Recognition: unknown
VRAG-DFD: Verifiable Retrieval-Augmentation for MLLM-based Deepfake Detection
Pith reviewed 2026-05-10 14:21 UTC · model grok-4.3
The pith
VRAG-DFD equips MLLMs with dynamic forgery knowledge retrieval and critical reasoning via RAG and RL to improve deepfake detection generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
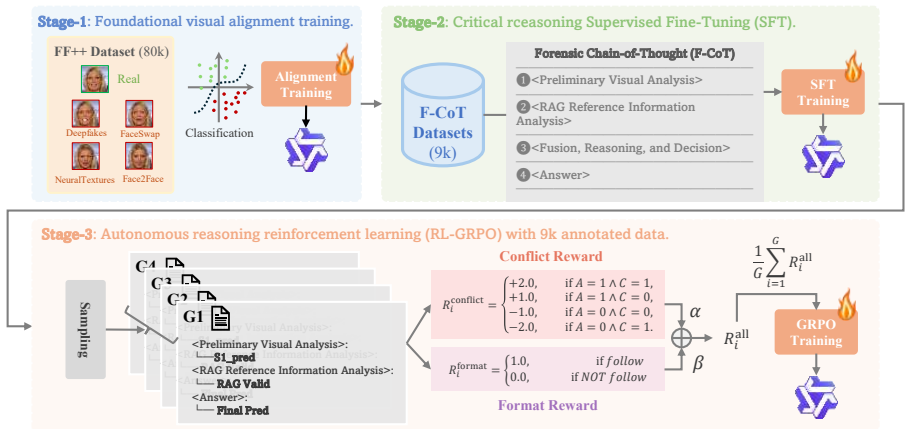
Through RAG and RL techniques, the VRAG-DFD framework supplies accurate dynamic forgery knowledge retrieval and powerful critical reasoning capabilities to MLLMs; it constructs the Forensic Knowledge Database for DFD knowledge annotation and the Forensic Chain-of-Thought Dataset for critical CoT construction, then applies a three-stage Alignment-SFT-GRPO training process that yields SOTA and competitive results on DFD generalization testing.
What carries the argument
The VRAG-DFD framework that combines retrieval-augmented generation for on-demand forensic knowledge with three-stage reinforcement learning training to develop critical reasoning over noisy references.
If this is right
- Detection performance improves on previously unseen forgery techniques because knowledge is retrieved dynamically rather than fixed at training time.
- The model learns to question and filter noisy or incorrect reference passages instead of blindly trusting them.
- Specialized datasets like FKD and F-CoT become reusable resources for training other MLLMs on forensic tasks.
- The three-stage training sequence gradually builds alignment, knowledge use, and then critical evaluation in sequence.
Where Pith is reading between the lines
- The same retrieval-plus-reasoning pattern could apply to other media authenticity tasks such as audio or video manipulation detection.
- Explicit verification steps inside the reasoning chain might reduce the chance that the model invents supporting details not present in the retrieved knowledge.
- Hybrid systems that feed VRAG-DFD outputs into traditional small detectors could combine broad reasoning with fine-grained artifact analysis.
Load-bearing premise
The RAG-retrieved knowledge items are accurate enough and the Alignment-SFT-GRPO process produces reasoning that remains reliable even when those references contain errors or irrelevancies.
What would settle it
An evaluation on a held-out set of deepfake images generated by methods absent from the Forensic Knowledge Database where the VRAG-DFD model shows no accuracy gain over standard MLLM baselines that lack retrieval or the GRPO stage.
