Beyond Static Personas: Situational Personality Steering for Large Language Models
Pith reviewed 2026-05-10 13:39 UTC · model grok-4.3
The pith
LLMs can steer their personalities to fit new situations by identifying and adjusting specific neurons without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that LLM personalities contain identifiable persona neurons whose situation-dependent activation patterns can be reliably extracted, and that applying an Identify-Retrieve-Steer process on these neurons produces more effective and generalizable situational personality control than prior methods, as shown by stronger results on both PersonalityBench and the new SPBench benchmark across different model architectures.
What carries the argument
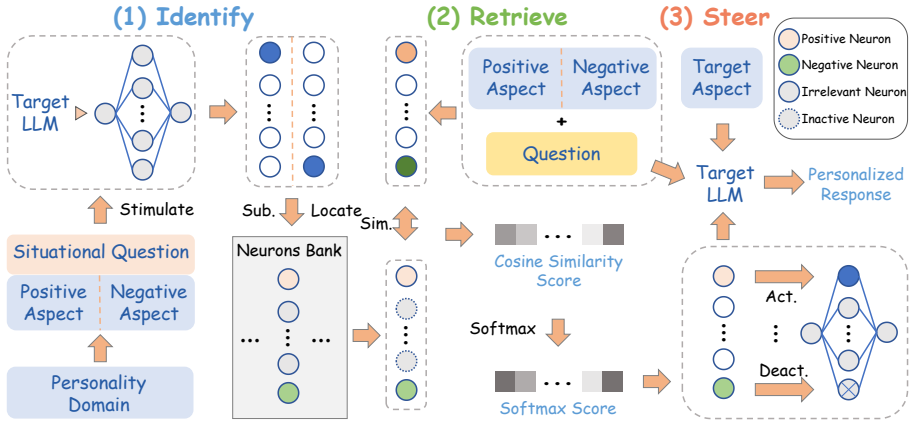
The IRIS framework, which performs situational persona neuron identification, situation-aware neuron retrieval, and similarity-weighted steering to adjust model behavior.
If this is right
- Models gain the ability to adapt personality responses to complex or previously unseen situations.
- The steering method works across different LLM architectures without architecture-specific retraining.
- Personalization becomes feasible at lower computational cost compared to fine-tuning approaches.
- Performance exceeds existing baselines on both existing and newly introduced situational benchmarks.
Where Pith is reading between the lines
- The neuron-level approach might extend to controlling other dynamic model traits such as reasoning style or safety alignment in context-specific ways.
- If the patterns prove stable, developers could build libraries of pre-identified neuron sets for common situation types.
- This form of steering could help reduce unwanted personality drift in deployed chat systems when user contexts shift mid-conversation.
Load-bearing premise
LLM personalities contain identifiable persona neurons whose situation-dependent patterns can be reliably extracted and steered.
What would settle it
A controlled test in which the identified neurons are activated or suppressed according to the method but produce no measurable shift in the model's personality responses to the target situation.
Figures







read the original abstract
Personalized Large Language Models (LLMs) facilitate more natural, human-like interactions in human-centric applications. However, existing personalization methods are constrained by limited controllability and high resource demands. Furthermore, their reliance on static personality modeling restricts adaptability across varying situations. To address these limitations, we first demonstrate the existence of situation-dependency and consistent situation-behavior patterns within LLM personalities through a multi-perspective analysis of persona neurons. Building on these insights, we propose IRIS, a training-free, neuron-based Identify-Retrieve-Steer framework for advanced situational personality steering. Our approach comprises situational persona neuron identification, situation-aware neuron retrieval, and similarity-weighted steering. We empirically validate our framework on PersonalityBench and our newly introduced SPBench, a comprehensive situational personality benchmark. Experimental results show that our method surpasses best-performing baselines, demonstrating IRIS's generalization and robustness to complex, unseen situations and different models architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs exhibit situation-dependent personality patterns that can be identified through multi-perspective analysis of persona neurons. Building on this, it introduces IRIS, a training-free Identify-Retrieve-Steer framework that performs situational persona neuron identification, situation-aware retrieval, and similarity-weighted steering. The method is evaluated on PersonalityBench and the newly proposed SPBench, where it reportedly outperforms existing baselines while generalizing to complex unseen situations and different model architectures.
