Recognition: unknown
From Exploration to Specification: LLM-Based Property Generation for Mobile App Testing
Pith reviewed 2026-05-10 13:46 UTC · model grok-4.3
The pith
PropGen uses LLMs to generate and refine behavioral properties for Android apps from observed executions, enabling detection of functional bugs without manual specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
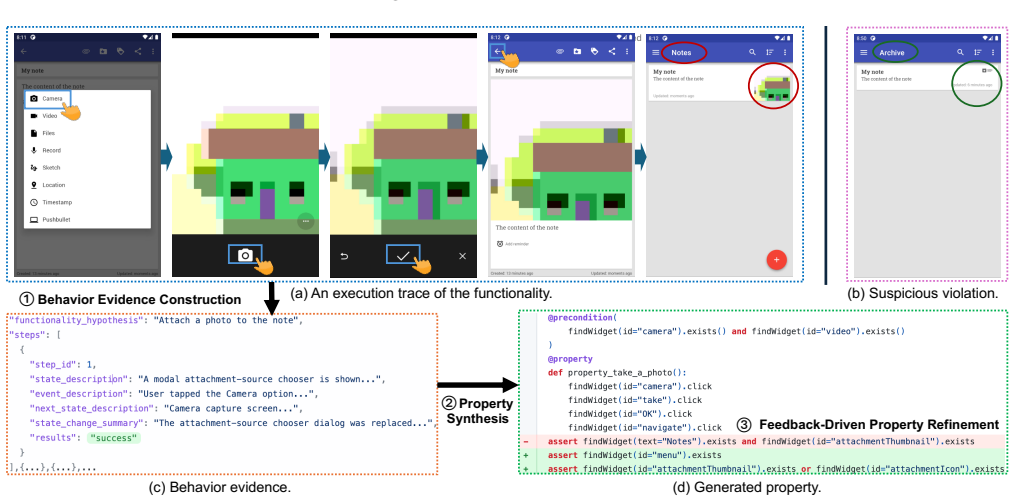
PropGen performs functionality-guided exploration to collect behavioral evidence from app executions, synthesizes properties from the collected evidence using large language models, and refines imprecise properties based on testing feedback. On 12 real-world Android apps, it identified 1,210 valid functionalities and executed 977 correctly, generated 985 properties of which 912 were valid, repaired 118 of 127 imprecise ones, and used the properties to find 25 previously unknown functional bugs missed by existing techniques.
What carries the argument
PropGen's three-stage process of functionality-guided exploration to gather evidence, LLM-based synthesis of properties from behaviors, and feedback-driven repair of imprecise properties.
If this is right
- Property-based testing becomes practical for mobile apps because properties no longer require extensive manual effort.
- Functional bugs that manifest only under specific interactions can be detected systematically rather than missed by crash-focused testing.
- The refinement loop corrects the majority of LLM-generated inaccuracies exposed during execution.
- Exploration guided by functionalities covers and executes far more valid app behaviors than unguided baselines.
Where Pith is reading between the lines
- Teams could embed the generated properties into regular regression suites to catch behavior changes across app updates.
- The same exploration-plus-LLM pattern might adapt to other domains such as web or desktop applications if comparable execution traces can be collected.
- Over time, stronger LLMs could shrink the repair step and make fully automatic specification the default for new apps.
Load-bearing premise
The behaviors collected during guided exploration accurately reflect the app's intended semantics so that LLMs can synthesize and repair correct properties without introducing systematic inaccuracies.
What would settle it
Applying PropGen to additional apps where most generated properties prove invalid upon manual review or fail to detect known functional bugs would show the automation does not reliably produce usable specifications.
