Recognition: unknown
VibeFlow: Versatile Video Chroma-Lux Editing through Self-Supervised Learning
Pith reviewed 2026-05-10 13:11 UTC · model grok-4.3
The pith
Pre-trained video generators can be adapted via self-supervised perturbations to edit color and lighting in videos without any paired training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
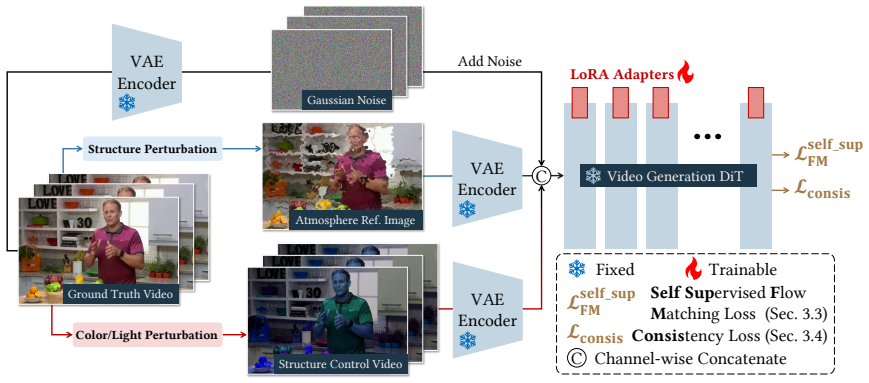
VibeFlow shows that a disentangled data perturbation pipeline on pre-trained video generation models can force adaptive recombination of structure from source videos with color-illumination cues from reference images, producing robust self-supervised disentanglement for chroma-lux editing. Residual Velocity Fields correct discretization errors in flow-based models while Structural Distortion Consistency Regularization enforces structural preservation and temporal coherence, allowing the system to generalize zero-shot across multiple editing tasks without task-specific training or paired data.
What carries the argument
The disentangled data perturbation pipeline, which separates and recombines structure from the source video with color-illumination cues from reference images.
If this is right
- The same trained system works zero-shot on video relighting, recoloring, low-light enhancement, day-night translation, and object-specific color editing.
- Computational cost drops sharply because no new supervised training or synthetic paired datasets are needed.
- Structural and temporal fidelity are maintained through the added Residual Velocity Fields and consistency regularization.
- Visual quality remains high while overhead is reduced compared with fully supervised alternatives.
Where Pith is reading between the lines
- The approach implies that other pre-trained generative models may hold similar latent physical knowledge that could be unlocked with comparable self-supervised pipelines.
- Because training resources are no longer required, the method could lower the barrier for smaller teams or individual creators to experiment with video editing tools.
- The zero-shot property suggests the framework might extend to new editing tasks beyond those demonstrated, provided suitable reference images are supplied.
Load-bearing premise
Pre-trained video generation models already contain an intrinsic, separable understanding of physical illumination and color that a self-supervised perturbation pipeline can reliably extract and recombine.
What would settle it
Videos edited with the method would show visible structural warping, flickering, or loss of fine detail in scenes with fast motion or complex lighting, or the outputs would fail to match the reference color and light when tested on diverse unseen references.
Figures










read the original abstract
Video chroma-lux editing, which aims to modify illumination and color while preserving structural and temporal fidelity, remains a significant challenge. Existing methods typically rely on expensive supervised training with synthetic paired data. This paper proposes VibeFlow, a novel self-supervised framework that unleashes the intrinsic physical understanding of pre-trained video generation models. Instead of learning color and light transitions from scratch, we introduce a disentangled data perturbation pipeline that enforces the model to adaptively recombine structure from source videos and color-illumination cues from reference images, enabling robust disentanglement in a self-supervised manner. Furthermore, to rectify discretization errors inherent in flow-based models, we introduce Residual Velocity Fields alongside a Structural Distortion Consistency Regularization, ensuring rigorous structural preservation and temporal coherence. Our framework eliminates the need for costly training resources and generalizes in a zero-shot manner to diverse applications, including video relighting, recoloring, low-light enhancement, day-night translation, and object-specific color editing. Extensive experiments demonstrate that VibeFlow achieves impressive visual quality with significantly reduced computational overhead. Our project is publicly available at https://lyf1212.github.io/VibeFlow-webpage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VibeFlow, a self-supervised framework for video chroma-lux editing that leverages pre-trained video generation models via a disentangled data perturbation pipeline. This pipeline recombines structure from source videos with color-illumination cues from reference images, while introducing Residual Velocity Fields and Structural Distortion Consistency Regularization to mitigate discretization errors in flow-based models and ensure structural/temporal fidelity. The work claims zero-shot generalization to tasks including relighting, recoloring, low-light enhancement, day-night translation, and object-specific editing, without requiring expensive supervised training on paired synthetic data.
