Recognition: unknown
RecNextEval: A Reference Implementation for Temporal Next-Batch Recommendation Evaluation
Pith reviewed 2026-05-10 12:56 UTC · model grok-4.3
The pith
RecNextEval provides a reference implementation that evaluates next-batch recommendation models with time-window splits along a global timeline to minimize data leakage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RecNextEval is a reference implementation that applies time-window data splitting to evaluate next-batch recommendation models along a single global timeline, thereby reducing data leakage that arises when splits ignore the chronological order of all interactions across users.
What carries the argument
The time-window data split mechanism, which partitions the full dataset into consecutive time windows so that each evaluation batch only uses past data up to that window's start.
If this is right
- Existing next-batch models may report lower performance numbers when re-evaluated under the stricter temporal protocol.
- New model development will need to incorporate temporal ordering constraints from the start rather than as a post-hoc fix.
- Standardized toolkits can adopt the same global-timeline split to improve comparability across papers.
- Production deployment decisions will rest on evaluation results that more closely match actual sequential data arrival.
Where Pith is reading between the lines
- The same time-window principle could be applied to other sequential tasks such as session-based or streaming recommendation without major redesign.
- Re-running published baselines with this split would likely produce a revised ranking of which models actually perform best under realistic constraints.
- Integration with existing RecSys libraries could create hybrid evaluation pipelines that combine multiple leakage-minimization techniques.
Load-bearing premise
That time-window splits along a global timeline accurately simulate production environments and are superior to other protocols for validating next-batch recommendation models.
What would settle it
A direct comparison experiment in which the same set of models is evaluated once with time-window splits and once with conventional random or per-user splits, then checked for measurable differences in both reported accuracy metrics and explicit data-leakage indicators such as access to future items.
Figures


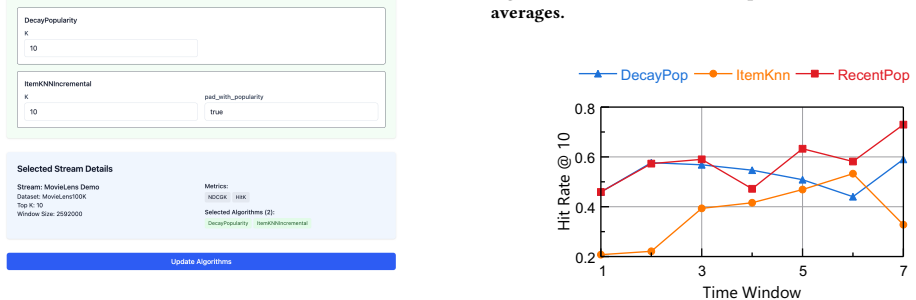
read the original abstract
A good number of toolkits have been developed in Recommender Systems (RecSys) research to promote fair evaluation and reproducibility. However, recent critical examinations of RecSys evaluation protocols have raised concerns regarding the validity of existing evaluation pipelines. In this demonstration, we present RecNextEval, a reference implementation of an evaluation framework specifically designed for next-batch recommendation. RecNextEval utilizes a time-window data split to ensure models are evaluated along a global timeline, effectively minimizing data leakage. Our implementation highlights the inherent complexities of RecSys evaluation and encourages a shift toward model development that more accurately simulates production environments. The RecNextEval library and its accompanying GUI interface are open-source and publicly accessible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents RecNextEval, a reference implementation and accompanying GUI for evaluating next-batch recommendation models. It employs a time-window data split along a global timeline to evaluate models while minimizing data leakage, with the goal of encouraging evaluation practices that more closely simulate production environments in recommender systems. The library is open-source and publicly accessible.