Figures

read the original abstract
Mobile apps often suffer from functional bugs that do not cause crashes but instead manifest as incorrect behaviors under specific user interactions. Such bugs are difficult to detect automatically because they often lack explicit test oracles. Property-based testing can effectively expose them by checking intended behavioral properties under diverse interactions. However, its use largely depends on manually written properties, whose construction is difficult and expensive, limiting its practical use for mobile apps. To address this limitation, we propose PropGen, an automated approach for generating properties for Android apps. However, this task is challenging for two reasons: app functionalities are often hard to systematically uncover and execute, and properties are difficult to derive accurately from observed behaviors. To this end, PropGen performs functionality-guided exploration to collect behavioral evidence from app executions, synthesizes properties from the collected evidence, and refines imprecise properties based on testing feedback. We implemented PropGen and evaluated it on 12 real-world Android apps. The results show that PropGen can effectively identify and execute valid app functionalities, generate valid properties, and repair most imprecise ones. Across all apps, PropGen identified 1,210 valid functionalities and correctly executed 977 of them, compared with 491 and 187 for the baseline. It generated 985 properties, 912 of which were valid, and repaired 118 of 127 imprecise ones exposed during testing. With the resulting properties, we found 25 previously unknown functional bugs in the latest versions of the subject apps, many of which were missed by existing functional testing techniques.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PropGen, an automated LLM-based system for generating properties to enable property-based testing of Android apps. It performs functionality-guided exploration to gather execution traces, synthesizes candidate properties from those traces, and iteratively repairs imprecise properties using testing feedback. On 12 real-world apps, PropGen identifies 1,210 valid functionalities (vs. 491 for baseline), executes 977 of them (vs. 187), generates 985 properties (912 deemed valid), repairs 118 of 127 imprecise ones, and uncovers 25 previously unknown functional bugs missed by existing techniques.
Significance. If the generated properties reliably capture intended developer semantics rather than merely observed (possibly buggy) behavior, the work would meaningfully lower the barrier to property-based testing for mobile apps, where functional oracles are scarce. The concrete bug-finding results and the scale of the evaluation (1,210 functionalities, 25 bugs) are notable strengths; however, the absence of an independent oracle for property validity limits the strength of the central claims.
major comments (3)
- [Evaluation / Results] Evaluation section (results on 12 apps): The determination that 912 of 985 properties are 'valid' and that 25 bugs are 'previously unknown functional bugs' rests on testing feedback and observed traces without an independent oracle (e.g., developer documentation, formal spec, or blinded manual review). This leaves open the possibility that properties encode implementation behavior—including latent bugs—rather than intended semantics, which directly affects the validity counts and the bug-discovery claim.
- [Approach / Property Generation and Refinement] § on functionality-guided exploration and property synthesis: No details are provided on how the LLM prompts or synthesis process guard against generalizing from incomplete or buggy traces; the repair loop uses the same testing feedback that may itself be influenced by the properties under test, creating a potential circularity in the 'valid' and 'repaired' counts.
- [Evaluation] Experimental setup: The comparison with the baseline reports raw counts (1,210 vs. 491 functionalities; 977 vs. 187 executions) but provides no statistical significance tests, variance across runs, or controls for app selection bias and exploration time budgets, making it difficult to assess whether the reported gains are robust.
minor comments (2)
- [Abstract / Results] The abstract and results tables would benefit from explicit definitions of 'valid functionality' and 'valid property' (e.g., criteria used by human judges or automated checks).
- [Evaluation] Clarify whether the 12 apps were chosen to represent diversity in domains or simply availability; this affects generalizability claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and have revised the manuscript to strengthen the evaluation and approach descriptions while acknowledging limitations.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation section (results on 12 apps): The determination that 912 of 985 properties are 'valid' and that 25 bugs are 'previously unknown functional bugs' rests on testing feedback and observed traces without an independent oracle (e.g., developer documentation, formal spec, or blinded manual review). This leaves open the possibility that properties encode implementation behavior—including latent bugs—rather than intended semantics, which directly affects the validity counts and the bug-discovery claim.
Authors: We agree that an independent oracle would provide stronger validation. Our validity assessment relies on properties holding consistently across multiple independent test executions with randomized inputs and successful refinement without contradictions. For the 25 bugs, we manually reproduced each failure, checked against available app documentation and public issue trackers, and confirmed they were unreported at discovery time. We have added a dedicated Threats to Validity subsection discussing the oracle limitation and expanded the bug verification process description. This is a partial revision as a full independent oracle would require developer participation beyond the current scope. revision: partial
-
Referee: [Approach / Property Generation and Refinement] § on functionality-guided exploration and property synthesis: No details are provided on how the LLM prompts or synthesis process guard against generalizing from incomplete or buggy traces; the repair loop uses the same testing feedback that may itself be influenced by the properties under test, creating a potential circularity in the 'valid' and 'repaired' counts.
