Recognition: unknown
Racing to Release: Priority, Congestion, and Community Recognition in Open-Source LLM Ecosystems
Pith reviewed 2026-05-10 12:00 UTC · model grok-4.3
The pith
Later releases and crowded fields around base models are linked to weaker community recognition for derivative LLMs on Hugging Face.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Drawing on the Race-to-the-Bottom framework, the study shows that later derivative model releases and higher competitive crowding are associated with reduced community recognition in open-source LLM ecosystems, after controlling for model and ecosystem prominence. Prominent base models draw concentrated derivative entry, yet the first movers and those in less crowded spaces receive stronger platform feedback.
What carries the argument
The Race-to-the-Bottom framework applied to release timing, competitive density around base models, and platform engagement metrics on Hugging Face.
If this is right
- Derivative models released earlier tend to secure more community attention than later ones in the same base-model lineage.
- Higher numbers of competing derivatives around a given base model dilute recognition for each individual release.
- Competition for priority continues to organize attention in open-source AI even under rapid platform feedback.
- Adjusting for base-model prominence does not eliminate the observed effects of release order and crowding.
Where Pith is reading between the lines
- Developers may face incentives to accelerate releases to capture early attention, potentially affecting the pace of quality improvements.
- Platform design choices that highlight release order or reduce visibility of crowded categories could alter recognition patterns.
- The same priority dynamics might appear in other open-source domains where base artifacts attract many derivatives under public metrics.
Load-bearing premise
Platform metrics such as downloads or likes accurately capture community recognition without being driven by unmeasured differences in model quality or the timing of base model releases.
What would settle it
A re-analysis that adds direct controls for model performance benchmarks or exact base-model release dates and finds the timing and crowding associations disappear would falsify the central claim.
Figures

read the original abstract
Open-source large language models have made platforms such as Hugging Face central hubs for decentralized AI innovation. Yet these ecosystems are shaped not only by collaboration, but also by competition for priority and community attention. Drawing on Hill and Stein's Race-to-the-Bottom framework, this study extends the logic of project potential, maturation, competition, and quality from scientific production to open-source LLM ecosystems, where prominent base models attract concentrated derivative entry under rapid and highly visible platform feedback. Using a large-scale sample of derivative models on Hugging Face, we find that later releases and more crowded competitive environments are both associated with weaker community recognition, even after accounting for differences in model and ecosystem prominence. These findings suggest that competition for priority remains an important organizing force in open-source LLM ecosystems, shaping which derivative innovations receive community recognition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends Hill and Stein's Race-to-the-Bottom framework to open-source LLM derivative models on Hugging Face. It uses a large-scale observational sample to show that later releases and higher crowding in competitive environments are negatively associated with community recognition metrics (e.g., downloads, likes), even after controlling for model and ecosystem prominence. The central claim is that priority competition remains an organizing force shaping which derivatives receive attention.
Significance. If the associations are robust to unmeasured confounders, the result would provide empirical evidence that competitive dynamics for priority and attention operate in decentralized AI innovation platforms, extending prior work on scientific races to LLM ecosystems. The large-scale platform data and focus on derivative models are strengths; the work could inform platform policies on visibility and incentives if identification concerns are addressed.
major comments (2)
- [§4] §4 (Regression Analysis): The central associations between release timing/crowding and recognition rest on OLS or similar specifications that control only for model/ecosystem prominence. No base-model cohort fixed effects, matching on release windows, or instrumental variables are reported to address omitted variable bias from unmeasured model quality, fine-tuning differences, or exact base-model release timing, which could correlate with both the key regressors and outcomes.
- [§3] §3 (Data and Measurement): The abstract claims controls for 'differences in model and ecosystem prominence,' but without details on how recognition (e.g., downloads vs. likes) and crowding are operationalized or robustness to alternative prominence proxies, it is unclear whether the negative coefficients reflect priority effects or residual confounding.
minor comments (2)
- [Abstract] Abstract and §2: The extension of Hill and Stein is summarized at a high level; a brief table comparing the original framework's constructs to the LLM application would improve clarity.
