Recognition: unknown
Parameter Importance is Not Static: Evolving Parameter Isolation for Supervised Fine-Tuning
Pith reviewed 2026-05-10 13:56 UTC · model grok-4.3
The pith
Parameter importance drifts during supervised fine-tuning, so isolation masks must evolve dynamically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We empirically demonstrate that parameter importance exhibits temporal drift over the course of training. To address this, we propose Evolving Parameter Isolation (EPI), a fine-tuning framework that adapts isolation decisions based on online estimates of parameter importance. Instead of freezing a fixed subset of parameters, EPI periodically updates isolation masks using gradient-based signals, enabling the model to protect emerging task-critical parameters while releasing outdated ones to recover plasticity. Experiments on diverse multi-task benchmarks demonstrate that EPI consistently reduces interference and forgetting compared to static isolation and standard fine-tuning, while improving
What carries the argument
Evolving Parameter Isolation (EPI) that periodically recomputes and applies isolation masks from online gradient-based importance estimates.
If this is right
- EPI reduces task interference and catastrophic forgetting relative to both static isolation and ordinary fine-tuning.
- Overall generalization improves on diverse multi-task benchmarks.
- Isolation decisions must be synchronized with the evolving dynamics of learning multiple abilities.
Where Pith is reading between the lines
- Similar periodic mask updates could be tested in continual learning settings outside language-model fine-tuning.
- The added cost of recomputing masks at intervals may be offset by gains in retention and plasticity.
- The observed drift raises the question of what training signals cause parameter importance to shift in the first place.
Load-bearing premise
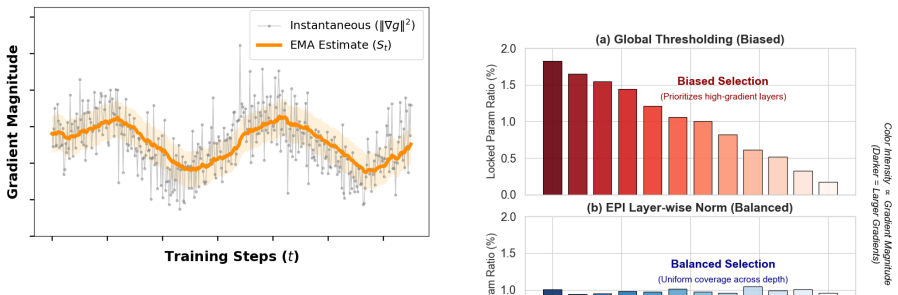
Online gradient-based estimates of parameter importance remain stable and informative enough to drive mask updates without introducing new training instabilities or requiring extensive extra tuning.
What would settle it
If a controlled multi-task SFT experiment shows that periodically updated masks produce equal or higher forgetting rates than fixed masks, the claim that evolving isolation is necessary would be falsified.
Figures



read the original abstract
Supervised Fine-Tuning (SFT) of large language models often suffers from task interference and catastrophic forgetting. Recent approaches alleviate this issue by isolating task-critical parameters during training. However, these methods represent a static solution to a dynamic problem, assuming that parameter importance remains fixed once identified. In this work, we empirically demonstrate that parameter importance exhibits temporal drift over the course of training. To address this, we propose Evolving Parameter Isolation (EPI), a fine-tuning framework that adapts isolation decisions based on online estimates of parameter importance. Instead of freezing a fixed subset of parameters, EPI periodically updates isolation masks using gradient-based signals, enabling the model to protect emerging task-critical parameters while releasing outdated ones to recover plasticity. Experiments on diverse multi-task benchmarks demonstrate that EPI consistently reduces interference and forgetting compared to static isolation and standard fine-tuning, while improving overall generalization. Our analysis highlights the necessity of synchronizing isolation mechanisms with the evolving dynamics of learning diverse abilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that parameter importance in supervised fine-tuning (SFT) of large language models is not static but exhibits temporal drift over the course of training. It proposes Evolving Parameter Isolation (EPI), a framework that periodically revises isolation masks using online gradient-based importance estimates to protect emerging task-critical parameters and release outdated ones, thereby reducing interference and catastrophic forgetting while improving generalization. Experiments on diverse multi-task benchmarks show EPI outperforming static isolation methods and standard fine-tuning.
Significance. If the empirical results hold after addressing controls, this work is significant for challenging the static assumption underlying recent parameter-isolation techniques in LLM fine-tuning. By demonstrating drift and providing an adaptive mechanism driven by observable gradients, it offers a practical way to maintain plasticity in multi-task SFT, which could inform more robust training strategies for models handling diverse abilities.
major comments (3)
- [§4] §4 (Method): The EPI update rule relies on periodic recomputation of gradient-based importance scores to revise masks, but no details are given on score smoothing, batch averaging, or handling of noise; without this, it is unclear whether mask flips remain stable or introduce optimization discontinuities.
