Recognition: unknown
MM-Doc-R1: Training Agents for Long Document Visual Question Answering through Multi-turn Reinforcement Learning
Pith reviewed 2026-05-10 13:50 UTC · model grok-4.3
The pith
MM-Doc-R1 trains vision-aware agents with multi-turn reinforcement learning to answer complex questions over long documents more accurately than single-pass retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
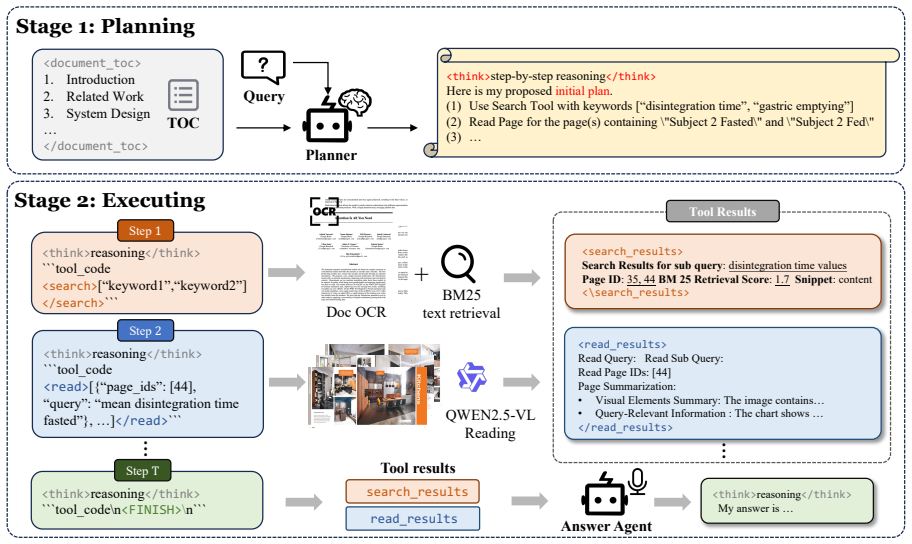
MM-Doc-R1 employs an agentic, vision-aware workflow that addresses long-document VQA through iterative information discovery and synthesis. The training uses Similarity-based Policy Optimization (SPO), which calculates a more precise baseline by similarity-weighted averaging of rewards across multiple trajectories. This corrects the bias in GRPO that applies the initial state's baseline to all intermediate states. The resulting agents achieve 10.4 percent higher performance than previous baselines on the MMLongbench-Doc benchmark, with SPO outperforming GRPO by 5.0 percent on Qwen3-8B and 6.1 percent on Qwen3-4B.
What carries the argument
Similarity-based Policy Optimization (SPO), which computes reward baselines via semantic-similarity-weighted averaging of trajectories in multi-turn reinforcement learning for agents.
If this is right
- Long-document visual question answering can shift from single-pass retrieval to iterative agent workflows that actively seek and combine evidence.
- Multi-turn reinforcement learning benefits from baseline estimates that account for trajectory similarity rather than uniform or initial-state values.
- The integrated framework raises accuracy on complex multi-hop queries that require synthesis across extended visual documents.
- SPO yields measurable training gains of 5 to 6 percent over GRPO when applied to models of different sizes.
Where Pith is reading between the lines
- The same similarity-weighted baseline approach could be tested in other multi-turn agent settings such as web navigation or tool-calling tasks where trajectory overlap is common.
- Because the workflow already incorporates vision, the method may extend to other multimodal long-context problems without major redesign.
- Refining the similarity function or combining it with additional signals might further stabilize learning in longer interaction sequences.
Load-bearing premise
That semantic similarity between trajectories produces a more accurate and less biased baseline estimate than standard methods without introducing new errors from the chosen similarity measure.
What would settle it
Re-training the same agents on the MMLongbench-Doc benchmark with GRPO instead of SPO and finding no performance difference or a reversal would show that the similarity-weighted baseline does not deliver the claimed advantage.
Figures




read the original abstract
Conventional Retrieval-Augmented Generation (RAG) systems often struggle with complex multi-hop queries over long documents due to their single-pass retrieval. We introduce MM-Doc-R1, a novel framework that employs an agentic, vision-aware workflow to address long document visual question answering through iterative information discovery and synthesis. To incentivize the information seeking capabilities of our agents, we propose Similarity-based Policy Optimization (SPO), addressing baseline estimation bias in existing multi-turn reinforcement learning (RL) algorithms like GRPO. Our core insight is that in multi-turn RL, the more semantically similar two trajectories are, the more accurate their shared baseline estimation becomes. Leveraging this, SPO calculates a more precise baseline by similarity-weighted averaging of rewards across multiple trajectories, unlike GRPO which inappropriately applies the initial state's baseline to all intermediate states. This provides a more stable and accurate learning signal for our agents, leading to superior training performance that surpasses GRPO. Our experiments on the MMLongbench-Doc benchmark show that MM-Doc-R1 outperforms previous baselines by 10.4%. Furthermore, SPO demonstrates superior performance over GRPO, boosting results by 5.0% with Qwen3-8B and 6.1% with Qwen3-4B. These results highlight the effectiveness of our integrated framework and novel training algorithm in advancing the state-of-the-art for complex, long-document visual question answering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MM-Doc-R1, an agentic vision-aware framework for long-document visual question answering that performs iterative information discovery and synthesis. It proposes Similarity-based Policy Optimization (SPO) as a multi-turn RL algorithm that computes baselines via similarity-weighted averaging of rewards from semantically similar trajectories, in contrast to GRPO. On the MMLongbench-Doc benchmark, MM-Doc-R1 is reported to outperform prior baselines by 10.4%, with SPO providing additional gains of 5.0% (Qwen3-8B) and 6.1% (Qwen3-4B).
