DRG-Font: Dynamic Reference-Guided Few-shot Font Generation via Contrastive Style-Content Disentanglement
Pith reviewed 2026-05-10 13:10 UTC · model grok-4.3
The pith
DRG-Font disentangles style from content with contrastive learning and dynamic reference selection to generate consistent glyphs from few examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
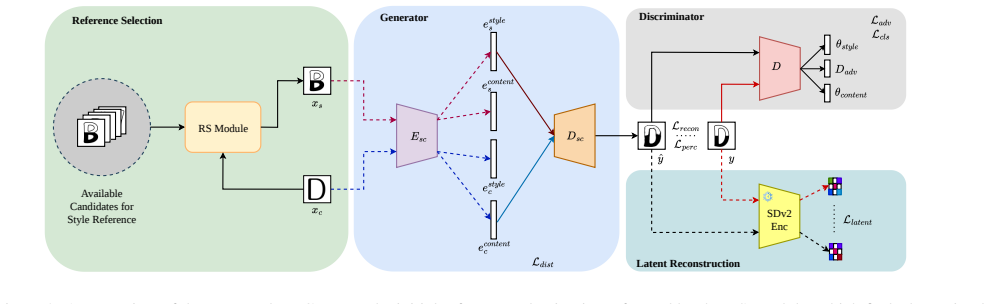
The central claim is that a contrastive font-generation network can learn to decompose glyph attributes into style and shape priors by combining a Reference Selection Module that chooses the best style exemplar, Multi-scale Style and Content Head Blocks that extract the priors, and a Multi-Fusion Upsampling Block that recombines them; when trained this way the model produces target glyphs that preserve both global style consistency and local character traits from only a few reference samples, outperforming earlier approaches on visual and quantitative tests.
What carries the argument
The Reference Selection (RS) Module that dynamically chooses the strongest style reference, paired with Multi-scale Style Head Block (MSHB) and Multi-scale Content Head Block (MCHB) that perform the contrastive style-content split, and Multi-Fusion Upsampling Block (MFUB) that merges the priors into the final glyph.
If this is right
- Generated samples retain more local glyph characteristics than earlier few-shot methods.
- The architecture works across multiple visual and analytical benchmarks without post-processing.
- Dynamic selection of the best style reference improves supervision quality.
- Multi-scale processing of style and content priors supports complex font styles from limited exemplars.
- No manual tuning per font is required for the reported performance gains.
Where Pith is reading between the lines
- The same contrastive split could be tested on few-shot generation of logos or icons where local detail preservation matters.
- The reference-selection idea might transfer to other conditional image-synthesis tasks that rely on a pool of style images.
- Extending the multi-scale heads to handle variable numbers of references could broaden applicability to even smaller shot counts.
- Quantitative glyph-feature metrics used here could serve as a diagnostic for other style-transfer pipelines.
Load-bearing premise
The contrastive decomposition together with the reference selection and multi-scale blocks can separate style from content while keeping local glyph features without needing dataset-specific adjustments.
What would settle it
Side-by-side visual inspection or quantitative metrics showing that generated glyphs lose distinctive local traits such as serifs, stroke thickness variations, or curve shapes relative to the chosen references would indicate the disentanglement has failed.