Significance. If the central claims hold, the work would be significant for video editing and generative modeling by showing how frozen pre-trained models can be adapted self-supervisedly for physical attribute manipulation, substantially lowering the barrier of paired data collection and training compute. The specific regularization terms target a known limitation in flow-based video models.
major comments (3)
- [Abstract] Abstract: the claim that the framework 'unleashes the intrinsic physical understanding' of pre-trained models and achieves zero-shot generalization to diverse tasks is asserted without any quantitative metrics, ablation studies, error bars, or baseline comparisons, which is load-bearing for the central claim of effectiveness and reduced training resources.
- [Method] Method description (perturbation pipeline): no explicit loss term, architectural constraint, or auxiliary objective is described that enforces disentanglement between structure and color-illumination factors; training reduces to reconstruction of the recombined target, so success may rely on dataset shortcuts rather than verified access to independent physical factors in the frozen latents.
- [Experiments] Experiments section: the contributions of Residual Velocity Fields and Structural Distortion Consistency Regularization are presented as rectifying discretization errors, but without ablations isolating their impact on structural preservation or temporal coherence, it is impossible to assess whether they are load-bearing or merely incremental.
minor comments (2)
- [Abstract] The term 'chroma-lux editing' is used without a formal definition or citation to prior literature establishing the scope of the problem.
- [Abstract] The project webpage link is provided but no details on released code, models, or evaluation protocols are given in the manuscript, limiting reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications where the manuscript already contains supporting material and outlining revisions where additional evidence or discussion will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'unleashes the intrinsic physical understanding' of pre-trained models and achieves zero-shot generalization to diverse tasks is asserted without any quantitative metrics, ablation studies, error bars, or baseline comparisons, which is load-bearing for the central claim of effectiveness and reduced training resources.
Authors: The abstract summarizes the core claims, while the full manuscript (Section 4) presents extensive qualitative results across five tasks, visual comparisons against existing methods, and demonstrations of zero-shot performance without paired training data. We agree that stronger referencing to the experimental evidence would improve the abstract. In the revision we will add a concise sentence directing readers to the quantitative user studies, perceptual metrics, and baseline comparisons reported in the experiments, along with a note on the absence of paired-data training. revision: yes
-
Referee: [Method] Method description (perturbation pipeline): no explicit loss term, architectural constraint, or auxiliary objective is described that enforces disentanglement between structure and color-illumination factors; training reduces to reconstruction of the recombined target, so success may rely on dataset shortcuts rather than verified access to independent physical factors in the frozen latents.
Authors: The disentanglement arises from the explicit construction of the training targets: each target is formed by taking structure exclusively from the source video and color-illumination exclusively from the reference image. Because the frozen video model must reconstruct this recombined input, it is incentivized to route the two factors through separate pathways in its latent space. We will expand the method section with a dedicated paragraph and accompanying diagram that formalizes this inductive bias and includes feature visualizations showing separation of structure and appearance cues. While an auxiliary loss could be added, the current design already avoids trivial shortcuts by construction. revision: partial
-
Referee: [Experiments] Experiments section: the contributions of Residual Velocity Fields and Structural Distortion Consistency Regularization are presented as rectifying discretization errors, but without ablations isolating their impact on structural preservation or temporal coherence, it is impossible to assess whether they are load-bearing or merely incremental.
