Recognition: unknown
A KL Lens on Quantization: Fast, Forward-Only Sensitivity for Mixed-Precision SSM-Transformer Models
Pith reviewed 2026-05-10 14:21 UTC · model grok-4.3
The pith
KL divergence ranks hybrid model components by quantization sensitivity using only forward passes, outperforming MSE and SQNR for mixed-precision decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the Kullback-Leibler divergence between full-precision and quantized forward outputs provides a superior surrogate measure of quantization sensitivity for language modeling compared with mean squared error or signal-to-quantization-noise ratio. Applied component-wise in a backpropagation-free surrogate framework, this metric produces rankings that accurately forecast end-to-end performance degradation, enabling targeted mixed-precision configurations that preserve near-FP16 perplexity while reducing model size and increasing inference speed on resource-constrained hardware.
What carries the argument
KL divergence computed on forward passes as a surrogate sensitivity score that ranks individual SSM and transformer components by expected quantization impact.
If this is right
- KL-guided mixed precision maintains near full-precision perplexity while shrinking model size and raising throughput.
- The method operates without backpropagation or access to in-domain training data.
- KL rankings align more closely with observed accuracy drops than MSE or SQNR across SSM and hybrid models.
- On-device profiling on Intel Lunar Lake hardware shows competitive CPU and GPU performance versus uniform INT4.
- Ablation studies validate that the framework supports practical deployment with minimal accuracy loss.
Where Pith is reading between the lines
- The forward-only nature could lower the cost of testing quantization on models where training data remains inaccessible.
- Similar distribution-shift metrics might extend to other compression methods such as pruning.
- Integrating hardware cost models directly into the sensitivity step could further optimize bit assignments for specific devices.
- The same lens could be tested on pure transformer or non-language models to check whether the superiority over MSE generalizes.
Load-bearing premise
The component rankings produced by the forward KL metric will reliably match the actual end-to-end performance loss observed after full quantization.
What would settle it
Quantizing the model according to KL rankings and observing a larger perplexity increase than when using MSE rankings on the same architecture and evaluation set would falsify the claim that KL better captures sensitivity.
Figures

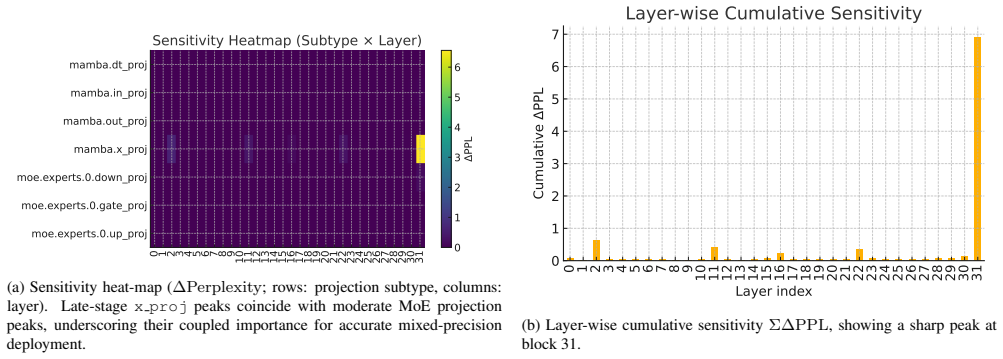

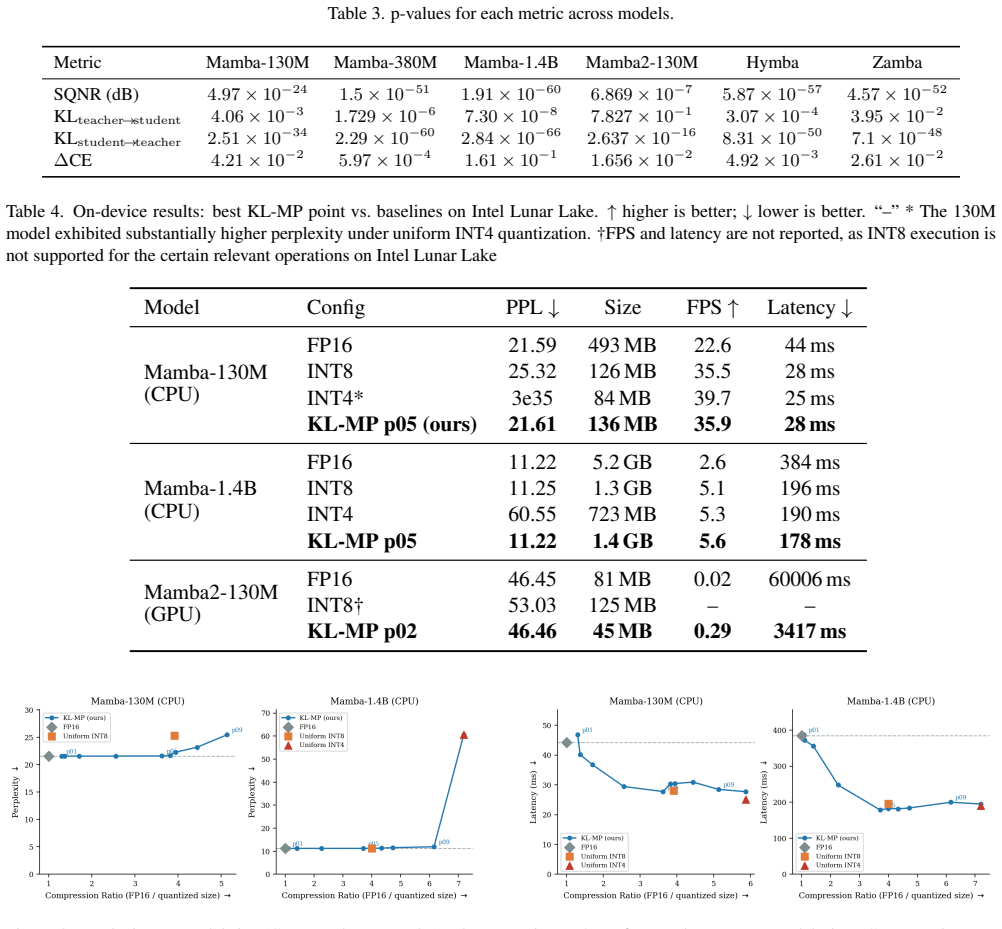


read the original abstract