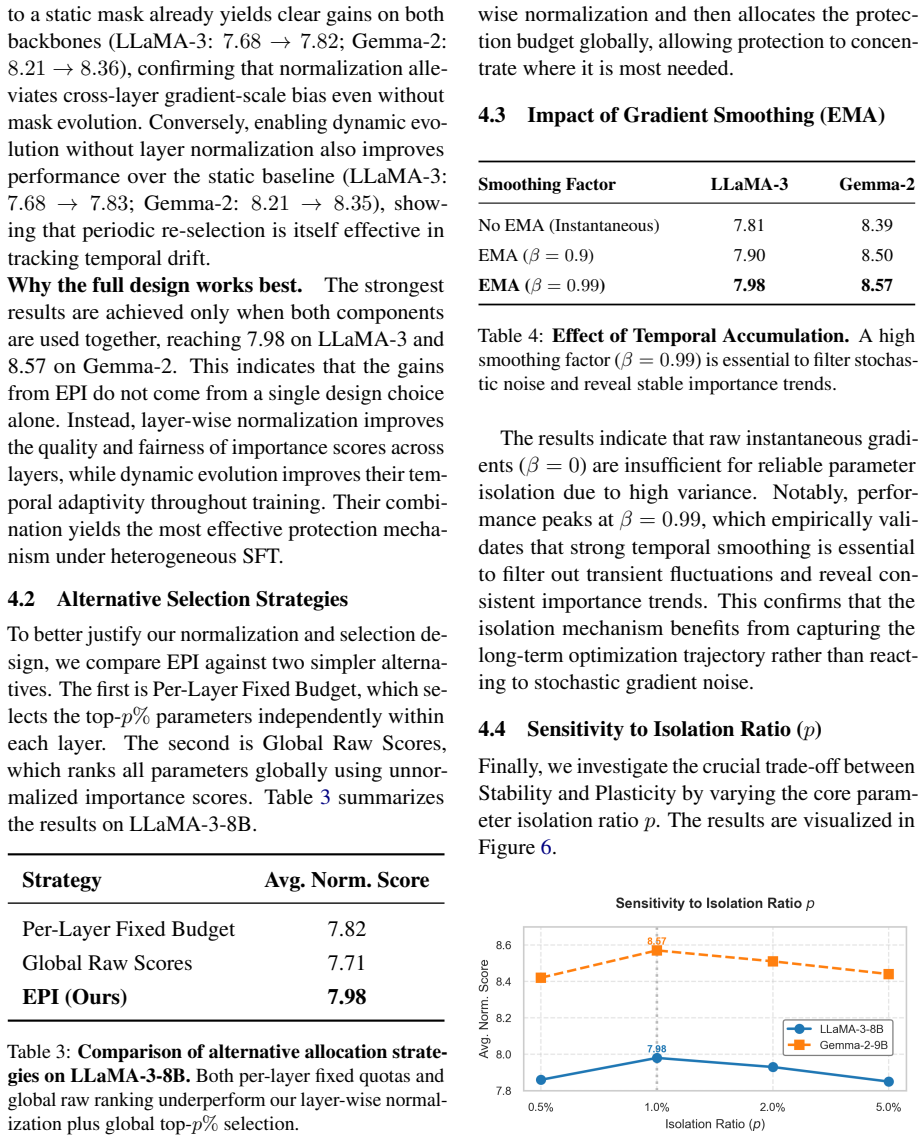
- [§5.2] §5.2 (Experiments): The reported gains over static isolation are presented without ablations on the two free parameters (mask update interval and importance threshold). This makes it impossible to determine whether performance improvements stem from addressing temporal drift or from additional hyperparameter search.
- [§5.3] §5.3 (Results): No loss curves, divergence metrics, or stability analysis are provided around mask-update steps; given known sensitivity of gradient importance to learning-rate schedules and batch noise, this leaves open the possibility that observed benefits are offset by new instabilities.
minor comments (2)
- The abstract and introduction could more explicitly list the concrete benchmarks and model sizes used, to allow immediate assessment of scope.
- [§4] Notation for the importance score computation in the method section would benefit from an explicit equation reference to avoid ambiguity with prior static-isolation work.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments, which help clarify several aspects of our presentation of Evolving Parameter Isolation (EPI). We address each major comment below and will revise the manuscript accordingly to improve technical clarity, experimental rigor, and analysis of training dynamics.
read point-by-point responses
-
Referee: [§4] §4 (Method): The EPI update rule relies on periodic recomputation of gradient-based importance scores to revise masks, but no details are given on score smoothing, batch averaging, or handling of noise; without this, it is unclear whether mask flips remain stable or introduce optimization discontinuities.