Figures






read the original abstract
Few-shot Font Generation aims to generate stylistically consistent glyphs from a few reference glyphs. However, capturing complex font styles from a few exemplars remains challenging, and the existing methods often struggle to retain discernible local characteristics in generated samples. This paper introduces DRG-Font, a contrastive font generation strategy that learns complex glyph attributes by decomposing style and content embedding spaces. For optimal style supervision, the proposed architecture incorporates a Reference Selection (RS) Module to dynamically select the best style reference from an available pool of candidates. The network learns to decompose glyph attributes into style and shape priors through a Multi-scale Style Head Block (MSHB) and a Multi-scale Content Head Block (MCHB). For style adaptation, a Multi-Fusion Upsampling Block (MFUB) produces the target glyph by combining the reference style prior and target content prior. The proposed method demonstrates significant improvements over state-of-the-art approaches across multiple visual and analytical benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRG-Font for few-shot font generation. It uses contrastive learning to decompose glyph attributes into separate style and content embedding spaces, incorporates a Reference Selection (RS) Module to dynamically choose optimal style references from a pool, employs Multi-scale Style Head Block (MSHB) and Multi-scale Content Head Block (MCHB) to learn the priors, and applies a Multi-Fusion Upsampling Block (MFUB) to synthesize the target glyph by fusing the selected style prior with the target content prior. The method is claimed to outperform state-of-the-art approaches on multiple visual and analytical benchmarks while better retaining local glyph characteristics.
Significance. If the contrastive decomposition and multi-scale blocks achieve the claimed independent factorization of style (font-wide traits) and content (character shape) without leakage, the work would advance few-shot font generation by addressing the common failure of prior methods to preserve fine local details from limited references. The dynamic RS Module adds practical adaptability that could extend to other reference-guided synthesis tasks in computer vision.
major comments (2)
- [Method] Method section (contrastive loss and MSHB/MCHB description): the central claim that the architecture successfully disentangles style and content priors rests on the contrastive loss plus multi-scale blocks, yet no post-training diagnostic (e.g., mutual-information estimate between embeddings, style-invariance test on content features, or leakage quantification) is reported to verify that factorization occurred rather than gains arising solely from the RS Module or MFUB fusion. This directly affects whether the reported benchmark improvements can be attributed to the proposed disentanglement.
- [Experiments] Experiments section: the abstract asserts 'significant improvements over state-of-the-art' across visual and analytical benchmarks, but without tabulated quantitative results, specific baselines, ablation studies isolating each component (RS, MSHB, MCHB, MFUB), or statistical significance tests, the load-bearing performance claim cannot be evaluated for robustness or reproducibility.
minor comments (1)
- The abstract and method overview use several acronyms (RS, MSHB, MCHB, MFUB) without an initial glossary or table; a short notation table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, providing the strongest honest defense of the manuscript while agreeing to strengthen the presentation where the concerns are valid.
read point-by-point responses
-
Referee: [Method] Method section (contrastive loss and MSHB/MCHB description): the central claim that the architecture successfully disentangles style and content priors rests on the contrastive loss plus multi-scale blocks, yet no post-training diagnostic (e.g., mutual-information estimate between embeddings, style-invariance test on content features, or leakage quantification) is reported to verify that factorization occurred rather than gains arising solely from the RS Module or MFUB fusion. This directly affects whether the reported benchmark improvements can be attributed to the proposed disentanglement.
Authors: The contrastive loss is explicitly formulated to push style embeddings to be invariant to content and content embeddings to be invariant to style, with the MSHB and MCHB designed to extract multi-scale priors that support this separation. However, we agree that explicit post-training verification would make the attribution clearer. In the revised manuscript we will add mutual-information estimates between the learned style and content embeddings (showing near-zero MI) and style-invariance tests on content features (measuring consistency of content embeddings across different style references). These diagnostics will directly address whether the observed gains stem from successful factorization rather than the RS or MFUB modules alone. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'significant improvements over state-of-the-art' across visual and analytical benchmarks, but without tabulated quantitative results, specific baselines, ablation studies isolating each component (RS, MSHB, MCHB, MFUB), or statistical significance tests, the load-bearing performance claim cannot be evaluated for robustness or reproducibility.