Authors: We acknowledge that the current ablation table does not fully isolate the two proposed components. In the revised manuscript we will add a dedicated ablation study that reports variants with and without Residual Velocity Fields and with and without the Structural Distortion Consistency Regularization. The new table will include quantitative measures of structural fidelity (edge preservation, landmark consistency) and temporal coherence (flow warping error, frame-to-frame consistency scores) together with standard deviations across multiple sequences. revision: yes
Circularity Check
No significant circularity; derivation relies on explicit pipeline design and experimental validation
full rationale
The paper introduces a disentangled perturbation pipeline that constructs training pairs by separating structure (from source video) and color-illumination (from reference), then trains the model via reconstruction on the recombined target. This separation is an explicit input construction rather than a derived or fitted result, and the zero-shot applications follow directly from using the adapted model with new references. No equations, self-citations, or fitted parameters are presented that reduce the central claims (disentanglement or generalization) to definitional equivalence with the inputs. The assumption of intrinsic understanding in the pre-trained model is a modeling premise, not a load-bearing reduction shown by the paper's own logic. The framework is therefore self-contained against its stated objectives.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained video generation models encode disentangleable physical cues for structure, color, and illumination that can be accessed without supervision.
invented entities (2)
-
Residual Velocity Fields
no independent evidence
-
Structural Distortion Consistency Regularization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2511.06271 , year=
[Bianet al., 2025] Weikang Bian, Xiaoyu Shi, Zhaoyang Huang, Jianhong Bai, Qinghe Wang, Xintao Wang, Pengfei Wan, Kun Gai, and Hongsheng Li. RelightMas- ter: Precise video relighting with multi-plane light images. arXiv:2511.06271,
-
[2]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
[Blattmannet al., 2023a] Andreas Blattmann, Tim Dock- horn, Sumith Kulal, Daniel Mendelevitch, Maciej Kil- ian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv:2311.15127,
work page internal anchor Pith review arXiv
-
[3]
Emerging properties in self-supervised vi- sion transformers
[Caronet al., 2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vi- sion transformers. InProc. Int’l Conf. Computer Vision,
2021
-
[4]
L-C4: Language- based video colorization for creative and consistent color
[Changet al., 2024] Zheng Chang, Shuchen Weng, Huan Ouyang, Yu Li, Si Li, and Boxin Shi. L-C4: Language- based video colorization for creative and consistent color. arXiv:2410.04972,
-
[5]
PerTouch: Vlm-driven agent for personalized and semantic image retouching
[Changet al., 2026] Zewei Chang, Zheng-Peng Duan, Jianxing Zhang, Chun-Le Guo, Siyu Liu, Hyungju Chun, Hyunhee Park, Zikun Liu, and Chongyi Li. PerTouch: Vlm-driven agent for personalized and semantic image retouching. InProc. AAAI Conference of Artifical Intelligence,
2026
-
[6]
VINO: A uni- fied visual generator with interleaved omnimodal context
[Chenet al., 2026] Junyi Chen, Tong He, Zhoujie Fu, Pengfei Wan, Kun Gai, and Weicai Ye. VINO: A uni- fied visual generator with interleaved omnimodal context. arXiv:2601.02358,
-
[7]
Scaling rectified flow transformers for high- resolution image synthesis
[Esseret al., 2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boe- sel, et al. Scaling rectified flow transformers for high- resolution image synthesis. InProc. IEEE Int’l Conf. Ma- chine Learning,
2024
-
[8]
arXiv preprint arXiv:2501.16330 (2025)
[Fanget al., 2025] Ye Fang, Zeyi Sun, Shangzhan Zhang, Tong Wu, Yinghao Xu, Pan Zhang, Jiaqi Wang, Gordon Wetzstein, and Dahua Lin. RelightVid: Temporal-consistent diffusion model for video relighting. arXiv:2501.16330,
-
[9]
[Gaoet al., 2025a] Wenshuo Gao, Junyi Fan, Jiangyue Zeng, and Shuai Yang. FlowPortal: Residual-corrected flow for training-free video relighting and background replace- ment.arXiv: 2511.18346,
-
[10]
