Recognition: unknown
From Where Words Come: Efficient Regularization of Code Tokenizers Through Source Attribution
Pith reviewed 2026-05-10 12:59 UTC · model grok-4.3
The pith
Source attribution during BPE training lets code tokenizers skip merges that create under-trained tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Code tokenizers trained with ordinary BPE overfit to source-specific repetitive strings that dominate imbalanced repositories, resulting in a large fraction of tokens that receive little or no training signal. By attaching source information to every merge decision and deliberately skipping merges whose resulting tokens would be rare across diverse sources, Source-Attributed BPE produces a vocabulary with substantially fewer under-trained entries while leaving the tokenization procedure at inference time unchanged.
What carries the argument
Source-Attributed BPE (SA-BPE), a modification of the BPE merge objective that records the repository or file origin of each merge and skips merges predicted to produce tokens unlikely to appear outside the original training sources.
If this is right
- The resulting tokenizer contains fewer tokens that remain unused after training, directly improving encoding efficiency.
- Inference cost and safety properties of the tokenizer stay identical to those of a standard BPE tokenizer.
- The regularization works on any BPE-based code tokenizer without requiring changes to the model architecture or runtime.
- Vocabulary coverage across programming languages and repositories is preserved while the count of source-specific overfit tokens falls.
Where Pith is reading between the lines
- The same source-tracking idea could be applied to natural-language tokenizers whenever training data carries metadata about domains or genres.
- SA-BPE may reduce the need for separate vocabulary pruning steps that are often applied after initial BPE training.
- Measuring the reduction in under-trained tokens on progressively larger and more balanced code collections would show how much the benefit scales with data diversity.
- The approach points to a broader principle that tokenizer quality depends on explicit modeling of data-source statistics rather than raw frequency alone.
Load-bearing premise
Tracking the source of each merge during training is enough to identify which merges will later produce under-trained tokens without also discarding merges that would have been useful for broad coverage.
What would settle it
Train two tokenizers on the same code corpus, one with ordinary BPE and one with SA-BPE; then measure the fraction of vocabulary tokens that receive zero or near-zero occurrences when the tokenizers are run on a large, held-out set of diverse repositories and languages. A clear drop in that fraction with no loss in downstream model performance on standard code tasks would confirm the central claim.
Figures






















read the original abstract