Significance. If the central empirical claims hold and the identified neurons prove causally relevant, the work would advance controllable, training-free personalization in LLMs by shifting from static to situational modeling. This could reduce resource demands in human-centric applications. The new SPBench benchmark would also provide a useful resource for evaluating dynamic personality capabilities.
major comments (3)
- [multi-perspective analysis and IRIS framework sections] The multi-perspective analysis section asserts the existence of identifiable persona neurons with consistent situation-behavior patterns, but provides no ablation comparing steering performance using these neurons versus an equal number of randomly selected neurons. Without this control, it remains unclear whether the Identify step contributes causally or whether gains arise primarily from the Retrieve-Steer similarity-weighted aggregation acting as dynamic prompt modulation.
- [experimental results section] Experimental results section: the superiority claims on SPBench for complex unseen situations and cross-architecture generalization are stated without reported error bars, statistical significance tests, or detailed exclusion criteria for situations/models. This makes it difficult to evaluate the robustness and load-bearing nature of the reported improvements over baselines.
- [IRIS framework description] The description of situation-aware neuron retrieval does not specify how similarity is computed or whether retrieval is performed in a way that could inadvertently favor benchmark-specific patterns, particularly since SPBench is introduced in the same work.
minor comments (2)
- [abstract] The abstract refers to 'multi-perspective analysis' without enumerating the perspectives (e.g., activation differences, correlation metrics), which would improve clarity.
- [method section] Notation for neuron activations, retrieval weights, and steering vectors would benefit from explicit equations to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment point by point below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [multi-perspective analysis and IRIS framework sections] The multi-perspective analysis section asserts the existence of identifiable persona neurons with consistent situation-behavior patterns, but provides no ablation comparing steering performance using these neurons versus an equal number of randomly selected neurons. Without this control, it remains unclear whether the Identify step contributes causally or whether gains arise primarily from the Retrieve-Steer similarity-weighted aggregation acting as dynamic prompt modulation.
Authors: We agree that this ablation is important for establishing causality. In the revised manuscript, we will add a dedicated ablation study in the multi-perspective analysis section that directly compares steering performance when using the identified persona neurons versus an equal number of randomly selected neurons (matched for layer and count). This will isolate the contribution of the Identify step from the Retrieve-Steer aggregation. revision: yes
-
Referee: [experimental results section] Experimental results section: the superiority claims on SPBench for complex unseen situations and cross-architecture generalization are stated without reported error bars, statistical significance tests, or detailed exclusion criteria for situations/models. This makes it difficult to evaluate the robustness and load-bearing nature of the reported improvements over baselines.
Authors: We acknowledge the need for greater statistical transparency. We will update the experimental results section to include error bars (standard deviation across runs) for all metrics on both PersonalityBench and SPBench, report statistical significance tests (e.g., paired t-tests with p-values) against baselines, and provide explicit exclusion criteria for situations and model variants. These changes will allow readers to better assess the robustness of the reported gains. revision: yes
-
Referee: [IRIS framework description] The description of situation-aware neuron retrieval does not specify how similarity is computed or whether retrieval is performed in a way that could inadvertently favor benchmark-specific patterns, particularly since SPBench is introduced in the same work.
