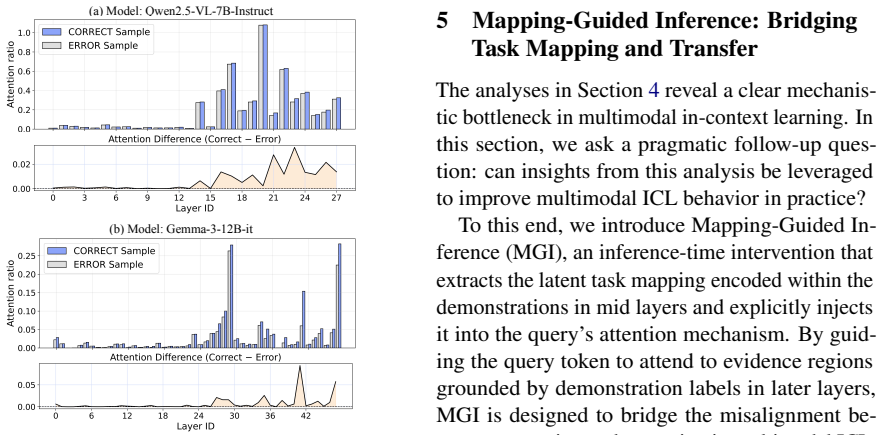
Using identical task formulations across modalities, multimodal ICL performs comparably to text-only ICL in zero-shot settings but degrades significantly under few-shot demonstrations. The models lack reasoning-level alignment between visual and textual representations and fail to reliably transfer learned task mappings to queries. Guided by this layer-wise decomposition into task mapping construction and task mapping transfer, a simple inference-stage enhancement that reinforces the transfer step improves results.
What carries the argument
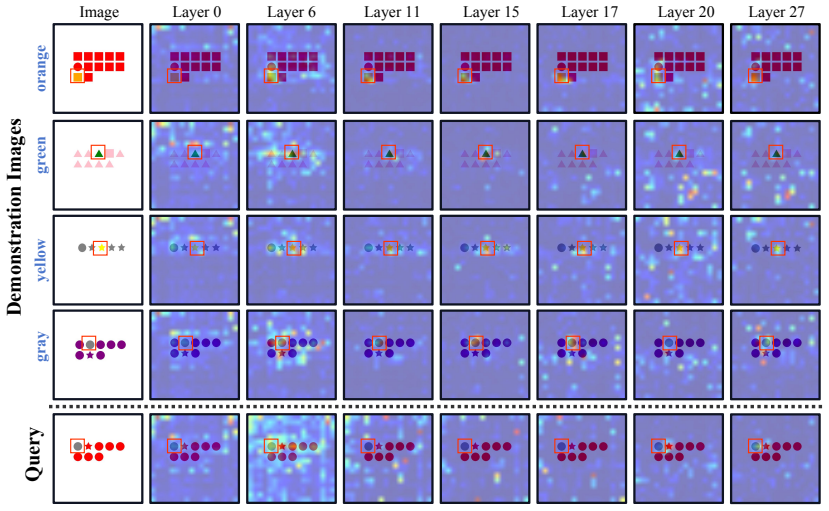
The decomposition of multimodal ICL into task mapping construction (building the mapping from demonstrations) and task mapping transfer (applying it to the query), tracked across model layers.
If this is right
- The performance gap appears only when demonstrations are supplied and is absent in pure zero-shot use.
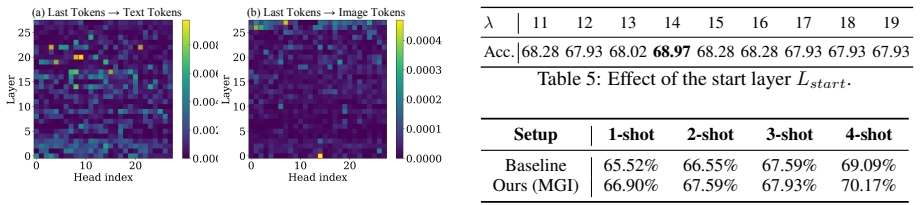
- A lightweight inference-time intervention that strengthens task mapping transfer measurably reduces the degradation without retraining.