Figures






read the original abstract
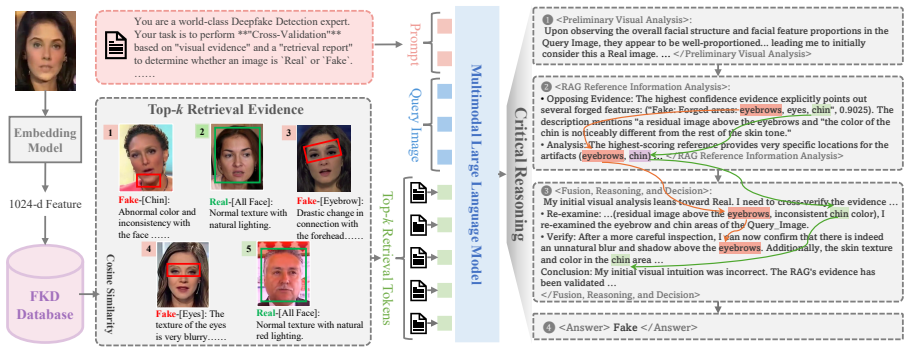
In Deepfake Detection (DFD) tasks, researchers proposed two types of MLLM-based methods: complementary combination with small DFD detectors, or static forgery knowledge injection. The lack of professional forgery knowledge hinders the performance of these DFD-MLLMs. To solve this, we deeply considered two insightful issues: How to provide high-quality associated forgery knowledge for MLLMs? AND How to endow MLLMs with critical reasoning abilities given noisy reference information? Notably, we attempted to address above two questions with preliminary answers by leveraging the combination of Retrieval-Augmented Generation (RAG) and Reinforcement Learning (RL). Through RAG and RL techniques, we propose the VRAG-DFD framework with accurate dynamic forgery knowledge retrieval and powerful critical reasoning capabilities. Specifically, in terms of data, we constructed two datasets with RAG: Forensic Knowledge Database (FKD) for DFD knowledge annotation, and Forensic Chain-of-Thought Dataset (F-CoT), for critical CoT construction. In terms of model training, we adopt a three-stage training method (Alignment->SFT->GRPO) to gradually cultivate the critical reasoning ability of the MLLM. In terms of performance, VRAG-DFD achieved SOTA and competitive performance on DFD generalization testing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the VRAG-DFD framework for MLLM-based deepfake detection. It leverages RAG to build a Forensic Knowledge Database (FKD) and Forensic Chain-of-Thought Dataset (F-CoT) for dynamic, accurate forgery knowledge retrieval, combined with a three-stage Alignment-SFT-GRPO training pipeline using reinforcement learning to instill critical reasoning abilities in MLLMs, and claims SOTA and competitive performance on DFD generalization testing.
Significance. If the empirical results hold after proper validation, the work could be significant for MLLM-based DFD by addressing gaps in professional forgery knowledge and enabling reliable reasoning over noisy references, offering a dynamic alternative to static knowledge injection methods.
major comments (4)
- [Abstract] Abstract: The central claim that 'VRAG-DFD achieved SOTA and competitive performance on DFD generalization testing' is unsupported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis, preventing evaluation of whether the RAG+RL mechanisms drive the reported gains.
- [Abstract] Abstract: No audit, precision/recall metrics, or factual correctness verification is reported for the RAG-retrieved items used to construct the FKD, which is load-bearing because the framework's value rests on the assumption that dynamic retrieval supplies high-quality forgery knowledge.
- [Abstract] Abstract: The F-CoT dataset and three-stage Alignment-SFT-GRPO pipeline lack any faithfulness metrics, entailment checks, or human ratings on the generated reasoning chains, especially when references contain noise; without these, performance cannot be attributed to the claimed critical reasoning capability rather than artifacts.
- [Abstract] Abstract: The manuscript provides only a high-level pipeline description with no details on the generalization test datasets, evaluation protocol, or specific results, making the SOTA assertion impossible to assess or reproduce.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below and have revised the manuscript to incorporate additional evidence, metrics, and details where the feedback correctly identifies gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'VRAG-DFD achieved SOTA and competitive performance on DFD generalization testing' is unsupported by any quantitative metrics, baseline comparisons, ablation studies, or error analysis, preventing evaluation of whether the RAG+RL mechanisms drive the reported gains.
Authors: We agree that the abstract, in its current concise form, does not include supporting quantitative evidence. The full manuscript contains experimental results with baseline comparisons, ablation studies on the RAG and RL components, and error analysis. We have revised the abstract to include key performance metrics and have ensured the Experiments section makes these results prominent for evaluation of the mechanisms' contributions. revision: yes
-
Referee: [Abstract] Abstract: No audit, precision/recall metrics, or factual correctness verification is reported for the RAG-retrieved items used to construct the FKD, which is load-bearing because the framework's value rests on the assumption that dynamic retrieval supplies high-quality forgery knowledge.
