Recognition: unknown
AVID: A Benchmark for Omni-Modal Audio-Visual Inconsistency Understanding via Agent-Driven Construction
Pith reviewed 2026-05-10 12:19 UTC · model grok-4.3
The pith
AVID benchmark tests how well AI models detect and reason about audio-visual inconsistencies in long videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
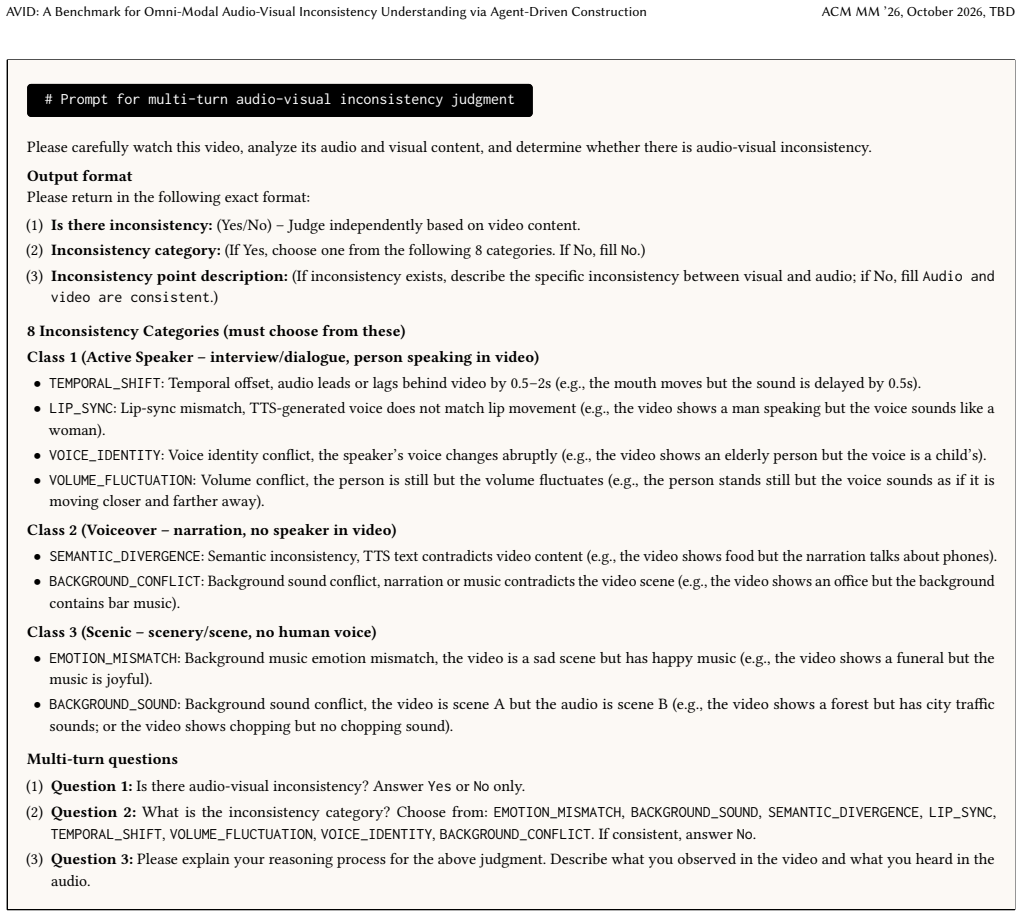
AVID is generated by a pipeline that first segments long videos by content type, then uses an agent-based planner to select appropriate inconsistency categories, and finally applies five specialized injectors to create realistic audio-visual conflicts; the outcome is a dataset of 11.2K videos containing 39.4K annotated events across eight categories that exposes clear weaknesses in current omni-modal models on temporal grounding and reasoning while allowing fine-tuned models to achieve stronger results on the same tasks.
What carries the argument
The agent-driven construction pipeline that performs temporal segmentation, selects inconsistency types via a planner, and deploys five specialized injectors to insert audio-visual conflicts.
If this is right
- The benchmark supplies standardized test cases for detection, temporal grounding, classification, and reasoning across eight inconsistency categories.
