Recognition: unknown
ATLAAS: Automatic Tensor-Level Abstraction of Accelerator Semantics
Pith reviewed 2026-05-10 12:36 UTC · model grok-4.3
The pith
An 8-pass MLIR pipeline lifts bit-level accelerator descriptions to complete tensor-level ISA specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
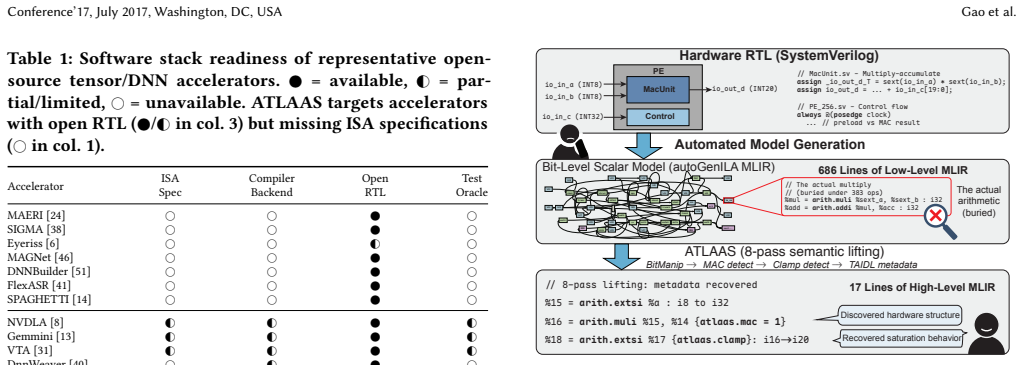
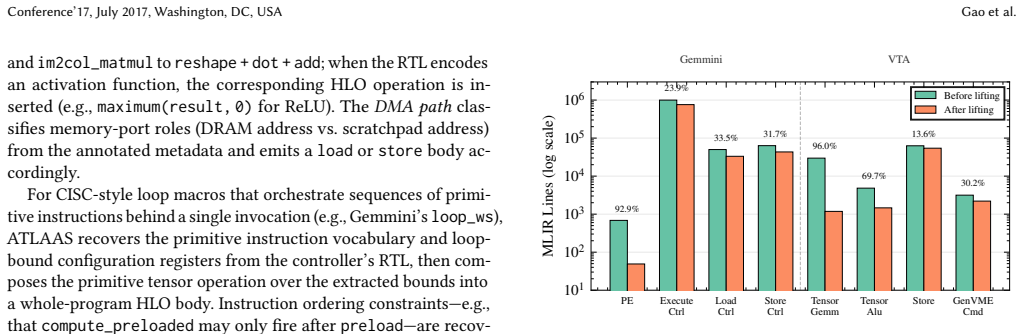
Starting from bit-level LLVM IR produced by RTL extraction, the 8-pass pipeline progressively recovers MAC idioms, saturation semantics, multi-dimensional buffer organizations, and data layout transformations, emitting tensor ISA specifications that enable automatic software stack generation. On the Gemmini systolic array the pipeline reduces bit-level MLIR size by up to 92.9 percent on processing elements and 24-34 percent on controllers, while discovering omitted hardware features whose correctness is confirmed by Z3 equivalence proofs. The same unmodified pipeline succeeds on all four datapath modules of TVM's VTA processor, confirming that the abstraction steps are general.
What carries the argument
An 8-pass semantic lifting pipeline inside MLIR that transforms bit-level operations into tensor-level constructs such as MAC idioms, saturation, buffers, and layouts.
If this is right
- Any accelerator whose RTL can be turned into LLVM IR can now receive a tensor ISA spec without manual documentation.
- Compiler backends, simulators, and code generators become available automatically once the lifted spec exists.
- Hardware features that were omitted from hand-written specs can be recovered and validated by equivalence checking.
- The same lifting steps apply across systolic arrays and other datapath styles without per-accelerator changes.
Where Pith is reading between the lines
- Design teams could iterate on new accelerator RTL and immediately obtain a compiler stack for evaluation instead of writing specs by hand.
- The recovered tensor specifications could serve as a neutral reference for comparing different hardware implementations of the same operator set.
- If the lifting passes are made modular, they might be reused to abstract other intermediate representations beyond MLIR.