Deploying Large Language Models (LLMs) on edge devices faces severe computational and memory constraints, limiting real-time processing and on-device intelligence. Hybrid architectures combining Structured State Space Models (SSMs) with transformer-based LLMs offer a balance of efficiency and performance. Aggressive quantization can drastically cut model size and speed up inference, but its uneven effects on different components require careful management. In this work, we propose a lightweight, backpropagation-free, surrogate-based sensitivity analysis framework to identify hybrid SSM-Transformer components most susceptible to quantization-induced degradation. Relying solely on forward-pass metrics, our method avoids expensive gradient computations and retraining, making it suitable for situations where access to in-domain data is limited due to proprietary restrictions or privacy constraints. We also provide a formal analysis showing that the Kullback-Leibler (KL) divergence metric better captures quantization sensitivity for Language modeling tasks than widely adopted alternatives such as mean squared error (MSE) and signal-to-quantization-noise ratio (SQNR). Through extensive experiments on SSM and hybrid architectures, our ablation studies confirm that KL-based rankings align with observed performance drops and outperform alternative metrics. This framework enables the practical deployment of advanced hybrid models on resource-constrained edge devices with minimal accuracy loss. We further validate our approach with real-world on-device profiling on Intel Lunar Lake hardware, demonstrating that KL-guided mixed-precision achieves near-FP16 perplexity with model sizes and throughput competitive with Uniform INT4 on both CPU and GPU execution modes. Code is available at https://github.com/jasonkongie/kl-ssm-quant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a backpropagation-free, forward-pass-only framework for analyzing quantization sensitivity in hybrid SSM-Transformer models using KL divergence as a surrogate metric. It includes formal analysis arguing for KL's advantages over MSE and SQNR in language modeling, ablation studies verifying that the resulting rankings predict performance degradation, and practical validation via mixed-precision quantization on edge hardware achieving near full-precision perplexity.
Significance. Should the results hold, particularly the predictive accuracy of the KL metric without gradients and under data constraints, the work offers substantial practical value for deploying large hybrid models on edge devices. It addresses key challenges in quantization management for efficiency gains while respecting privacy limitations on data access, with added credibility from real-world hardware profiling.
major comments (2)
- [Abstract] Abstract: The claim that KL-based rankings align with observed performance drops (and outperform MSE/SQNR) is load-bearing, yet the validation appears to rely on full in-domain calibration sets. This does not establish reliability under the paper's stated operating constraints of limited or out-of-domain data due to privacy/proprietary restrictions; explicit experiments with restricted calibration data are required to support the surrogate's predictive power.