Significance. If the implementation correctly realizes the described split and the approach is sound, the work could help address documented concerns about data leakage in RecSys evaluation protocols by providing a concrete, reusable tool. The open-source release and GUI are strengths that support reproducibility and adoption.
major comments (1)
- Abstract: the claim that the time-window data split 'effectively minimizing data leakage' is presented without any supporting validation experiments, comparisons to alternative protocols, or analysis of leakage reduction. This is load-bearing for the paper's central motivation and demonstration purpose.
minor comments (1)
- Abstract: the reference to 'recent critical examinations of RecSys evaluation protocols' would benefit from specific citations to ground the motivation.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our demonstration paper. We address the major comment below and propose a targeted revision to better align the abstract with the paper's scope as a reference implementation.
read point-by-point responses
-
Referee: Abstract: the claim that the time-window data split 'effectively minimizing data leakage' is presented without any supporting validation experiments, comparisons to alternative protocols, or analysis of leakage reduction. This is load-bearing for the paper's central motivation and demonstration purpose.
Authors: We agree that the manuscript provides no empirical validation experiments, comparisons to alternative splits, or quantitative analysis of leakage reduction. As a demonstration paper whose primary contribution is the open-source RecNextEval library and GUI, the work focuses on implementing and exposing the time-window split rather than conducting a comparative study. The phrasing in the abstract reflects the design intent: by enforcing evaluation along a single global timeline, the split ensures that training data cannot include information from the future relative to test instances, which logically precludes a common form of temporal leakage present in random or user-wise splits. Nevertheless, we accept that the word 'effectively' implies a stronger empirical guarantee than the paper demonstrates. We will revise the abstract to replace 'effectively minimizing data leakage' with 'designed to minimize data leakage' and will add a brief clarifying sentence in the introduction noting that empirical quantification of leakage reduction is left to future users of the toolkit. This change preserves the motivation while accurately representing the paper's scope. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript is a demonstration paper presenting RecNextEval, an open-source reference implementation and GUI for temporal next-batch recommendation evaluation. Its core design choice—a global-timeline time-window data split—is stated directly as a mechanism to reduce leakage, without any accompanying equations, derivations, fitted parameters, or predictions that reduce to the inputs by construction. No self-definitional steps, fitted-input predictions, load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided text. The work is self-contained as a software artifact whose validity rests on implementation details rather than any circular chain of reasoning.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vito Walter Anelli, Alejandro Bellogin, Antonio Ferrara, Daniele Malitesta, Fe- lice Antonio Merra, Claudio Pomo, Francesco Maria Donini, and Tommaso Di Noia. 2021. Elliot: A Comprehensive and Rigorous Framework for Repro- ducible Recommender Systems Evaluation. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in In...
-
[2]
Andreas Argyriou, Miguel González-Fierro, and Le Zhang. 2020. Microsoft Recommenders: Best Practices for Production-Ready Recommendation Systems. InCompanion Proceedings of the Web Conference 2020(Taipei, Taiwan)(WWW ’20). Association for Computing Machinery, New York, NY, USA, 50–51. doi:10. 1145/3366424.3382692
-
[3]
Christine Bauer, Eva Zangerle, and Alan Said. 2024. Exploring the Landscape of Recommender Systems Evaluation: Practices and Perspectives.ACM Trans. Recomm. Syst.2, 1, Article 11 (March 2024), 31 pages. doi:10.1145/3629170
-
[4]