Load-bearing premise
The eight successive passes can reconstruct the full high-level tensor structure from bit-level IR without any accelerator-specific tuning and without dropping semantics.
What would settle it
Running the pipeline on a third accelerator whose hand-written tensor ISA is known to be complete, then checking whether the automatically produced spec either differs in observable behavior or fails to generate a working compiler backend.
Figures



read the original abstract
Numerous tensor accelerator designs have been proposed, yet most lack well-documented ISAs and compiler backends, limiting evaluation to a handful of operators. Recent work has shown that given a tensor-level ISA specification, complete software stacks including compiler backends can be automatically generated--but writing such specifications remains a manual, expert-driven process. We present ATLAAS, the first end-to-end MLIR-based pipeline that lifts RTL-extracted accelerator semantics to tensor ISA specifications. Starting from bit-level LLVM IR produced by prior architecture-level model extraction, ATLAAS applies an 8-pass semantic lifting pipeline that progressively recovers high-level tensor structure--MAC idioms, saturation semantics, multi-dimensional buffer organizations, and data layout transformations--emitting specifications that immediately enable automatic software stack generation through the ACT ecosystem. We evaluate ATLAAS on the Gemmini systolic-array accelerator, where the pipeline collapses bit-level MLIR by up to 92.9% on processing elements and 24-34% on controller modules. ATLAAS discovers hardware features omitted from the hand-written reference, with correctness validated via Z3 SMT equivalence proofs. Generality is confirmed on TVM's VTA processor, where the same pipeline lifts all four datapath modules without accelerator-specific changes, enabling an automated path from RTL to a performance-competitive compiler backend.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. ATLAAS presents the first end-to-end MLIR-based pipeline that lifts bit-level LLVM IR (extracted from RTL accelerator models) to high-level tensor ISA specifications via an 8-pass semantic lifting process. The passes progressively recover MAC idioms, saturation semantics, multi-dimensional buffers, and data-layout transformations, emitting specs that feed directly into the ACT ecosystem for automatic compiler-backend generation. Evaluation on Gemmini reports up to 92.9% collapse of bit-level MLIR on processing elements (24-34% on controllers) and discovery of omitted hardware features; the same untuned pipeline is shown to lift all four datapath modules of TVM's VTA, with Z3 SMT equivalence proofs used to validate correctness.
Significance. If the lifting pipeline is shown to be semantics-preserving and free of accelerator-specific tuning, the work would meaningfully reduce the manual effort required to obtain usable tensor ISA specifications, thereby enabling automated software-stack generation for a wider range of accelerators. The combination of an MLIR-based implementation, concrete size-reduction numbers, application to two distinct designs, and use of SMT-based validation constitutes a concrete engineering contribution; the reproducibility of the pipeline and the formal checks are particular strengths.
major comments (2)
- [§5 and §6] §5 (Gemmini evaluation) and §6 (VTA evaluation): the claim that the 8-pass pipeline recovers complete tensor structure 'without accelerator-specific changes' and 'without loss of semantics' rests on Z3 equivalence proofs, yet the manuscript does not state whether these proofs establish exhaustive functional equivalence (all operators, all input vectors, saturation boundaries, and layout transformations) or only equivalence on the newly discovered omitted features and sampled behaviors. If the latter, undetected semantic loss remains possible and directly weakens the 92.9% collapse claim.
- [§4] §4 (semantic lifting pipeline): the description of the eight passes does not provide a formal argument or invariant that each pass is semantics-preserving; without such an argument or an exhaustive equivalence check between the original bit-level IR and the final tensor spec, it is difficult to assess whether the progressive abstraction is total.
minor comments (2)
- [Table 1] Table 1 (Gemmini size-reduction results): the baseline 'bit-level MLIR' size should be reported alongside the post-lifting sizes so that the 92.9% figure can be independently verified.