Efficiency and safety of Large Language Models (LLMs), among other factors, rely on the quality of tokenization. A good tokenizer not only improves inference speed and language understanding but also provides extra defense against jailbreak attacks and lowers the risk of hallucinations. In this work, we investigate the efficiency of code tokenization, in particular from the perspective of data source diversity. We demonstrate that code tokenizers are prone to producing unused, and thus under-trained, tokens due to the imbalance in repository and language diversity in the training data, as well as the dominance of source-specific, repetitive tokens that are often unusable in future inference. By modifying the BPE objective and introducing merge skipping, we implement different techniques under the name Source-Attributed BPE (SA-BPE) to regularize BPE training and minimize overfitting, thereby substantially reducing the number of under-trained tokens while maintaining the same inference procedure as with regular BPE. This provides an effective tool suitable for production use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
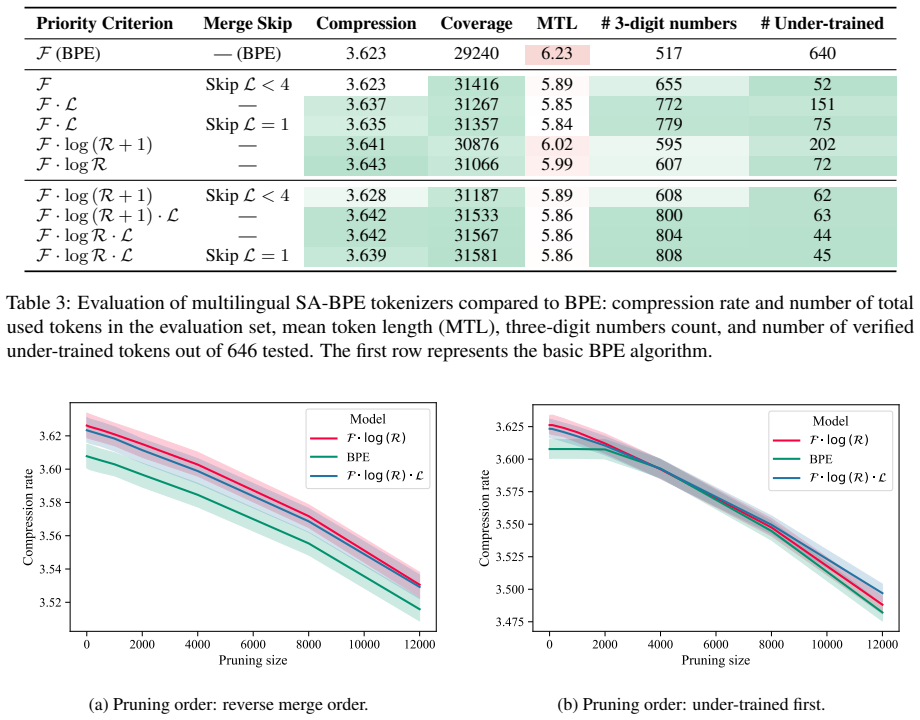
Summary. The paper proposes Source-Attributed BPE (SA-BPE), a set of modifications to standard BPE training for code tokenizers. By incorporating source attribution to detect repository- and language-specific repetitive patterns and introducing merge-skipping rules, the method regularizes the vocabulary construction process to reduce the production of under-trained (unused) tokens. The central claim is that this regularization substantially lowers the count of such tokens while leaving the inference-time tokenization procedure identical to vanilla BPE.
Significance. If the empirical results hold, the contribution is practically significant for code LLM pipelines: fewer under-trained tokens can improve training efficiency, reduce overfitting to narrow source patterns, and provide ancillary benefits for safety and robustness without any change to deployed inference. The approach is presented as production-ready because it requires no modification to existing tokenization code paths.
minor comments (3)
- [§3.2] §3.2: the precise definition of an 'under-trained token' (frequency threshold, context of non-use) should be stated explicitly with a formula or pseudocode so that the ablation tables can be reproduced without ambiguity.
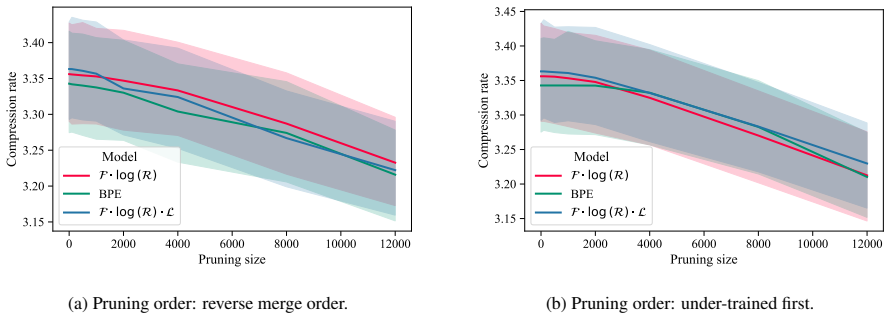
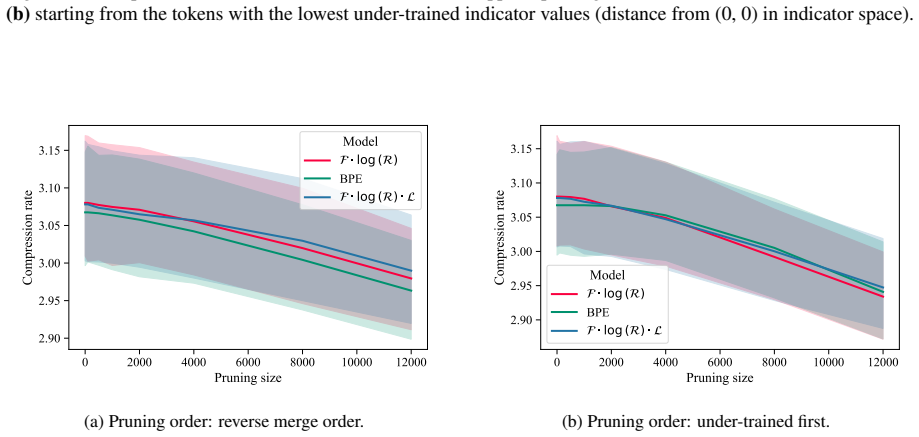
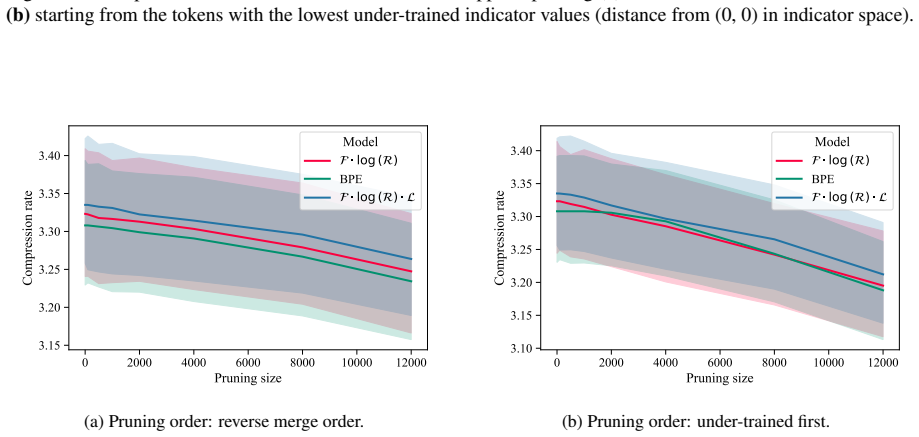
- [Table 2, Figure 4] Table 2 and Figure 4: the reported reductions in under-trained tokens are given as absolute counts; relative percentages and confidence intervals across multiple random seeds would strengthen the claim that the improvement is stable rather than corpus-specific.
