Recognition: unknown
Efficient Multi-View 3D Object Detection by Dynamic Token Selection and Fine-Tuning
Pith reviewed 2026-05-10 13:30 UTC · model grok-4.3
The pith
An image token compensator enables dynamic layer-wise token selection in ViT backbones for multi-view 3D detection, cutting GFLOPs by 48-55 percent while raising accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
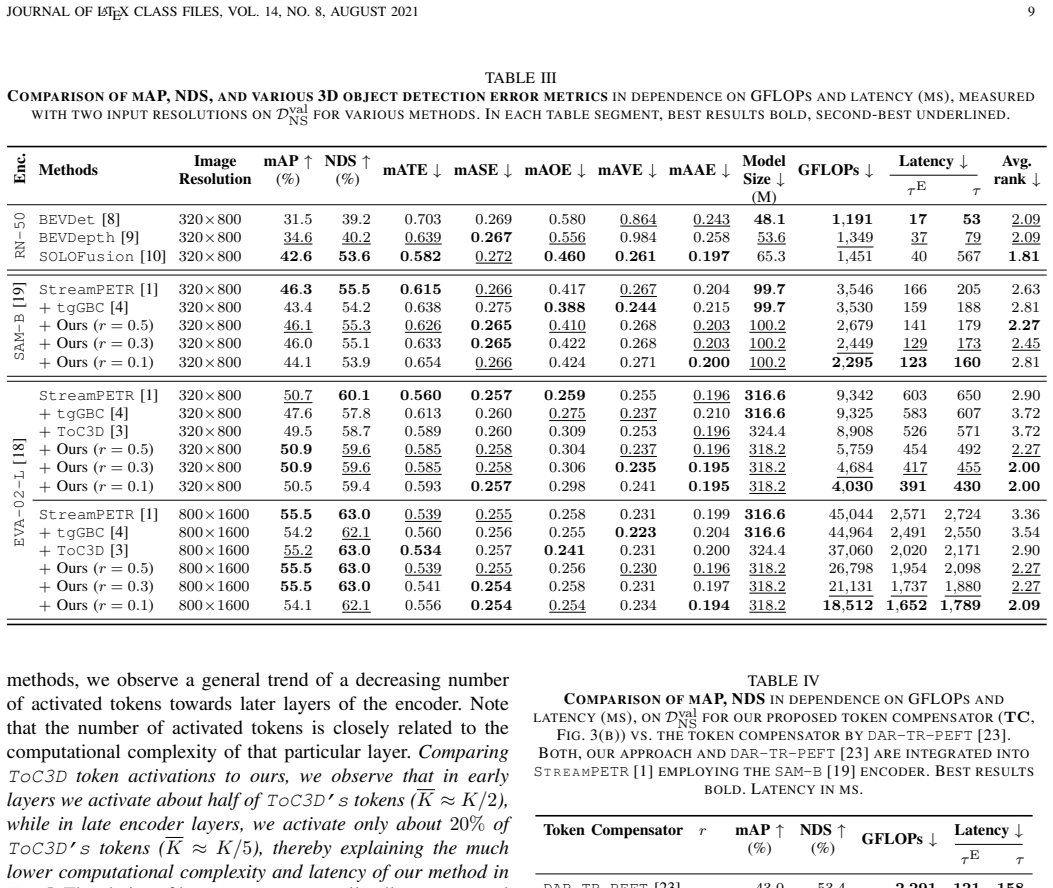
The image token compensator combined with dynamic token selection allows variable pruning ratios at each ViT layer while preserving the information needed for 3D detection; the parameter-efficient fine-tuning strategy updates only the added modules rather than the entire backbone, producing 48 to 55 percent fewer GFLOPs, 9 to 25 percent lower inference latency on an NVIDIA GV100 GPU, and 1.0 to 2.8 percent higher mAP plus 0.4 to 1.2 percent higher NDS than the prior state-of-the-art ToC3D method.