- The manuscript would benefit from a short pseudocode or data-flow diagram of the eight passes to make the overall pipeline structure immediately clear to readers unfamiliar with MLIR dialects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the validation scope and semantics preservation arguments. We agree that the manuscript would benefit from greater clarity on these points and will revise accordingly while preserving the core technical contributions.
read point-by-point responses
-
Referee: [§5 and §6] §5 (Gemmini evaluation) and §6 (VTA evaluation): the claim that the 8-pass pipeline recovers complete tensor structure 'without accelerator-specific changes' and 'without loss of semantics' rests on Z3 equivalence proofs, yet the manuscript does not state whether these proofs establish exhaustive functional equivalence (all operators, all input vectors, saturation boundaries, and layout transformations) or only equivalence on the newly discovered omitted features and sampled behaviors. If the latter, undetected semantic loss remains possible and directly weakens the 92.9% collapse claim.
Authors: The Z3 equivalence proofs were performed on the specific tensor operations recovered by the pipeline, including the omitted hardware features identified in Gemmini, along with representative operators, input vectors, saturation behaviors, and layout transformations. These checks confirm that the lifted specifications compute identical results to the original bit-level IR for the abstracted structures. We do not claim exhaustive verification over the entire input space or all boundary conditions, which would be intractable. The 92.9% collapse figure quantifies the reduction from replacing verified bit-level patterns with their tensor equivalents. We will revise §5 and §6 to explicitly delineate the scope of the proofs and note that they validate the recovered semantics. revision: partial
-
Referee: [§4] §4 (semantic lifting pipeline): the description of the eight passes does not provide a formal argument or invariant that each pass is semantics-preserving; without such an argument or an exhaustive equivalence check between the original bit-level IR and the final tensor spec, it is difficult to assess whether the progressive abstraction is total.
Authors: Each pass is implemented via MLIR rewrites that substitute equivalent higher-level constructs for lower-level bit operations while preserving dataflow, computation results, and memory semantics by construction. The end-to-end Z3 validation supports overall correctness. We acknowledge that the manuscript lacks an explicit statement of per-pass invariants. In the revision we will add a subsection to §4 that articulates the semantic invariants maintained by each pass (e.g., equivalence of arithmetic results, buffer layouts, and control flow) and describes their composition, thereby addressing the concern about total abstraction. revision: yes
Circularity Check
No circularity: empirical tool pipeline with external validation
full rationale
The paper presents ATLAAS as an 8-pass MLIR pipeline that lifts bit-level LLVM IR to tensor ISA specifications, with claims resting on measured collapse ratios (92.9% on PEs), discovery of omitted features, and Z3 SMT equivalence proofs on Gemmini and VTA. No mathematical derivations, equations, fitted parameters, or predictions are described. The central results are obtained by applying the pipeline to concrete accelerators and checking outputs against reference implementations via an external solver (Z3), which does not reduce to self-definition or self-citation chains. The pipeline description and evaluation are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, San- jay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dandelion Mané, Rajat Monga, Sherry Moore, Derek Mur...
-
[2]
https://www.tensorflow.org/ Software available from tensorflow.org
TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. https://www.tensorflow.org/ Software available from tensorflow.org
-
[3]
Alon Amid, David Biancolin, Abraham Gonzalez, Daniel Grubb, Sagar Karandikar, Harrison Liew, Albert Magyar, Howard Mao, Albert Ou, Nathan Pemberton, et al
-
[4]
