Recognition: unknown
The cognitive companion: a lightweight parallel monitoring architecture for detecting and recovering from reasoning degradation in LLM agents
Pith reviewed 2026-05-10 13:11 UTC · model grok-4.3
The pith
A parallel Cognitive Companion architecture monitors LLM agents to detect and recover from reasoning degradation like looping with low or zero overhead.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
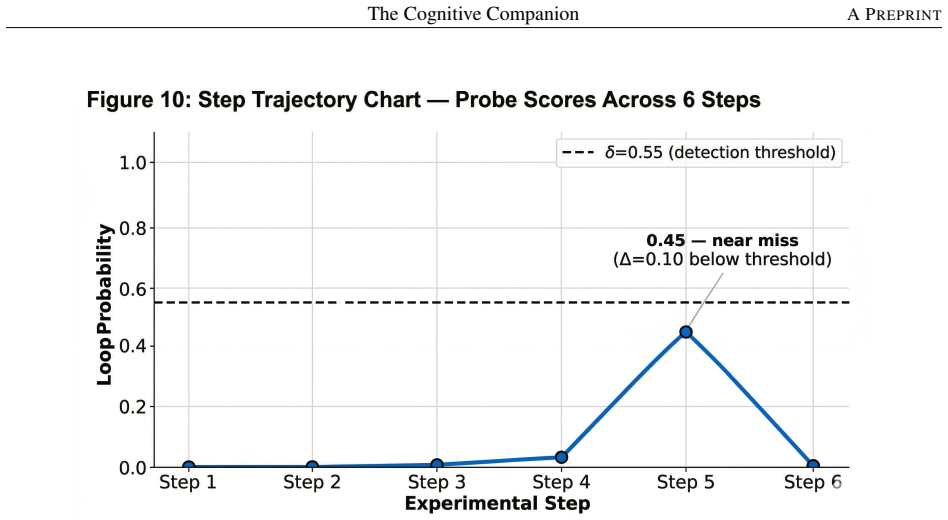
The paper claims that a parallel monitoring architecture called the Cognitive Companion can detect reasoning degradation in LLM agents and intervene to reduce repetition, with the LLM-based companion achieving 52-62 percent reduction at approximately 11 percent overhead and the probe-based companion, trained on hidden states from a specific layer, delivering a mean effect size of +0.471 at zero overhead along with cross-validated AUROC of 0.840 on proxy data. The central empirical observation is that these benefits are task-type dependent, proving most useful on loop-prone and open-ended tasks while showing no improvement on 1B-1.5B scale models even when interventions occur.
What carries the argument
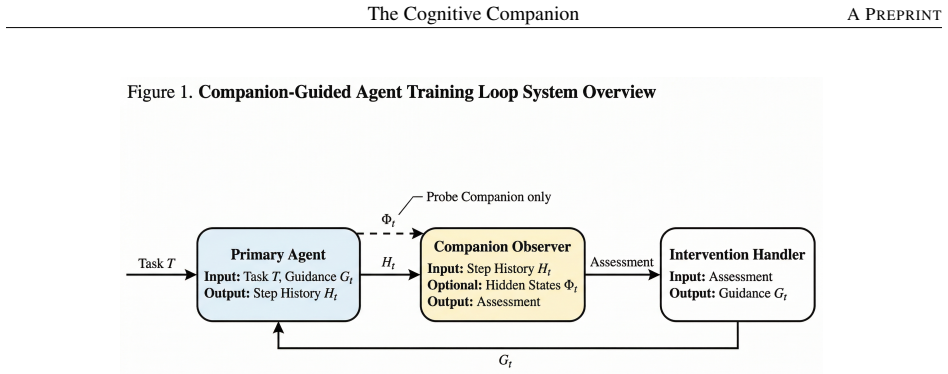
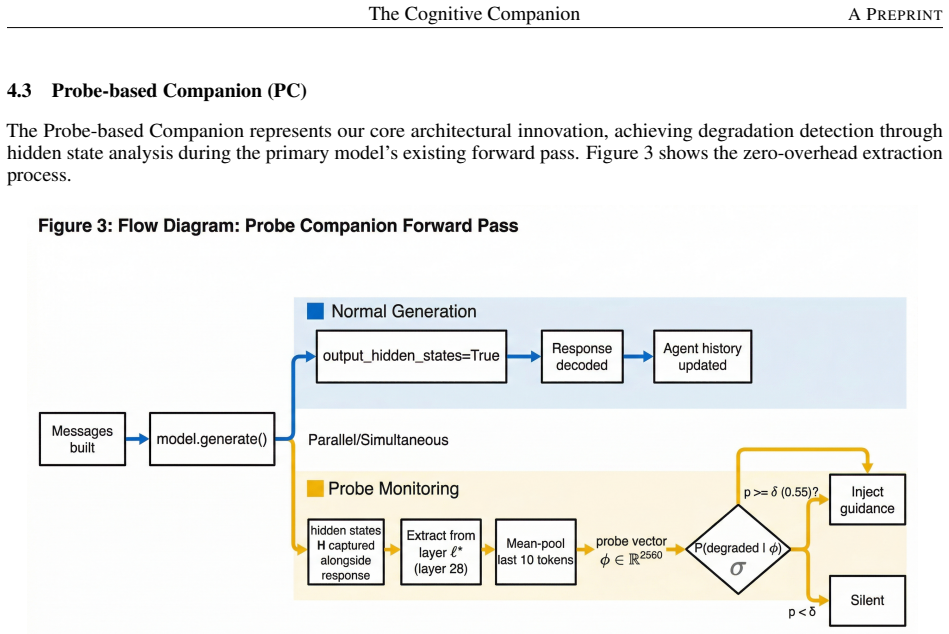
The Cognitive Companion, a parallel monitoring architecture with an LLM-based implementation for monitoring and recovery plus a probe-based implementation that trains lightweight classifiers on internal hidden states to flag degradation without extra inference cost.
