Recognition: unknown
Breaking the Generator Barrier: Disentangled Representation for Generalizable AI-Text Detection
Pith reviewed 2026-05-10 13:11 UTC · model grok-4.3
The pith
Disentangling AI-detection semantics from generator-specific artifacts allows detectors to generalize to new language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
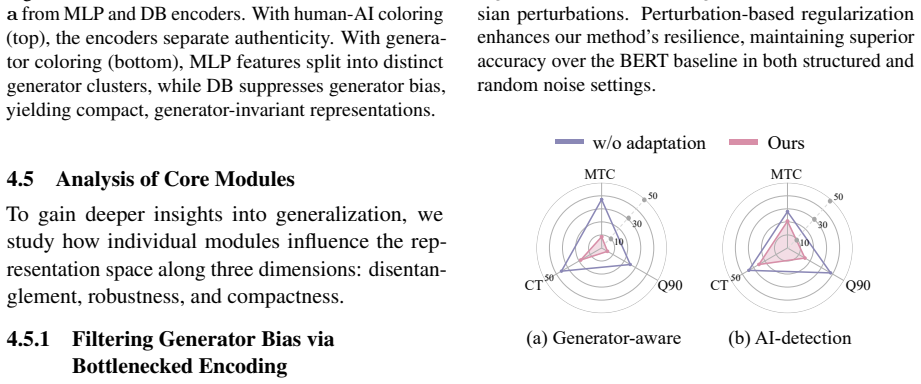
A progressively structured framework disentangles AI-detection semantics from generator-aware artifacts through compact latent encoding that encourages semantic minimality, perturbation-based regularization to reduce residual entanglement, and a final discriminative adaptation stage. This produces consistent gains over prior methods and improves further as training-generator diversity increases in open-set settings.
What carries the argument
Progressively structured disentanglement framework that uses compact latent encoding for minimal semantics, followed by perturbation regularization and discriminative adaptation.
If this is right
- Detectors remain effective on unseen generators without retraining for each new model.
- Performance improves as the number and variety of training generators grows, supporting open-set scalability.
- The approach delivers measurable gains over prior methods on a benchmark of twenty LLMs across seven categories.
Where Pith is reading between the lines
- The same separation of core signals from source artifacts could extend to detecting generated content in other media like images or audio from evolving models.
- Broad training across current generators may produce detectors that handle future models with less degradation.
- The stages could be tested in low-data regimes to check whether the disentanglement still holds with limited examples.
Load-bearing premise
The method assumes that a compact latent encoding plus perturbation regularization can cleanly separate detection semantics from generator artifacts without discarding useful signals.
What would settle it
If a new LLM outside the training set and MAGE benchmark shows no accuracy or F1 gain over existing detectors, the generalization benefit would be refuted.
Figures



read the original abstract
As large language models (LLMs) generate text that increasingly resembles human writing, the subtle cues that distinguish AI-generated content from human-written content become increasingly challenging to capture. Reliance on generator-specific artifacts is inherently unstable, since new models emerge rapidly and reduce the robustness of such shortcuts. This generalizes unseen generators as a central and challenging problem for AI-text detection. To tackle this challenge, we propose a progressively structured framework that disentangles AI-detection semantics from generator-aware artifacts. This is achieved through a compact latent encoding that encourages semantic minimality, followed by perturbation-based regularization to reduce residual entanglement, and finally a discriminative adaptation stage that aligns representations with task objectives. Experiments on MAGE benchmark, covering 20 representative LLMs across 7 categories, demonstrate consistent improvements over state-of-the-art methods, achieving up to 24.2% accuracy gain and 26.2% F1 improvement. Notably, performance continues to improve as the diversity of training generators increases, confirming strong scalability and generalization in open-set scenarios. Our source code will be publicly available at https://github.com/PuXiao06/DRGD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a progressively structured framework (DRGD) to disentangle AI-detection semantics from generator-aware artifacts for generalizable AI-text detection. It employs a compact latent encoding to promote semantic minimality, followed by perturbation-based regularization to reduce residual entanglement, and a final discriminative adaptation stage. Experiments on the MAGE benchmark (20 LLMs across 7 categories) report consistent gains over state-of-the-art methods, reaching up to 24.2% accuracy improvement and 26.2% F1 improvement, with performance scaling positively as the number of training generators increases, supporting open-set generalization. The authors commit to releasing source code publicly.