Patrick John Chia, Jacopo Tagliabue, Federico Bianchi, Chloe He, and Brian Ko. 2022. Beyond NDCG: Behavioral Testing of Recommender Systems with RecList. InCompanion Proceedings of the Web Conference 2022(Virtual Event, Lyon, France)(WWW ’22). Association for Computing Machinery, New York, NY, USA, 99–104. doi:10.1145/3487553.3524215
-
[5]
Michael D. Ekstrand. 2020. LensKit for Python: Next-Generation Software for Recommender Systems Experiments. InProceedings of the 29th ACM Interna- tional Conference on Information & Knowledge Management(Virtual Event, Ire- land)(CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2999–3006. doi:10.1145/3340531.3412778
-
[6]
João Gama, Indrundefined Žliobaitundefined, Albert Bifet, Mykola Pechenizkiy, and Abdelhamid Bouchachia. 2014. A survey on concept drift adaptation.ACM Comput. Surv.46, 4, Article 44 (March 2014), 37 pages. doi:10.1145/2523813
-
[7]
Yitong Ji, Aixin Sun, Jie Zhang, and Chenliang Li. 2020. A Re-visit of the Popularity Baseline in Recommender Systems. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 1749–1752. doi:10.1145/3397271.3401233
-
[8]
Anton Klenitskiy, Anna Volodkevich, Anton Pembek, and Alexey Vasilev. 2026. An Analysis of Sequential Patterns in Datasets for Evaluation of Sequential Recommendations.ACM Trans. Recomm. Syst.(Jan. 2026). doi:10.1145/3787969
-
[9]
Jiayu Li, Hanyu Li, Zhiyu He, Weizhi Ma, Peijie Sun, Min Zhang, and Shaoping Ma. 2024. ReChorus2.0: A Modular and Task-Flexible Recommendation Library. InProceedings of the 18th ACM Conference on Recommender Systems(Bari, Italy) (RecSys ’24). Association for Computing Machinery, New York, NY, USA, 454–464. doi:10.1145/3640457.3688076
-
[10]
Dickerson, and Colin White
Duncan McElfresh, Sujay Khandagale, Jonathan Valverde, John P. Dickerson, and Colin White. 2022. On the generalizability and predictability of recommender systems. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA)(NIPS ’22). Curran Associates Inc., Red Hook, NY, USA, Article 319, 17 pages
2022
-
[11]
Lien Michiels, Robin Verachtert, and Bart Goethals. 2022. RecPack: An(Other) Experimentation Toolkit for Top-N Recommendation Using Implicit Feedback Data. InProceedings of the 16th ACM Conference on Recommender Systems(Seattle, WA, USA)(RecSys ’22). Association for Computing Machinery, New York, NY, USA, 648–651. doi:10.1145/3523227.3551472
-
[12]
Alexander Ploshkin, Vladislav Tytskiy, Alexey Pismenny, Vladimir Baikalov, Evgeny Taychinov, Artem Permiakov, Daniil Burlakov, and Eugene Krofto. 2025. Yambda-5B — A Large-Scale Multi-Modal Dataset for Ranking and Retrieval. In Proceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys ’25). Association for Computing Machinery, New York, ...
-
[13]
Aixin Sun. 2023. Take a Fresh Look at Recommender Systems from an Evaluation Standpoint. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computing Machinery, New York, NY, USA, 2629–2638. doi:10. 1145/3539618.3591931
-
[14]
Zhu Sun, Hui Fang, Jie Yang, Xinghua Qu, Hongyang Liu, Di Yu, Yew-Soon Ong, and Jie Zhang. 2023. DaisyRec 2.0: Benchmarking Recommendation for Rigorous Evaluation.IEEE Trans. Pattern Anal. Mach. Intell.45, 7 (July 2023), 8206–8226. doi:10.1109/TPAMI.2022.3231891
-
[15]
Lanling Xu, Zhen Tian, Gaowei Zhang, Junjie Zhang, Lei Wang, Bowen Zheng, Yifan Li, Jiakai Tang, Zeyu Zhang, Yupeng Hou, Xingyu Pan, Wayne Xin Zhao, Xu Chen, and Ji-Rong Wen. 2023. Towards a More User-Friendly and Easy-to- Use Benchmark Library for Recommender Systems. InProceedings of the 46th International ACM SIGIR Conference on Research and Developmen...
-
[16]
Jieming Zhu, Quanyu Dai, Liangcai Su, Rong Ma, Jinyang Liu, Guohao Cai, Xi Xiao, and Rui Zhang. 2022. BARS: Towards Open Benchmarking for Recom- mender Systems. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval(Madrid, Spain)(SIGIR ’22). Association for Computing Machinery, New York, NY, USA,...
-
[17]
Indrăź źLiobaităź, Albert Bifet, Jesse Read, Bernhard Pfahringer, and Geoff Holmes
-
[18]
Learn.98, 3 (March 2015), 455–482
Evaluation methods and decision theory for classification of streaming data with temporal dependence.Mach. Learn.98, 3 (March 2015), 455–482. doi:10.1007/s10994-014-5441-4
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.