What carries the argument
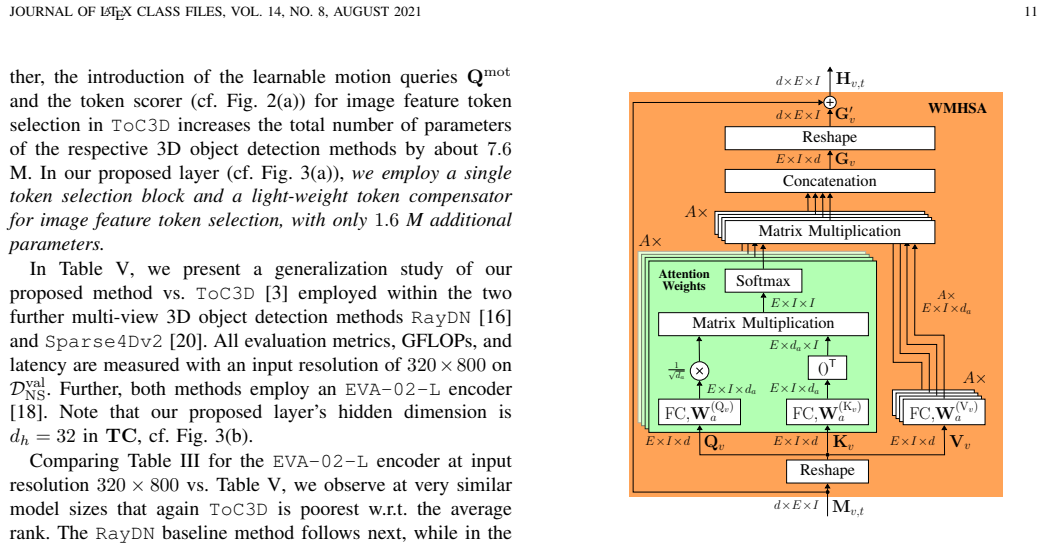
The image token compensator, a lightweight module that restores information for tokens chosen dynamically per layer, together with the parameter-efficient fine-tuning adapter that trains only 1.6 million new parameters.
If this is right
- Dynamic per-layer ratios adapt token count to the actual content of each layer, unlike fixed ratios that waste compute at some depths.
- Training only 1.6 million parameters lets the same modules be attached to any ViT-based multi-view detector without retraining the full backbone.
- The efficiency gains hold across three separate multi-view 3D detection pipelines on the large-scale NuScenes dataset.
- Both training and inference become faster because token selection ratios are no longer fixed in advance.
Where Pith is reading between the lines
- The approach could be combined with other ViT compression techniques such as quantization to reach even lower latency on embedded hardware.
- Similar compensators might improve token pruning in other dense prediction tasks that rely on transformer backbones.
- The reduction in fine-tuned parameters suggests the method could be deployed quickly on new datasets or camera configurations without massive retraining.
- If the compensator generalizes, it could lower the barrier for using large foundation models in real-time perception systems.
Load-bearing premise
The compensator can select fewer tokens at some layers without discarding spatial details that 3D detection requires.
What would settle it
Running the method on the NuScenes validation set and observing that mean average precision falls below the ToC3D baseline would falsify the claim of maintained or improved accuracy.
Figures





read the original abstract
Existing multi-view three-dimensional (3D) object detection approaches widely adopt large-scale pre-trained vision transformer (ViT)-based foundation models as backbones, being computationally complex. To address this problem, current state-of-the-art (SOTA) \texttt{ToC3D} for efficient multi-view ViT-based 3D object detection employs ego-motion-based relevant token selection. However, there are two key limitations: (1) The fixed layer-individual token selection ratios limit computational efficiency during both training and inference. (2) Full end-to-end retraining of the ViT backbone is required for the multi-view 3D object detection method. In this work, we propose an image token compensator combined with a token selection for ViT backbones to accelerate multi-view 3D object detection. Unlike \texttt{ToC3D}, our approach enables dynamic layer-wise token selection within the ViT backbone. Furthermore, we introduce a parameter-efficient fine-tuning strategy, which trains only the proposed modules, thereby reducing the number of fine-tuned parameters from more than $300$ million (M) to only $1.6$ M. Experiments on the large-scale NuScenes dataset across three multi-view 3D object detection approaches demonstrate that our proposed method decreases computational complexity (GFLOPs) by $48\%$ ... $55\%$, inference latency (on an \texttt{NVIDIA-GV100} GPU) by $9\%$ ... $25\%$, while still improving mean average precision by $1.0\%$ ... $2.8\%$ absolute and NuScenes detection score by $0.4\%$ ... $1.2\%$ absolute compared to so-far SOTA \texttt{ToC3D}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an image token compensator combined with dynamic layer-wise token selection in ViT backbones, plus parameter-efficient fine-tuning of only 1.6M parameters, enables 48-55% GFLOPs reduction, 9-25% lower inference latency on NVIDIA GV100, and absolute gains of 1.0-2.8% mAP and 0.4-1.2% NDS over ToC3D on NuScenes across three multi-view 3D detectors.