- Current models succeed at zero-shot multimodal adaptation but cannot yet leverage example-based adaptation as effectively as text-only models.
- Layer-wise inspection reveals that the transfer failure occurs after the construction stage, pinpointing where cross-modal information is lost.
Where Pith is reading between the lines
- Future pretraining could add explicit objectives that force visual and textual reasoning representations to occupy a shared space, potentially closing the few-shot gap at the source.
- The same construction-versus-transfer lens could be applied to other multimodal adaptation regimes such as retrieval-augmented generation or chain-of-thought prompting with images.
- If the transfer bottleneck is modality-specific, audio-language or video-language models may exhibit analogous few-shot drops that the same analysis would detect.
Load-bearing premise
The proposed split into task mapping construction and task mapping transfer, together with the layer-wise measurements, correctly isolates the true internal cause of the multimodal ICL gap rather than a side effect.
What would settle it
Train or fine-tune a multimodal model with an auxiliary objective that explicitly aligns reasoning-level features between vision and language on the same tasks, then measure whether the few-shot ICL degradation disappears while zero-shot performance stays unchanged.
Figures






read the original abstract
In-context learning (ICL) enables models to adapt to new tasks via inference-time demonstrations. Despite its success in large language models, the extension of ICL to multimodal settings remains poorly understood in terms of its internal mechanisms and how it differs from text-only ICL. In this work, we conduct a systematic analysis of ICL in multimodal large language models. Using identical task formulations across modalities, we show that multimodal ICL performs comparably to text-only ICL in zero-shot settings but degrades significantly under few-shot demonstrations. To understand this gap, we decompose multimodal ICL into task mapping construction and task mapping transfer, and analyze how models establish cross-modal task mappings, and transfer them to query samples across layers. Our analysis reveals that current models lack reasoning-level alignment between visual and textual representations, and fail to reliably transfer learned task mappings to queries. Guided by these findings, we further propose a simple inference-stage enhancement method that reinforces task mapping transfer. Our results provide new insights into the mechanisms and limitations of multimodal ICL and suggest directions for more effective multimodal adaptation. Our code is available \href{https://github.com/deeplearning-wisc/Multimocal-ICL-Analysis-Framework-MGI}{here}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that multimodal ICL in MLLMs matches text-only ICL in zero-shot settings but degrades markedly with few-shot demonstrations. It decomposes multimodal ICL into task-mapping construction (from demonstrations) and task-mapping transfer (to queries), then uses layer-wise activation and similarity analyses to attribute the gap to missing reasoning-level cross-modal alignment and unreliable transfer. Guided by these observations, the authors propose a simple inference-stage enhancement to reinforce transfer and release an analysis framework.
Significance. If the empirical patterns and decomposition hold under scrutiny, the work supplies concrete mechanistic hypotheses for why multimodal ICL underperforms and a lightweight practical fix, together with reproducible code. These elements could usefully inform both model architecture choices and future causal studies of cross-modal ICL.
major comments (2)
- [Layer-wise analysis and task-mapping decomposition (Sections 4–5)] The central attribution of the few-shot degradation to insufficient reasoning-level alignment rests on layer-wise similarity metrics and activation patterns without causal interventions (e.g., representation editing, targeted layer ablation, or counterfactual prompting). This makes it difficult to distinguish whether the reported alignment/transfer failures are causal mechanisms or downstream correlates of modality-specific tokenization and attention.
