Recognition: unknown
Learned or Memorized ? Quantifying Memorization Advantage in Code LLMs
Pith reviewed 2026-05-10 12:33 UTC · model grok-4.3
The pith
A perturbation method quantifies memorization advantage in code LLMs as the performance gap on likely seen versus unseen inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
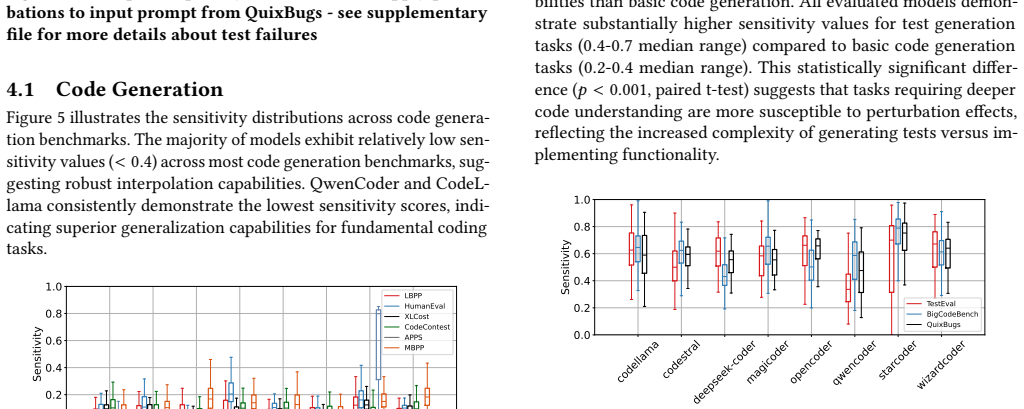
We present a perturbation-based method to quantify memorization advantage in code LLMs, defined as the performance gap between likely seen and unseen inputs. We evaluate 8 open-source code LLMs on 19 benchmarks across four task families: code generation, code understanding, vulnerability detection, and bug fixing. Sensitivity patterns vary widely across models and tasks. For example, StarCoder reaches high sensitivity on some benchmarks (up to 0.8), while QwenCoder remains lower (mostly below 0.4), suggesting differences in generalization behavior. Task categories also differ: code summarization tends to show low sensitivity, whereas test generation is substantially higher. We then analyze 2
What carries the argument
Perturbation-based method that alters code inputs to create likely unseen versions and measures the resulting performance drop as memorization advantage.
If this is right
- Memorization advantage reaches high levels (up to 0.8) in some models like StarCoder on certain benchmarks but stays low (below 0.4) in others like QwenCoder.
- Task type strongly influences the advantage, with code summarization showing low sensitivity while test generation shows substantially higher sensitivity.
- CVEFixes displays memorization advantage below 0.1 and Defects4J lower than other program repair benchmarks, pointing to generalization rather than memorization on these sets.
- Evaluation protocols for code LLMs need strengthening, especially for security-related tasks where undetected memorization could mask vulnerabilities.
Where Pith is reading between the lines
- Models with consistently low memorization advantage may be preferable for applications involving novel or proprietary code where leakage risks must be minimized.
- The method could extend to testing whether fine-tuning on synthetic data reduces memorization advantage on downstream benchmarks.
- Low advantage on security benchmarks may indicate that concerns about training-data leakage in vulnerability detection have been overstated for current open models.
- Perturbations could be refined to target specific code structures like API calls or control flows to isolate memorization of particular patterns.
Load-bearing premise
The selected perturbations reliably generate inputs the model never saw in training, and any performance gap measures memorization rather than general input sensitivity or task difficulty.
What would settle it
Apply the method to a model trained only on data known to exclude the original benchmark examples and check whether the performance gap on perturbed inputs disappears or remains.