Authors: The comment correctly notes the absence of quantitative verification for FKD quality. While the construction process is described, we have added an audit subsection reporting precision/recall metrics and factual correctness verification on sampled retrieved items to substantiate the high-quality knowledge assumption. revision: yes
-
Referee: [Abstract] Abstract: The F-CoT dataset and three-stage Alignment-SFT-GRPO pipeline lack any faithfulness metrics, entailment checks, or human ratings on the generated reasoning chains, especially when references contain noise; without these, performance cannot be attributed to the claimed critical reasoning capability rather than artifacts.
Authors: We acknowledge this gap in validating the reasoning chains. We have added faithfulness metrics, automated entailment checks, and human ratings on a subset of F-CoT examples (including noisy reference cases) to the revised manuscript, allowing attribution of gains to the critical reasoning instilled by the GRPO stage. revision: yes
-
Referee: [Abstract] Abstract: The manuscript provides only a high-level pipeline description with no details on the generalization test datasets, evaluation protocol, or specific results, making the SOTA assertion impossible to assess or reproduce.
Authors: The referee is correct that the current manuscript presentation is high-level on these aspects. We have expanded the Experiments section with explicit details on the generalization test datasets, the full evaluation protocol, and specific numerical results to enable assessment and reproduction of the SOTA claims. revision: yes
Circularity Check
No significant circularity; empirical framework with independent performance claims
full rationale
The manuscript describes an empirical pipeline: RAG-based construction of FKD and F-CoT datasets, followed by a three-stage Alignment-SFT-GRPO training schedule on an MLLM, with final SOTA/competitive results reported on DFD generalization benchmarks. No equations, derivations, fitted parameters, or uniqueness theorems appear. Claims do not reduce to self-definitions or self-citations by construction; the reported performance is framed as an external empirical outcome rather than a quantity forced by the training inputs themselves. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption RAG can deliver high-quality associated forgery knowledge for MLLMs in DFD tasks
- ad hoc to paper The three-stage Alignment-SFT-GRPO pipeline endows MLLMs with critical reasoning abilities
Reference graph
Works this paper leans on
-
[1]
com / deepfakes / faceswap, 2020
Deepfakes.https : / / github . com / deepfakes / faceswap, 2020. Accessed: 2020-05-10. 3
2020
-
[2]
com / MarekKowalski / FaceSwap, 2020
Faceswap.https : / / github . com / MarekKowalski / FaceSwap, 2020. Accessed: 2020-05-10. 3
2020
-
[3]
irag: Advancing rag for videos with an incremental approach
Md Adnan Arefeen, Biplob Debnath, Md Yusuf Sar- war Uddin, and Srimat Chakradhar. irag: Advancing rag for videos with an incremental approach. InPro- ceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4341–4348, 2024. 3
2024
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923, 2025. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Aunet: Learning relations between ac- tion units for face forgery detection
Weiming Bai, Yufan Liu, Zhipeng Zhang, Bing Li, and Weiming Hu. Aunet: Learning relations between ac- tion units for face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24709–24719, 2023. 7
2023
-
[6]
End-to-end reconstruction-classification learning for face forgery detection
Junyi Cao, Chao Ma, Taiping Yao, Shen Chen, Shouhong Ding, and Xiaokang Yang. End-to-end reconstruction-classification learning for face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4113–4122, 2022. 1, 2
2022
-
[7]
arXiv preprint arXiv:2410.06126 , year=
Yize Chen, Zhiyuan Yan, Guangliang Cheng, Kangran Zhao, Siwei Lyu, and Baoyuan Wu. X2-dfd: A frame- work for explainable and extendable deepfake detec- tion.arXiv preprint arXiv:2410.06126, 2024. 2, 7
-
[8]
Large legal fictions: Profiling legal hal- lucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E Ho. Large legal fictions: Profiling legal hal- lucinations in large language models.Journal of Legal Analysis, 16(1):64–93, 2024. 3