- [Experimental setup and results (Section 3)] The claim that multimodal ICL 'degrades significantly' under few-shot demonstrations is presented as robust, yet the manuscript provides no details on data splits, number of runs, or statistical tests for the zero-shot vs. few-shot gap; without these, it is unclear whether the observed difference is load-bearing or sensitive to post-hoc choices.
minor comments (2)
- The abstract states that 'identical task formulations across modalities' are used, but the precise construction of visual versus textual demonstrations (token counts, prompt templates, image preprocessing) is not summarized in the main text; a short table or paragraph would improve clarity.
- Figure captions for the layer-wise plots should explicitly state the similarity metric (e.g., cosine, CCA) and whether shaded regions represent standard error across tasks or seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of our experimental details and to clarify the scope of our mechanistic claims.
read point-by-point responses
-
Referee: [Layer-wise analysis and task-mapping decomposition (Sections 4–5)] The central attribution of the few-shot degradation to insufficient reasoning-level alignment rests on layer-wise similarity metrics and activation patterns without causal interventions (e.g., representation editing, targeted layer ablation, or counterfactual prompting). This makes it difficult to distinguish whether the reported alignment/transfer failures are causal mechanisms or downstream correlates of modality-specific tokenization and attention.
Authors: We agree that our layer-wise analyses rely on observational metrics (activation patterns and similarity scores) rather than causal interventions, and therefore cannot definitively establish that the observed alignment and transfer failures are the direct causal drivers of the performance gap rather than correlates of tokenization or attention differences. The patterns we report are consistent across multiple models, tasks, and layers, which supports our hypotheses, but we acknowledge the correlational nature of the evidence. In the revised manuscript we have added an explicit limitations paragraph in the discussion section noting this point and outlining how future work could employ representation editing or targeted ablations to test causality. We have also softened the language in Sections 4–5 from “attribution” to “consistent evidence supporting the hypothesis that...” to avoid overclaiming. revision: partial
-
Referee: [Experimental setup and results (Section 3)] The claim that multimodal ICL 'degrades significantly' under few-shot demonstrations is presented as robust, yet the manuscript provides no details on data splits, number of runs, or statistical tests for the zero-shot vs. few-shot gap; without these, it is unclear whether the observed difference is load-bearing or sensitive to post-hoc choices.
Authors: We appreciate this observation. The original manuscript did not report these experimental controls. We have now expanded Section 3 and the appendix with: (i) explicit descriptions of the data splits and task sampling procedure, (ii) results averaged over five independent runs using different random seeds for demonstration selection, and (iii) paired t-test results showing that the zero-shot to few-shot degradation is statistically significant (p < 0.01) across all evaluated settings. These additions confirm that the reported gap is not sensitive to the particular choices described in the paper. revision: yes
Circularity Check
No circularity: empirical decomposition and layer-wise measurements are independent of fitted inputs or self-referential definitions
full rationale
The paper's core contribution is an empirical analysis of multimodal ICL performance gaps, using identical task formulations to compare zero-shot vs. few-shot behavior, followed by a decomposition into task mapping construction and transfer that is then measured via layer-wise activations and similarity metrics. No equations, parameter fits, or predictions are described that reduce to the inputs by construction. The proposed inference-stage enhancement is presented as a direct consequence of the observed measurements rather than a renamed fit. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, and 8 others. 2025. https://arxiv.org/abs/2502.13923 Qwen2.5-vl technical report . Preprint, arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Folco Bertini Baldassini, Mustafa Shukor, Matthieu Cord, Laure Soulier, and Benjamin Piwowarski. 2024. What makes multimodal in-context learning work? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1539--1550