Authors: The manuscript reports both visual comparisons and analytical metrics (e.g., FID, LPIPS, and glyph-specific metrics) against multiple recent few-shot font generation baselines. We acknowledge that the presentation can be made more transparent. In the revision we will expand the experiments section with complete numerical tables listing exact scores for each baseline, add ablation tables that isolate the contribution of the RS Module, MSHB, MCHB, and MFUB, and include statistical significance tests (paired t-tests with p-values) on the key metrics. These additions will allow readers to assess robustness and reproducibility directly. revision: yes
Circularity Check
No circularity; empirical architecture with external benchmarks
full rationale
The paper describes a standard neural architecture (RS Module, MSHB, MCHB, MFUB) trained with contrastive losses on font data and evaluated on independent visual/analytical benchmarks against prior SOTA methods. No derivation reduces to self-definition, fitted parameters renamed as predictions, or load-bearing self-citations. The central claims rest on empirical gains rather than any closed loop in equations or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multi-content gan for few-shot font style transfer
Samaneh Azadi, Matthew Fisher, Vladimir G Kim, Zhaowen Wang, Eli Shechtman, and Trevor Darrell. Multi-content gan for few-shot font style transfer. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7564–7573, 2018. 2
work page 2018
-
[2]
Nilanjana Bhattacharya, Partha Pratim Roy, and Umapada Pal. Sub-stroke-wise relative feature for online indic handwriting recognition.ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 18(2):1–16, 2018. 4
work page 2018
-
[3]
Learning a manifold of fonts.ACM Transactions on Graphics (ToG), 33(4):1–11,
Neill DF Campbell and Jan Kautz. Learning a manifold of fonts.ACM Transactions on Graphics (ToG), 33(4):1–11,
-
[4]
Da-font: Few-shot font generation via dual-attention hybrid integration
Weiran Chen, Guiqian Zhu, Ying Li, Yi Ji, and Chunping Liu. Da-font: Few-shot font generation via dual-attention hybrid integration. InProceedings of the 33rd ACM International Conference on Multimedia, pages 6644–6653,
-
[5]
Stargan: Unified generative adversarial networks for multi-domain image-to- image translation
Yunjey Choi, Minje Choi, Munyoung Kim, Jung-Woo Ha, Sunghun Kim, and Jaegul Choo. Stargan: Unified generative adversarial networks for multi-domain image-to- image translation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8789–8797,
-
[6]
Xception: Deep learning with depthwise separable convolutions, 2017
Franc ¸ois Chollet. Xception: Deep learning with depthwise separable convolutions, 2017. 5
work page 2017
-
[7]
Histograms of oriented gradients for human detection
Navneet Dalal and Bill Triggs. Histograms of oriented gradients for human detection. In2005 IEEE computer society conference on computer vision and pattern recogni- tion (CVPR’05), pages 886–893. Ieee, 2005. 4
work page 2005
-
[8]
Faster: A font-agnostic scene text editing and rendering framework
Alloy Das, Sanket Biswas, Prasun Roy, Subhankar Ghosh, Umapada Pal, Michael Blumenstein, Josep Llad ´os, and Saumik Bhattacharya. Faster: A font-agnostic scene text editing and rendering framework. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1944–1954. IEEE, 2025. 8
work page 1944
-
[9]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014. 1, 2
work page 2014
-
[10]
Robust learning with the hilbert-schmidt independence criterion
Daniel Greenfeld and Uri Shalit. Robust learning with the hilbert-schmidt independence criterion. InInternational Conference on Machine Learning, pages 3759–3768. PMLR,
-
[11]
Haibin He, Xinyuan Chen, Chaoyue Wang, Juhua Liu, Bo Du, Dacheng Tao, and Qiao Yu. Diff-font: Diffusion model for robust one-shot font generation.International Journal of Computer Vision, 132(11):5372–5386, 2024. 3
work page 2024
-
[12]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1
work page 2020
-
[13]
Arbitrary style transfer in real-time with adaptive instance normalization
Xun Huang and Serge Belongie. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE international conference on computer vision, pages 1501–1510, 2017. 2, 5