- Current omni-modal models exhibit measurable shortcomings in temporal grounding and reasoning when evaluated on the dataset.
- Fine-tuning on the AVID data yields stronger performance than the base model or other compared systems on the supported tasks.
- AVID functions as a reusable testbed for developing omni-modal systems that handle cross-modal conflicts more reliably.
Where Pith is reading between the lines
- The same agent-planner-plus-injector approach could be reused to synthesize training data that improves model robustness on naturally occurring video mismatches in editing or surveillance settings.
- AVID-style benchmarks may help researchers test whether stronger inconsistency awareness also improves performance on aligned multimodal tasks such as captioning or retrieval.
- Developers of content-moderation or media-authenticity tools could adopt the dataset to measure how well systems flag real-world audio-visual contradictions.
Load-bearing premise
The pipeline's agent planner and five injectors produce inconsistency events that are semantically fitting, realistic, and typical of conflicts humans notice in videos.
What would settle it
A controlled human study in which raters judge a random sample of AVID events as unnatural or non-conflicting, or a controlled experiment showing that models fine-tuned on AVID gain no advantage on a separate collection of naturally occurring inconsistent videos.
Figures








read the original abstract
We present AVID, the first large-scale benchmark for audio-visual inconsistency understanding in videos. While omni-modal large language models excel at temporally aligned tasks such as captioning and question answering, they struggle to perceive cross-modal conflicts, a fundamental human capability that is critical for trustworthy AI. Existing benchmarks predominantly focus on aligned events or deepfake detection, leaving a significant gap in evaluating inconsistency perception in long-form video contexts. AVID addresses this with: (1) a scalable construction pipeline comprising temporal segmentation that classifies video content into Active Speaker, Voiceover, and Scenic categories; an agent-driven strategy planner that selects semantically appropriate inconsistency categories; and five specialized injectors for diverse audio-visual conflict injection; (2) 11.2K long videos (avg. 235.5s) with 39.4K annotated inconsistency events and 78.7K segment clips, supporting evaluation across detection, temporal grounding, classification, and reasoning with 8 fine-grained inconsistency categories. Comprehensive evaluations of state-of-the-art omni-models reveal significant limitations in temporal grounding and reasoning. Our fine-tuned baseline, AVID-Qwen, achieves substantial improvements over the base model (2.8$\times$ higher BLEU-4 in segment reasoning) and surpasses all compared models in temporal grounding (mIoU: 36.1\% vs 26.2\%) and holistic understanding (SODA-m: 7.47 vs 6.15), validating AVID as an effective testbed for advancing trustworthy omni-modal AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AVID as the first large-scale benchmark for audio-visual inconsistency understanding in long-form videos. It describes a scalable construction pipeline using temporal segmentation into Active Speaker/Voiceover/Scenic categories, an agent-driven strategy planner to select inconsistency categories, and five specialized injectors to create 11.2K videos (avg. 235.5s) with 39.4K annotated events across 8 fine-grained categories and 78.7K segment clips. The benchmark supports detection, temporal grounding, classification, and reasoning tasks. Evaluations show limitations in state-of-the-art omni-modal models, while the fine-tuned AVID-Qwen baseline reports gains including 2.8× higher BLEU-4 in segment reasoning, mIoU 36.1% (vs. 26.2%), and SODA-m 7.47 (vs. 6.15).
Significance. If the injected inconsistencies prove realistic and representative of natural cross-modal conflicts, AVID would fill a notable gap in evaluating omni-modal models on conflict perception rather than aligned captioning or deepfake detection, supporting progress toward trustworthy AI. The dataset scale, fine-grained categories, and reported improvements in the fine-tuned baseline demonstrate the benchmark's potential as a testbed. The agent-driven pipeline and multi-task annotations are strengths that could enable reproducible advances if validated.
major comments (1)
- The construction pipeline (temporal segmentation, agent-driven planner, and five injectors) is presented as producing semantically appropriate and realistic inconsistencies, yet the manuscript reports no human validation such as plausibility ratings, inter-rater agreement on naturalness, or comparison to naturally occurring conflicts. This is load-bearing for the central claim, as the quantitative gains (e.g., temporal grounding mIoU and reasoning BLEU-4) could reflect exploitation of synthetic artifacts rather than genuine inconsistency understanding.
minor comments (2)
- The abstract and results sections should include a table explicitly listing all compared models with their full metric scores to support the claim of surpassing 'all compared models' in temporal grounding and holistic understanding.