2024
- [4]
- [5]
- [6]
-
[7]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, and 1 others. 2024 b . Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185--24198
2024
- [8]
-
[9]
Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. 2023. https://arxiv.org/abs/2212.10559 Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers . In ICLR 2023 Workshop on Mathematical and Empirical Understanding of Foundation Models
- [10]
- [11]
-
[12]
Jun Gao, Qian Qiao, Tianxiang Wu, Zili Wang, Ziqiang Cao, and Wenjie Li. 2025. Aim: Let any multimodal large language models embrace efficient in-context learning. In Proceedings of the AAAI Conference on Artificial Intelligence, number 3 in 39, pages 3077--3085
2025
- [13]
-
[14]
Xiaochuang Han, Daniel Simig, Todor Mihaylov, Yulia Tsvetkov, Asli Celikyilmaz, and Tianlu Wang. 2023 b . https://arxiv.org/abs/2306.15091 Understanding in-context learning via supportive pretraining data . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12660--12673
-
[15]
Brandon Huang, Chancharik Mitra, Assaf Arbelle, Leonid Karlinsky, Trevor Darrell, and Roei Herzig. 2024. Multimodal task vectors enable many-shot multimodal in-context learning. Advances in Neural Information Processing Systems, 37:22124--22153
2024
- [16]
- [17]
- [18]
- [19]
- [20]
-
[21]
Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. 2023 b . Otter: A multi-modal model with in-context instruction tuning. arXiv preprint arXiv:2305.03726
work page internal anchor Pith review arXiv 2023
- [22]
- [23]
- [24]
-
[25]
Yanshu Li, Jianjiang Yang, Ziteng Yang, Bozheng Li, Hongyang He, Zhengtao Yao, Ligong Han, Yingjie Victor Chen, Songlin Fei, Dongfang Liu, and Ruixiang Tang. 2025 b . https://arxiv.org/abs/2505.17097 Cama: Enhancing multimodal in-context learning with context-aware modulated attention . Preprint, arXiv:2505.17097
- [26]
-
[27]
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. 2024. https://llava-vl.github.io/blog/2024-01-30-llava-next/ Llava-next: Improved reasoning, ocr, and world knowledge
2024
-
[28]
Zhining Liu, Ziyi Chen, Hui Liu, Chen Luo, Xianfeng Tang, Suhang Wang, Joy Zeng, Zhenwei Dai, Zhan Shi, Tianxin Wei, Benoit Dumoulin, and Hanghang Tong. 2025. https://arxiv.org/abs/2510.17771 Seeing but not believing: Probing the disconnect between visual attention and answer correctness in vlms . Preprint, arXiv:2510.17771
- [29]
-
[30]
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Conference on Computer Vision and Pattern Recognition (CVPR)
2019
- [31]
- [32]
- [33]
- [35]
- [36]
-
[37]
Aaditya K Singh, Ted Moskovitz, Felix Hill, Stephanie CY Chan, and Andrew M Saxe. 2024 b . https://arxiv.org/abs/2404.07129 What needs to go right for an induction head? a mechanistic study of in-context learning circuits and their formation . In Forty-first International Conference on Machine Learning
-
[38]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, and 197 others. 2025. https://arxiv.org/abs/2503.19786...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Lean Wang, Lei Li, Damai Dai, Deli Chen, Hao Zhou, Fandong Meng, Jie Zhou, and Xu Sun. 2023. https://arxiv.org/abs/2305.14160 Label words are anchors: An information flow perspective for understanding in-context learning . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9840--9855
- [40]
- [41]
- [42]
-
[43]
Xu Yang, Yongliang Wu, Mingzhuo Yang, Haokun Chen, and Xin Geng. 2024. Exploring diverse in-context configurations for image captioning. Advances in Neural Information Processing Systems, 36
2024
- [44]
-
[45]
Yuanhan Zhang, Kaiyang Zhou, and Ziwei Liu. 2023 b . What makes good examples for visual in-context learning? Advances in Neural Information Processing Systems, 36:17773--17794
2023
- [46]
- [47]
-
[48]
Yuxiang Zhou, Jiazheng Li, Yanzheng Xiang, Hanqi Yan, Lin Gui, and Yulan He. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.795 The mystery of in-context learning: A comprehensive survey on interpretation and analysis . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 14365--14378, Miami, Florida, USA. As...
- [49]
-
[50]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[51]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.