2024
-
[9]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Can- ton Ferrer. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397, 2020. 7
work page internal anchor Pith review arXiv 2006
-
[10]
Exploring unbiased deepfake detection via token-level shuffling and mixing
Xinghe Fu, Zhiyuan Yan, Taiping Yao, Shen Chen, and Xi Li. Exploring unbiased deepfake detection via token-level shuffling and mixing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3040–3048, 2025. 7
2025
-
[11]
Exploring unbiased deepfake detection via token-level shuffling and mixing
Xinghe Fu, Zhiyuan Yan, Taiping Yao, Shen Chen, and Xi Li. Exploring unbiased deepfake detection via token-level shuffling and mixing. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3040–3048, 2025. 1, 2
2025
-
[12]
Generative adversar- ial networks.Communications of the ACM, 63(11): 139–144, 2020
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversar- ial networks.Communications of the ACM, 63(11): 139–144, 2020. 1
2020
-
[13]
Rethinking vision-language model in face forensics: Multi-modal interpretable forged face detector
Xiao Guo, Xiufeng Song, Yue Zhang, Xiaohong Liu, and Xiaoming Liu. Rethinking vision-language model in face forensics: Multi-modal interpretable forged face detector. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 105–116,
-
[14]
Hangfeng He, Hongming Zhang, and Dan Roth. Re- thinking with retrieval: Faithful large language model inference.ArXiv, abs/2301.00303, 2022. 3
-
[15]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vi- sion and pattern recognition, pages 770–778, 2016. 4
2016
-
[16]
Denois- ing diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denois- ing diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1
2020
-
[17]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 7, 8
2022
-
[18]
Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM computing surveys, 55(12):1–38, 2023. 3
2023
-
[19]
Oc-fakedect: Clas- sifying deepfakes using one-class variational autoen- coder
Hasam Khalid and Simon S Woo. Oc-fakedect: Clas- sifying deepfakes using one-class variational autoen- coder. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 656–657, 2020. 1, 2
2020
-
[20]
Truthlens: Explainable deepfake detec- tion for face manipulated and fully synthetic data
Rohit Kundu, Athula Balachandran, and Amit K Roy- Chowdhury. Truthlens: Explainable deepfake detec- tion for face manipulated and fully synthetic data. arXiv preprint arXiv:2503.15867, 2025. 2
-
[21]
Seeable: Soft dis- crepancies and bounded contrastive learning for ex- posing deepfakes
Nicolas Larue, Ngoc-Son Vu, Vitomir Struc, Peter Peer, and Vassilis Christophides. Seeable: Soft dis- crepancies and bounded contrastive learning for ex- posing deepfakes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21011–21021, 2023. 1, 2, 7
2023
-
[22]
Frequency-aware dis- criminative feature learning supervised by single- center loss for face forgery detection
Jiaming Li, Hongtao Xie, Jiahong Li, Zhongyuan Wang, and Yongdong Zhang. Frequency-aware dis- criminative feature learning supervised by single- center loss for face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6458–6467, 2021. 2
2021
-
[23]
arXiv preprint arXiv:1912.13457 , year=
Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, and Fang Wen. Faceshifter: Towards high fidelity and occlusion aware face swapping.arXiv preprint arXiv:1912.13457, 2019. 1
-
[24]
Face x-ray for more general face forgery detection
Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, Fang Wen, and Baining Guo. Face x-ray for more general face forgery detection. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5001–5010, 2020. 1, 2
2020
-
[25]
Celeb-df: A large-scale challenging dataset for deepfake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deepfake forensics. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3207–3216, 2020. 7
2020
-
[26]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek- v3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Spatial-phase shallow learning: rethinking face forgery detection in frequency domain