- Dataset statistics such as the distribution of the 8 inconsistency categories and video length variance (beyond the reported average of 235.5s) would improve clarity on the benchmark's coverage and balance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment on human validation of the inconsistency construction pipeline below.
read point-by-point responses
-
Referee: The construction pipeline (temporal segmentation, agent-driven planner, and five injectors) is presented as producing semantically appropriate and realistic inconsistencies, yet the manuscript reports no human validation such as plausibility ratings, inter-rater agreement on naturalness, or comparison to naturally occurring conflicts. This is load-bearing for the central claim, as the quantitative gains (e.g., temporal grounding mIoU and reasoning BLEU-4) could reflect exploitation of synthetic artifacts rather than genuine inconsistency understanding.
Authors: We agree that human validation is important to substantiate the realism and semantic appropriateness of the injected inconsistencies. The manuscript does not currently report plausibility ratings, inter-rater agreement, or direct comparisons to natural conflicts, which is a limitation in the presented work. The pipeline is designed with an agent-driven planner that selects inconsistency categories based on semantic analysis of each segment's category (Active Speaker, Voiceover, or Scenic) and five specialized injectors that enforce contextual constraints during injection. Nevertheless, to directly address this concern, we will add a dedicated human evaluation section in the revised manuscript. This will include plausibility and naturalness ratings by multiple annotators on a representative sample of the 39.4K events, along with inter-rater agreement metrics (e.g., Fleiss' kappa). Where feasible, we will also provide qualitative comparisons to naturally occurring audio-visual conflicts drawn from existing video datasets. These additions will help confirm that the reported gains (such as the 2.8× BLEU-4 improvement in segment reasoning and mIoU gains in temporal grounding) arise from genuine inconsistency understanding rather than exploitation of synthetic artifacts. The differential performance patterns across SOTA models and tasks provide supporting indirect evidence that the benchmark poses meaningful challenges. revision: yes
Circularity Check
No significant circularity in benchmark construction or evaluation chain
full rationale
The paper introduces AVID as a new benchmark via an explicit agent-driven pipeline (temporal segmentation into Active Speaker/Voiceover/Scenic, planner, and five injectors) that generates 11.2K videos and 39.4K events. All reported metrics (BLEU-4, mIoU, SODA-m) are standard external measures applied to fine-tuned AVID-Qwen versus base models and other baselines. No equations, fitted parameters renamed as predictions, self-citations to author prior uniqueness results, or ansatzes smuggled via citation appear in the abstract or described methods. The construction pipeline and evaluation results are presented as independent of the evaluated models, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Video content can be reliably classified into Active Speaker, Voiceover, and Scenic categories for segmentation
- ad hoc to paper An agent-driven strategy planner can select semantically appropriate inconsistency categories for injection
invented entities (1)
-
Five specialized injectors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Muhammad Aleem, Muhammad Umair, Muhammad Zubair, Rozeena Ibrahim, Muhammad Tahir Naseem, Muhammad Mohsin Raza, Muhammad Nadeem Ali, and Byung-Seo Kim. 2026. Seeing Through the Fake: Explainable AI With Multiple CNNs for Deepfake Detection.IEEE Access14 (2026), 131–162. doi:10. 1109/ACCESS.2025.3649128
-
[2]
Matyas Bohacek and Hany Farid. 2024. Lost in Translation: Lip-Sync Deepfake Detection from Audio-Video Mismatch. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, Seattle, WA, USA, 4315–
2024
-
[3]
doi:10.1109/CVPRW63382.2024.00435
-
[4]
Zhixi Cai, Kartik Kuckreja, Shreya Ghosh, Akanksha Chuchra, Muhammad Haris Khan, Usman Tariq, Tom Gedeon, and Abhinav Dhall. 2025. AV-Deepfake1M++: A Large-Scale Audio-Visual Deepfake Benchmark with Real-World Perturbations. InProceedings of the 33rd ACM International Conference on Multimedia (ACM MM). doi:10.1145/3746027.3761979
-
[5]
