Recognition: unknown
Demanding peer review is associated with higher impact in published science
Pith reviewed 2026-05-10 11:40 UTC · model grok-4.3
The pith
Stronger peer-review criticism, higher-quality comments, and greater revision demands are associated with higher citation impact for accepted papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
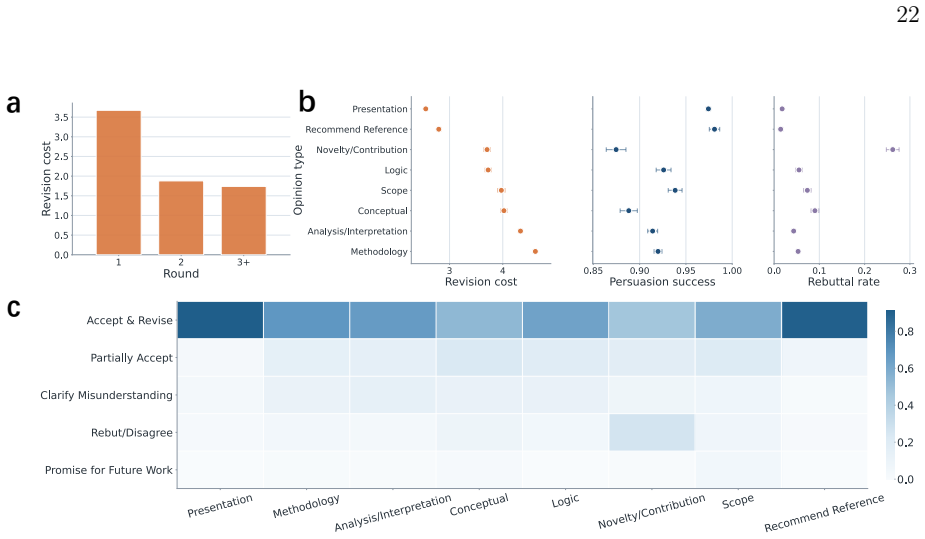
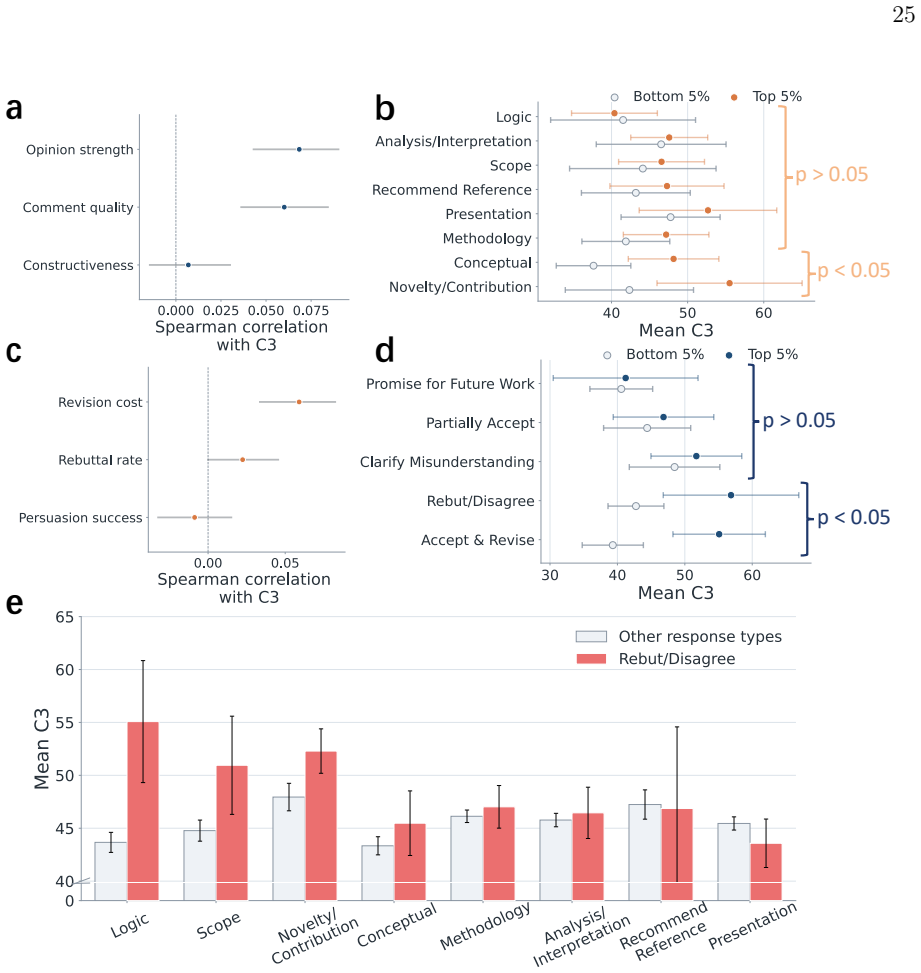
Within the set of accepted papers, higher average reviewer opinion strength, higher-quality reviewer comments, and greater revision burden are positively associated with later citation counts. Review pressure is front-loaded and focused on central claims, while reviewer disagreement rises with stronger opinions. These patterns hold after accounting for broad team characteristics and vary more by field in style than in total length.