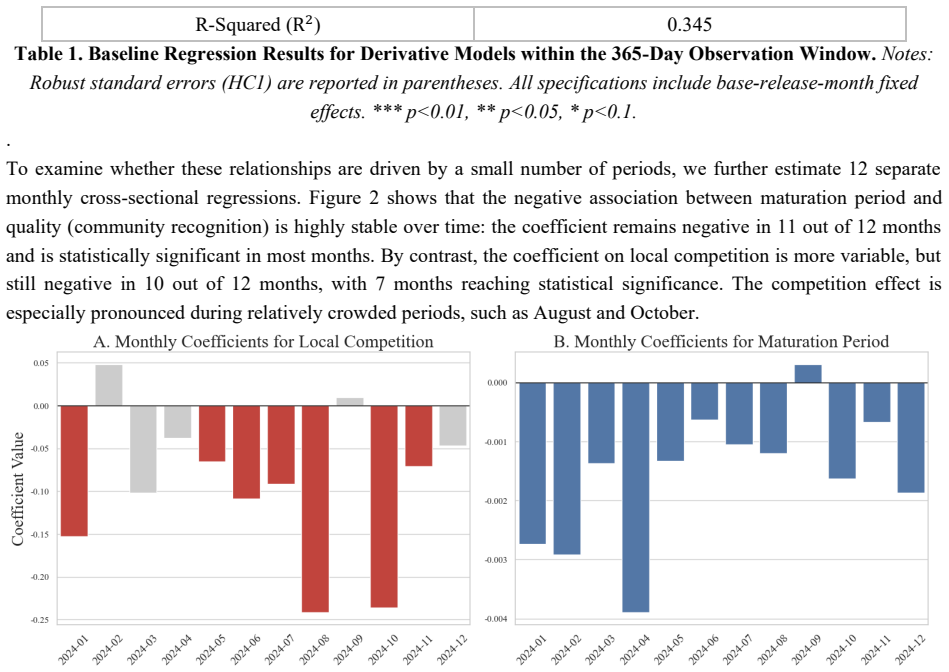
- [Figures] Figure 1 or equivalent: Ensure that any visualization of crowding or release order distributions includes sample sizes and confidence intervals for the reported associations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript extending the Race-to-the-Bottom framework to open-source LLM derivatives. The feedback highlights important identification considerations, and we address each major point below with plans for revision.
read point-by-point responses
-
Referee: [§4] §4 (Regression Analysis): The central associations between release timing/crowding and recognition rest on OLS or similar specifications that control only for model/ecosystem prominence. No base-model cohort fixed effects, matching on release windows, or instrumental variables are reported to address omitted variable bias from unmeasured model quality, fine-tuning differences, or exact base-model release timing, which could correlate with both the key regressors and outcomes.
Authors: We agree that omitted variable bias from unmeasured quality or timing factors is a valid concern in this observational setting. Our current models control for observable model and ecosystem prominence as stated in the abstract and methods. In revision, we will add base-model cohort fixed effects and report matching results on release windows to strengthen identification. Suitable instruments for priority and crowding are not readily available without introducing new assumptions, so we will explicitly discuss this limitation while showing that the negative associations persist under the expanded robustness checks. revision: partial
-
Referee: [§3] §3 (Data and Measurement): The abstract claims controls for 'differences in model and ecosystem prominence,' but without details on how recognition (e.g., downloads vs. likes) and crowding are operationalized or robustness to alternative prominence proxies, it is unclear whether the negative coefficients reflect priority effects or residual confounding.
Authors: We will expand the data and measurement section to detail the operationalization of recognition (downloads and likes) and crowding variables, including exact definitions and data sources. We will also add robustness tables using alternative prominence proxies (e.g., base-model popularity metrics and ecosystem size indicators) to confirm the associations are not driven by residual confounding. These changes will make the controls and results more transparent. revision: yes
Circularity Check
No significant circularity: empirical observational study with independent data patterns
full rationale
The paper conducts a large-scale empirical analysis of derivative models on Hugging Face, reporting associations between release timing, crowding, and community recognition metrics via regressions that control for model and ecosystem prominence. No mathematical derivation chain, first-principles result, or fitted parameter is presented that reduces by construction to its own inputs. The abstract and described approach draw on an external framework (Hill and Stein) without self-citation load-bearing or ansatz smuggling; claims rest on observable data patterns rather than self-referential definitions or renamed known results. This is a standard observational design whose validity hinges on external data and controls, not internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amanda Askell et al., ‘The Role of Cooperation in Responsible AI Development’, arXiv:1907.04534, preprint, arXiv, 10 July 2019, https://doi.org/10.48550/arXiv.1907.04534. Bengüsu Özcan et al., ‘Beyond the Binary: A Nuanced Path for Open-Weight Advanced AI’, arXiv:2602.19682, preprint, arXiv, 23 February 2026, https://doi.org/10.48550/arXiv.2602.19682. Cat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.