- [§4.3] §4.3: the ablation isolating 'merge skipping' from the source-attribution signal is useful, but the interaction term between the two components is not quantified; a 2×2 factorial table would clarify whether the gains are additive or synergistic.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. We are pleased that the practical significance for code LLM pipelines—improved training efficiency, reduced overfitting to source-specific patterns, and no changes to inference—is recognized.
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces Source-Attributed BPE (SA-BPE) as a direct algorithmic modification to the standard BPE objective via source attribution and merge skipping. No equations, derivations, or first-principles results are presented that reduce the claimed reduction in under-trained tokens to a fitted parameter, self-referential quantity, or self-citation chain. The central claim rests on an independent regularization procedure whose implementation details and ablation results are described without internal reduction to the inputs by construction. The method maintains the original inference procedure and is positioned as a practical extension rather than a derived prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Source attribution during BPE merge decisions can identify and avoid merges that produce under-trained tokens
invented entities (1)
-
Source-Attributed BPE (SA-BPE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pavel Chizhov, Catherine Arnett, Elizaveta Korotkova, and Ivan P
Curran Associates, Inc. Pavel Chizhov, Catherine Arnett, Elizaveta Korotkova, and Ivan P. Yamshchikov. 2024. BPE Gets Picky: Efficient V ocabulary Refinement During Tokenizer Training. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 16587–16604, Miami, Florida, USA. Associa- tion for Computational Linguistic...
-
[2]
StarCoder 2 and The Stack v2: The Next Generation
StarCoder 2 and The Stack v2: The Next Generation.Preprint, arXiv:2402.19173. Ivan Provilkov, Dmitrii Emelianenko, and Elena V oita
work page internal anchor Pith review arXiv
-
[3]
InProceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics, pages 1882–1892, Online
BPE-Dropout: Simple and Effective Subword Regularization. InProceedings of the 58th Annual Meeting of the Association for Computational Lin- guistics, pages 1882–1892, Online. Association for Computational Linguistics. Taido Purason, Pavel Chizhov, Ivan P. Yamshchikov, and Mark Fishel. 2026. Teaching old tokenizers new words: Efficient tokenizer adaptatio...
2026
-
[4]
Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Neural Machine Translation of Rare Words with Subword Units. InProceedings of the 54th An- nual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1715– 1725, Berlin, Germany. Association for Computa- tional Linguistics. David Vilar and Marcello Federico. 2021. A Statistical Extension of Byte-Pair Encoding. InProceedin...
work page internal anchor Pith review arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.