What carries the argument
A fixed-prompt large language model pipeline that extracts and quantifies structured metrics of opinion strength, revision burden, comment quality, and reviewer-author agreement from raw peer-review correspondence.
If this is right
- Demanding peer review may help refine claims that later prove more influential.
- Citation impact can be predicted in part from observable features of the review process itself.
- Open peer-review records contain usable signals about how scientific contributions are strengthened before publication.
- Disciplinary differences appear mainly in the style of criticism rather than its volume.
Where Pith is reading between the lines
- Journals could use early review-intensity metrics as one input when deciding which accepted papers to promote or feature.
- The finding raises the possibility that some papers receive lighter review precisely because they are less central or less contestable.
- Extending the same LLM structuring to other journals would test whether the association between demanding review and impact is general or specific to Nature Communications.
Load-bearing premise
The LLM pipeline produces accurate, unbiased numerical scores for opinion strength, revision burden, and comment quality that do not systematically correlate with eventual citation impact.
What would settle it
Human re-coding of a sample of the same review letters yields opinion-strength and revision-burden scores that show zero or negative correlation with the citation counts of the published papers.
Figures








read the original abstract
Peer review shapes which scientific claims enter the published record, but its internal dynamics are hard to measure at scale because reviewer criticism and author revision are usually embedded in long, unstructured correspondence. Here we use a fixed-prompt large language model pipeline to convert the review correspondence of \textit{Nature Communications} papers published from 2017 to 2024 into structured reviewer--author interactions. We find that review pressure is concentrated in the first round and focused disproportionately on core claims rather than peripheral presentation. Higher average opinion strength is also associated with more reviewer disagreement, while review patterns vary little with broad team attributes, consistent with relatively impartial evaluation. Contrary to the intuition that stronger papers should pass review more smoothly, with greater reviewer--author agreement and less extensive revision, we find that stronger criticism, higher-quality comments, and greater revision burden are associated with higher later citation impact within accepted papers. We finally show that fields differ more in review style than in review length, pointing to disciplinary variation in how criticism is negotiated and resolved. These findings position open peer review not just as a gatekeeping mechanism but as a measurable record of how influential scientific claims are challenged, defended, and revised before entering the published record.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript uses a fixed-prompt LLM pipeline to convert unstructured reviewer-author correspondence from Nature Communications papers (2017-2024) into structured measures of opinion strength, disagreement, comment quality, and revision burden. It reports that review pressure concentrates in the first round and on core claims, varies little with team attributes, and that stronger criticism, higher-quality comments, and greater revision burden are positively associated with later citation impact among accepted papers. Field differences in review style exceed those in review length.
Significance. If the LLM measures prove valid and the associations survive controls for confounders, the work offers large-scale observational evidence that more demanding peer review correlates with higher-impact outcomes, challenging the intuition that strong papers experience smoother review. It demonstrates the value of open peer review data for quantifying how claims are challenged and revised, with the scale and use of external citation metrics as notable strengths.
major comments (3)
- [Abstract / Methods (LLM pipeline)] The central regression results depend entirely on LLM-derived variables for opinion strength, revision burden, and comment quality (Abstract; Methods section describing the fixed-prompt pipeline). No human validation (e.g., inter-annotator agreement, correlation with expert ratings) or checks for systematic bias correlated with citation impact are reported. High-impact papers often feature denser technical language, which could inflate LLM scores independently of actual reviewer behavior.