Authors: We agree that the method section would benefit from greater implementation detail. The original manuscript described the periodic update at a conceptual level but omitted specifics on score computation. In the revised version we will expand §4 with: (i) the precise importance-score formula, including averaging over a sliding window of mini-batches; (ii) the optional exponential-moving-average smoothing coefficient used to dampen gradient noise; and (iii) the mask-update procedure (threshold-based flipping with a small hysteresis margin) that prevents abrupt discontinuities. We will also add a short stability analysis showing that mask changes occur infrequently and produce negligible spikes in the loss surface under the reported hyper-parameters. revision: yes
-
Referee: [§5.2] §5.2 (Experiments): The reported gains over static isolation are presented without ablations on the two free parameters (mask update interval and importance threshold). This makes it impossible to determine whether performance improvements stem from addressing temporal drift or from additional hyperparameter search.
Authors: We acknowledge the absence of explicit ablations on mask-update interval and importance threshold. To isolate the contribution of temporal adaptation, we will run additional controlled experiments in the revision, sweeping both parameters over a grid of plausible values while keeping all other settings fixed. The resulting tables and figures will demonstrate that EPI retains its advantage over static baselines across a wide range of these hyper-parameters, thereby showing that the observed gains arise from the evolving mechanism rather than from extra tuning. revision: yes
-
Referee: [§5.3] §5.3 (Results): No loss curves, divergence metrics, or stability analysis are provided around mask-update steps; given known sensitivity of gradient importance to learning-rate schedules and batch noise, this leaves open the possibility that observed benefits are offset by new instabilities.
Authors: We agree that training dynamics around mask updates were not reported. In the revised manuscript we will add: (i) training and validation loss curves with vertical markers at each mask-update step; (ii) quantitative stability metrics (gradient-norm ratio and parameter-update magnitude) computed immediately before and after updates; and (iii) a short sensitivity study under varied learning-rate schedules. These additions will allow readers to verify that mask revisions do not introduce measurable instabilities and that the reported generalization improvements are not offset by optimization artifacts. revision: yes
Circularity Check
No circularity: empirical observation of drift and gradient-driven mask updates are independent of target outcomes
full rationale
The paper's core contribution is an empirical demonstration that parameter importance drifts during SFT, addressed by proposing EPI which periodically recomputes isolation masks from online gradient signals. No equation or claim reduces by construction to a fitted parameter or self-defined quantity that encodes the reported gains in generalization or reduced forgetting. Isolation decisions rest on observable gradients rather than quantities defined in terms of the final performance metrics. The method is self-contained against external benchmarks (static isolation, standard fine-tuning) with no load-bearing self-citation chains or ansatzes smuggled from prior author work. This is the normal case of an empirical proposal whose validity is tested rather than assumed.
Axiom & Free-Parameter Ledger
free parameters (2)
- mask update interval
- importance threshold
Reference graph
Works this paper leans on
-
[1]
In search of the real inductive bias: On the role of implicit regularization in deep learning
In search of the real inductive bias: On the role of implicit regularization in deep learning.arXiv preprint arXiv:1412.6614. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow in- structions with human feedbac...
-
[2]
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis
IEEE. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Language models are unsupervised multitask learn- ers.OpenAI blog, 1(8):9. Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. Codebleu: a method for automatic evaluation of...
work page internal anchor Pith review arXiv 2019
-
[3]
Question calibration and multi-hop modeling for temporal question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19332–19340. Chao Xue, Di Liang, Sirui Wang, Jing Zhang, and Wei Wu. 2023. Dual path modeling for semantic match- ing by perceiving subtle conflicts. InICASSP 2023- 2023 IEEE International Conferenc...
work page internal anchor Pith review arXiv 2023
-
[4]
seesaw phe- nomenon
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Rui Zheng, Bao Rong, Yuhao Zhou, Di Liang, Sirui Wang, Wei Wu, Tao Gui, Qi Zhang, and Xuan-Jing Huang. 2022. Robust lottery tickets for pre-trained language models. InProceedings of the 60th Annual Meeting of the Association for Comp...
2022
-
[5]
Complementarily, gradient-based meth- ods constrain update directions
introduce historical data into current train- ing stages. Complementarily, gradient-based meth- ods constrain update directions. Regularization techniques such as Elastic Weight Consolidation (EWC) (Kirkpatrick et al., 2017; Li and Hoiem,
2017
-
[6]
penalize changes to important weights, while projection-based gradient constraints (or gradient surgery) such as GEM (López-Paz and Ranzato,
-
[7]
Separately, gradient nor- malization methods such as GradNorm (Chen et al.,
and PCGrad (Yu et al., 2020) modify gradi- ents to reduce conflicts. Separately, gradient nor- malization methods such as GradNorm (Chen et al.,
2020
-
[8]
seesaw effect
adaptively reweight tasks by matching gradi- ent magnitudes. However, finding a single update direction for conflicting objectives remains geo- metrically infeasible, failing to resolve destructive interference. Architectural Modularization.To avoid con- tention in shared spaces, a distinct paradigm physi- cally decouples task representations by expanding...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.