work page 2017
-
[14]
Image-to-image translation with conditional adver- sarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adver- sarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134,
-
[15]
Perceptual losses for real-time style transfer and super-resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In European conference on computer vision, pages 694–711. Springer, 2016. 5
work page 2016
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Bbdm: Image- to-image translation with brownian bridge diffusion models
Bo Li, Kaitao Xue, Bin Liu, and Yu-Kun Lai. Bbdm: Image- to-image translation with brownian bridge diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1952–1961, 2023. 2
work page 1952
-
[18]
Few-shot font style transfer between different languages
Chenhao Li, Yuta Taniguchi, Min Lu, and Shin’ichi Konomi. Few-shot font style transfer between different languages. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 433–442, 2021. 7
work page 2021
-
[19]
Few-shot unsupervised image-to-image translation
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, and Jan Kautz. Few-shot unsupervised image-to-image translation. InProceedings of the IEEE/CVF international conference on computer vision, pages 10551–10560, 2019. 1, 2
work page 2019
-
[20]
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vision, 60(2):91–110, 2004. 4
work page 2004
-
[21]
Sabri A Mahmoud, Ibrahim AbuHaiba, and Roger J Green. Skeletonization of arabic characters using clustering based skeletonization algorithm (cbsa).Pattern Recognition, 24(5): 453–464, 1991. 4
work page 1991
-
[22]
Patch-font: Enhancing few-shot font gener- ation with patch-based attention and multitask encoding
Irfanullah Memon, Muhammad Ammar Ul Hassan, and Jaeyoung Choi. Patch-font: Enhancing few-shot font gener- ation with patch-based attention and multitask encoding. Applied Sciences, 15(3):1654, 2025. 3, 8
work page 2025
-
[23]
Conditional image synthesis with auxiliary classifier gans
Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional image synthesis with auxiliary classifier gans. In International conference on machine learning, pages 2642–
-
[24]
Multiple heads are better than one: Few- shot font generation with multiple localized experts
Song Park, Sanghyuk Chun, Junbum Cha, Bado Lee, and Hyunjung Shim. Multiple heads are better than one: Few- shot font generation with multiple localized experts. In Proceedings of the IEEE/CVF international conference on computer vision, pages 13900–13909, 2021. 1, 2
work page 2021
-
[25]
Zero-shot image-to- image translation
Gaurav Parmar, Krishna Kumar Singh, Richard Zhang, Yijun Li, Jingwan Lu, and Jun-Yan Zhu. Zero-shot image-to- image translation. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023. 2
work page 2023
-
[26]
Film: Visual reasoning 10 with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning 10 with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, 2018. 5
work page 2018
-
[27]
Flexyfont: Learning transferring rules for flexible typeface synthesis
Huy Quoc Phan, Hongbo Fu, and Antoni B Chan. Flexyfont: Learning transferring rules for flexible typeface synthesis. In Computer Graphics Forum, pages 245–256. Wiley Online Library, 2015. 2
work page 2015
-
[28]
Ma- font: Few-shot font generation by multi-adaptation method
Yanbo Qiu, Kaibin Chu, Ji Zhang, and Chengtao Feng. Ma- font: Few-shot font generation by multi-adaptation method. IEEE Access, 12:60765–60781, 2024. 2, 8
work page 2024
-
[29]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2
work page 2021
-
[30]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3, 6
work page 2022
-
[31]
Stefann: scene text editor using font adaptive neural network
Prasun Roy, Saumik Bhattacharya, Subhankar Ghosh, and Umapada Pal. Stefann: scene text editor using font adaptive neural network. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13228– 13237, 2020. 1, 2, 8
work page 2020
-
[32]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014. 6
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[33]
Learning to write stylized chinese characters by reading a handful of examples,
