Recognition: unknown
A Comparative Study of Dynamic Programming and Reinforcement Learning in Finite Horizon Dynamic Pricing
Pith reviewed 2026-05-10 11:37 UTC · model grok-4.3
The pith
Fitted dynamic programming can be applied to multi-product finite-horizon pricing with constraints, where it trades off against reinforcement learning in revenue, stability, and scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper shows that fitted dynamic programming, when applied to multi-dimensional environments with multiple product types and inter-temporal constraints, produces measurable differences from reinforcement learning in revenue performance, constraint satisfaction, stability, and computational scaling, thereby revealing the practical trade-offs between explicit expectation-based optimization and trajectory-based learning.
What carries the argument
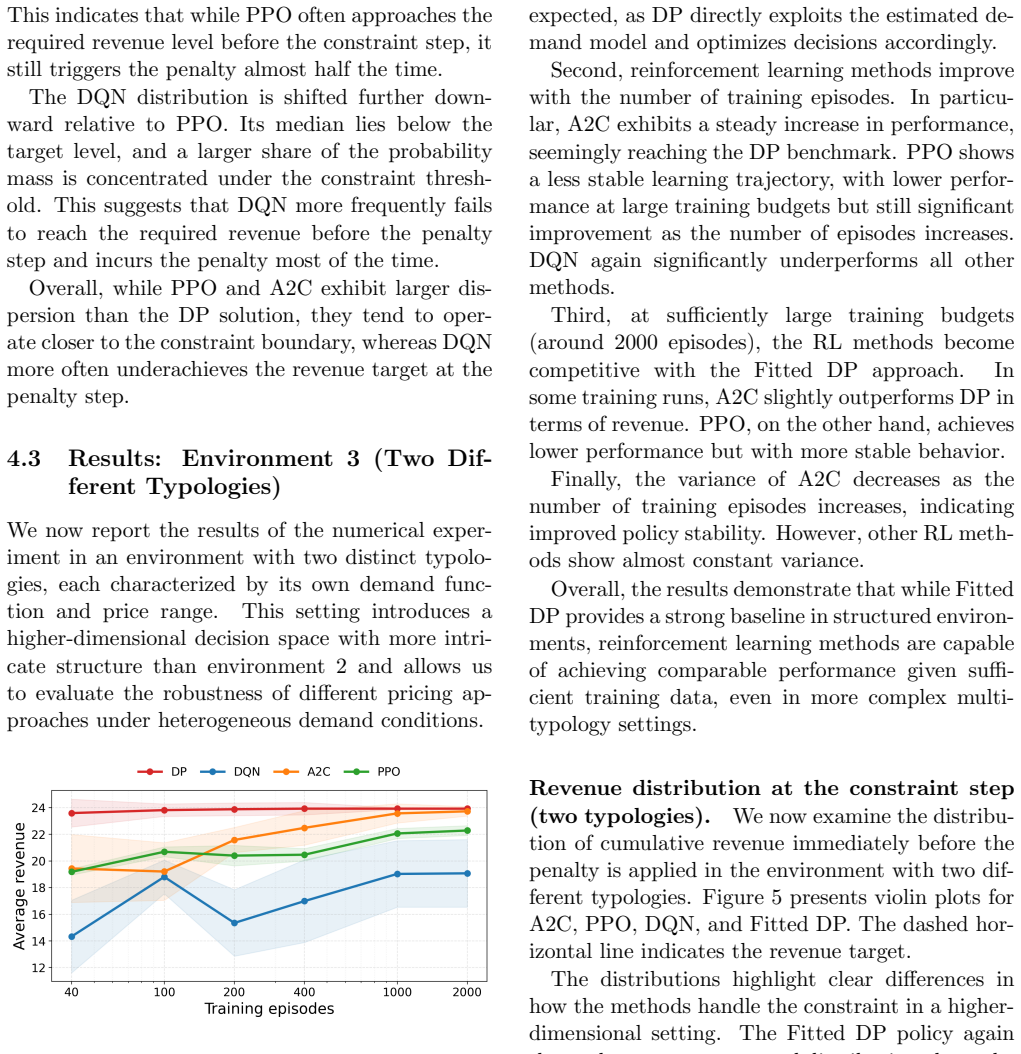
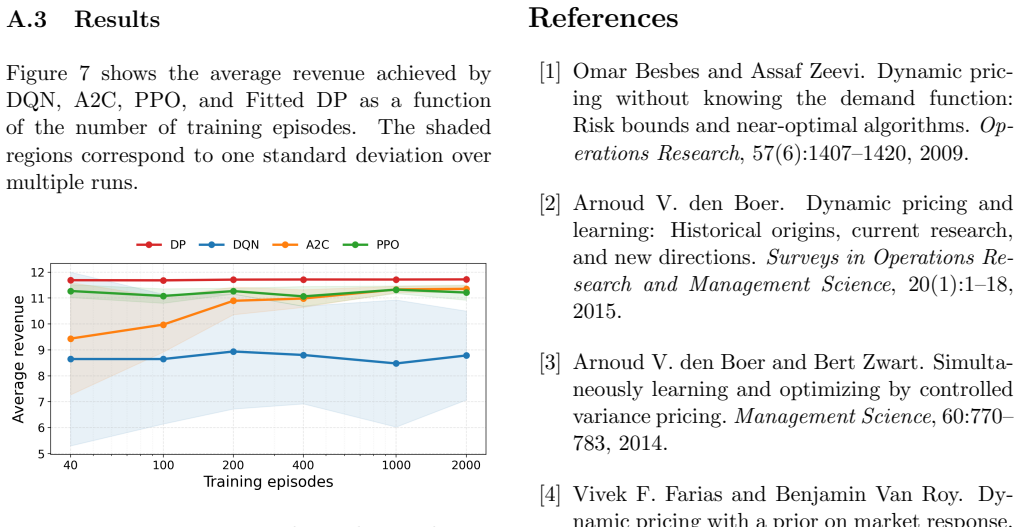
Environments of increasing structural complexity, ranging from a single-typology benchmark to multi-typology settings with heterogeneous demand and inter-temporal revenue constraints, used to benchmark fitted dynamic programming against reinforcement learning.
If this is right
- Dynamic programming remains usable for pricing problems that involve several product types and time-linked constraints when function approximation is employed.
- Reinforcement learning trajectories may require additional mechanisms to enforce revenue constraints reliably.
- Computational scaling favors one method over the other once the number of product types and time periods grows beyond small cases.
- Explicit demand estimation allows direct incorporation of known constraints that trajectory sampling must discover indirectly.