TokenFlow: Consistent diffu- sion features for consistent video editing.Proc
[Geyeret al., 2024] Michal Geyer, Omer Bar-Tal, Shai Bagon, and Tali Dekel. TokenFlow: Consistent diffu- sion features for consistent video editing.Proc. Int’l Conf. Learning Representations,
2024
-
[11]
Nano banana,
[Google, 2025] Google. Nano banana,
2025
-
[12]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
https://aistudio. google.com/models/gemini-2-5-flash-image. [Guoet al., 2023] Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. AnimateDiff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv:2307.04725,
work page internal anchor Pith review arXiv 2023
-
[13]
Denoising diffusion probabilistic models
[Hoet al., 2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems,
2020
-
[14]
LoRA: Low-rank adaptation of large language models
[Huet al., 2022] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InProc. Int’l Conf. Learning Represen- tations,
2022
-
[15]
VBench: Comprehensive benchmark suite for video gen- erative models
[Huanget al., 2024] Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. VBench: Comprehensive benchmark suite for video gen- erative models. InProc. IEEE Int’l Conf. Computer Vision and Pattern Recognition,
2024
-
[16]
QuadPrior++: Multi-dimension augmented physical prior for zero-reference illumination enhancement.IEEE Trans- actions on Pattern Analysis and Machine Intelligence,
[Huanget al., 2025] Haofeng Huang, Yifan Li, Wenjing Wang, Wenhan Yang, Ling Yu Duan, and Jiaying Liu. QuadPrior++: Multi-dimension augmented physical prior for zero-reference illumination enhancement.IEEE Trans- actions on Pattern Analysis and Machine Intelligence,
2025
-
[17]
DeepRemaster: Temporal source-reference attention net- works for comprehensive video enhancement.ACM Trans- actions on Graphics, 38(6):1–13,
[Iizukaet al., 2019] Satoshi Iizuka and Edgar Simo-Serra. DeepRemaster: Temporal source-reference attention net- works for comprehensive video enhancement.ACM Trans- actions on Graphics, 38(6):1–13,
2019
-
[18]
Vace: All-in-one video creation and editing.arXiv preprint arXiv:2503.07598, 2025
[Jianget al., 2025] Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. V ACE: All-in-one video creation and editing.arXiv:2503.07598,
-
[19]
Taming flow-based i2v models for creative video editing.arXiv:2509.21917,
[Konget al., 2025] Xianghao Kong, Hansheng Chen, Yuwei Guo, Lvmin Zhang, Gordon Wetzstein, Maneesh Agrawala, and Anyi Rao. Taming flow-based i2v models for creative video editing.arXiv:2509.21917,
-
[20]
[Kuet al., 2024] Max Ku, Cong Wei, Weiming Ren, Harry Yang, and Wenhu Chen. AnyV2V: A tuning- free framework for any video-to-video editing tasks. arXiv:2403.14468,
-
[21]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
[Labs, 2025] Black Forest Labs. FLUX.1 Kontext: Flow matching for in-context image generation and editing in latent space.arXiv: 2506.15742,
work page internal anchor Pith review arXiv 2025
-
[22]
COCO-LC: Colorfulness controllable language- based colorization
[Liet al., 2024] Yifan Li, Yuhang Bai, Shuai Yang, and Jiay- ing Liu. COCO-LC: Colorfulness controllable language- based colorization. InProc. ACM Int’l Conf. Multimedia,
2024
-
[23]
Control color: Multimodal diffusion-based interactive image coloriza- tion.arXiv:2402.10855,
[Lianget al., 2024] Zhexin Liang, Zhaochen Li, Shangchen Zhou, Chongyi Li, and Chen Change Loy. Control color: Multimodal diffusion-based interactive image coloriza- tion.arXiv:2402.10855,
-
[24]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
[Liuet al., 2022] Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and trans- fer data with rectified flow.arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[25]
UniLumos: Fast and unified im- age and video relighting with physics-plausible feedback
[Liuet al., 2025a] Ropeway Liu, Hangjie Yuan, Bo Dong, Jiazheng Xing, Jinwang Wang, Rui Zhao, Yan Xing, Wei- hua Chen, and Fan Wang. UniLumos: Fast and unified im- age and video relighting with physics-plausible feedback. arXiv:2511.01678,
-
[26]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
[Nanet al., 2024] Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high- quality dataset for text-to-video generation.arXiv preprint arXiv:2407.02371,
