Recognition: unknown
Reconstruction of a 3D wireframe from a single line drawing via generative depth estimation
Pith reviewed 2026-05-10 14:04 UTC · model grok-4.3
The pith
A generative depth estimation model reconstructs 3D wireframes from single line drawings
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
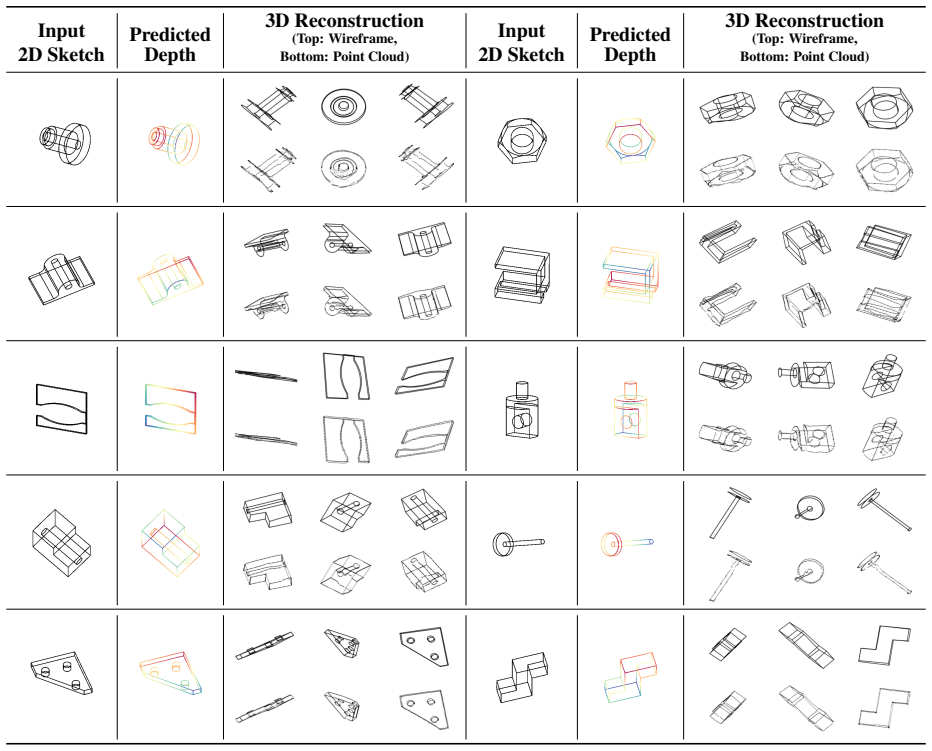
By framing the reconstruction of 3D wireframes from single line drawings as a conditional dense depth estimation task, a Latent Diffusion Model equipped with a conditioning framework resolves the inherent ambiguities of orthographic projections after training on a dataset of over one million image-depth pairs, yielding robust performance with 5.3 percent average depth error across varying shape complexities.
What carries the argument
Latent Diffusion Model with conditioning framework that performs conditional dense depth estimation on line drawings to generate the depth maps needed for 3D wireframe output.
If this is right
- The method works across shapes of different complexity.
- Depth error averages 5.3 percent.
- It supplies an alternative where standard monocular depth methods fail on line drawings.
- It supports direct conversion of freehand sketches into 3D models for CAD use.
Where Pith is reading between the lines
- The depth estimation step could combine with sketch cleanup tools to handle imperfect user input.
- The same conditioning approach might extend to other 2D-to-3D tasks such as diagram lifting or map reconstruction.
- Performance on drawings that include perspective or heavy stylization remains untested and could be checked directly.
- Integration into interactive design software would let users iterate on 3D shapes starting from a single sketch.
Load-bearing premise
Training on a large set of image-depth pairs will generalize to resolve the ambiguities of real freehand orthographic line drawings sufficiently for accurate wireframe output.
What would settle it
Evaluating the trained model on real freehand line drawings paired with ground-truth 3D models and observing depth errors substantially higher than 5.3 percent would falsify the claim of robust generalization.
Figures








read the original abstract
The conversion of 2D freehand sketches into 3D models remains a pivotal challenge in computer vision, bridging the gap between fluent sketching and CAD. Traditional monocular depth reconstruction techniques are not suitable for line drawing interpretation. We propose a generative approach by framing reconstruction as a conditional dense depth estimation task. To achieve this, we implemented a Latent Diffusion Model (LDM) with a conditioning framework to resolve the inherent ambiguities of orthographic projections. We trained our model using a dataset of over one million image-depth pairs. Our framework demonstrated robust performance across varying shape complexities, with 5.3 percent average depth error.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes reconstructing 3D wireframes from single 2D freehand line drawings by framing the task as conditional dense depth estimation with a Latent Diffusion Model (LDM). The model is trained on a dataset of over one million image-depth pairs and is reported to achieve 5.3% average depth error while handling orthographic ambiguities across varying shape complexities.