Chipyard: Integrated design, simulation, and implementation framework for custom socs.Ieee Micro40, 4 (2020), 10–21
2020
-
[5]
Krste Asanovic, Rimas Avizienis, Jonathan Bachrach, Scott Beamer, David Bian- colin, Christopher Celio, Henry Cook, Daniel Dabbelt, John Hauser, Adam Izraele- vitz, et al . 2016. The rocket chip generator.EECS Department, University of California, Berkeley, Tech. Rep. UCB/EECS-2016-174 (2016), 6–2
2016
-
[6]
2018.JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Yash Katariya, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018.JAX: composable transformations of Python+NumPy programs. http://github.com/jax-ml/jax
2018
-
[7]
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. 2018. {TVM}: An automated {End-to-End} optimizing compiler for deep learning. In13th USENIX symposium on operating systems design and implementation (OSDI 18). 578–594
2018
-
[8]
Yu-Hsin Chen, Tushar Krishna, Joel S Emer, and Vivienne Sze. 2016. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks.IEEE journal of solid-state circuits52, 1 (2016), 127–138
2016
-
[9]
Sharan Chetlur, Cliff Woolley, Philippe Vandermersch, Jonathan Cohen, John Tran, Bryan Catanzaro, and Evan Shelhamer. 2014. cuDNN: Efficient primitives for deep learning.arXiv preprint arXiv:1410.0759(2014)
work page Pith review arXiv 2014
-
[10]
NVIDIA Corporation. 2017. NVDLA: Open Source Deep Learning Accelerator. http://nvdla.org. Accessed: 2026-04-05
2017
-
[11]
Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: an efficient SMT solver. In Proceedings of the Theory and Practice of Software, 14th International Conference on Tools and Algorithms for the Construction and Analysis of Systems(Budapest, Hungary)(TACAS’08/ETAPS’08). Springer-Verlag, Berlin, Heidelberg, 337–340
2008
-
[12]
Alessandro Di Federico, Mathias Payer, and Giovanni Agosta. 2017. rev.ng: a unified binary analysis framework to recover CFGs and function boundaries. In Proceedings of the 26th International Conference on Compiler Construction(Austin, TX, USA)(CC 2017). Association for Computing Machinery, New York, NY, USA, 131–141. doi:10.1145/3033019.3033028
-
[13]
Schuyler Eldridge, Prithayan Barua, Aliaksei Chapyzhenka, Adam Izraelevitz, Jack Koenig, Chris Lattner, Andrew Lenharth, George Leontiev, Fabian Schuiki, Ram Sunder, et al. 2021. MLIR as hardware compiler infrastructure. InWorkshop on Open-Source EDA Technology (WOSET), Vol. 3
2021
-
[14]
Mathieu Fehr, Yuyou Fan, Hugo Pompougnac, John Regehr, and Tobias Grosser
-
[15]
First-Class Verification Dialects for MLIR.Proc. ACM Program. Lang.9, PLDI, Article 206 (June 2025), 25 pages. doi:10.1145/3729309
-
[16]
Hasan Genc, Seah Kim, Alon Amid, Ameer Haj-Ali, Vighnesh Iyer, Pranav Prakash, Jerry Zhao, Daniel Grubb, Harrison Liew, Howard Mao, et al . 2021. Gemmini: Enabling systematic deep-learning architecture evaluation via full- stack integration. In2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 769–774
2021
-
[17]
Reza Hojabr, Ali Sedaghati, Amirali Sharifian, Ahmad Khonsari, and Arrvindh Shriraman. 2021. SPAGHETTI: Streaming Accelerators for Highly Sparse GEMM on FPGAs. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 84–96. doi:10.1109/HPCA51647.2021.00017
- [18]
-
[19]
Bo-Yuan Huang, Steven Lyubomirsky, Yi Li, Mike He, Gus Henry Smith, Thierry Tambe, Akash Gaonkar, Vishal Canumalla, Andrew Cheung, Gu-Yeon Wei, Aarti Gupta, Zachary Tatlock, and Sharad Malik. 2024. Application-level Validation of Accelerator Designs Using a Formal Software/Hardware Interface.ACM Trans. Des. Autom. Electron. Syst.29, 2, Article 35 (Feb. 20...
2024
-
[20]
Bo-Yuan Huang, Hongce Zhang, Pramod Subramanyan, Yakir Vizel, Aarti Gupta, and Sharad Malik. 2018. Instruction-Level Abstraction (ILA): A Uniform Specifi- cation for System-on-Chip (SoC) Verification.ACM Trans. Des. Autom. Electron. Syst.24, 1, Article 10 (Dec. 2018), 24 pages. doi:10.1145/3282444
-
[21]
Yuka Ikarashi, Gilbert Louis Bernstein, Alex Reinking, Hasan Genc, and Jonathan Ragan-Kelley. 2022. Exocompilation for productive programming of hardware accelerators. InProceedings of the 43rd ACM SIGPLAN International Conference on Programming Language Design and Implementation(San Diego, CA, USA) (PLDI 2022). Association for Computing Machinery, New Yo...