Honggu Liu, Xiaodan Li, Wenbo Zhou, Yuefeng Chen, Yuan He, Hui Xue, Weiming Zhang, and Nenghai Yu. Spatial-phase shallow learning: rethinking face forgery detection in frequency domain. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 772–781, 2021. 2
2021
-
[28]
Spatial-phase shallow learning: rethinking face forgery detection in frequency domain
Honggu Liu, Xiaodan Li, Wenbo Zhou, Yuefeng Chen, Yuan He, Hui Xue, Weiming Zhang, and Nenghai Yu. Spatial-phase shallow learning: rethinking face forgery detection in frequency domain. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 772–781, 2021. 7
2021
-
[29]
Generalizing face forgery detection with high- frequency features
Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Generalizing face forgery detection with high- frequency features. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 16317–16326, 2021. 7
2021
-
[30]
Generalizing face forgery detection with high- frequency features
Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Generalizing face forgery detection with high- frequency features. InProceedings of the IEEE/CVF conference on computer vision and pattern recogni- tion, pages 16317–16326, 2021. 2
2021
-
[31]
F2trans: High- frequency fine-grained transformer for face forgery de- tection.IEEE Transactions on Information Forensics and Security, 18:1039–1051, 2023
Changtao Miao, Zichang Tan, Qi Chu, Huan Liu, Honggang Hu, and Nenghai Yu. F2trans: High- frequency fine-grained transformer for face forgery de- tection.IEEE Transactions on Information Forensics and Security, 18:1039–1051, 2023. 7
2023
-
[32]
Laa-net: Localized arti- fact attention network for quality-agnostic and gen- eralizable deepfake detection
Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghor- bel, and Djamila Aouada. Laa-net: Localized arti- fact attention network for quality-agnostic and gen- eralizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 17395–17405, 2024. 7
2024
-
[33]
Core: Con- sistent representation learning for face forgery detec- tion
Yunsheng Ni, Depu Meng, Changqian Yu, Chengbin Quan, Dongchun Ren, and Youjian Zhao. Core: Con- sistent representation learning for face forgery detec- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pages 12–21, 2022. 7
2022
-
[34]
Siran Peng, Zipei Wang, Li Gao, Xiangyu Zhu, Tianshuo Zhang, Ajian Liu, Haoyuan Zhang, and Zhen Lei. Mllm-enhanced face forgery detection: A vision-language fusion solution.arXiv preprint arXiv:2505.02013, 2025. 2
-
[35]
Autorepo: A general framework for multimodal llm- based automated construction reporting.Expert Sys- tems with Applications, 255:124601, 2024
Hongxu Pu, Xincong Yang, Jing Li, and Runhao Guo. Autorepo: A general framework for multimodal llm- based automated construction reporting.Expert Sys- tems with Applications, 255:124601, 2024. 3
2024
-
[36]
Thinking in frequency: Face forgery detection by mining frequency-aware clues
Yuyang Qian, Guojun Yin, Lu Sheng, Zixuan Chen, and Jing Shao. Thinking in frequency: Face forgery detection by mining frequency-aware clues. InEu- ropean conference on computer vision, pages 86–103. Springer, 2020. 7
2020
-
[37]
Learning transferable visual models from natural lan- guage supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sas- try, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural lan- guage supervision. InInternational conference on ma- chine learning, pages 8748–8763. PmLR, 2021. 4, 8
2021
-
[38]
The curious case of hallucinations in neural machine translation.ArXiv, abs/2104.06683, 2021
Vikas Raunak, Arul Menezes, and Marcin Junczys- Dowmunt. The curious case of hallucinations in neural machine translation.ArXiv, abs/2104.06683, 2021. 3
-
[39]
High- resolution image synthesis with latent diffusion mod- els
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High- resolution image synthesis with latent diffusion mod- els. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
2022
-
[40]
Faceforensics++: Learning to detect manipulated fa- cial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Faceforensics++: Learning to detect manipulated fa- cial images. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 1–11,
