Recognition: unknown
Robust Ultra Low-Bit Post-Training Quantization via Stable Diagonal Curvature Estimate
Pith reviewed 2026-05-10 14:11 UTC · model grok-4.3
The pith
DASH-Q quantizes large language models to 2-3 bits by replacing full Hessian matrices with stable diagonal curvature estimates and iterative weighted least squares.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
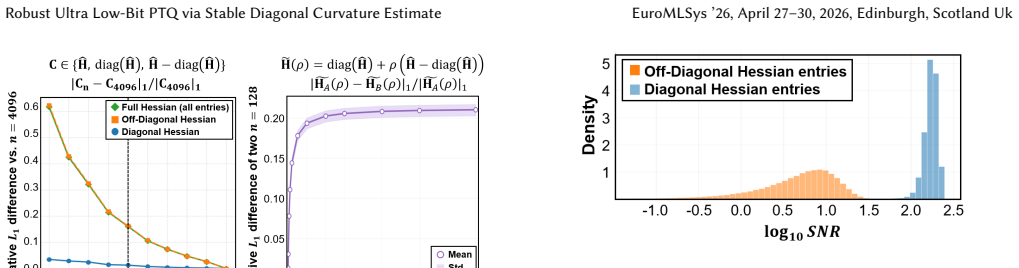
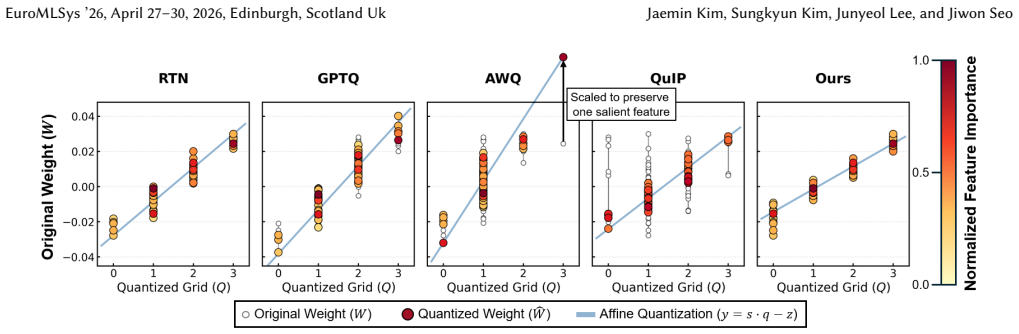
DASH-Q approximates the Hessian diagonally and applies iterative weighted least squares to compensate quantization error while preserving salient feature power. By discarding noise-prone off-diagonal dependencies, the method filters sampling noise from limited calibration data and outperforms existing PTQ baselines, raising average zero-shot accuracy by 7.01 percent and up to 14.01 percent over the strongest competitors across five LLM models.
What carries the argument
DASH-Q framework: diagonal Hessian approximation combined with iterative weighted least squares for error compensation.
If this is right
- LLMs become deployable at 2-3 bit precision with smaller memory footprint and less accuracy loss than prior PTQ methods.
- Quantization can succeed with far fewer calibration examples than full-Hessian approaches require.
- Robustness across model families increases because the method avoids unstable curvature estimates.
- Compensation remains effective even when off-diagonal channel dependencies cannot be reliably estimated.
Where Pith is reading between the lines
- The same diagonal-plus-iterative-least-squares pattern may apply to other low-precision compression tasks where full second-order information is expensive.
- Future work could test whether the observed stability holds for structured pruning or knowledge distillation that also rely on curvature.
- Hardware implementations could exploit the diagonal-only storage to reduce both memory and compute during the compensation step.
Load-bearing premise
Discarding off-diagonal Hessian terms and relying on iterative weighted least squares with a small calibration set will reliably preserve salient feature power without introducing new biases or instability at 2-3 bit widths.
What would settle it
Observe whether accuracy of a 2-bit quantized model drops below that of a full-Hessian baseline when the calibration set size is increased from a few hundred to several thousand samples.