Significance. If the reported depth accuracy generalizes to real freehand sketches and the dense depth maps can be converted into explicit wireframes, the work could advance sketch-to-CAD pipelines. The generative framing for resolving projection ambiguities is a reasonable direction, but the absence of any description of the conditioning mechanism, training data domain (line drawings vs. shaded renders), test-set composition, or post-processing to wireframes makes the practical significance impossible to evaluate from the provided material.
major comments (2)
- [Abstract] Abstract: the performance claim of '5.3 percent average depth error' supplies no definition of the metric (relative, absolute, or otherwise), no description of the test set (synthetic renders vs. real freehand orthographic sketches), and no baseline comparisons. Without these details the central empirical result cannot be assessed.
- [Abstract] Abstract: the training data is described only as 'image-depth pairs' with no indication whether the images are line drawings matching the target input distribution or shaded renders; this directly affects whether the reported error supports generalization to freehand sketches, which is the load-bearing assumption for the wireframe reconstruction claim.
minor comments (1)
- [Abstract] The abstract states the method 'resolves the inherent ambiguities of orthographic projections' but provides no concrete description of the conditioning framework (e.g., edge-map control, cross-attention) or the depth-to-wireframe conversion step.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. The comments correctly identify areas where additional specificity is needed to allow readers to properly evaluate the central claims. We will revise the abstract accordingly in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claim of '5.3 percent average depth error' supplies no definition of the metric (relative, absolute, or otherwise), no description of the test set (synthetic renders vs. real freehand orthographic sketches), and no baseline comparisons. Without these details the central empirical result cannot be assessed.
Authors: We agree that the abstract lacks the necessary precision on these points. In the revised manuscript we will expand the abstract to define the reported figure as mean relative depth error (average of |estimated - ground-truth| / ground-truth), to state that the test set comprises synthetic orthographic line drawings generated from 3D models spanning a range of complexities, and to include quantitative comparisons against baseline depth-estimation approaches. These additions will be made without altering the reported numerical result. revision: yes
-
Referee: [Abstract] Abstract: the training data is described only as 'image-depth pairs' with no indication whether the images are line drawings matching the target input distribution or shaded renders; this directly affects whether the reported error supports generalization to freehand sketches, which is the load-bearing assumption for the wireframe reconstruction claim.
Authors: The training corpus consists of line drawings paired with depth maps, synthesized to match the distribution of freehand orthographic sketches. The current abstract is too terse on this point. We will revise the abstract to explicitly state that the image-depth pairs are line drawings (not shaded renders) and that the data-generation process was designed to approximate freehand input statistics. This clarification will be added while preserving the existing description of dataset size. revision: yes
Circularity Check
No significant circularity; empirical ML result with no derivations
full rationale
The paper frames 3D wireframe reconstruction as a conditional dense depth estimation task solved via a Latent Diffusion Model (LDM) trained on >1M image-depth pairs, reporting 5.3% average depth error as an empirical outcome. No equations, derivations, or first-principles claims appear in the abstract or described content. The result is a trained model's performance on held-out data rather than any quantity forced by definition, fitted parameter renamed as prediction, or self-citation chain. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. This is a standard data-driven computer vision pipeline whose central claim (generalization to freehand sketches) is falsifiable via external test sets and does not reduce to its training inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Orthographic line drawings contain sufficient information for a generative model to resolve depth ambiguities when conditioned properly
- domain assumption A dataset of over one million image-depth pairs is representative of real freehand sketches
Reference graph
Works this paper leans on
-
[1]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
X. Bi et al. Deepseek llm: Scaling open-source language models with longtermism.arXiv preprint arXiv:2401.02954, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, and J. Uszkoreit. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Eigen, C
D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. InAd- vances in Neural Information Processing Systems (NeurIPS), 2014