Significance. If the disentanglement mechanism proves effective, the work could meaningfully advance robust detection methods that avoid brittle generator-specific shortcuts, addressing a key challenge as new LLMs emerge. The scalability observation with increasing generator diversity is promising for practical deployment. Public code release is a clear strength that supports reproducibility and follow-on research. However, the significance hinges on whether reported gains arise from the claimed mechanism rather than confounding factors such as data volume or model capacity.
major comments (2)
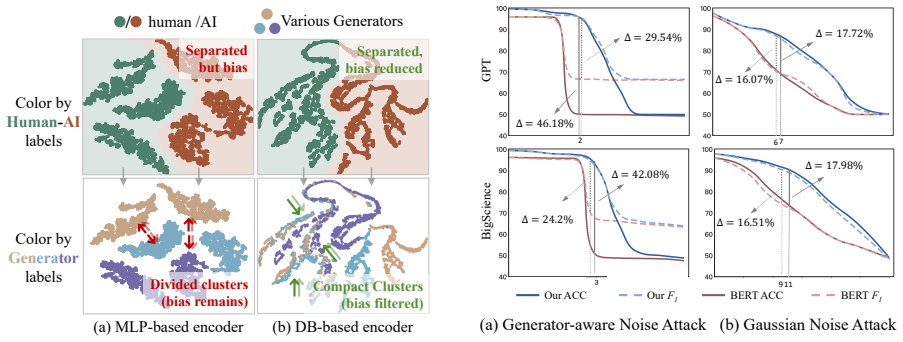
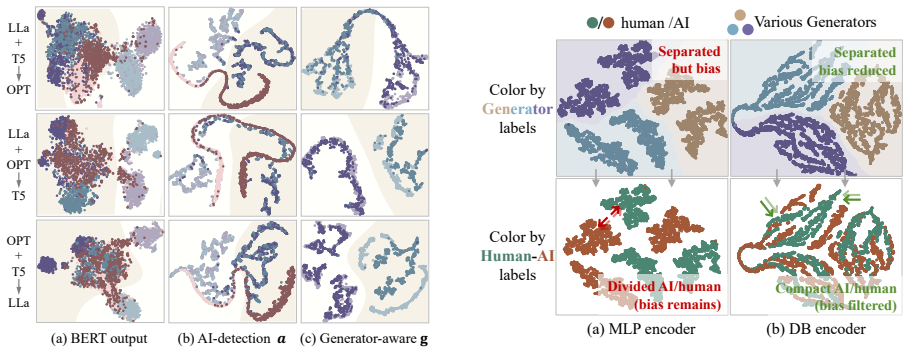
- [Experiments section] Experiments section: Downstream accuracy and F1 gains on MAGE are reported, but no intermediate diagnostics (e.g., mutual information between latents and generator identity, representation visualizations, or controlled ablations isolating the perturbation regularization term) are provided. This is load-bearing for the central claim, as the abstract and skeptic note leave open whether improvements stem from successful disentanglement or from training diversity alone.
- [Method section] Method section: The compact latent encoding and perturbation-based regularization are described at a high level without explicit loss functions, architectural equations, or hyperparameter details. This absence prevents assessment of how semantic minimality is enforced or entanglement reduced, directly undermining evaluation of the proposed framework's technical contribution.
minor comments (2)
- The abstract claims 'up to 24.2% accuracy gain' without specifying the exact baseline methods, train/test splits, or conditions under which the maximum is achieved.
- No error bars, number of runs, or statistical significance tests accompany the reported performance metrics, reducing confidence in the reliability of the improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to incorporate additional technical details and experimental diagnostics as outlined.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: Downstream accuracy and F1 gains on MAGE are reported, but no intermediate diagnostics (e.g., mutual information between latents and generator identity, representation visualizations, or controlled ablations isolating the perturbation regularization term) are provided. This is load-bearing for the central claim, as the abstract and skeptic note leave open whether improvements stem from successful disentanglement or from training diversity alone.