-
[41]
Detecting deepfakes with self-blended images
Kaede Shiohara and Toshihiko Yamasaki. Detecting deepfakes with self-blended images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18720–18729, 2022. 1, 2, 7
2022
-
[42]
Extracting local in- formation from global representations for interpretable deepfake detection
Elahe Soltandoost, Richard Plesh, Stephanie Schuck- ers, Peter Peer, and Vitomir ˇStruc. Extracting local in- formation from global representations for interpretable deepfake detection. InProceedings of the Winter Con- ference on Applications of Computer Vision, pages 1629–1639, 2025. 7
2025
-
[43]
Domain general face forgery detection by learning to weight
Ke Sun, Hong Liu, Qixiang Ye, Yue Gao, Jianzhuang Liu, Ling Shao, and Rongrong Ji. Domain general face forgery detection by learning to weight. InProceed- ings of the AAAI conference on artificial intelligence, pages 2638–2646, 2021. 7
2021
-
[44]
Dual contrastive learning for general face forgery detection
Ke Sun, Taiping Yao, Shen Chen, Shouhong Ding, Jilin Li, and Rongrong Ji. Dual contrastive learning for general face forgery detection. InProceedings of the AAAI conference on artificial intelligence, pages 2316–2324, 2022. 7
2022
-
[45]
Xichen Tan, Yunfan Ye, Yuanjing Luo, Qian Wan, Fang Liu, and Zhiping Cai. Rag-adapter: A plug- and-play rag-enhanced framework for long video un- derstanding.arXiv preprint arXiv:2503.08576, 2025. 3
-
[46]
Face2face: Real-time face capture and reenactment of rgb videos
Justus Thies, Michael Zollhofer, Marc Stamminger, Christian Theobalt, and Matthias Nießner. Face2face: Real-time face capture and reenactment of rgb videos. InProceedings of the IEEE conference on computer vi- sion and pattern recognition, pages 2387–2395, 2016. 1, 3
2016
-
[47]
Deferred neural rendering: Image synthesis using neural textures.Acm Transactions on Graphics (TOG), 38(4):1–12, 2019
Justus Thies, Michael Zollh ¨ofer, and Matthias Nießner. Deferred neural rendering: Image synthesis using neural textures.Acm Transactions on Graphics (TOG), 38(4):1–12, 2019. 1, 3
2019
-
[48]
Altfreezing for more general video face forgery detection
Zhendong Wang, Jianmin Bao, Wengang Zhou, Weilun Wang, and Houqiang Li. Altfreezing for more general video face forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4129–4138, 2023. 7
2023
-
[49]
Ucf: Uncovering common features for gener- alizable deepfake detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. Ucf: Uncovering common features for gener- alizable deepfake detection. InProceedings of the IEEE/CVF international conference on computer vi- sion, pages 22412–22423, 2023. 7
2023
-
[50]
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke- Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decomposition for generaliz- able ai-generated image detection.arXiv preprint arXiv:2411.15633, 2024. 1, 2, 4, 7, 8
-
[51]
Df40: Toward next-generation deepfake detection.Advances in Neural Information Processing Systems, 37:29387– 29434, 2024
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, et al. Df40: Toward next-generation deepfake detection.Advances in Neural Information Processing Systems, 37:29387– 29434, 2024. 7
2024
-
[52]
Peipeng Yu, Jianwei Fei, Hui Gao, Xuan Feng, Zhihua Xia, and Chip Hong Chang. Unlocking the capabili- ties of large vision-language models for generalizable and explainable deepfake detection.arXiv preprint arXiv:2503.14853, 2025. 2, 7
-
[53]
Common sense reasoning for deepfake detection
Yue Zhang, Ben Colman, Xiao Guo, Ali Shahriyari, and Gaurav Bharaj. Common sense reasoning for deepfake detection. InEuropean conference on com- puter vision, pages 399–415. Springer, 2024. 2
2024
-
[54]
Learning self- consistency for deepfake detection
Tianchen Zhao, Xiang Xu, Mingze Xu, Hui Ding, Yuanjun Xiong, and Wei Xia. Learning self- consistency for deepfake detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 15023–15033, 2021. 7
2021
-
[55]
Diffswap: High-fidelity and controllable face swapping via 3d-aware masked diffusion
Wenliang Zhao, Yongming Rao, Weikang Shi, Zuyan Liu, Jie Zhou, and Jiwen Lu. Diffswap: High-fidelity and controllable face swapping via 3d-aware masked diffusion. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 8568–8577, 2023. 1