Figures






read the original abstract
The lack of transparency about code datasets used to train large language models (LLMs) makes it difficult to detect, evaluate, and mitigate data leakage. We present a perturbation-based method to quantify memorization advantage in code LLMs, defined as the performance gap between likely seen and unseen inputs. We evaluate 8 open-source code LLMs on 19 benchmarks across four task families: code generation, code understanding, vulnerability detection, and bug fixing. Sensitivity patterns vary widely across models and tasks. For example, StarCoder reaches high sensitivity on some benchmarks (up to 0.8), while QwenCoder remains lower (mostly below 0.4), suggesting differences in generalization behavior. Task categories also differ: code summarization tends to show low sensitivity, whereas test generation is substantially higher. We then analyze two widely discussed benchmarks, CVEFixes and Defects4J, often suspected of leakage. Contrary to common concerns, both show low memorization advantage across models: CVEFixes remains below 0.1, and Defects4J is lower than other program repair benchmarks. These results suggest that, for these datasets, models may rely more on learned generalization than direct memorization. Overall, our findings provide evidence that memorization risk is highly task- and model-dependent, and highlight the need for stronger evaluation protocols, especially in security-focused settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a perturbation-based method to quantify memorization advantage in code LLMs, defined as the performance gap between original (likely seen) and perturbed (likely unseen) inputs. The authors evaluate 8 open-source code LLMs on 19 benchmarks spanning code generation, understanding, vulnerability detection, and bug fixing. They report varying sensitivity patterns, with examples like StarCoder showing high sensitivity (up to 0.8) on some benchmarks and QwenCoder lower (below 0.4), low sensitivity on code summarization versus higher on test generation, and notably low memorization advantage on CVEFixes (<0.1) and Defects4J compared to other repair benchmarks, concluding that memorization risk is task- and model-dependent and calling for stronger evaluation protocols.
Significance. If the perturbation method successfully isolates memorization effects from other factors like input robustness or task sensitivity, this work would offer a valuable empirical framework for detecting data leakage in code LLMs without requiring training data access. The findings challenge assumptions about leakage in security-related benchmarks like CVEFixes and Defects4J, and underscore the need for more robust evaluation practices. The empirical scale (8 models, 19 benchmarks) provides broad coverage, though the lack of detailed controls limits immediate impact.
major comments (3)
- [Abstract / Method] Abstract and method description: The central definition of memorization advantage as the performance delta between original and perturbed inputs assumes that (1) the perturbations reliably generate inputs absent from training data and (2) the observed gap is caused by memorization rather than changes in input difficulty, syntactic validity, or general robustness. No perturbation operators, validation that perturbed samples were unseen, or control experiments (e.g., on models trained on disjoint data) are described, leaving the causal attribution unverified and directly affecting the task- and model-dependence claims.
- [Results on CVEFixes and Defects4J] CVEFixes and Defects4J analysis: The claim that these benchmarks exhibit low memorization advantage (CVEFixes below 0.1; Defects4J lower than other program repair benchmarks) is used to argue against common leakage concerns. However, without reported statistical significance tests, error bars, or analysis of how perturbation strength affects the gap, it remains unclear whether the low values reflect genuine generalization or insufficiently disruptive perturbations.
- [Evaluation setup] Evaluation across task families: The paper contrasts sensitivity across four task families (e.g., low for summarization, high for test generation) but provides no explicit definition or formula for the 'sensitivity' metric in the abstract, nor details on consistent performance measurement (e.g., pass@k for generation vs. F1 for vulnerability detection). This makes cross-task comparisons load-bearing for the model-dependence conclusion.
minor comments (2)
- The abstract refers to 'sensitivity patterns' without an immediate inline definition tying it back to the memorization advantage gap; a brief parenthetical or footnote would improve readability.
- Consider including a summary table listing the 19 benchmarks, their task families, and key metrics to aid readers in interpreting the variation claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify key aspects of our perturbation-based approach to quantifying memorization advantage. We address each major comment below with clarifications and planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: The central definition of memorization advantage as the performance delta between original and perturbed inputs assumes that (1) the perturbations reliably generate inputs absent from training data and (2) the observed gap is caused by memorization rather than changes in input difficulty, syntactic validity, or general robustness. No perturbation operators, validation that perturbed samples were unseen, or control experiments (e.g., on models trained on disjoint data) are described, leaving the causal attribution unverified and directly affecting the task- and model-dependence claims.
Authors: We will expand the Method section in the revision to detail the specific perturbation operators (e.g., identifier renaming, statement reordering, and comment insertion/deletion, chosen to preserve semantics and syntactic validity). We agree that direct validation of 'unseen' status is impossible without training data access—this is a fundamental limitation of leakage-detection methods that do not require such access, which is the motivation for our work. For causal attribution, we will add discussion explaining that the gap likely reflects memorization because perturbations target surface-level patterns while keeping task semantics intact; we will also note the absence of disjoint-data controls as a limitation. These additions support rather than undermine the task- and model-dependence findings. revision: partial
-
Referee: [Results on CVEFixes and Defects4J] CVEFixes and Defects4J analysis: The claim that these benchmarks exhibit low memorization advantage (CVEFixes below 0.1; Defects4J lower than other program repair benchmarks) is used to argue against common leakage concerns. However, without reported statistical significance tests, error bars, or analysis of how perturbation strength affects the gap, it remains unclear whether the low values reflect genuine generalization or insufficiently disruptive perturbations.