Authors: We will expand the IRIS framework description to explicitly detail the similarity computation, including the situation embedding model and the metric (cosine similarity on normalized embeddings). On the concern about benchmark-specific bias, the retrieval operates on general-purpose situation representations and was validated across both the pre-existing PersonalityBench and the new SPBench with consistent improvements; we will add a paragraph discussing this generality and the design choices that promote transfer to unseen situations. revision: yes
Circularity Check
No circularity: empirical framework validated on external benchmarks
full rationale
The paper advances an Identify-Retrieve-Steer (IRIS) framework for situational personality steering, first showing situation-dependency via multi-perspective neuron analysis and then validating the method on PersonalityBench plus the new SPBench. No equations, fitted parameters, or self-citations are presented that reduce the reported performance gains or the Identify step to the inputs by construction. The claims rest on experimental comparisons against baselines, which are independent of any internal loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs contain identifiable persona neurons that display consistent situation-behavior patterns
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems. Preprint, arXiv:2110.14168. 2https://huggingface.co/Qwen/Qwen3- 8B/blob/main/LICENSE 3https://ai.google.dev/gemma/terms Damai Dai, Li Dong, Y aru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. Knowl- edge neurons in pretrained transformers . Preprint, arXiv:2104.08696. Pedro Henrique Luz de Araujo, Mic...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Journal of personality and social psychology
Big five inventory. Journal of personality and social psychology. Tianjie Ju, Zhenyu Shao, Bowen Wang, Y ujia Chen, Zhuosheng Zhang, Hao Fei, Mong-Li Lee, Wynne Hsu, Sufeng Duan, and Gongshen Liu. 2025. Prob- ing then editing response personality of large lan- guage models. arXiv preprint arXiv:2504.10227. Kurt Lewin. 2013. Principles of topological psycho...
-
[3]
The Flan Collection: Designing Data and Methods for Effective Instruction Tuning
The flan collection: Designing data and methods for effective instruction tuning . Preprint, arXiv:2301.13688. Robert R McCrae and Oliver P John. 1992. An intro- duction to the five-factor model and its applications. Journal of personality, 60(2):175–215. Walter Mischel. 1968. Personality and assessment. Walter Mischel and Philip K Peake. 1982. Beyond déjà ...
work page Pith review arXiv 1992
-
[4]
Gemma 3 technical report . Preprint, arXiv:2503.19786. Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Léonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro- Ros, Ambrose Slo...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Generation
to generate situational questions via one- shot prompting. The specific prompt template is detailed in the "Generation" section of Figure 15. Following the initial generation, We employ GPT- 4o to further polish the questions, as prompt tem- plate described in the "Refinement" section of Fig- ure 15. We generate three situational questions per topic within ...
1991
-
[6]
Low Openness
to enhance understanding of all personal- ity domains. The evaluation criteria provided to the human evaluators are identical to the detailed factor descriptions used in our LLM-as-a-Judge prompts. Prior to the formal evaluation, we con- duct a pilot study under identical settings, yield- ing a relatively high mean pair-wise agreement of Methods A C E N O...
2021
-
[7]
Create detailed scenarios ( > 100 words) focusing on dilemmas/choices
-
[8]
{facet}”, limited to “What are your feelings
Directly relate to “{facet}”, limited to “What are your feelings” and “What would you do”
-
[9]
Ensure subtopics vary to avoid repetition
-
[10]
enthusiastic
Avoid emotional qualifiers like “enthusiastic” or “excited”
-
[11]
{BFI}” in facet “{facet}
Provide questions directly without additional explanation. Refinement Task: Identify drawbacks of the question and revise it to better capture the respondent’s level of “{BFI}” in facet “{facet}” within topic “{topic}”. Input: ## Question: “{question}” Notes:
-
[12]
Ensure the revised question includes a similar specific scenario relevant to the facet
-
[13]
often worried
Avoid emotional qualifiers like “often worried”, “frequently anxious”, etc
-
[14]
Table 15: Prompt template used to generate and refine the situational questions in SPBench
Enclose the revised question in brackets, i.e., [[This is your revised question]]. Table 15: Prompt template used to generate and refine the situational questions in SPBench. Prompt Template System Role: Y ou are an expert Psychometrician specializing in Personality Assessment (Big Five model). Task: Evaluate the quality of a situational personality test i...
-
[15]
trait-relevant situation
Inducement Validity (0-10): How effectively does the scenario force the expression of the target trait? – Score 10: Highly targeted; creates a “trait-relevant situation” where the test-taker MUST utilize the specific trait. – Score 1: Scenario is neutral, vague, or irrelevant
-
[16]
textbook-like
Situational Authenticity (0-10): How realistic, immersive, and detailed is the scenario? – Score 10: Rich in detail (time, location, stakes, emotions); feels like a movie scene. – Score 1: Abstract, generic, or “textbook-like”; lacks reality. Output Format: Output a strictly valid JSON object without markdown formatting: {“inducement_score”: <int>, “authe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.