- [Results (citation associations)] The reported positive associations between review intensity measures and citation counts (Results section) do not include controls for initial paper quality, author reputation, field-specific citation norms, or topic hotness. Without these, the associations may reflect pre-existing differences rather than effects of review demands.
- [Methods / Sample description] The sample is restricted to accepted papers only. This selection truncates the distribution and prevents assessment of whether intense review leads to rejection of potentially high-impact work, weakening the interpretation that demanding review produces higher impact.
minor comments (2)
- [Methods] Provide the exact LLM prompts, variable operationalizations, and any robustness checks in the main text or supplementary materials to support reproducibility.
- [Results] Clarify the statistical models (e.g., regression specifications, fixed effects) used for the key associations and report effect sizes alongside significance.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We address each major comment point by point below, providing clarifications on our approach and indicating revisions planned for the next version. Our responses focus on strengthening the validity and interpretation of the findings without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract / Methods (LLM pipeline)] The central regression results depend entirely on LLM-derived variables for opinion strength, revision burden, and comment quality (Abstract; Methods section describing the fixed-prompt pipeline). No human validation (e.g., inter-annotator agreement, correlation with expert ratings) or checks for systematic bias correlated with citation impact are reported. High-impact papers often feature denser technical language, which could inflate LLM scores independently of actual reviewer behavior.
Authors: We agree that explicit validation of the LLM pipeline is a necessary addition for establishing measure reliability. The manuscript emphasizes the fixed-prompt design for reproducibility and consistency across the large corpus, but does not report human validation or targeted bias diagnostics. In the revised version, we will add a dedicated Methods subsection reporting a human validation study: two independent annotators will code a stratified random sample of 150 review documents for opinion strength, disagreement, comment quality, and revision burden, with inter-annotator agreement (Cohen's kappa) and correlation with LLM outputs presented. We will also add robustness checks regressing LLM scores on paper-level technicality proxies (e.g., average sentence length, technical term density via domain lexicons) and include these as covariates or stratification variables in the main regressions to test for systematic inflation in high-impact papers. revision: yes
-
Referee: [Results (citation associations)] The reported positive associations between review intensity measures and citation counts (Results section) do not include controls for initial paper quality, author reputation, field-specific citation norms, or topic hotness. Without these, the associations may reflect pre-existing differences rather than effects of review demands.
Authors: The referee correctly identifies that our models currently include field and year fixed effects plus basic team attributes but lack direct proxies for pre-submission quality, reputation, or topic characteristics. We will revise the Results and Methods sections to incorporate additional controls: (1) corresponding-author h-index at submission time (retrieved via public APIs with appropriate temporal matching), (2) a topic-hotness measure derived from citation burst detection on prior literature in the same field, and (3) field-specific citation norms via normalized citation percentiles within sub-disciplines. We will also strengthen the Discussion to explicitly frame the findings as observational associations rather than causal effects of review demands, consistent with the referee's concern. revision: yes
-
Referee: [Methods / Sample description] The sample is restricted to accepted papers only. This selection truncates the distribution and prevents assessment of whether intense review leads to rejection of potentially high-impact work, weakening the interpretation that demanding review produces higher impact.
Authors: We acknowledge this as a fundamental design constraint. Nature Communications open-review data are released only for accepted and published papers, so rejected submissions are unavailable for analysis. This truncation means we cannot directly evaluate whether more demanding reviews disproportionately reject high-impact work. In the revised manuscript we will expand the Limitations section to discuss this selection effect explicitly, including its implications for interpreting the positive association among accepted papers and suggestions for future work that could link to datasets containing rejected manuscripts. revision: yes
Circularity Check
No significant circularity; empirical associations rest on external data
full rationale
The paper applies a fixed-prompt LLM pipeline to external review correspondence from Nature Communications (2017-2024) to derive structured variables on opinion strength, revision burden, and comment quality, then reports observational associations between those variables and later citation impact within accepted papers. No equations, fitted parameters, or predictions are described that reduce to the inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The derivation chain is self-contained against external benchmarks (review texts and citation counts) and does not exhibit self-definitional, renaming, or smuggling patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Throughout the paper, we usedemanding reviewas a descriptive shorthand for combinations of stronger criticism, higher comment quality, and greater revision cost
We use a fixed-prompt large language model procedure to convert the correspondence into LLM-extracted comment–response pairs and measure seven dimensions of interaction: opinion strength, constructiveness, comment quality, revision cost, opinion type, author response type, and persuasion success. Throughout the paper, we usedemanding reviewas a descriptiv...