work page internal anchor Pith review arXiv 2024
-
[27]
Perazzi, J
[Perazziet al., 2016] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine- Hornung. A benchmark dataset and evaluation method- ology for video object segmentation. InProc. IEEE Int’l Conf. Computer Vision and Pattern Recognition,
2016
-
[28]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
[Podellet al., 2023] Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. SDXL: Improving la- tent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review arXiv 2023
-
[29]
[Qwen, 2025] Team Qwen. Qwen-image technical report. arXiv: 2508.02324,
work page internal anchor Pith review arXiv 2025
-
[30]
Learning transferable visual models from nat- ural language supervision
[Radfordet al., 2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from nat- ural language supervision. InProc. IEEE Int’l Conf. Ma- chine Learning,
2021
-
[31]
High-resolution image synthesis with latent diffusion models
[Rombachet al., 2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProc. IEEE Int’l Conf. Computer Vision and Pattern Recognition,
2022
-
[32]
RAFT: Re- current all-pairs field transforms for optical flow
[Teedet al., 2020] Zachary Teed and Jia Deng. RAFT: Re- current all-pairs field transforms for optical flow. In Proc. European Conf. Computer Vision,
2020
-
[33]
Videox-fun,
[Videox-fun, 2025] Videox-fun. Videox-fun,
2025
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
https: //github.com/aigc-apps/VideoX-Fun. [Wanet al., 2025] Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Image quality assessment: From error visibility to structural similarity.IEEE Trans- actions on Image Processing,
[Wanget al., 2004] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Trans- actions on Image Processing,
2004
-
[36]
Video models are zero-shot learners and reasoners
[Wiedemeret al., 2025] Thadd ¨aus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners. arXiv:2509.20328,
work page internal anchor Pith review arXiv 2025
-
[37]
Rerender a video: Zero-shot text- guided video-to-video translation
[Yanget al., 2023] Shuai Yang, Yifan Zhou, Ziwei Liu, and Chen Change Loy. Rerender a video: Zero-shot text- guided video-to-video translation
2023
-
[38]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
[Yanget al., 2024c] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072,
work page internal anchor Pith review arXiv
-
[39]
ImgEdit: A Unified Image Editing Dataset and Benchmark
[Yeet al., 2025] Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. ImgEdit: A unified image editing dataset and benchmark. arXiv: 2505.20275,
work page internal anchor Pith review arXiv 2025
-
[40]
[Zenget al., 2025] Jianshu Zeng, Yuxuan Liu, Yutong Feng, Chenxuan Miao, Zixiang Gao, Jiwang Qu, Jianzhang Zhang, Bin Wang, and Kun Yuan. Lumen: Consistent video relighting and harmonious background replacement with video generative models.arXiv:2508.12945,
-
[41]
Adding conditional control to text-to-image dif- fusion models
[Zhanget al., 2023] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image dif- fusion models. InProc. IEEE Int’l Conf. Computer Vision and Pattern Recognition,
2023
-
[42]
Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing con- sistent light transport
[Zhanget al., 2025] Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Scaling in-the-wild training for diffusion-based illumination harmonization and editing by imposing con- sistent light transport. InProc. Int’l Conf. Learning Rep- resentations,
2025
-
[43]
VCGAN: Video colorization with hy- brid generative adversarial network.IEEE Transactions on Multimedia, 25:3017–3032,
[Zhaoet al., 2022] Yuzhi Zhao, Lai-Man Po, Wing-Yin Yu, Yasar Abbas Ur Rehman, Mengyang Liu, Yujia Zhang, and Weifeng Ou. VCGAN: Video colorization with hy- brid generative adversarial network.IEEE Transactions on Multimedia, 25:3017–3032,
2022
-
[44]
Light-A-Video: Training-free video relighting via progressive light fusion
[Zhouet al., 2025] Yujie Zhou, Jiazi Bu, Pengyang Ling, Pan Zhang, Tong Wu, Qidong Huang, Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Anyi Rao, Jiaqi Wang, and Li Niu. Light-A-Video: Training-free video relighting via progressive light fusion. InProc. Int’l Conf. Computer Vision,
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.