Significance. If the central empirical claims hold after addressing the mechanism details, the work would be significant for practical deployment of ViT-based 3D detectors: it shows that dynamic per-layer pruning with compensation can simultaneously cut compute and improve accuracy, while the PEFT strategy reduces adaptation cost from >300M to 1.6M parameters. The multi-baseline evaluation on a large-scale dataset like NuScenes strengthens the case for broader applicability.
major comments (2)
- [Method section (Image Token Compensator)] Method section (Image Token Compensator description): the claim that the compensator restores information lost by dynamic token selection is load-bearing for the accuracy gains, yet the description does not specify how 2D token compensation recovers cross-view depth or epipolar constraints required for 3D box regression; without this, the reported mAP/NDS improvements could be dataset-specific artifacts rather than a general property of the approach.
- [Experiments section (results tables)] Experiments section (results tables): the headline efficiency+accuracy numbers are presented as ranges across three detection pipelines, but without per-method breakdowns, ablation isolating the compensator's contribution, or controls confirming identical hyperparameter tuning and training protocols versus ToC3D, it is difficult to attribute the 1-2.8% mAP lift specifically to the proposed dynamic selection rather than implementation differences.
minor comments (2)
- [Abstract and Experiments] The abstract and results use ellipsis notation for ranges (48% ... 55%); replace with explicit per-approach values or a summary table for clarity.
- [Method or Experiments] Add a table listing the exact number of trainable parameters for each proposed module versus the full ViT backbone to support the 1.6M claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Method section (Image Token Compensator description): the claim that the compensator restores information lost by dynamic token selection is load-bearing for the accuracy gains, yet the description does not specify how 2D token compensation recovers cross-view depth or epipolar constraints required for 3D box regression; without this, the reported mAP/NDS improvements could be dataset-specific artifacts rather than a general property of the approach.
Authors: We agree that the current description of the Image Token Compensator would benefit from greater mechanistic detail to substantiate its role in supporting 3D reasoning. In the revised manuscript we will expand the relevant subsection with an explicit formulation of the compensation operation and a discussion of how the 2D spatial reconstruction of token features preserves cues that the downstream 3D detection heads can exploit for depth and epipolar consistency. We will also add qualitative feature-map visualizations comparing token representations before and after compensation. These additions should clarify that the observed accuracy gains arise from the proposed mechanism rather than dataset idiosyncrasies. revision: yes
-
Referee: Experiments section (results tables): the headline efficiency+accuracy numbers are presented as ranges across three detection pipelines, but without per-method breakdowns, ablation isolating the compensator's contribution, or controls confirming identical hyperparameter tuning and training protocols versus ToC3D, it is difficult to attribute the 1-2.8% mAP lift specifically to the proposed dynamic selection rather than implementation differences.