Zhixi Cai, Kalin Stefanov, Abhinav Dhall, and Munawar Hayat. 2022. Do You Re- ally Mean That? Content Driven Audio-Visual Deepfake Dataset and Multimodal Method for Temporal Forgery Localization. In2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA). IEEE, Sydney, Australia, 1–10. doi:10.1109/DICTA56598.2022.10034605
-
[6]
Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. Vg- gsound: A large-scale audio-visual dataset. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 721–725
2020
-
[7]
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. 2023. VAST: A Vision-Audio-Subtitle-Text Omni-Modality Founda- tion Model and Dataset. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[8]
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming- Hsuan Yang, and Sergey Tulyakov. 2024. Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2024
-
[9]
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. 2025. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 24108–24118
2025
-
[10]
Jiyang Gao, Chen Sun, Zhenheng Yang, and Ram Nevatia. 2017. TALL: Temporal Activity Localization via Language Query. InProceedings of the IEEE International Conference on Computer Vision (ICCV). 5267–5275
2017
-
[11]
Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio set: An ontology and human-labeled dataset for audio events. In2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 776–780
2017
-
[12]
Tiantian Geng, Teng Wang, Jinming Duan, Runmin Cong, and Feng Zheng. 2023. Dense-Localizing Audio-Visual Events in Untrimmed Videos: A Large-Scale Benchmark and Baseline. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2023
-
[13]
Tiantian Geng, Jinrui Zhang, Qingni Wang, Teng Wang, Jinming Duan, and Feng Zheng. 2025. LongVALE: Vision-Audio-Language-Event Benchmark To- wards Time-Aware Omni-Modal Perception of Long Videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
2025
-
[14]
Goel et al
A. Goel et al. 2024. OMCAT: Omni-Context Audio-Visual Transformer for Video Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops
2024
-
[15]
Alexandros Haliassos, Konstantinos Vougioukas, Stavros Petridis, and Maja Pan- tic. 2021. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5039–5049
2021
- [16]
-
[17]
Hasam Khalid, Shahroz Tariq, Minha Kim, and Simon S. Woo. 2021. FakeAVCeleb: A Novel Audio-Video Multimodal Deepfake Dataset. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), Datasets and Benchmarks Track
2021
-
[18]
Chris Dongjoo Kim, Byeongchang Kim, Hyunmin Lee, and Gunhee Kim. 2019. AudioCaps: Generating Captions for Audios in The Wild. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT)
2019
-
[19]
Ranjay Krishna, Kenji Hata, Frederic Ren, Li Fei-Fei, and Juan Carlos Niebles
-
[20]
InProceedings of the IEEE International Conference on Computer Vision (ICCV)
Dense-Captioning Events in Videos. InProceedings of the IEEE International Conference on Computer Vision (ICCV)
-
[21]
Sangho Lee, Jiwan Chung, Youngjae Yu, Gunhee Kim, Thomas Breuel, Gal Chechik, and Yale Song. 2021. ACAV100M: Automatic Curation of Large-Scale Datasets for Audio-Visual Video Representation Learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
2021
-
[22]
Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Bain- ing Guo. 2020. Face x-ray for more general face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 5001–5010
2020
-
[23]
Jing Liu, Sihan Chen, Xingjian He, Longteng Guo, Xinxin Zhu, Weining Wang, and Jinhui Tang. 2024. VALOR: Vision-Audio-Language Omni-Perception Pretraining Model and Dataset.IEEE Transactions on Multimedia(2024). doi:10.1109/TMM. 2024.3480698
work page doi:10.1109/tmm 2024
-
[24]
Miao Liu, Jing Wang, Xinyuan Qian, and Haizhou Li. 2023. Audio-Visual Tempo- ral Forgery Detection Using Embedding-Level Fusion and Multi-Dimensional Contrastive Loss.IEEE Transactions on Circuits and Systems for Video Technology PP (2023), 1–1. doi:10.1109/TCSVT.2023.3326694
-
[25]
Weifeng Liu, Tianyi She, Jiawei Liu, Boheng Li, Dongyu Yao, Ziyou Liang, and Run Wang. 2024. Lips Are Lying: Spotting the Temporal Inconsistency between Audio and Visual in Lip-Syncing DeepFakes. doi:10.48550/arXiv.2401.15668 arXiv:2401.15668 [cs]
-
[26]
Xinhao Mei, Chutong Meng, Haohe Liu, Qiuqiang Kong, Tom Ko, Chengqi Zhao, Mark D. Plumbley, Yuexian Zou, and Wenwu Wang. 2024. WavCaps: A ChatGPT- Assisted Weakly-Labelled Audio Captioning Dataset for Audio-Language Multi- modal Research.IEEE/ACM Transactions on Audio, Speech, and Language Process- ing(2024). doi:10.1109/TASLP.2024.3419446
-
[27]
Trevine Oorloff, Surya Koppisetti, Nicolo Bonettini, Divyaraj Solanki, Ben Col- man, Yaser Yacoob, Ali Shahriyari, and Gaurav Bharaj. [n. d.]. AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection. ([n. d.])