Authors: We agree that direct evidence of disentanglement would strengthen the central claim. The reported scaling of performance with increasing numbers of training generators provides indirect support, as gains continue to accrue beyond what would be expected from diversity alone if the model were merely memorizing generator-specific cues. However, to directly address the concern, we will add the requested diagnostics in the revised Experiments section: t-SNE visualizations of the latent representations colored by generator identity, estimates of mutual information between latent dimensions and generator labels, and controlled ablations that isolate the contribution of the perturbation-based regularization term by comparing variants with and without it. revision: yes
-
Referee: [Method section] Method section: The compact latent encoding and perturbation-based regularization are described at a high level without explicit loss functions, architectural equations, or hyperparameter details. This absence prevents assessment of how semantic minimality is enforced or entanglement reduced, directly undermining evaluation of the proposed framework's technical contribution.
Authors: We acknowledge that the current Method section presents the framework components at a conceptual level. In the revision, we will expand this section to include the explicit loss functions for the compact latent encoding objective (enforcing semantic minimality), the perturbation-based regularization term, and the final discriminative adaptation stage, along with the corresponding architectural equations. A table of all key hyperparameters and training details will also be added to enable full reproduction and assessment of the technical approach. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper proposes a progressively structured empirical framework consisting of compact latent encoding for semantic minimality, perturbation-based regularization, and discriminative adaptation. No mathematical derivations, equations, or first-principles predictions are present that reduce to inputs by construction. Claims rest on experimental results from the external MAGE benchmark across 20 LLMs, with reported accuracy/F1 gains and scalability observations. This constitutes a standard empirical contribution without self-definitional, fitted-input, or self-citation circularity.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
MELD: Multi-Task Equilibrated Learning Detector for AI-Generated Text
MELD is a multi-task AI-text detector using auxiliary heads, uncertainty-weighted losses, EMA distillation, and pairwise ranking that reaches 99.9% TPR at 1% FPR on a new held-out benchmark while remaining competitive...
Reference graph
Works this paper leans on
-
[1]
Shuhuai Ren, Yihe Deng, Kun He, and Wanxiang Che
Dear: Disentangled event-agnostic representa- tion learning for early fake news detection.Transac- tions of the Association for Computational Linguis- tics, 13:343–356. Shuhuai Ren, Yihe Deng, Kun He, and Wanxiang Che
-
[2]
InProceedings of the 57th annual meeting of the as- sociation for computational linguistics, pages 1085– 1097
Generating natural language adversarial ex- amples through probability weighted word saliency. InProceedings of the 57th annual meeting of the as- sociation for computational linguistics, pages 1085– 1097. Rui Shao and 1 others. 2023. Detecting and grounding multi-modal media manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pa...
2023
-
[3]
InThe 2023 Conference on Empirical Methods in Natural Language Processing
DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text. InThe 2023 Conference on Empirical Methods in Natural Language Processing. Bryan E Tuck and Rakesh M Verma. 2026. Guided perturbation sensitivity (gps): Detecting adversarial text via embedding stability and word importance. InProceedings of the AAAI Conference o...
2023
-
[4]
Authorship attribution for neural text gener- ation. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 8384–8395. Christoforos Vasilatos, Manaar Alam, Talal Rahwan, Yasir Zaki, and Michail Maniatakos. 2023. Howkgpt: Investigating the detection of chatgpt-generated uni- versity student homework through ...
-
[5]
Xiaowei Zhu, Yubing Ren, Yanan Cao, Xixun Lin, Fang Fang, and Yangxi Li
Adadetectgpt: Adaptive detection of llm- generated text with statistical guarantees.The 39th Conference on Neural Information Processing Sys- tems. Xiaowei Zhu, Yubing Ren, Yanan Cao, Xixun Lin, Fang Fang, and Yangxi Li. 2025. Reliably bounding false positives: A zero-shot machine-generated text detec- tion framework via multiscaled conformal prediction. ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.