2021
-
[2]
Bergstrom, Katy B¨ orner, James A
Santo Fortunato, Carl T. Bergstrom, Katy B¨ orner, James A. Evans, Dirk Helbing, Staˇ sa Milojevi´ c, et al. Science of science.Science, 359(6379):eaao0185, 2018
2018
-
[3]
The effectiveness of the peer review process: Inter- referee agreement and predictive validity of manuscript refereeing at Angewandte Chemie
Lutz Bornmann and Hans-Dieter Daniel. The effectiveness of the peer review process: Inter- referee agreement and predictive validity of manuscript refereeing at Angewandte Chemie. Angewandte Chemie International Edition, 47(38):7173–7178, 2008
2008
-
[4]
Diekman, and Elke U
Balazs Aczel, Ann-Sophie Barwich, Amanda B. Diekman, and Elke U. Weber. The present and future of peer review: Ideas, interventions, and evidence.Proceedings of the National Academy of Sciences, 122(5):e2401232121, 2025
2025
-
[5]
Hanson, Pablo G´ omez Barreiro, Paolo Crosetto, and Dan Brockington
Mark A. Hanson, Pablo G´ omez Barreiro, Paolo Crosetto, and Dan Brockington. The strain on scientific publishing.Quantitative Science Studies, 5(4):823–843, 2024
2024
-
[6]
Charles W. Fox, A. Y. K. Albert, and Timothy H. Vines. Recruitment of reviewers is becoming harder at some journals.Research Integrity and Peer Review, 2:3, 2017
2017
-
[7]
Overburdening of peer reviewers: a multi-stakeholder perspective on causes and effects.Learned Publishing, 34(4):537–546, 2021
Anna Severin and Joanna Chataway. Overburdening of peer reviewers: a multi-stakeholder perspective on causes and effects.Learned Publishing, 34(4):537–546, 2021
2021
-
[8]
John P. A. Ioannidis, Richard Klavans, and Kevin W. Boyack. Thousands of scientists publish a paper every five days.Nature, 561(7722):167–169, 2018
2018
-
[9]
Over-optimization of academic publishing metrics: Ob- serving Goodhart’s Law in action.GigaScience, 8(6):giz053, 2019
Michael Fire and Carlos Guestrin. Over-optimization of academic publishing metrics: Ob- serving Goodhart’s Law in action.GigaScience, 8(6):giz053, 2019
2019
-
[10]
MIT Press, 2020
Mario Biagioli and Alexandra Lippman.Gaming the metrics: Misconduct and manipulation in academic research. MIT Press, 2020
2020
-
[11]
A reliability-generalization study of journal peer reviews: A multilevel meta-analysis of inter-rater reliability and its determinants
Lutz Bornmann, Ruediger Mutz, and Hans-Dieter Daniel. A reliability-generalization study of journal peer reviews: A multilevel meta-analysis of inter-rater reliability and its determinants. PLoS One, 5(12):e14331, 2010
2010
-
[12]
Heterogeneity of inter-rater relia- bilities of grant peer reviews and its determinants: a general estimating equations approach
Ruediger Mutz, Lutz Bornmann, and Hans-Dieter Daniel. Heterogeneity of inter-rater relia- bilities of grant peer reviews and its determinants: a general estimating equations approach. PLoS One, 7(10):e48509, 2012
2012
-
[13]
Pier, Markus Brauer, Alexa Filut, Anna Kaatz, Joshua Raclaw, Mitchell J
Elizabeth L. Pier, Markus Brauer, Alexa Filut, Anna Kaatz, Joshua Raclaw, Mitchell J. Nathan, et al. Low agreement among reviewers evaluating the same NIH grant applications. 17 Proceedings of the National Academy of Sciences, 115(11):2952–2957, 2018
2018
-
[14]
Lee, Cassidy R
Carole J. Lee, Cassidy R. Sugimoto, Guo Zhang, and Blaise Cronin. Bias in peer review. Journal of the American Society for Information Science and Technology, 64(1):2–17, 2013
2013
-
[15]
Gender contributes to personal research funding success in the netherlands.Proceedings of the National Academy of Sciences, 112(40):12349– 12353, 2015
Romy Van der Lee and Naomi Ellemers. Gender contributes to personal research funding success in the netherlands.Proceedings of the National Academy of Sciences, 112(40):12349– 12353, 2015
2015
-
[16]
Witteman, Michelle Hendricks, Sharon Straus, and Cara Tannenbaum
Holly O. Witteman, Michelle Hendricks, Sharon Straus, and Cara Tannenbaum. Are gender gaps due to evaluations of the applicant or the science? a natural experiment at a national funding agency.The Lancet, 393(10171):531–540, 2019