-
[22]
2023.Intel Advanced Matrix Extensions (Intel AMX) Technology Brief
Intel Corporation. 2023.Intel Advanced Matrix Extensions (Intel AMX) Technology Brief. Technology Brief. Intel Corporation. https://intel.com
2023
-
[23]
Devansh Jain, Marco Frigo, Jai Arora, Akash Pardeshi, Zhihao Wang, Krut Patel, and Charith Mendis. 2025.Artifact of TAIDL: Tensor Accelerator ISA Definition Language with Auto-generation of Scalable Test Oracles. doi:10.5281/zenodo. 16934755
-
[24]
Devansh Jain, Marco Frigo, Jai Arora, Akash Pardeshi, Zhihao Wang, Krut Patel, and Charith Mendis. 2025. TAIDL: Tensor Accelerator ISA Definition Language with Auto-generation of Scalable Test Oracles. InProceedings of the 2025 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Machinery, New York, NY, USA, 1...
-
[25]
Devansh Jain, Akash Pardeshi, Marco Frigo, Krut Patel, Kaustubh Khulbe, Jai Arora, and Charith Mendis. 2025. ACT: Automatically Generating Compiler Backends from Tensor Accelerator ISA Descriptions. doi:10.48550/arXiv.2510. 09932
-
[26]
Norman P Jouppi, Cliff Young, Nishant Patil, David Patterson, Gaurav Agrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-datacenter performance analysis of a tensor processing unit. InProceedings of the 44th annual international symposium on computer architecture. 1–12
2017
-
[27]
Hyoukjun Kwon, Ananda Samajdar, and Tushar Krishna. 2018. Maeri: Enabling flexible dataflow mapping over dnn accelerators via reconfigurable interconnects. ACM Sigplan Notices53, 2 (2018), 461–475
2018
-
[28]
Yi-Hsiang Lai, Yuze Chi, Yuwei Hu, Jie Wang, Cody Hao Yu, Yuan Zhou, Jason Cong, and Zhiru Zhang. 2019. HeteroCL: A multi-paradigm programming in- frastructure for software-defined reconfigurable computing. InProceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. 242–251
2019
-
[29]
Chris Lattner, Mehdi Amini, Uday Bondhugula, Albert Cohen, Andy Davis, Jacques Pienaar, River Riddle, Tatiana Shpeisman, Nicolas Vasilache, and Olek- sandr Zinenko. 2021. MLIR: Scaling compiler infrastructure for domain specific computation. In2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2–14
2021
- [30]
-
[31]
LLVM Project. 2026. Chapter 5: Partial Lowering to Lower-Level Dialects for Optimization. https://mlir.llvm.org/docs/Tutorials/Toy/Ch-5/. MLIR tutorial documentation. Accessed: 2026-04-09
2026
-
[32]
LLVM Project. 2026. Linalg Dialect. https://mlir.llvm.org/docs/Dialects/Linalg/. MLIR documentation. Accessed: 2026-04-09
2026
-
[33]
LLVM Project. 2026. Pattern Rewriting: Generic DAG-to-DAG Rewriting. https: //mlir.llvm.org/docs/PatternRewriter/. MLIR documentation. Accessed: 2026-04- 09. Conference’17, July 2017, Washington, DC, USA Gao et al
2026
-
[34]
Thierry Moreau, Tianqi Chen, Luis Vega, Jared Roesch, Eddie Yan, Lianmin Zheng, Josh Fromm, Ziheng Jiang, Luis Ceze, Carlos Guestrin, et al. 2019. A hardware– software blueprint for flexible deep learning specialization.IEEE Micro39, 5 (2019), 8–16
2019
-
[35]
John Nickolls, Ian Buck, Michael Garland, and Kevin Skadron. 2008. Scalable parallel programming with CUDA.ACM Queue6, 2 (2008), 40–53
2008
- [36]
-
[37]
Rachit Nigam, Samuel Thomas, Zhijing Li, and Adrian Sampson. 2021. A com- piler infrastructure for accelerator generators. InProceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems(Virtual, USA)(ASPLOS ’21). Association for Computing Machinery, New York, NY, USA, 804–817. doi:10.1145/34...