Authors: We have substantially expanded the relevant sections with prompt templates and pseudocode now included in the appendix. The synthesis prompts explicitly require properties to be entailed by the provided traces without extrapolation, using few-shot examples that demonstrate conservative generalization. The repair loop performs separate test runs with fresh randomized inputs after each refinement iteration, and we cross-validate repaired properties against the original exploration traces to break potential circularity. These clarifications address the concern directly. revision: yes
-
Referee: [Evaluation] Experimental setup: The comparison with the baseline reports raw counts (1,210 vs. 491 functionalities; 977 vs. 187 executions) but provides no statistical significance tests, variance across runs, or controls for app selection bias and exploration time budgets, making it difficult to assess whether the reported gains are robust.
Authors: We have rerun the experiments with five independent trials per app under identical conditions. The revised evaluation now reports means, standard deviations, and results of paired t-tests showing statistical significance (p < 0.01) for the reported improvements. App selection criteria (top downloads per category, size diversity, and open-source availability) are detailed, and all runs used a fixed 30-minute exploration budget to control for time. These additions demonstrate robustness. revision: yes
Circularity Check
No circularity in claimed derivation or results
full rationale
The paper presents an empirical tool (PropGen) that performs exploration, LLM synthesis of properties from traces, and refinement via testing feedback. Reported outcomes are independent empirical counts (functionalities identified/executed, properties generated/valid, bugs found) measured against external baselines and real apps. No equations, self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the abstract or evaluation summary that would reduce any result to the method's own inputs by construction. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Christoffer Quist Adamsen, Gianluca Mezzetti, and Anders Møller. 2015. System- atic execution of android test suites in adverse conditions. InProceedings of the 2015 International Symposium on Software Testing and Analysis. 83–93
2015
-
[2]
Thomas Arts, John Hughes, Joakim Johansson, and Ulf Wiger. 2006. Testing telecoms software with Quviq QuickCheck. InProceedings of the 2006 ACM SIGPLAN Workshop on Erlang. 2–10
2006
-
[3]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. Chatunitest: A framework for llm-based test generation. InCompan- ion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 572–576
2024
-
[4]
Shauvik Roy Choudhary, Alessandra Gorla, and Alessandro Orso. 2015. Au- tomated test input generation for android: Are we there yet?(e). In2015 30th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 429–440
2015
-
[5]
Koen Claessen and John Hughes. 2000. QuickCheck: a lightweight tool for random testing of Haskell programs. InICFP’00. 268–279
2000
-
[6]
Riccardo Coppola and Emil Alégroth. 2022. A taxonomy of metrics for GUI- based testing research: A systematic literature review.Information and Software Technology152 (2022), 107062
2022
-
[7]
Yinlin Deng, Chunqiu Steven Xia, Haoran Peng, Chenyuan Yang, and Lingming Zhang. 2023. Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models. InProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis. 423–435
2023
-
[8]
Zhen Dong, Marcel Böhme, Lucia Cojocaru, and Abhik Roychoudhury. 2020. Time-travel testing of android apps. InProceedings of the ACM/IEEE 42nd Inter- national Conference on Software Engineering. 481–492
2020
- [9]
-
[10]
Madeline Endres, Sarah Fakhoury, Saikat Chakraborty, and Shuvendu K Lahiri
-
[11]
Can large language models transform natural language intent into formal method postconditions?Proceedings of the ACM on Software Engineering1, FSE (2024), 1889–1912
2024
-
[12]
Angela Fan, Beliz Gokkaya, Mark Harman, Mitya Lyubarskiy, Shubho Sengupta, Shin Yoo, and Jie M Zhang. 2023. Large language models for software engineering: Survey and open problems. In2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE, 31–53
2023
-
[13]