Authors: We acknowledge that the current presentation of results as aggregate ranges limits attribution. In the revised version we will replace the summary tables with per-method breakdowns for each of the three detection pipelines, add a dedicated ablation study isolating the Image Token Compensator (with and without it, while keeping dynamic selection fixed), and insert a short paragraph in the experimental setup section that explicitly states the hyperparameter and training-protocol controls used for all ToC3D comparisons. These changes will make the source of the reported gains transparent. revision: yes
Circularity Check
No circularity: empirical head-to-head measurements on NuScenes
full rationale
The paper's central claims consist of measured GFLOPs, latency, mAP, and NDS improvements obtained by running the proposed dynamic token selection plus compensator and parameter-efficient fine-tuning modules on three ViT-based 3D detectors. These are direct experimental outcomes against the external baseline ToC3D; no equations, fitted parameters, or self-citations are shown to reduce the reported deltas to definitions or prior author results by construction. The method description (image token compensator, layer-wise selection ratios, 1.6 M tunable parameters) is presented as an engineering proposal whose value is established by the external benchmark comparison rather than by any self-referential derivation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Image token compensator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Exploring Object- Centric Temporal Modeling for Efficient Multi-View 3D Object De- tection,
S. Wang, Y . Liu, T. Wang, Y . Li, and X. Zhang, “Exploring Object- Centric Temporal Modeling for Efficient Multi-View 3D Object De- tection,” inProc. of ICCV, Montreal, QC, Canada, October 2023, pp. 3621–3631
2023
-
[2]
PETR: Position Embedding Transformation for Multi-View 3D Object Detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “PETR: Position Embedding Transformation for Multi-View 3D Object Detection,” inProc. of ECCV. Milan, Italy: Springer, October 2022, pp. 531–548
2022
-
[3]
Make Your ViT-Based Multi-View 3D Detectors Faster via Token Compression,
D. Zhang, D. Liang, Z. Tan, X. Ye, C. Zhang, J. Wang, and X. Bai, “Make Your ViT-Based Multi-View 3D Detectors Faster via Token Compression,” inProc. of ECCV, Milan, Italy, October 2024, pp. 56–72
2024
-
[4]
Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning,
L. Xu, X. Bai, X. Jia, J. Fang, and S. Pang, “Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning,”arXiv preprint arXiv:2503.08101, 2025
-
[5]
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D,
J. Philion and S. Fidler, “Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D,” inProc. of ECCV. virtual: Springer, October 2020, pp. 194–210
2020
-
[6]
BEVFormer: Learning Bird’s-Eye-View Representation from Lidar- Camera Via Spatiotemporal Transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “BEVFormer: Learning Bird’s-Eye-View Representation from Lidar- Camera Via Spatiotemporal Transformers,”IEEE T-PAMI, 2024
2024
-
[7]
BEVFormer V2: Adapting Modern Image Back- bones to Bird’s-Eye-View Recognition Via Perspective Supervision,
C. Yang, Y . Chen, H. Tian, C. Tao, X. Zhu, Z. Zhang, G. Huang, H. Li, Y . Qiao, L. Luet al., “BEVFormer V2: Adapting Modern Image Back- bones to Bird’s-Eye-View Recognition Via Perspective Supervision,” in Proc. of CVPR, Vancouver, BC, Canada, June 2023, pp. 17 830–17 839
2023
-
[8]
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du, “BEVDet: High- Performance Multi-Camera 3D Object Detection in Bird-Eye-View,” arXiv preprint arXiv:2112.11790, 2021
-
[9]
BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection,