Danyang Sun, Tongzheng Ren, Chongxun Li, Hang Su, and Jun Zhu. Learning to write stylized chinese characters by reading a handful of examples.arXiv preprint arXiv:1712.06424, 2017. 3
-
[34]
Circle loss: A unified perspective of pair similarity optimization
Yifan Sun, Changmao Cheng, Yuhan Zhang, Chi Zhang, Liang Zheng, Zhongdao Wang, and Yichen Wei. Circle loss: A unified perspective of pair similarity optimization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6398–6407, 2020. 6
work page 2020
-
[35]
Few-shot font generation by learning fine-grained local styles
Licheng Tang, Yiyang Cai, Jiaming Liu, Zhibin Hong, Mingming Gong, Minhu Fan, Junyu Han, Jingtuo Liu, Errui Ding, and Jingdong Wang. Few-shot font generation by learning fine-grained local styles. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7895–7904, 2022. 2, 3
work page 2022
-
[36]
Plug-and-play diffusion features for text-driven image-to-image translation
Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1921–1930, 2023. 2
work page 1921
-
[37]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 7
work page 2004
-
[38]
Dg- font: Deformable generative networks for unsupervised font generation
Yangchen Xie, Xinyuan Chen, Li Sun, and Yue Lu. Dg- font: Deformable generative networks for unsupervised font generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5130–5140,
-
[39]
Clip-font: Sementic self-supervised few-shot font generation with clip
Jialu Xiong, Yefei Wang, and Jinshan Zeng. Clip-font: Sementic self-supervised few-shot font generation with clip. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 3620–3624. IEEE, 2024. 2
work page 2024
-
[40]
Chinese clip: Contrastive vision-language pretraining in chinese,
An Yang, Junshu Pan, Junyang Lin, Rui Men, Yichang Zhang, Jingren Zhou, and Chang Zhou. Chinese clip: Contrastive vision-language pretraining in chinese.arXiv preprint arXiv:2211.01335, 2022. 2
-
[41]
Awesome typography: Statistics-based text effects transfer
Shuai Yang, Jiaying Liu, Zhouhui Lian, and Zongming Guo. Awesome typography: Statistics-based text effects transfer. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7464–7473, 2017. 2
work page 2017
-
[42]
Zhenhua Yang, Dezhi Peng, Yuxin Kong, Yuyi Zhang, Cong Yao, and Lianwen Jin. Fontdiffuser: One-shot font generation via denoising diffusion with multi-scale content aggregation and style contrastive learning. InProceedings of the AAAI conference on artificial intelligence, pages 6603– 6611, 2024. 3
work page 2024
-
[43]
Vq-font: Few-shot font generation with structure-aware enhancement and quantization
Mingshuai Yao, Yabo Zhang, Xianhui Lin, Xiaoming Li, and Wangmeng Zuo. Vq-font: Few-shot font generation with structure-aware enhancement and quantization. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 16407–16415, 2024. 3
work page 2024
-
[44]
Dualgan: Unsupervised dual learning for image-to-image translation
Zili Yi, Hao Zhang, Ping Tan, and Minglun Gong. Dualgan: Unsupervised dual learning for image-to-image translation. InProceedings of the IEEE international conference on computer vision, pages 2849–2857, 2017. 2
work page 2017
-
[45]
Jinshan Zeng, Yan Zhang, Yiyang Yuan, Ling Tu, and Yefei Wang. Few-shot font generation via stroke prompt and hierarchical representation learning.Expert Systems with Applications, page 128656, 2025. 1, 2
work page 2025
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 7
work page 2018
-
[47]
Easy generation of personal chinese handwritten fonts
Baoyao Zhou, Weihong Wang, and Zhanghui Chen. Easy generation of personal chinese handwritten fonts. In2011 IEEE international conference on multimedia and expo, pages 1–6. IEEE, 2011. 2
work page 2011
-
[48]
Unpaired image-to-image translation using cycle- consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle- consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223– 2232, 2017. 2
work page 2017
-
[49]
Deformable convnets v2: More deformable, better results
Xizhou Zhu, Han Hu, Stephen Lin, and Jifeng Dai. Deformable convnets v2: More deformable, better results. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9308–9316, 2019. 2, 4 11
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.