Gordon Fraser and Andrea Arcuri. 2011. Evosuite: automatic test suite generation for object-oriented software. InProceedings of the 19th ACM SIGSOFT symposium and the 13th European conference on Foundations of software engineering. 416–419
2011
-
[14]
Cuiyun Gao, Xing Hu, Shan Gao, Xin Xia, and Zhi Jin. 2025. The current chal- lenges of software engineering in the era of large language models.ACM Trans- actions on Software Engineering and Methodology34, 5 (2025), 1–30
2025
-
[15]
Patrice Godefroid, Nils Klarlund, and Koushik Sen. 2005. DART: Directed auto- mated random testing. InProceedings of the 2005 ACM SIGPLAN conference on Programming language design and implementation. 213–223
2005
-
[16]
Harrison Goldstein, Joseph W Cutler, Daniel Dickstein, Benjamin C Pierce, and Andrew Head. 2024. Property-based testing in practice. InProceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[17]
Harrison Goldstein, Joseph W Cutler, Adam Stein, Benjamin C Pierce, and Andrew Head. 2022. Some problems with properties. InProc. Workshop on the Human Aspects of Types and Reasoning Assistants (HATRA), Vol. 1. 3
2022
-
[18]
Tianxiao Gu, Chengnian Sun, Xiaoxing Ma, Chun Cao, Chang Xu, Yuan Yao, Qirun Zhang, Jian Lu, and Zhendong Su. 2019. Practical GUI testing of An- droid applications via model abstraction and refinement. In2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). IEEE, 269–280
2019
-
[19]
Wunan Guo, Zhen Dong, Liwei Shen, Wei Tian, Ting Su, and Xin Peng. 2022. Detecting and fixing data loss issues in Android apps. InISSTA ’22: 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. 605–616. doi:10.1145/3533767.3534402
-
[20]
Yongxiang Hu, Hailiang Jin, Xuan Wang, Jiazhen Gu, Shiyu Guo, Chaoyi Chen, Xin Wang, and Yangfan Zhou. 2024. Autoconsis: Automatic gui-driven data inconsistency detection of mobile apps. InProceedings of the 46th International Conference on Software Engineering: Software Engineering in Practice. 137–146
2024
-
[21]
John Hughes. 2016. Experiences with QuickCheck: testing the hard stuff and staying sane. InA List of Successes That Can Change the World: Essays Dedicated to Philip Wadler on the Occasion of His 60th Birthday. Springer, 169–186
2016
-
[22]
John Hughes, Benjamin C Pierce, Thomas Arts, and Ulf Norell. 2016. Mysteries of dropbox: property-based testing of a distributed synchronization service. In 2016 IEEE International Conference on Software Testing, Verification and Validation (ICST). IEEE, 135–145
2016
-
[23]
Zongze Jiang, Ming Wen, Jialun Cao, Xuanhua Shi, and Hai Jin. 2024. Towards Understanding the Effectiveness of Large Language Models on Directed Test Input Generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1408–1420
2024
-
[24]
Stefan Karlsson, Adnan Čaušević, and Daniel Sundmark. 2020. QuickREST: Property-based test generation of OpenAPI-described RESTful APIs. In2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST). IEEE, 131–141
2020
-
[25]
Pavneet Singh Kochhar, Ferdian Thung, Nachiappan Nagappan, Thomas Zim- mermann, and David Lo. 2015. Understanding the test automation culture of app developers. In2015 IEEE 8th International Conference on Software Testing, Verification and Validation (ICST). IEEE, 1–10
2015
-
[26]
Shuvendu K Lahiri, Sarah Fakhoury, Aaditya Naik, Georgios Sakkas, Saikat Chakraborty, Madanlal Musuvathi, Piali Choudhury, Curtis von Veh, Jee- vana Priya Inala, Chenglong Wang, et al . 2022. Interactive code generation via test-driven user-intent formalization.arXiv preprint arXiv:2208.05950(2022)
-
[27]
Mario Linares-Vásquez, Carlos Bernal-Cárdenas, Kevin Moran, and Denys Poshy- vanyk. 2017. How do developers test android applications?. In2017 IEEE In- ternational Conference on Software Maintenance and Evolution (ICSME). IEEE, 613–622
2017
-
[28]
Ruofan Liu, Xiwen Teoh, Yun Lin, Guanjie Chen, Ruofei Ren, Denys Poshyvanyk, and Jin Song Dong. 2025. GUIPilot: A Consistency-Based Mobile GUI Testing Approach for Detecting Application-Specific Bugs.Proceedings of the ACM on Software Engineering2, ISSTA (2025), 753–776
2025
-
[29]
Ye Liu, Yue Xue, Daoyuan Wu, Yuqiang Sun, Yi Li, Miaolei Shi, and Yang Liu
- [30]
-
[31]
Zhe Liu, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Xing Che, Dandan Wang, and Qing Wang. 2024. Make llm a testing expert: Bringing human-like interaction to mobile gui testing via functionality-aware decisions. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 1–13