Y . Li, Z. Ge, G. Yu, J. Yang, Z. Wang, Y . Shi, J. Sun, and Z. Li, “BEVDepth: Acquisition of Reliable Depth for Multi-View 3D Object Detection,” inProc. of AAAI, vol. 37, no. 2, Washington, DC, USA, October 2023, pp. 1477–1485
2023
-
[10]
J. Park, C. Xu, S. Yang, K. Keutzer, K. Kitani, M. Tomizuka, and W. Zhan, “Time Will Tell: New Outlooks and a Baseline for Temporal Multi-View 3D Object Detection,”arXiv preprint arXiv:2210.02443, 2022
-
[11]
BEVNext: Reviving Dense BEV Frameworks for 3D Object Detection,
Z. Li, S. Lan, J. M. Alvarez, and Z. Wu, “BEVNext: Reviving Dense BEV Frameworks for 3D Object Detection,” inProc. of CVPR, Seattle, W A, USA, June 2024, pp. 20 113–20 123
2024
-
[12]
Detr3D: 3D Object Detection from Multi-View Images via 3D-to-2D Queries,
Y . Wang, V . C. Guizilini, T. Zhang, Y . Wang, H. Zhao, and J. Solomon, “Detr3D: 3D Object Detection from Multi-View Images via 3D-to-2D Queries,” inProc. of CORL. Auckland,NZ: PMLR, December 2022, pp. 180–191
2022
-
[13]
M-BEV: Masked BEV Perception for Robust Autonomous Driving,
S. Chen, Y . Ma, Y . Qiao, and Y . Wang, “M-BEV: Masked BEV Perception for Robust Autonomous Driving,” inProc. of AAAI, vol. 38, no. 2, Vancouver, BC, Canada, February 2024, pp. 1183–1191
2024
-
[14]
arXiv preprint arXiv:2211.10581 (2022)
X. Lin, T. Lin, Z. Pei, L. Huang, and Z. Su, “Sparse4D: Multi-View 3D Object Detection With Sparse Spatial-Temporal Fusion,”arXiv preprint arXiv:2211.10581, 2022
-
[15]
SparseBEV: High- Performance Sparse 3D Object Detection from Multi-Camera Videos,
H. Liu, Y . Teng, T. Lu, H. Wang, and L. Wang, “SparseBEV: High- Performance Sparse 3D Object Detection from Multi-Camera Videos,” inProc. of ICCV, Paris,France, October 2023, pp. 18 580–18 590
2023
-
[16]
Ray Denoising: Depth-Aware Hard Negative Sampling for Multi-View 3D Object Detection,
F. Liu, T. Huang, Q. Zhang, H. Yao, C. Zhang, F. Wan, Q. Ye, and Y . Zhou, “Ray Denoising: Depth-Aware Hard Negative Sampling for Multi-View 3D Object Detection,” inProc. of ECCV. Milan, Italy: Springer, October 2024, pp. 200–217
2024
-
[17]
OPEN: Object-Wise Position Embedding for Multi-View 3D Object Detection,
J. Hou, T. Wang, X. Ye, Z. Liu, S. Gong, X. Tan, E. Ding, J. Wang, and X. Bai, “OPEN: Object-Wise Position Embedding for Multi-View 3D Object Detection,” inProc. of ECCV. Milan, Italy: Springer, October 2024, pp. 146–162
2024
-
[18]
EV A-02: A Visual Representation for Neon Genesis,
Y . Fang, Q. Sun, X. Wang, T. Huang, X. Wang, and Y . Cao, “EV A-02: A Visual Representation for Neon Genesis,”Elsevier IVC, vol. 149, p. 105171, 2024
2024
-
[19]
Segment Anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment Anything,” inProc. of ICCV, Paris, France, October 2023, pp. 4015–4026
2023
-
[20]
arXiv preprint arXiv:2305.14018 (2023)
X. Lin, T. Lin, Z. Pei, L. Huang, and Z. Su, “Sparse4DV2: Recurrent Temporal Fusion With Sparse Model,”arXiv preprint arXiv:2305.14018, 2023
-
[21]
Nuscenes: A Multimodal Dataset for Autonomous Driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Kr- ishnan, Y . Pan, G. Baldan, and O. Beijbom, “Nuscenes: A Multimodal Dataset for Autonomous Driving,” inProc. of CVPR, Seattle, W A, USA, June 2020, pp. 11 621–11 631
2020
-
[22]
LoRA: Low-Rank Adaptation of Large Language Models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “LoRA: Low-Rank Adaptation of Large Language Models,”Proc. of ICLR, vol. 1, no. 2, p. 3, April 2022
2022
-
[23]
Rethinking Token Reduction With Parameter-Efficient Fine-Tuning in ViT for Pixel-Level Tasks,
C. Lei, A. Li, H. Yao, C. Zhu, and L. Zhang, “Rethinking Token Reduction With Parameter-Efficient Fine-Tuning in ViT for Pixel-Level Tasks,” inProc. of CVPR, Nashville, TN, USA, June 2025, pp. 14 954– 14 964
2025
-
[24]
BEVStereo: Enhancing Depth Estimation in Multi-View 3D Object Detection With Temporal Stereo,