If this is right
- Companions provide the largest gains on loop-prone and open-ended tasks while offering little or no benefit on structured tasks.
- Probe-based monitoring enables degradation detection at zero added inference cost by using internal model states.
- Interventions remain ineffective on models at the 1B-1.5B scale even when triggers fire.
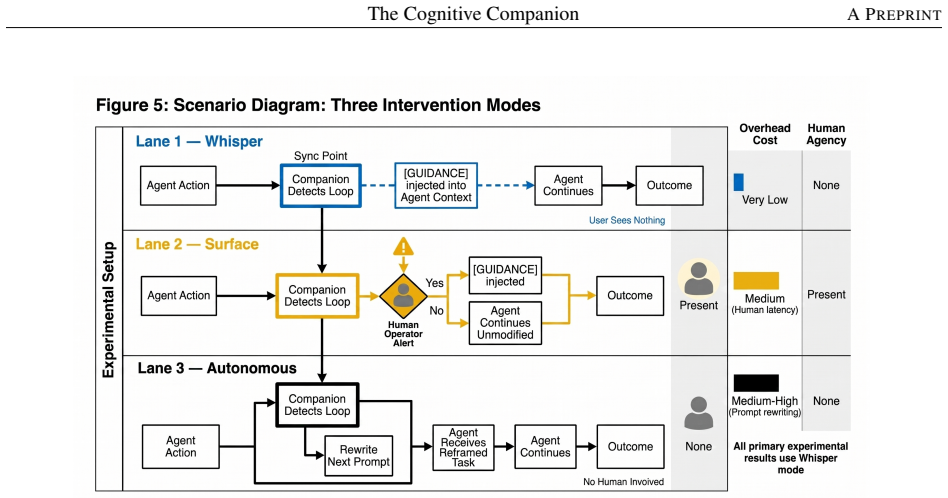
- The architecture supports selective activation rather than constant monitoring as a design choice.
Where Pith is reading between the lines
- Task-type detection could be added upstream to activate companions only when likely to help, reducing average overhead further.
- The probe approach might extend to other degradation signals beyond repetition, such as factual drift or goal abandonment.
- Combining probes across multiple layers or with lightweight external checks could improve robustness without regaining full LLM overhead.
Load-bearing premise
The reductions in repetition and positive effect sizes observed in the small feasibility study on specific models and tasks will hold more broadly without the monitoring introducing unmeasured side effects or false triggers that harm overall performance.
What would settle it
A controlled follow-up experiment on a wider set of tasks and larger models that finds no statistically significant drop in repetition rates or that shows quality degradation from companion interventions would falsify the practical value of the approach.