Figures

read the original abstract
Large Language Models (LLMs) are widely used across many domains, but their scale makes deployment challenging. Post-Training Quantization (PTQ) reduces memory footprint without retraining by leveraging a small calibration set. Recent Hessian-based PTQ methods compensate quantization error via cross-channel dependencies, but such approaches degrade at low bit-widths due to noisy curvature estimates from limited calibration data. We propose DASH-Q, a robust PTQ framework using diagonal Hessian approximation and iterative weighted least squares. By discarding noise-prone dependencies, DASH-Q filters sampling noise while prioritizing the preservation of salient feature power. We outperform other PTQ baselines in ultra low-bit regime, improving zero-shot accuracy by 7.01% on average and up to 14.01% over the strongest baselines across five baseline LLM models, while showing robust and stable performance with very small calibration data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DASH-Q, a post-training quantization (PTQ) framework for large language models that employs a diagonal Hessian approximation combined with iterative weighted least squares on small calibration data. By discarding off-diagonal curvature terms to mitigate sampling noise, the method aims to preserve salient feature power more reliably than prior Hessian-based PTQ approaches in the ultra-low-bit regime. The authors report average zero-shot accuracy gains of 7.01% (up to 14.01% over the strongest baselines) across five LLM models while maintaining stable performance even with very limited calibration sets.
Significance. If the empirical gains prove robust under standard controls, DASH-Q would represent a practical advance in efficient LLM deployment by addressing the well-known instability of full Hessian estimates at 2-3 bit widths. The emphasis on a diagonal-only approximation plus weighted least-squares refinement offers a clear engineering trade-off that could influence subsequent quantization work, particularly for resource-constrained inference. The reported stability with minimal calibration data is a noteworthy practical strength.
minor comments (3)
- The abstract and experimental claims would benefit from explicit specification of the exact bit-widths (2-bit vs. 3-bit), calibration-set sizes, and the five baseline models to allow immediate contextualization of the 7.01% average gain.
- A brief pseudocode or expanded description of the iterative weighted least-squares procedure, including initialization and stopping criteria, would improve reproducibility of the diagonal-curvature estimation step.
- Consider adding error bars or statistical significance tests for the zero-shot accuracy improvements to substantiate the robustness claim against baseline variability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of DASH-Q and the recommendation for minor revision. The review accurately captures the core contribution of using a stable diagonal Hessian approximation combined with iterative weighted least squares to improve robustness in the ultra-low-bit regime.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents DASH-Q as applying a diagonal Hessian approximation combined with iterative weighted least squares on a small calibration set to stabilize curvature estimates for ultra-low-bit PTQ. This is a direct engineering choice that discards off-diagonal terms to reduce noise, without any quoted equation or step that defines a quantity in terms of itself, renames a fitted parameter as a prediction, or relies on a self-citation chain for the central claim. Performance gains are reported as empirical results on LLM models rather than derived tautologically from the inputs. The approach builds on standard Hessian-based PTQ ideas without reducing the claimed robustness to a self-referential construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Am- mar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jian- min Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capa- ble language model locally on your phone, 2024.URL https://arxiv. org/abs/2404.14219, 2(6):4, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Yamato Arai and Yuma Ichikawa. Quantization error propagation: Revisiting layer-wise post-training quantization.arXiv preprint arXiv:2504.09629, 2025
-
[3]
Quarot: Outlier-free 4-bit inference in rotated llms
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. Quarot: Outlier-free 4-bit inference in rotated llms. Advances in Neural Information Processing Systems, 37:100213–100240, 2024
2024
-
[4]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. InPro- ceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[5]