-
[38]
oneDNN Contributors. [n. d.].oneAPI Deep Neural Network Library (oneDNN). https://github.com/uxlfoundation/oneDNN
-
[39]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems32 (2019)
2019
- [40]
-
[41]
Eric Qin, Ananda Samajdar, Hyoukjun Kwon, Vineet Nadella, Sudarshan Srini- vasan, Dipankar Das, Bharat Kaul, and Tushar Krishna. 2020. Sigma: A sparse and irregular gemm accelerator with flexible interconnects for dnn training. In 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 58–70
2020
-
[42]
Amit Sabne. 2020. XLA : Compiling Machine Learning for Peak Performance
2020
-
[43]
Hardik Sharma, Jongse Park, Divya Mahajan, Emmanuel Amaro, Joon Kyung Kim, Chenkai Shao, Asit Mishra, and Hadi Esmaeilzadeh. 2016. From high-level deep neural models to FPGAs. In2016 49th Annual IEEE/ACM international symposium on microarchitecture (MICRO). IEEE, 1–12
2016
-
[44]
Ko, Yuji Chai, Coleman Hooper, Marco Donato, Paul N
Thierry Tambe, En-Yu Yang, Glenn G. Ko, Yuji Chai, Coleman Hooper, Marco Donato, Paul N. Whatmough, Alexander M. Rush, David Brooks, and Gu-Yeon Wei. 2021. A 25mm2 SoC for IoT Devices with 18ms Noise Robust Speech-to- Text Latency via Bayesian Speech Denoising and Attention-Based Sequence-to- Sequence DNN Speech Recognition in 16nm FinFET. InInternational...
2021
-
[45]
2019.IREE
The IREE Authors. 2019.IREE. https://github.com/iree-org/iree
2019
-
[46]
Jianming Tong, Anirudh Itagi, Prasanth Chatarasi, and Tushar Krishna. 2024. Feather: A reconfigurable accelerator with data reordering support for low- cost on-chip dataflow switching. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, 198–214
2024
-
[47]
UC Berkeley Architecture Research. 2026. Gemmini RoCC Tests. https://github. com/ucb-bar/gemmini-rocc-tests. Bare-metal test suite for the Gemmini acceler- ator
2026
-
[48]
UC Berkeley Architecture Research. 2026. Gemmini Spike Functional Simula- tor. https://github.com/ucb-bar/libgemmini. Cycle-level functional model for Gemmini
2026
-
[49]
Rangharajan Venkatesan, Yakun Sophia Shao, Miaorong Wang, Jason Clemons, Steve Dai, Matthew Fojtik, Ben Keller, Alicia Klinefelter, Nathaniel Pinckney, Priyanka Raina, et al. 2019. Magnet: A modular accelerator generator for neural networks. In2019 IEEE/ACM International Conference on Computer-Aided Design (ICCAD). IEEE, 1–8
2019
-
[50]
Haoyuan Wu, Zhuolun He, Xinyun Zhang, Xufeng Yao, Su Zheng, Haisheng Zheng, and Bei Yu. 2024. ChatEDA: A Large Language Model Powered Au- tonomous Agent for EDA.IEEE Transactions on Computer-Aided Design of Inte- grated Circuits and Systems43, 10 (2024), 3184–3197
2024
-
[51]
Zhongzhi Yu, Mingjie Liu, Michael Zimmer, Yingyan Celine, Yong Liu, and Haox- ing Ren. 2025. Spec2rtl-agent: Automated hardware code generation from com- plex specifications using llm agent systems. In2025 IEEE International Conference on LLM-Aided Design (ICLAD). IEEE, 37–43
2025
-
[52]
Yu Zeng, Aarti Gupta, and Sharad Malik. 2022. Automatic Generation of Architecture-Level Models from RTL Designs for Processors and Accelerators. In2022 Design, Automation & Test in Europe Conference & Exhibition (DATE). 460–465. doi:10.23919/DATE54114.2022.9774527
-
[53]
Yu Zeng, Bo-Yuan Huang, Hongce Zhang, Aarti Gupta, and Sharad Malik. 2021. Generating Architecture-Level Abstractions from RTL Designs for Processors and Accelerators Part I: Determining Architectural State Variables. In2021 IEEE/ACM International Conference On Computer Aided Design (ICCAD). 1–9. doi:10.1109/ ICCAD51958.2021.9643584
-
[54]
Xiaofan Zhang, Junsong Wang, Chao Zhu, Yonghua Lin, Jinjun Xiong, Wen-mei Hwu, and Deming Chen. 2018. DNNBuilder: an automated tool for building high-performance DNN hardware accelerators for FPGAs. InProceedings of the International Conference on Computer-Aided Design(San Diego, California)(IC- CAD ’18). Association for Computing Machinery, New York, NY,...
- [55]
- [56]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.