Figures











read the original abstract
Large language model (LLM) agents on multi-step tasks suffer reasoning degradation, looping, drift, stuck states, at rates up to 30% on hard tasks. Current solutions include hard step limits (abrupt) or LLM-as-judge monitoring (10-15% overhead per step). This paper introduces the Cognitive Companion, a parallel monitoring architecture with two implementations: an LLM-based Companion and a novel zero-overhead Probe-based Companion. We report a three-batch feasibility study centered on Gemma 4 E4B, with an additional exploratory small-model analysis on Qwen 2.5 1.5B and Llama 3.2 1B. In our experiments, the LLM-based Companion reduced repetition on loop-prone tasks by 52-62% with approximately 11% overhead. The Probe-based Companion, trained on hidden states from layer 28, showed a mean effect size of +0.471 at zero measured inference overhead; its strongest probe result achieved cross-validated AUROC 0.840 on a small proxy-labeled dataset. A key empirical finding is that companion benefit appears task-type dependent: companions are most helpful on loop-prone and open-ended tasks, while effects are neutral or negative on more structured tasks. Our small-model experiments also suggest a possible scale boundary: companions did not improve the measured quality proxy on 1B-1.5B models, even when interventions fired. Overall, the paper should be read as a feasibility study rather than a definitive validation. The results provide encouraging evidence that sub-token monitoring may be useful, identify task-type sensitivity as a practical design constraint, and motivate selective companion activation as a promising direction for future work.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Cognitive Companion, a parallel monitoring architecture for LLM agents to detect and recover from reasoning degradation (looping, drift, stuck states) on multi-step tasks. It describes two implementations—an LLM-based Companion and a zero-overhead Probe-based Companion trained on hidden states (layer 28)—and reports results from a three-batch feasibility study on Gemma 4 E4B plus exploratory runs on Qwen 2.5 1.5B and Llama 3.2 1B. Key empirical claims include 52-62% repetition reduction (LLM-based, ~11% overhead), mean effect size +0.471 and cross-validated AUROC 0.840 (probe-based), with benefits appearing task-type dependent and absent on 1B-1.5B models.
Significance. If the reported reductions and detection performance hold under more rigorous controls, the architecture offers a practical, low-overhead approach to improving reliability of LLM agents, especially via sub-token probe monitoring. The identification of task-type sensitivity and possible scale boundaries provides actionable design constraints for future selective activation strategies.
major comments (3)
- [Experiments] Experiments section: the proxy-labeled dataset used for the probe AUROC 0.840 is described only as 'small'; no size, proxy-label generation procedure, inter-rater reliability, or label-noise controls are provided, which is load-bearing for interpreting the cross-validated result as evidence of genuine detection rather than overfitting to chosen proxies.
- [Results] Results on LLM-based Companion: the 52-62% repetition reduction and 11% overhead are reported from a three-batch feasibility study without stating per-batch trial counts, variance, statistical tests, or full baseline comparisons (e.g., hard step limits), making it impossible to assess whether the effect is robust or task-specific noise.
- [Exploratory small-model analysis] Small-model analysis and task-type dependence: the claims of no benefit on 1B-1.5B models and neutral/negative effects on structured tasks rest on the same limited three-batch design; without quantified effect sizes per task category or controls for intervention side-effects, these boundary conditions cannot be separated from the specific models and tasks tested.
minor comments (2)
- [Abstract] The abstract and results should explicitly state the total number of tasks, runs, and any data exclusion criteria to allow readers to gauge the scale of the feasibility study.
- [Results] Clarify how the 'mean effect size of +0.471' was computed (e.g., which quality proxy, aggregation across batches) and whether it is standardized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our feasibility study. We agree that several aspects of the experimental reporting require expansion to allow better evaluation of the preliminary results, and we will revise the manuscript accordingly while preserving its framing as an initial exploration rather than a definitive validation.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the proxy-labeled dataset used for the probe AUROC 0.840 is described only as 'small'; no size, proxy-label generation procedure, inter-rater reliability, or label-noise controls are provided, which is load-bearing for interpreting the cross-validated result as evidence of genuine detection rather than overfitting to chosen proxies.
Authors: We accept this criticism. The revised manuscript will specify the exact size of the proxy-labeled dataset, describe the proxy-label generation procedure in detail (including how repetition and coherence metrics were used to create labels), and explicitly note the absence of inter-rater reliability assessment and label-noise controls as limitations of the current feasibility study. We will also clarify that the reported AUROC is exploratory and cross-validated only on this small set. revision: yes
-
Referee: [Results] Results on LLM-based Companion: the 52-62% repetition reduction and 11% overhead are reported from a three-batch feasibility study without stating per-batch trial counts, variance, statistical tests, or full baseline comparisons (e.g., hard step limits), making it impossible to assess whether the effect is robust or task-specific noise.
Authors: We agree that the current reporting lacks necessary detail for assessing robustness. In revision we will add the per-batch trial counts, observed variance across batches, and explicit comparisons against a hard step-limit baseline. Because the work was designed as a feasibility study, no formal statistical tests were performed; we will state this limitation clearly and present the 52-62% range as an observed improvement rather than a statistically validated effect size. revision: yes
-
Referee: [Exploratory small-model analysis] Small-model analysis and task-type dependence: the claims of no benefit on 1B-1.5B models and neutral/negative effects on structured tasks rest on the same limited three-batch design; without quantified effect sizes per task category or controls for intervention side-effects, these boundary conditions cannot be separated from the specific models and tasks tested.