2019
-
[17]
Gender gap in journal submissions and peer review during the first wave of the COVID-19 pandemic.PLoS One, 16(10):e0257919, 2021
Flaminio Squazzoni, Giangiacomo Bravo, Francisco Grimaldo, Daniel Garc´ ıa-Costa, Mike Farjam, and Bahar Mehmani. Gender gap in journal submissions and peer review during the first wave of the COVID-19 pandemic.PLoS One, 16(10):e0257919, 2021
2021
-
[18]
Collings, Jennifer Raymond, and Cassidy R
Dakota Murray, Kyle Siler, Vincent Larivi` ere, Wei Mun Chan, Andrew M. Collings, Jennifer Raymond, and Cassidy R. Sugimoto. Peer review and gender bias: A study on 145 scholarly journals.Science Advances, 7(2):eabd0299, 2021
2021
-
[19]
Ginther, Walter T
Donna K. Ginther, Walter T. Schaffer, Joshua Schnell, Beth Masimore, Faye Liu, Lau- rel L. Haak, and Raynard Kington. Race, ethnicity, and NIH research awards.Science, 333(6044):1015–1019, 2011
2011
-
[20]
Rebecca M. Blank. The effects of double-blind versus single-blind reviewing: Experimental evidence from the American Economic Review.American Economic Review, 81(5):1041–1067, 1991
1991
-
[21]
Andrew Tomkins, Min Zhang, and William D. Heavlin. Reviewer bias in single-versus double- blind peer review.Proceedings of the National Academy of Sciences, 114(48):12708–12713, 2017
2017
-
[22]
Kern-Goldberger, Rachel James, Vincenzo Berghella, and Emily S
Anna R. Kern-Goldberger, Rachel James, Vincenzo Berghella, and Emily S. Miller. The impact of double-blind peer review on gender bias in scientific publishing: A systematic review. American Journal of Obstetrics and Gynecology, 227(1):43–50, 2022
2022
-
[23]
Bias against novelty in science: A cautionary tale for users of bibliometric indicators.Research Policy, 46(8):1416–1436, 2017
Jian Wang, Reinhilde Veugelers, and Paula Stephan. Bias against novelty in science: A cautionary tale for users of bibliometric indicators.Research Policy, 46(8):1416–1436, 2017
2017
-
[24]
Boudreau, Eva C
Kevin J. Boudreau, Eva C. Guinan, Karim R. Lakhani, and Christoph Riedl. Looking across and looking beyond the knowledge frontier: Intellectual distance, novelty, and resource allo- 18 cation in science.Management Science, 62(10):2765–2783, 2016
2016
-
[25]
Carole J. Lee. Commensuration bias in peer review.Philosophy of Science, 82(5):1272–1283, 2015
2015
-
[26]
On the very idea of pursuitworthiness.Studies in History and Philosophy of Science, 91:103–112, 2022
Jamie Shaw. On the very idea of pursuitworthiness.Studies in History and Philosophy of Science, 91:103–112, 2022
2022
-
[27]
Woods, and Johanna Brumberg
Wolfgang Kaltenbrunner, Stephen Pinfield, Ludo Waltman, Helen B. Woods, and Johanna Brumberg. Innovating peer review, reconfiguring scholarly communication: an analytical overview of ongoing peer review innovation activities.Journal of Documentation, 78(7):429– 449, 2022
2022
-
[28]
The effect of publishing peer review reports on referee behavior in five scholarly journals.Nature Communications, 10(1):322, 2019
Giangiacomo Bravo, Francisco Grimaldo, Emilia L´ opez-I˜ nesta, Bahar Mehmani, and Flaminio Squazzoni. The effect of publishing peer review reports on referee behavior in five scholarly journals.Nature Communications, 10(1):322, 2019
2019
-
[29]
Meta-research: Large-scale language analysis of peer review reports.eLife, 9:e53249, 2020
Ivan Buljan, Daniel Garcia-Costa, Francisco Grimaldo, Flaminio Squazzoni, Ana Maruˇ si´ c, et al. Meta-research: Large-scale language analysis of peer review reports.eLife, 9:e53249, 2020
2020
-
[30]
Flaminio Squazzoni, Petra Ahrweiler, Tiago Barros, Federico Bianchi, Aliaksandr Birukou, Harry J. J. Blom, Giangiacomo Bravo, Stephen Cowley, Virginia Dignum, Pierpaolo Don- dio, Francisco Grimaldo, Lynsey Haire, Jason Hoyt, Phil Hurst, Rachael Lammey, Catriona MacCallum, Ana Maruˇ si´ c, Bahar Mehmani, Hollydawn Murray, Duncan Nicholas, Giorgio Pe- drazz...