Y . Li, H. Bao, Z. Ge, J. Yang, J. Sun, and Z. Li, “BEVStereo: Enhancing Depth Estimation in Multi-View 3D Object Detection With Temporal Stereo,” inProc. of AAAI, vol. 37, no. 2, Washington, DC, USA, October 2023, pp. 1486–1494
2023
-
[25]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An Image is Worth 16x16 Words: Transformers for Image Recognition At Scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[26]
Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows,” inProc. of ICCV, Montreal, QC, Canada, October 2021, pp. 10 012–10 022
2021
-
[27]
ImageNet: A Large-scale Hierarchical Image Database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A Large-scale Hierarchical Image Database,” inProc. of CVPR, Miami, FL, USA, June 2009, pp. 248–255
2009
-
[28]
Distributed Semantic Segmentation With Efficient Joint Source and Task Decoding,
D. Nazir, T. Bartels, J. Piewek, T. Bagdonat, and T. Fingscheidt, “Distributed Semantic Segmentation With Efficient Joint Source and Task Decoding,” inProc. of ECCV, Milan, Italy, October 2024, pp. 195–212
2024
-
[29]
Fingscheidt, H
T. Fingscheidt, H. Gottschalk, and S. Houben, Eds., Deep Neural Networks and Data for Automated Driving: Robustness, Uncertainty Quantification, and Insights Towards Safety. Cham: Springer Nature, 2022. [Online]. Available: https://library.oapen.org/handle/20.500.12657/57375
2022
-
[30]
DynamicViT: Efficient Vision Transformers With Dynamic Token Sparsification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C.-J. Hsieh, “DynamicViT: Efficient Vision Transformers With Dynamic Token Sparsification,” Proc. of NeurIPS, vol. 34, pp. 13 937–13 949, December 2021
2021
-
[31]
EVO-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,
Y . Xu, Z. Zhang, M. Zhang, K. Sheng, K. Li, W. Dong, L. Zhang, C. Xu, and X. Sun, “EVO-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer,” inProc. of AAAI, vol. 36, no. 3, Washington, DC, USA, February 2022, pp. 2964–2972
2022
-
[32]
Token Merging: Your ViT But Faster
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, C. Feichtenhofer, and J. Hoffman, “Token Merging: Your ViT But Faster,”arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review arXiv 2022
-
[33]
Vid-TLDR: Training Free Token Merging for Light-Weight Video Transformer,
J. Choi, S. Lee, J. Chu, M. Choi, and H. J. Kim, “Vid-TLDR: Training Free Token Merging for Light-Weight Video Transformer,” inProc. of CVPR, Seattle, W A, USA, June 2024, pp. 18 771–18 781
2024
-
[34]
Dynamic Tuning Towards Parameter and Inference Efficiency for ViT Adaptation,
W. Zhao, J. Tang, Y . Han, Y . Song, K. Wang, G. Huang, F. Wang, and Y . You, “Dynamic Tuning Towards Parameter and Inference Efficiency for ViT Adaptation,”Proc. of NeurIPS, vol. 37, pp. 114 765–114 796, December 2024
2024
-
[35]
DETR3D: 3D Object Detection from Multi-View Images via 3D-To-2D Queries,
Y . Wang, V . C. Guizilini, T. Zhang, Y . Wang, H. Zhao, and J. Solomon, “DETR3D: 3D Object Detection from Multi-View Images via 3D-To-2D Queries,” inProc. of CoRL. Auckland, Newzealand: PMLR, December 2022, pp. 180–191
2022
-
[36]
URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement,
W. Zhang, R. Scheibler, K. Saijo, S. Cornell, C. Li, Z. Ni, J. Pirkl- bauer, M. Sach, S. Watanabe, T. Fingscheidt, and Y . Qian, “URGENT Challenge: Universality, Robustness, and Generalizability For Speech Enhancement,” inProc. of Interspeech, Kos, Greece, September 2024, pp. 4868–4872
2024
-
[37]
Inter- speech 2025 URGENT Speech Enhancement Challenge,
K. Saijo, W. Zhang, S. Cornell, R. Scheibler, C. Li, Z. Ni, A. Kumar, M. Sach, Y . Fu, W. Wang, T. Fingscheidt, and S. Watanabe, “Inter- speech 2025 URGENT Speech Enhancement Challenge,” inProc. of Interspeech, Rotterdam, Netherlands, August 2025, pp. 858–862
2025
-
[38]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProc. of CVPR, Las Vegas, NV , USA, July 2016, pp. 770–778
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.