2014
-
[4]
Eissen and R
K. Eissen and R. Steur.Sketching: Drawing techniques for product designers. BIS Publishers, 2008
2008
-
[5]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilis- tic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[6]
D. A. Huffman. Impossible objects as nonsense sentences. Machine Intelligence, 6:295–323, 1971
1971
-
[7]
B. Ke, A. Obukhov, S. Huang, N. Metzger, R. C. Daudt, and K. Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9492–9502, 2024
2024
-
[8]
D. P. Kingma and M. Welling. An introduction to variational autoencoders.Foundations and Trends in Machine Learning, 12(4):307–392, 2019
2019
-
[9]
S. Koch, A. Matveev, Z. Jiang, F. Williams, A. Artemov, E. Burnaev, A. Somov, D. Zorin, and D. Panozzo. Abc: A big cad model dataset for geometric deep learning. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9601–9611, 2019
2019
-
[10]
Koley, T
S. Koley, T. K. Dutta, A. Sain, P. N. Chowdhury, A. K. Bhunia, and Y . Z. Song. Sketchfusion: Learning universal sketch features through fusing foundation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2556–2567, 2025
2025
-
[11]
C. Li, H. Pan, A. Bousseau, and N. J. Mitra. Sketch2cad: Sequential cad modeling by sketching in context.ACM Trans- actions on Graphics (TOG), 39(6):1–14, 2020
2020
-
[12]
C. Li, H. Pan, A. Bousseau, and N. J. Mitra. Free2cad: Parsing freehand drawings into cad commands.ACM Transactions on Graphics (TOG), 41(4):1–16, 2022
2022
-
[13]
Lipson and M
H. Lipson and M. Shpitalni. Optimization-based reconstruc- tion of a 3d object from a single freehand line drawing. Computer-Aided Design, 28(8):651–663, 1996
1996
-
[14]
Lipson and M
H. Lipson and M. Shpitalni. Correlation-based reconstruc- tion of a 3d object from a single freehand sketch. InACM SIGGRAPH 2007 Courses, pages 44–es, 2007
2007
-
[15]
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 9298–9309, 2023
2023
-
[16]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regular- ization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
N. J. Mitra, M. Pauly, M. Wand, and D. Ceylan. Structure- aware shape processing.Eurographics State of the Art Re- ports, 32(2):1–21, 2013
2013
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, and P. Bojanowski. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Paszke, S
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, S. Chintala, et al. Pytorch: An imperative style, high- performance deep learning library. InAdvances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[20]
L. S. Penrose and R. Penrose. Impossible objects: A special type of visual illusion.British Journal of Psychology, 49(1): 31–33, 1958
1958
-
[21]
Ranftl, K
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(3):1623–1637, 2020
2020
-
[22]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Om- mer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 10684–10695, 2022. 12
2022
-
[23]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical Im- age Computing and Computer-Assisted Intervention–MICCAI 2015, pages 234–241. Springer, 2015
2015
- [24]
-
[25]
Shpitalni and H
M. Shpitalni and H. Lipson. Identification of faces in a 2d line drawing projection of a wireframe object.IEEE Transactions on Pattern Analysis and Machine Intelligence, 18(10):1000– 1012, 1996
1996
-
[26]
O. Siméoni et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Sugihara.Machine Interpretation of Line Drawings
K. Sugihara.Machine Interpretation of Line Drawings. MIT Press, 1986
1986
-
[28]
N. Wang, Y . Zhang, Z. Li, Y . Fu, W. Liu, and Y . G. Jiang. Pixel2mesh: Generating 3d mesh models from single rgb images. InProceedings of the European Conference on Com- puter Vision (ECCV), pages 52–67, 2018
2018
-
[29]
Wang et al
X. Wang et al. Neural face identification in a 2d wireframe projection of a manifold object.IEEE Transactions on Visu- alization and Computer Graphics, 2022
2022
-
[30]
T. Wolf, L. Debut, V . Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, and J. Brew. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771, 2019
work page internal anchor Pith review arXiv 1910
-
[31]
R. Wu, C. Xiao, and C. Zheng. Deepcad: A deep generative network for computer-aided design models. InProceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, pages 6772–6782, 2021
2021
-
[32]
Xiang, Z
J. Xiang, Z. Lv, S. Xu, Y . Deng, R. Wang, B. Zhang, et al. Structured 3d latents for scalable and versatile 3d generation. InProceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, pages 21469– 21480, 2025
2025
-
[33]
Q. W. Yan, C. L. P. Chen, and Z. Tang. Efficient algorithm for the reconstruction of 3d objects from orthographic projections. Computer-Aided Design, 26(9):699–717, 1994
1994
-
[34]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unla- beled data. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10371– 10381, 2024
2024
-
[35]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023
2023
-
[36]
L. Zhou, L. Zhang, and N. Konz. Computer vision techniques in manufacturing.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 53(1):105–117, 2023. 13
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.