2023
-
[56]
Freqblender: Enhancing deepfake de- tection by blending frequency knowledge.Advances in Neural Information Processing Systems, 37:44965– 44988, 2024
Jiaran Zhou, Yuezun Li, Baoyuan Wu, Bin Li, Junyu Dong, et al. Freqblender: Enhancing deepfake de- tection by blending frequency knowledge.Advances in Neural Information Processing Systems, 37:44965– 44988, 2024. 7
2024
-
[57]
Docprompting: Generating code by retrieving the docs
Shuyan Zhou, Uri Alon, Frank F Xu, Zhengbao Jiang, and Graham Neubig. Docprompting: Generating code by retrieving the docs. InThe Eleventh International Conference on Learning Representations, 2022. 3
2022
-
[58]
Face forensics in the wild
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. Face forensics in the wild. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5778– 5788, 2021. 7
2021
-
[59]
Face forgery detection by 3d decomposi- tion
Xiangyu Zhu, Hao Wang, Hongyan Fei, Zhen Lei, and Stan Z Li. Face forgery detection by 3d decomposi- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2929– 2939, 2021. 1, 2
2021
-
[60]
, 0.692)` Opposing Evidence (contradicts my judgment): `(\
Bojia Zi, Minghao Chang, Jingjing Chen, Xingjun Ma, and Yu-Gang Jiang. Wilddeepfake: A challenging real-world dataset for deepfake detection. InProceed- ings of the 28th ACM international conference on mul- timedia, pages 2382–2390, 2020. 7 VRAG-DFD: Verifiable Retrieval-Augmentation for MLLM-based Deepfake Detection Supplementary Material A. Implementati...
2020
-
[61]
unnaturally shaped and misaligned teeth\
Verify Opposing Evidence: The RAG report's highest-scoring `Fake` evidence (similarity 0.717) claims \"unnaturally shaped and misaligned teeth\" and \"significant blurriness\" in the eyes. Upon re-examining the `Query_Image`, I cannot confirm these specific artifacts. The teeth are not clearly defined, but their shape is consistent with the overall low re...
-
[62]
the overall level of blurriness is consistent across the entire face, hair, and background.\
Verify Supporting Evidence:The RAG report's `Real` evidence (similarity 0.692) states that \"the overall level of blurriness is consistent across the entire face, hair, and background.\" This observation can be confirmed and perfectly aligns with my visual analysis. The consistency of the low resolution across all facial features is a strong indicator of ...
-
[63]
lips appear blurry\
Verify Opposing Evidence:The RAG report's highest-scoring `Fake` evidence (similarity 0.6383) claims the \"lips appear blurry\" and the \"skin on the chin and around the mouth is unnaturally smooth.\" This assertion cannot be confirmed by my visual inspection. The blurriness of the lips is consistent with the overall low resolution of the entire image, no...
-
[64]
the degree of softness and lack of fine detail on the facial skin is consistent with the blurriness of the hair and the background.\
Verify Supporting Evidence: The RAG report's `Real` evidence (similarity 0.6406) states that\"the degree of softness and lack of fine detail on the facial skin is consistent with the blurriness of the hair and the background.\" This statement can be confirmed and perfectly aligns with my visual analysis. The consistency of the low-resolution effect across...
-
[65]
However, this claim cannot be fully confirmed by my visual inspection
Verify Opposing Evidence: The RAG report's `Real` evidence (similarity 0.5938) claims that the blurriness is consistent across the entire image. However, this claim cannot be fully confirmed by my visual inspection. While the entire image is low-resolution, the smoothness on the face appears more pronounced and lacks the fine texture that would be expecte...
-
[66]
appears unusually smooth, lacking high- frequency details\
Verify Supporting Evidence: The RAG report's `Fake` evidence (similarity 0.5938) states that the skin \"appears unusually smooth, lacking high- frequency details\" and has a \"'mask-like' appearance.\" This description can be directly confirmed on the `Query_Image`. The waxy, textureless quality I observed on the man's forehead and cheeks perfectly matche...