-
[28]
Andrew Owens and Alexei A Efros. 2018. Audio-visual scene analysis with self-supervised multisensory features. InProceedings of the European conference on computer vision (ECCV). 631–648
2018
-
[29]
Yapeng Tian, Di Li, and Chenliang Xu. 2020. Unified Multisensory Perception: Weakly-Supervised Audio-Visual Video Parsing. InComputer Vision – ECCV 2020. 436–454
2020
-
[30]
Yapeng Tian, Jing Shi, Bochen Li, Zhiyao Duan, and Chenliang Xu. 2018. Audio- Visual Event Localization in Unconstrained Videos. InProceedings of the European Conference on Computer Vision (ECCV)
2018
-
[31]
Ruben Tolosana, Ruben Vera-Rodriguez, Julian Fierrez, Aythami Morales, and Javier Ortega-Garcia. 2020. Deepfakes and beyond: A survey of face manipulation and fake detection.Information fusion64 (2020), 131–148
2020
-
[32]
Sung Jin Um, Dongjin Kim, Sangmin Lee, and Jung Uk Kim. 2025. Object-aware Sound Source Localization via Audio-Visual Scene Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 8342– 8351
2025
- [33]
-
[34]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, and Yu Qiao. 2024. InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation. InInternational Conference on Learning Representations (ICLR)
2024
-
[35]
Shichuang Xie, Tong Qiao, Sheng Li, Xinpeng Zhang, Jiantao Zhou, and Guorui Feng. 2026. DeepFake Detection in the AIGC Era: A Survey, Benchmarks, and Future Perspectives.Information Fusion127 (2026), 103740. doi:10.1016/j.inffus. 2025.103740
-
[36]
Wenyuan Yang, Xiaoyu Zhou, Zhikai Chen, Bofei Guo, Zhongjie Ba, Zhihua Xia, Xiaochun Cao, and Kui Ren. 2023. AVoiD-DF: Audio-Visual Joint Learning for Detecting Deepfake.IEEE Transactions on Information Forensics and Security18 (2023), 2015–2029. doi:10.1109/TIFS.2023.3262148
-
[37]
Qilang Ye, Wei Zeng, Meng Liu, Jie Zhang, Yupeng Hu, Zitong Yu, and Yu Zhou
-
[38]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Con- fusion?. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 11955–11963
-
[39]
Hang Zhang, Xin Li, and Lidong Bing. 2023. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demon- strations(EMNLP). 543–553
2023
-
[40]
away” (1.0→ 0.01, simulating moving away) or “toward
Hao Zhu, Man-Di Luo, Rui Wang, Ai-Hua Zheng, and Ran He. 2021. Deep audio- visual learning: A survey.International Journal of Automation and Computing18, 3 (2021), 351–376. A Appendix Overview This appendix provides implementation-level details that are inten- tionally omitted from the main paper for space reasons. We organize the content into four main s...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.