2024
-
[32]
Zhe Liu, Cheng Li, Chunyang Chen, Junjie Wang, Mengzhuo Chen, Boyu Wu, Yawen Wang, Jun Hu, and Qing Wang. 2025. Seeing is believing: Vision-driven non-crash functional bug detection for mobile apps.IEEE Transactions on Software Engineering(2025)
2025
-
[33]
Aravind Machiry, Rohan Tahiliani, and Mayur Naik. 2013. Dynodroid: An input generation system for android apps. InProceedings of the 2013 9th Joint Meeting on Foundations of Software Engineering. 224–234
2013
-
[34]
David R MacIver, Zac Hatfield-Dodds, et al. 2019. Hypothesis: A new approach to property-based testing.Journal of Open Source Software4, 43 (2019), 1891
2019
-
[35]
Ke Mao, Mark Harman, and Yue Jia. 2016. Sapienz: Multi-objective automated testing for android applications. InProceedings of the 25th international symposium on software testing and analysis. 94–105
2016
-
[36]
2016.American Fuzzy Lop - Whitepaper
Michał Zalewski. 2016.American Fuzzy Lop - Whitepaper. https://lcamtuf. coredump.cx/afl/technical_details.txt
2016
-
[37]
Liam O’Connor and Oskar Wickström. 2022. Quickstrom: property-based accep- tance testing with LTL specifications. InProceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation (PLDI). 1025–1038. doi:10.1145/3519939.3523728
-
[38]
Carlos Pacheco and Michael D Ernst. 2007. Randoop: feedback-directed random testing for Java. InCompanion to the 22nd ACM SIGPLAN conference on Object- oriented programming systems and applications companion. 815–816
2007
-
[39]
Rohan Padhye, Caroline Lemieux, and Koushik Sen. 2019. Jqf: Coverage-guided property-based testing in java. InProceedings of the 28th ACM SIGSOFT Interna- tional Symposium on Software Testing and Analysis. 398–401
2019
-
[40]
Minxue Pan, An Huang, Guoxin Wang, Tian Zhang, and Xuandong Li. 2020. Reinforcement learning based curiosity-driven testing of android applications. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 153–164
2020
-
[41]
Annibale Panichella, Sebastiano Panichella, Gordon Fraser, Anand Ashok Sawant, and Vincent J Hellendoorn. 2020. Revisiting test smells in automatically generated tests: limitations, pitfalls, and opportunities. In2020 IEEE international conference on software maintenance and evolution (ICSME). IEEE, 523–533
2020
-
[42]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326 (2025)
work page Pith review arXiv 2025
-
[43]
Dezhi Ran, Hao Wang, Zihe Song, Mengzhou Wu, Yuan Cao, Ying Zhang, Wei Yang, and Tao Xie. 2024. Guardian: A Runtime Framework for LLM-based UI Exploration. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis
2024
-
[44]
Oliviero Riganelli, Simone Paolo Mottadelli, Claudio Rota, Daniela Micucci, and Leonardo Mariani. 2020. Data loss detector: automatically revealing data loss bugs in Android apps. InISSTA ’20: 29th ACM SIGSOFT International Symposium on Software Testing and Analysis. 141–152. doi:10.1145/3395363.3397379 Conference’17, July 2017, Washington, DC, USA Yiheng...
-
[45]
André Santos, Alcino Cunha, and Nuno Macedo. 2018. Property-based testing for the robot operating system. InProceedings of the 9th ACM SIGSOFT International Workshop on Automating TEST Case Design, Selection, and Evaluation. 56–62
2018
-
[46]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering50, 1 (2023), 85–105
2023
-
[47]
Koushik Sen, Darko Marinov, and Gul Agha. 2005. CUTE: A concolic unit testing engine for C.ACM SIGSOFT software engineering notes30, 5 (2005), 263–272
2005
-
[48]
Sina Shamshiri. 2015. Automated unit test generation for evolving software. In Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering. 1038–1041
2015
-
[49]
Ting Su, Guozhu Meng, Yuting Chen, Ke Wu, Weiming Yang, Yao Yao, Geguang Pu, Yang Liu, and Zhendong Su. 2017. Guided, Stochastic Model-based GUI Testing of Android Apps. InThe joint meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE). 245–256. doi:10.1145/3106237.3106298
-
[50]
Ting Su, Yichen Yan, Jue Wang, Jingling Sun, Yiheng Xiong, Geguang Pu, Ke Wang, and Zhendong Su. 2021. Fully automated functional fuzzing of Android apps for detecting non-crashing logic bugs.Proc. ACM Program. Lang.5, OOPSLA (2021), 1–31. doi:10.1145/3485533
-
[51]
Jingling Sun, Ting Su, Jiayi Jiang, Jue Wang, Geguang Pu, and Zhendong Su. 2023. Property-Based Fuzzing for Finding Data Manipulation Errors in Android Apps. InProceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 1088–1100. doi:10.1145/3611643.3616286