-
[67]
Consistent Skin Tone/Lighting\
Verify Opposing Evidence: The RAG report's highest-scoring `Real` evidence (similarity 0.670) claims \"Consistent Skin Tone/Lighting\". While the lighting is indeed consistent, this claim cannot be fully confirmed because it overlooks the key visual artifact I identified: the complete absence of natural skin texture. The claim of \"consistent\" skin tone ...
-
[68]
abnormally smooth and blurry\
Verify Supporting Evidence: The RAG report's `Fake` evidence (similarity 0.650) states that the skin is \"abnormally smooth and blurry\" and lacks \"fine wrinkles and natural skin texture.\" This description can be directly confirmed and perfectly matches my visual observation of the `Query_Image`. The lack of texture is a significant indicator of manipul...
-
[69]
Carefully compare all facial features, hair, skin color, etc., to locate manipulated regions without omis- sions or hallucinations
-
[70]
Correct Example: Inconsistent skin tone, feature overlap, blurry edges, structural distortion
Distinguish between: •Analyze This - Forgery Artifacts: Anomalies caused by technical flaws (e.g., low-resolution bottle- necks, blending, alignment failures). Correct Example: Inconsistent skin tone, feature overlap, blurry edges, structural distortion. •Ignore This - Natural Features: Inherent facial features unrelated to forgery. Incorrect Example: Mak...
-
[71]
skin looks airbrushed
Attribute observed phenomena (e.g., “skin looks airbrushed”) to the technical flaw (e.g., “detail loss due to low resolution”)
-
[72]
Based on Comparison, Loyal to Evidence
Report all types of artifacts present in a region, not only the most obvious. DeepFakes Potential Forgery Artifacts Reference Guide: 1.Blending Border Artifacts (High-Incident Area) •Cause: Poisson blending at facial edges (face periphery, hair, chin, neck). •Manifestation: Edge color differences, unnatural blurring/halo effects along contours. 2.Structur...
-
[73]
Pay special attention to the lips and surrounding areas
Identify all differences to locate manipulated areas, including facial features, hair, and skin tone. Pay special attention to the lips and surrounding areas
-
[74]
Correct Example: ’Plastic-like’ skin, expression structural distortion (’puppet-like’), misalignment at facial edges, unrealistic lighting/highlights
Distinguish between: •Analyze This - Forgery Artifacts: Technical anomalies (3D re-rendering, Blendshape parameterized driving, 3D tracking errors). Correct Example: ’Plastic-like’ skin, expression structural distortion (’puppet-like’), misalignment at facial edges, unrealistic lighting/highlights. •Ignore This - Natural Features: Expression changes thems...
-
[75]
Base your analysis on the technical flaws outlined in the Reference Guide; attribute observed phenom- ena to the correct cause
-
[76]
Based on Comparison, Loyal to Evidence
Note: Face2Face preserves identity; focus on expression manipulation artifacts, not identity differences. Face2Face Potential Forgery Artifacts Reference Guide: 1.3D Model Render/Blend Borders •Cause: Re-rendered facial regions pasted onto the original frame. •Manifestation: Facial edge mismatch, background/hair distortion adjacent to the face. 2.Texture ...
-
[77]
Carefully compare each facial feature, hair, skin, etc., to locate manipulated regions without omissions or hallucina- tions
-
[78]
Correct Example: Inconsistent skin tone, feature overlap, blurry edges, structural distortion
Distinguish clearly between: •Analyze This - Forgery Artifacts: Visual anomalies directly caused by technical flaws (e.g., blending, alignment, 3D fitting). Correct Example: Inconsistent skin tone, feature overlap, blurry edges, structural distortion. •Ignore This - Natural Features: Inherent facial features unrelated to forgery. Incorrect Example: Makeup...
-
[79]
two eyebrows
Attribute observed phenomena (e.g., “two eyebrows”) to technical flaws (e.g., “feature overlap caused by keypoint mismatch”). FaceSwap Potential Forgery Artifacts Reference Guide:
-
[80]
•Incorrect Lighting/Shadows: Face highlights/shadows inconsistent with environment
Color & Lighting Inconsistency •Inconsistent Skin Tone: Skin hue, saturation, or brightness differs from surrounding regions. •Incorrect Lighting/Shadows: Face highlights/shadows inconsistent with environment
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.