A stochastic quasi-newton method for large-scale optimization.SIAM Journal on Optimization, 26(2):1008–1031, 2016
Richard H Byrd, Samantha L Hansen, Jorge Nocedal, and Yoram Singer. A stochastic quasi-newton method for large-scale optimization.SIAM Journal on Optimization, 26(2):1008–1031, 2016
2016
-
[6]
Quip: 2-bit quantization of large language models with guarantees
Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36:4396–4429, 2023
2023
-
[7]
Everlyn Asiko Chimoto, Mostafa Elhoushi, and Bruce A Bassett. Cali- brating beyond english: Language diversity for better quantized multi- lingual llm.arXiv preprint arXiv:2601.18306, 2026
-
[8]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions.arXiv preprint arXiv:1905.10044, 2019
work page internal anchor Pith review arXiv 1905
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sab- harwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Deepseek- moe: Towards ultimate expert specialization in mixture-of-experts language models
Damai Dai, Chengqi Deng, Chenggang Zhao, RX Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Yu Wu, et al. Deepseek- moe: Towards ultimate expert specialization in mixture-of-experts language models. InProceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 1280–1297, 2024
2024
-
[11]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3. int8 (): 8-bit matrix multiplication for transformers at scale. Advances in neural information processing systems, 35:30318–30332, 2022
2022
-
[12]
Hawq: Hessian aware quantization of neural networks with mixed-precision
Zhen Dong, Zhewei Yao, Amir Gholami, Michael W Mahoney, and Kurt Keutzer. Hawq: Hessian aware quantization of neural networks with mixed-precision. InProceedings of the IEEE/CVF international conference on computer vision, pages 293–302, 2019
2019
-
[13]
Gemlite: Fast low-bit matmul kernels in triton, 2024
Dropbox AI. Gemlite: Fast low-bit matmul kernels in triton, 2024
2024
-
[14]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Ka- dian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[15]
arXiv preprint arXiv:2509.23202 , year=
Vage Egiazarian, Roberto L Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, et al. Bridging the gap between promise and performance for microscaling fp4 quantization.arXiv preprint arXiv:2509.23202, 2025
-
[16]
Michael Fleermann and Johannes Heiny. High-dimensional sam- ple covariance matrices with curie-weiss entries.arXiv preprint arXiv:1910.12332, 2019
-
[17]
Optimal brain compression: A frame- work for accurate post-training quantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
Elias Frantar and Dan Alistarh. Optimal brain compression: A frame- work for accurate post-training quantization and pruning.Advances in Neural Information Processing Systems, 35:4475–4488, 2022
2022
-
[18]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained trans- formers.arXiv preprint arXiv:2210.17323, 2022
work page internal anchor Pith review arXiv 2022
-
[19]
Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh
Elias Frantar, Roberto L Castro, Jiale Chen, Torsten Hoefler, and Dan Alistarh. Marlin: Mixed-precision auto-regressive parallel inference on large language models.arXiv preprint arXiv:2408.11743, 2024
-
[20]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
2024
-
[21]
Quantization and training of neural networks for efficient integer- arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer- arithmetic-only inference. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2704–2713, 2018
2018
-
[22]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Jaemin Kim, Hongjun Um, Sungkyun Kim, Yongjun Park, and Ji- won Seo. Flexiq: Adaptive mixed-precision quantization for la- tency/accuracy trade-offs in deep neural networks.arXiv preprint arXiv:2510.02822, 2025
-
[24]
Robust quantization of deep neural networks
Youngseok Kim, Junyeol Lee, Younghoon Kim, and Jiwon Seo. Robust quantization of deep neural networks. InProceedings of the 29th International Conference on Compiler Construction, pages 74–84, 2020
2020
-
[25]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[26]
A well-conditioned estimator for large-dimensional covariance matrices.Journal of multivariate analy- sis, 88(2):365–411, 2004
Olivier Ledoit and Michael Wolf. A well-conditioned estimator for large-dimensional covariance matrices.Journal of multivariate analy- sis, 88(2):365–411, 2004
2004
-
[27]
Owq: Outlier-aware weight quantization for efficient fine-tuning and inference of large language models
Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, and Eunhyeok Park. Owq: Outlier-aware weight quantization for efficient fine-tuning and inference of large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 13355–13364, 2024. Robust Ultra Low-Bit PTQ via Stable Diagonal Curvature Estimate EuroMLSys ’26, Ap...