Authors: This observation is fair. The revision will include available effect-size breakdowns by task category (loop-prone versus structured) drawn from the three batches and will discuss possible intervention side-effects. We will also strengthen the language to emphasize that these patterns are preliminary observations from the limited design and should be treated as design constraints for future selective-activation work rather than general claims. revision: partial
Circularity Check
No circularity: purely empirical feasibility study with no derivations
full rationale
The paper reports experimental results from a three-batch study on Gemma 4 E4B and smaller models, including repetition reductions and probe AUROC values, without any equations, derivations, fitted parameters presented as predictions, or self-referential constructions. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked to justify central claims; all findings are framed as direct observations from specific tasks and proxy labels, with explicit caveats on generalization and task dependence. This structure keeps the work self-contained as an empirical architecture proposal rather than a closed logical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semantic Looping in Small Language Models: Characterization and Mitigation
Pipis, E., Chen, L., and Wang, M. Semantic Looping in Small Language Models: Characterization and Mitigation. arXiv preprint arXiv:2501.xxxxx, 2025
2025
-
[2]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y ., et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.arXiv preprint arXiv:2306.05685, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
The Curious Case of Neural Text Degeneration
Holtzman, A., Buys, J., Du, L., Forbes, M., and Choi, Y . The Curious Case of Neural Text Degeneration. In International Conference on Learning Representations, 2020
2020
-
[4]
and Bengio, Y
Alain, G. and Bengio, Y . Understanding intermediate layers using linear classifier probes. InInternational Conference on Learning Representations Workshop, 2017
2017
-
[5]
Discovering Latent Knowledge in Language Models Without Supervision
Burns, C., Ye, H., Klein, D., and Steinhardt, J. Discovering Latent Knowledge in Language Models Without Supervision. InInternational Conference on Learning Representations, 2023
2023
-
[6]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , shorttitle =
Li, K., Hopkins, A. K., Bau, D., Viégas, F., Pfister, H., and Wattenberg, M. Inference-Time Intervention: Eliciting Truthful Answers from a Language Model.arXiv preprint arXiv:2306.03341, 2023
-
[7]
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Kuhn, L., Gal, Y ., and Farquhar, S. Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation. InInternational Conference on Learning Representations, 2023
2023
-
[8]
INSPECTOR: A Framework for Semantic Capacity Assessment in Language Models.arXiv preprint arXiv:2601.xxxxx, 2026
Chen, R., Liu, S., and Zhang, H. INSPECTOR: A Framework for Semantic Capacity Assessment in Language Models.arXiv preprint arXiv:2601.xxxxx, 2026
2026
-
[9]
LangGraph: Multi-Agent Workflows.https://python.langchain.com/docs/langgraph, 2024
LangChain Team. LangGraph: Multi-Agent Workflows.https://python.langchain.com/docs/langgraph, 2024
2024
-
[10]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Wu, Q., Bansal, G., Zhang, J., et al. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversa- tion.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
OpenDevin: An Open Platform for AI Software Developers
OpenDevin Team. OpenDevin: An Open Platform for AI Software Developers. https://github.com/ OpenDevin/OpenDevin, 2024
2024
-
[12]
SpecRA: Spectral Repetition Analysis for Real-time Loop Detection.arXiv preprint arXiv:2501.xxxxx, 2025
Johnson, A., Lee, B., and Kim, C. SpecRA: Spectral Repetition Analysis for Real-time Loop Detection.arXiv preprint arXiv:2501.xxxxx, 2025. 19 The Cognitive CompanionA PREPRINT
2025
-
[13]
ERGO: Entropy-based Real-time Generation Oversight.arXiv preprint arXiv:2501.xxxxx, 2025
Smith, D., Brown, E., and Wilson, F. ERGO: Entropy-based Real-time Generation Oversight.arXiv preprint arXiv:2501.xxxxx, 2025
2025
-
[14]
S., Hou, L., et al
Huang, J., Gu, S. S., Hou, L., et al. Large Language Models Cannot Self-Correct Reasoning Yet. InInternational Conference on Learning Representations, 2024
2024
-
[15]
STaSC: Self-Training for Self-Correction in Small Language Models
Garcia, M., Patel, N., and Rodriguez, O. STaSC: Self-Training for Self-Correction in Small Language Models. arXiv preprint arXiv:2501.xxxxx, 2025. 20
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.