Significance. If the reported gains are reproducible and the SPO mechanism is shown to be non-circular, the work would offer a practical advance in training agents for complex multi-hop document VQA tasks. The semantic-similarity baseline idea addresses a known issue in multi-turn RL and could generalize beyond this domain, but the absence of implementation details, derivations, and statistical analysis currently limits assessment of its broader impact.
major comments (2)
- Abstract and Experiments section: performance claims of 10.4% overall improvement and 5.0–6.1% from SPO are stated without any description of baselines, implementation of SPO, number of runs, statistical tests, or error analysis, preventing evaluation of whether the central empirical claim holds.
- SPO method description: the core claim that semantic similarity yields a more accurate baseline is presented without equations, pseudocode, or derivation showing how the weighted average is computed or why it avoids the bias attributed to GRPO; this leaves open whether the baseline remains independently grounded or reduces to a fitted quantity on the same trajectories.
minor comments (1)
- The abstract uses the term 'vision-aware workflow' without defining what visual processing components are involved or how they integrate with the RL loop.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below and will make substantial revisions to enhance clarity, formalization, and empirical rigor.
read point-by-point responses
-
Referee: Abstract and Experiments section: performance claims of 10.4% overall improvement and 5.0–6.1% from SPO are stated without any description of baselines, implementation of SPO, number of runs, statistical tests, or error analysis, preventing evaluation of whether the central empirical claim holds.
Authors: We acknowledge that the current manuscript version presents the performance claims in the abstract and experiments section without adequate supporting details on baselines, SPO implementation specifics, number of runs, statistical tests, or error analysis. This is a valid concern that limits full assessment. In the revised manuscript, we will expand the experiments section with: (1) explicit descriptions of all baselines (including standard RAG variants and prior agentic methods), (2) full implementation details of SPO including similarity computation, weighting formula, and hyperparameters, (3) results from multiple independent runs (e.g., 5 random seeds) with standard deviations and error bars, and (4) statistical significance tests (e.g., paired t-tests) along with error analysis. The abstract will be updated to reference these additions for better context. revision: yes
-
Referee: SPO method description: the core claim that semantic similarity yields a more accurate baseline is presented without equations, pseudocode, or derivation showing how the weighted average is computed or why it avoids the bias attributed to GRPO; this leaves open whether the baseline remains independently grounded or reduces to a fitted quantity on the same trajectories.
Authors: We agree that the SPO description requires formalization to substantiate the core claim. The current text relies on intuition without equations or pseudocode. In the revision, we will add: (1) the mathematical formulation for the similarity-weighted baseline (including the similarity metric and weighted averaging equation), (2) pseudocode for the full SPO algorithm, and (3) a derivation explaining how semantic similarity produces a more accurate baseline than GRPO by weighting trajectories based on semantic proximity rather than applying a single initial-state baseline. We will explicitly clarify that the baseline is computed from an independent pool of sampled trajectories (not the current one being optimized), ensuring it remains grounded and non-circular. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper introduces MM-Doc-R1 as an agentic framework and SPO as a similarity-weighted baseline method for multi-turn RL, with the core insight stated as an empirical modeling choice rather than a derived necessity. Reported gains (10.4% overall, 5.0-6.1% from SPO) are tied to external benchmark results on MMLongbench-Doc rather than any internal reduction. No equations, self-citations, or parameter fits are shown that would make the baseline computation or performance claims equivalent to the inputs by construction. The approach is self-contained against the stated benchmarks and does not rely on load-bearing self-references or tautological definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard assumptions of policy gradient methods in multi-turn reinforcement learning apply, including the existence of a baseline that can be improved by similarity weighting.
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Colpali: Efficient document retrieval with vision language models. InThe Thirteenth Interna- tional Conference on Learning Representations. Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A sub query #### Instructions
-
[3]
First, extract all visual elements: - Tables - Figures - Charts - Images - Text content
-
[4]
Then, identify information relevant to: - Origin Query - Sub Query
-
[5]
Cannot answer due to insufficient data
Format your output as: - Visual Elements Summary - Query-Relevant Information (text and visual elements) - Key Findings #### Important Notes - Base your analysis strictly on the provided images - Do not make assumptions or add information beyond what is shown - If required information is missing, clearly state: "Cannot answer due to insufficient data" - T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.