- [Abstract] Abstract: Potential circularity exists if the same forward-pass outputs used to compute KL rankings are also used to measure the perplexity drops in the ablations; an independent held-out evaluation or external benchmark is needed to confirm that the metric genuinely predicts end-to-end degradation rather than reflecting internal consistency.
minor comments (1)
- The abstract references extensive experiments and ablations but provides no quantitative details (e.g., correlation values or specific component rankings); the full manuscript should include these to allow assessment of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that KL-based rankings align with observed performance drops (and outperform MSE/SQNR) is load-bearing, yet the validation appears to rely on full in-domain calibration sets. This does not establish reliability under the paper's stated operating constraints of limited or out-of-domain data due to privacy/proprietary restrictions; explicit experiments with restricted calibration data are required to support the surrogate's predictive power.
Authors: We agree that explicit validation under limited-data and out-of-domain conditions is necessary to fully substantiate the framework's utility in the privacy-constrained regimes highlighted in the paper. Although the current ablations use full calibration sets, the method itself requires only forward passes and is therefore directly applicable to smaller or shifted datasets. In the revised manuscript we will add new ablation results that subsample the calibration set to 5% and 10% of its original size as well as results using out-of-domain calibration data drawn from a different corpus; these experiments will report both ranking stability and the correlation between KL rankings and measured perplexity degradation. revision: yes
-
Referee: [Abstract] Abstract: Potential circularity exists if the same forward-pass outputs used to compute KL rankings are also used to measure the perplexity drops in the ablations; an independent held-out evaluation or external benchmark is needed to confirm that the metric genuinely predicts end-to-end degradation rather than reflecting internal consistency.
Authors: The KL rankings are derived from forward passes on a designated calibration split, while end-to-end perplexity is evaluated after quantization on the standard held-out test splits of the respective benchmarks (distinct from the calibration data). This separation already exists in the experimental protocol. To eliminate any ambiguity we will revise the relevant sections to explicitly document the data splits and, space permitting, add a small additional experiment on an external benchmark to further demonstrate that the predictive relationship holds outside the calibration distribution. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core contribution is a forward-only KL surrogate for sensitivity ranking in SSM-Transformer quantization, supported by a separate formal comparison of KL versus MSE/SQNR and by empirical ablations that measure end-to-end perplexity degradation after actual quantization. These steps rely on distinct computations (KL on unquantized forward passes for ranking; full quantized inference for validation) and do not reduce to each other by definition or by fitting the same quantities. No load-bearing self-citations, ansatz smuggling, or uniqueness theorems imported from prior author work are evident in the provided abstract or description. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Software repository,
XAMBA: Enabling efficient state space models on resource- constrained neural processing units. Software repository,
-
[2]
Quarot: Outlier- free 4-bit inference in rotated llms.Advances in Neural In- formation Processing Systems, 37:100213–100240, 2024
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alis- tarh, Torsten Hoefler, and James Hensman. Quarot: Outlier- free 4-bit inference in rotated llms.Advances in Neural In- formation Processing Systems, 37:100213–100240, 2024. 1
2024
-
[3]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Tim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettle- moyer. LLM.int8(): 8-bit matrix multiplication for trans- formers at scale.arXiv preprint arXiv:2208.07339, 2022. 1
work page internal anchor Pith review arXiv 2022
-
[4]
QLoRA: Efficient Finetuning of Quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs.arXiv preprint arXiv:2305.14314, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[5]
Mahabaleshwarkar, Shih- Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al
Xin Dong, Yonggan Fu, Shizhe Diao, Wonmin Byeon, Zi- jia Chen, Ameya Sunil Mahabaleshwarkar, Shih-Yang Liu, Matthijs Van Keirsbilck, Min-Hung Chen, Yoshi Suhara, et al. Hymba: A hybrid-head architecture for small language models.arXiv preprint arXiv:2411.13676, 2024. 1, 2, 5