2024
-
[28]
Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, and Yongin Kwon. Exploring the trade-offs: Quantization methods, task difficulty, and model size in large language models from edge to giant.arXiv preprint arXiv:2409.11055, 2024
-
[29]
Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei- Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. Awq: Activation-aware weight quantization for on-device llm compression and acceleration.Proceedings of machine learning and systems, 6:87–100, 2024
2024
-
[30]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764, 2024
-
[31]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review arXiv 2016
-
[32]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering.arXiv preprint arXiv:1809.02789, 2018
work page internal anchor Pith review arXiv 2018
-
[33]
Tensorrt-llm, 2023
NVIDIA Corporation. Tensorrt-llm, 2023
2023
-
[34]
Exegpt: Constraint-aware resource scheduling for llm inference
Hyungjun Oh, Kihong Kim, Jaemin Kim, Sungkyun Kim, Junyeol Lee, Du-seong Chang, and Jiwon Seo. Exegpt: Constraint-aware resource scheduling for llm inference. InProceedings of the 29th ACM Interna- tional Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, pages 369–384, 2024
2024
-
[35]
Out-of- order backprop: An effective scheduling technique for deep learning
Hyungjun Oh, Junyeol Lee, Hyeongju Kim, and Jiwon Seo. Out-of- order backprop: An effective scheduling technique for deep learning. InProceedings of the Seventeenth European Conference on Computer Systems, pages 435–452, 2022
2022
-
[36]
Zero: Memory optimizations toward training trillion parameter mod- els
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter mod- els. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[37]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021
2021
-
[38]
SocialIQA: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728, 2019
work page internal anchor Pith review arXiv 1904
-
[39]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi- billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[40]
On the variance of the fisher information for deep learning.Advances in Neural Information Processing Systems, 34:5708–5719, 2021
Alexander Soen and Ke Sun. On the variance of the fisher information for deep learning.Advances in Neural Information Processing Systems, 34:5708–5719, 2021
2021
-
[41]
Trade-offs of diagonal fisher information matrix estimators.Advances in Neural Information Processing Systems, 37:5870–5912, 2024
Alexander Soen and Ke Sun. Trade-offs of diagonal fisher information matrix estimators.Advances in Neural Information Processing Systems, 37:5870–5912, 2024
2024
-
[42]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Alma- hairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine- tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
On the impact of calibration data in post-training quantization and pruning
Miles Williams and Nikolaos Aletras. On the impact of calibration data in post-training quantization and pruning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10100–10118, 2024
2024
-
[44]
Smoothquant: Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning, pages 38087–38099. PMLR, 2023
2023
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Zhihang Yuan, Lin Niu, Jiawei Liu, Wenyu Liu, Xinggang Wang, Yuzhang Shang, Guangyu Sun, Qiang Wu, Jiaxiang Wu, and Bingzhe Wu. Rptq: Reorder-based post-training quantization for large language models.arXiv preprint arXiv:2304.01089, 2023
-
[47]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?arXiv preprint arXiv:1905.07830, 2019
work page internal anchor Pith review arXiv 1905
-
[48]
Hero-q: A general framework for stable low bit quantization via hessian conditioning.arXiv e-prints, pages arXiv–2601, 2026
Jinhao Zhang Yunquan Zhang, Boyang Zhang, Jun Sun, Daning Cheng, et al. Hero-q: A general framework for stable low bit quantization via hessian conditioning.arXiv e-prints, pages arXiv–2601, 2026
2026
-
[49]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. Atom: Low-bit quantization for efficient and accurate llm serving.Proceedings of Machine Learning and Systems, 6:196–209, 2024. A Derivation of𝑠 ∗ and𝑧 ∗ (Eq.(10),(11)) For a groupG, consider the weighted quadratic objecti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.