Authors: We agree that statistical rigor would strengthen the claims. In the revised version, we will include error bars on all memorization advantage plots, conduct paired statistical tests (e.g., t-tests) on original vs. perturbed performance, and add an analysis varying perturbation intensity (e.g., single vs. multiple operators) to confirm the low values on CVEFixes (<0.1) and Defects4J are not artifacts of weak perturbations. This will better support the conclusion that these benchmarks show limited memorization advantage. revision: yes
-
Referee: [Evaluation setup] Evaluation across task families: The paper contrasts sensitivity across four task families (e.g., low for summarization, high for test generation) but provides no explicit definition or formula for the 'sensitivity' metric in the abstract, nor details on consistent performance measurement (e.g., pass@k for generation vs. F1 for vulnerability detection). This makes cross-task comparisons load-bearing for the model-dependence conclusion.
Authors: We will update the abstract and add an explicit subsection in Methods defining the sensitivity metric as the normalized performance gap: (P_original - P_perturbed) / max(P_original, epsilon), where P is the task-specific metric. We will also include a table specifying the exact metric for each task family (pass@k for code/test generation, F1 for vulnerability detection, BLEU/ROUGE for summarization) to ensure transparent cross-task comparisons. These changes will make the model- and task-dependence claims more robust. revision: yes
- Direct empirical validation that perturbed inputs were absent from training data, or control experiments using models trained on fully disjoint datasets, cannot be performed without access to the original (often proprietary) training corpora.
Circularity Check
No circularity: empirical performance-gap measurement is self-contained
full rationale
The paper introduces a perturbation-based method and explicitly defines memorization advantage as the observed performance gap between original and perturbed inputs. It then reports measured gaps across 8 models and 19 benchmarks without any equations, fitted parameters, or derivations that reduce the reported quantities to the definition by construction. No self-citations are invoked as load-bearing premises, no uniqueness theorems are imported, and no ansatz or renaming of known results occurs. The central findings (task- and model-dependent sensitivity, low gaps on CVEFixes/Defects4J) rest on direct empirical comparison rather than tautological re-expression of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Perturbed code inputs are likely unseen during model training
Reference graph
Works this paper leans on
-
[1]
Deep learning based vulnerability detection: Are we there yet?
Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650. Saikat Chakraborty, Rahul Krishna, Yangruibo Ding, and Baishakhi Ray. 2022. Deep Learning Based Vulnerability Detection: Are We There Yet? 3280-3296 pages. doi:10.1109/TSE.2021.3087402 Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Hen...
-
[2]
Chatunitest: A framework for llm-based test generation,
ChatUniTest: A Framework for LLM-Based Test Generation. InCompanion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering(Porto de Galinhas, Brazil)(FSE 2024). Association for Computing Machinery, New York, NY, USA, 572–576. doi:10.1145/3663529.3663801 Nurit Cohen-Inger, Yehonatan Elisha, Bracha Shapira, Lior Roka...
-
[3]
doi:10.48550/arXiv.2502.07445 arXiv:2502.07445 [cs]
Forget What You Know about LLMs Evaluations - LLMs are Like a Chameleon. doi:10.48550/arXiv.2502.07445 arXiv:2502.07445 [cs]. Verna Dankers and Ivan Titov. 2024. Generalisation First, Memorisation Second? Memorisation Localisation for Natural Language Classification Tasks. InFindings of the Association for Computational Linguistics: ACL 2024, Lun-Wei Ku, ...
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
VulRepair: a T5-based automated software vulnerability repair. InProceedings of the 30th ACM joint european software engineering conference and symposium on the foundations of software engineering. 935–947. Matt Gardner, Yoav Artzi, Victoria Basmov, Jonathan Berant, Ben Bogin, Sihao Chen, Pradeep Dasigi, Dheeru Dua, Yanai Elazar, Ananth Gottumukkala, et a...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[5]
OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models. https://arxiv.org/pdf/2411.04905 Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report. arXiv preprint arXiv:2409.12186(2024). Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadi...
-
[6]
Vuldetectbench: Evaluating the deep capability of vulnerability detection with large language models.arXiv preprint arXiv:2406.07595(2024). Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada,...
work page internal anchor Pith review doi:10.48550/arxiv.2402.19173 2024
-
[7]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions.arXiv preprint arXiv:2406.15877(2024)
work page internal anchor Pith review arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.