-
[6]
Ma- honey, and Kurt Keutzer
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W. Ma- honey, and Kurt Keutzer. Hawq: Hessian aware quantization of neural networks with mixed-precision. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 293–302, 2019. 1, 2
2019
-
[7]
Zamba: A compact 7b SSM.arXiv preprint arXiv:2405.16712,
Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, and Beren Millidge. Zamba: A compact 7b ssm hybrid model.arXiv preprint arXiv:2405.16712, 2024. 1, 2
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. 1, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Intel core ultra 200v series pro- cessors (lunar lake) product brief.https : / / www
Intel Corporation. Intel core ultra 200v series pro- cessors (lunar lake) product brief.https : / / www . intel . com / content / www / us / en / products / docs / processors / core - ultra / core - ultra - 200v-product-brief.html, 2024. Accessed: 2025. 5
2024
-
[10]
Maurice G. Kendall. A new measure of rank correlation. Biometrika, 30(1–2):81–93, 1938. 3
1938
-
[11]
Quantizing deep convolutional networks for efficient inference: A whitepaper
Raghuraman Krishnamoorthi. Quantizing deep convolu- tional networks for efficient inference: A whitepaper.arXiv preprint arXiv:1806.08342, 2018. 1, 2
-
[12]
Solomon Kullback and Richard A. Leibler. On information and sufficiency.The Annals of Mathematical Statistics, 22 (1):79–86, 1951. 3
1951
-
[13]
Up or down? adap- tive rounding for post-training quantization
Markus Nagel, Rana Ali Amjad, Mart Van Baalen, Chris- tos Louizos, and Tijmen Blankevoort. Up or down? adap- tive rounding for post-training quantization. InInternational Conference on Machine Learning (ICML), 2020. 1, 2
2020
-
[14]
A white paper on neural network quantization.arXiv preprint arXiv:2106.08295,
Markus Nagel, Marios Fournarakis, Rana Ali Amjad, Yely- sei Bondarenko, Mart Van Baalen, and Tijmen Blankevoort. A white paper on neural network quantization.arXiv preprint arXiv:2106.08295, 2021. 1, 2
-
[15]
Softmax bias correction for quantized gener- ative models
Nilesh Prasad Pandey, Marios Fournarakis, Chirag Patel, and Markus Nagel. Softmax bias correction for quantized gener- ative models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1453–1458, 2023. 1
2023
-
[16]
A practi- cal mixed precision algorithm for post-training quantization
Nilesh Prasad Pandey, Markus Nagel, Mart van Baalen, Yin Huang, Chirag Patel, and Tijmen Blankevoort. A practi- cal mixed precision algorithm for post-training quantization. arXiv preprint arXiv:2302.05397, 2023. 1, 2, 3, 5
-
[17]
Nilesh Prasad Pandey, Jangseon Park, Onat Gungor, Flavio Ponzina, and Tajana Rosing. Qmc: Efficient slm edge infer- ence via outlier-aware quantization and emergent memories co-design.arXiv preprint arXiv:2601.14549, 2026. 1
-
[18]
Mamba-ptq: Outlier channels in recurrent large language models.arXiv preprint arXiv:2407.12397, 2024
Alessandro Pierro and Steven Abreu. Mamba-ptq: Outlier channels in recurrent large language models.arXiv preprint arXiv:2407.12397, 2024. 1, 2
-
[19]
SQuAD: 100,000+ questions for machine com- prehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine com- prehension of text. InProceedings of EMNLP, 2016. 2
2016
-
[20]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 1
2017
-
[21]
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. GLUE: A multi-task benchmark and analysis platform for natural language under- standing.arXiv preprint arXiv:1804.07461, 2018. 2
work page internal anchor Pith review arXiv 2018
-
[22]
HAQ: Hardware-aware automated quantization
Kuan Wang, Zhijian Liu, Yujun Lin, Ji Lin, and Song Han. HAQ: Hardware-aware automated quantization. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 2
2019
-
[23]
Smoothquant: Accurate and efficient post-training quantization for large language models,
Guangxuan Xiao, Ji Lin, Mathieu Seznec, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post- training quantization for large language models.arXiv preprint arXiv:2211.10438, 2023. 1
-
[24]
Efficient quantization strategies for latent diffusion models.arXiv preprint arXiv:2312.05431,
Yuewei Yang, Xiaoliang Dai, Jialiang Wang, Peizhao Zhang, and Hongbo Zhang. Efficient quantization strategies for latent diffusion models.arXiv preprint arXiv:2312.05431,
-
[25]
Y., Zhang, M., Wu, X., Li, C., and He, Y
Zhewei Yao, Yuxiong He, et al. ZeroQuant: Efficient and af- fordable post-training quantization for large-scale transform- ers.arXiv preprint arXiv:2206.01861, 2022. 1 A. On-Device Profiling: Reproducibility Guide All profiling scripts target Intel Lunar Lake via OpenVINO. The pipeline runs in three stages. Step 1 | Convert and Quantize python convert.py ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.