-
[52]
Jingling Sun, Ting Su, Junxin Li, Zhen Dong, Geguang Pu, Tao Xie, and Zhendong Su. 2021. Understanding and finding system setting-related defects in Android apps. InISSTA ’21: 30th ACM SIGSOFT International Symposium on Software Testing and Analysis. 204–215. doi:10.1145/3460319.3464806
-
[53]
Jingling Sun, Ting Su, Kai Liu, Chao Peng, Zhao Zhang, Geguang Pu, Tao Xie, and Zhendong Su. 2023. Characterizing and Finding System Setting-Related Defects in Android Apps.IEEE Trans. Software Eng.49, 4 (2023), 2941–2963. doi:10.1109/TSE.2023.3236449
-
[54]
Jingling Sun, Ting Su, Jun Sun, Jianwen Li, Mengfei Wang, and Geguang Pu
-
[55]
InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering
Property-Based Testing for Validating User Privacy-Related Functionalities in Social Media Apps. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 440–451
-
[56]
2021.Android Debug Bridge (adb)
Android Team. 2021.Android Debug Bridge (adb). Retrieved 2026-3 from https: //developer.android.com/tools/adb
2021
-
[57]
Nikolai Tillmann, Jonathan De Halleux, and Tao Xie. 2014. Transferring an automated test generation tool to practice: From Pex to Fakes and Code Digger. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering. 385–396
2014
- [58]
-
[59]
2021.uiautomator2
uiautomator2 Team. 2021.uiautomator2. Retrieved 2026-3 from https://github. com/openatx/uiautomator2
2021
- [60]
-
[61]
Chenxu Wang, Tianming Liu, Yanjie Zhao, Minghui Yang, and Haoyu Wang
-
[62]
Llmdroid: Enhancing automated mobile app gui testing coverage with large language model guidance.Proceedings of the ACM on Software Engineering 2, FSE (2025), 1001–1022
2025
-
[63]
Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision.IEEE Transactions on Software Engineering50, 4 (2024), 911–936
2024
-
[64]
Jue Wang, Yanyan Jiang, Ting Su, Shaohua Li, Chang Xu, Jian Lu, and Zhendong Su. 2022. Detecting non-crashing functional bugs in Android apps via deep- state differential analysis. InProceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE). 434–446. doi:10.1145/3540250.3549170
-
[65]
Jue Wang, Yanyan Jiang, Chang Xu, Chun Cao, Xiaoxing Ma, and Jian Lu. 2020. Combodroid: generating high-quality test inputs for android apps via use case combinations. InProceedings of the ACM/IEEE 42nd International Conference on Software Engineering. 469–480
2020
- [66]
-
[67]
Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, and Yunxin Liu. 2024. Autodroid: Llm-powered task automation in android. InProceedings of the 30th Annual International Con- ference on Mobile Computing and Networking. 543–557
2024
- [68]
- [69]
-
[70]
Yiheng Xiong, Ting Su, Jue Wang, Jingling Sun, Geguang Pu, and Zhendong Su. 2024. General and Practical Property-based Testing for Android Apps. In Proceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 53–64
2024
-
[71]
Yiheng Xiong, Mengqian Xu, Ting Su, Jingling Sun, Jue Wang, He Wen, Geguang Pu, Jifeng He, and Zhendong Su. 2023. An empirical study of functional bugs in android apps. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA’23). 1319–1331
2023
-
[72]
Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, et al. 2024. On the evaluation of large language models in unit test generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1607–1619
2024
-
[73]
Juyeon Yoon, Robert Feldt, and Shin Yoo. 2024. Intent-driven mobile gui test- ing with autonomous large language model agents. In2024 IEEE Conference on Software Testing, Verification and Validation (ICST). IEEE, 129–139
2024
-
[74]
Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. 2024. Evaluating and improving chatgpt for unit test generation. Proceedings of the ACM on Software Engineering1, FSE (2024), 1703–1726
2024
-
[75]
Razieh Nokhbeh Zaeem, Mukul R. Prasad, and Sarfraz Khurshid. 2014. Automated Generation of Oracles for Testing User-Interaction Features of Mobile Apps. In Proceedings of the International Conference on Software Testing, Verification and Validation (ICST). 183–192. doi:10.1109/ICST.2014.31
-
[76]
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. 2025. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems. 1–20
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.