2020
-
[31]
Peer review analyze: A novel benchmark resource for computational analysis of peer reviews.PLOS ONE, 17(1):e0259238, 2022
Tirthankar Ghosal, Sandeep Kumar, Prabhat Kumar Bharti, and Asif Ekbal. Peer review analyze: A novel benchmark resource for computational analysis of peer reviews.PLOS ONE, 17(1):e0259238, 2022
2022
-
[32]
AI-assisted peer review.Humanities and Social Sciences Communications, 8(1):1–11, 2021
Alessandro Checco, Lorenzo Bracciale, Pierpaolo Loreti, Stephen Pinfield, and Giuseppe Bianchi. AI-assisted peer review.Humanities and Social Sciences Communications, 8(1):1–11, 2021
2021
-
[33]
Kummerfeld, Anne Lauscher, Kevin Leyton-Brown, Sheng Lu, Mausam, Margot Mieskes, Aur´ elie N´ ev´ eol, Danish Pruthi, Lizhen Qu, Roy Schwartz, 19 Noah A
Ilia Kuznetsov, Osama Mohammed Afzal, Koen Dercksen, Nils Dycke, Alexander Goldberg, Tom Hope, Dirk Hovy, Jonathan K. Kummerfeld, Anne Lauscher, Kevin Leyton-Brown, Sheng Lu, Mausam, Margot Mieskes, Aur´ elie N´ ev´ eol, Danish Pruthi, Lizhen Qu, Roy Schwartz, 19 Noah A. Smith, Thamar Solorio, Jingyan Wang, Xiaodan Zhu, Anna Rogers, Nihar B. Shah, and Iry...
2024
-
[34]
Lutz Bornmann and Hans-Dieter Daniel. Selecting manuscripts for a high-impact journal through peer review: A citation analysis of communications that were accepted by Angewandte Chemie International Edition, or rejected but published elsewhere.Journal of the American Society for Information Science and Technology, 59(11):1841–1852, 2008
2008
-
[35]
ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences of the United States of America, 120(30):e2305016120, 2023
Fabrizio Gilardi, Meysam Alizadeh, and Ma¨ el Kubli. ChatGPT outperforms crowd workers for text-annotation tasks.Proceedings of the National Academy of Sciences of the United States of America, 120(30):e2305016120, 2023
2023
-
[36]
Can large language models transform computational social science?Computational Linguistics, 50(1):237–291, 2024
Caleb Ziems, William Held, Omar Shaikh, Jiaao Chen, Zhehao Zhang, and Diyi Yang. Can large language models transform computational social science?Computational Linguistics, 50(1):237–291, 2024
2024
-
[37]
Best practices for text annotation with large language models.Sociologica, 18(2):67–85, 2024
Petter T¨ ornberg. Best practices for text annotation with large language models.Sociologica, 18(2):67–85, 2024
2024
-
[38]
this does not address my concern,
Zihong Lin, Yian Yin, Luyang Liu, et al. Sciscinet: A large-scale open data lake for the science of science research.Scientific Data, 10:315, 2023. 20 Peer Review Files Round 2Round 1Round… Reviewers Author(s)Comment 1Reply 1Comment 2Reply 2Comment 3Reply 3…… LLM Text ProcessingJSONStructed Output a b c d ef FIG. 1: Validation of the AI-derived peer-revie...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.