Where Pith is reading between the lines
- Firms facing strict inventory or revenue targets across product lines may find fitted dynamic programming easier to audit and adjust than pure reinforcement learning policies.
- If demand patterns shift faster than simulation training allows, reinforcement learning could gain an edge by updating from live trajectories without re-estimating an explicit model.
- Hybrid methods that use dynamic programming for constraint projection and reinforcement learning for exploration might reduce the stability issues seen in either approach alone.
Load-bearing premise
The simulated environments with increasing structural complexity capture the essential challenges of real-world finite-horizon dynamic pricing with heterogeneous demand.
What would settle it
A side-by-side test on actual retail transaction logs that records whether fitted dynamic programming and reinforcement learning produce the same relative gaps in revenue and constraint violations as observed in the multi-typology simulations.
Figures





read the original abstract
This paper provides a systematic comparison between Fitted Dynamic Programming (DP), where demand is estimated from data, and Reinforcement Learning (RL) methods in finite-horizon dynamic pricing problems. We analyze their performance across environments of increasing structural complexity, ranging from a single typology benchmark to multi-typology settings with heterogeneous demand and inter-temporal revenue constraints. Unlike simplified comparisons that restrict DP to low-dimensional settings, we apply dynamic programming in richer, multi-dimensional environments with multiple product types and constraints. We evaluate revenue performance, stability, constraint satisfaction behavior, and computational scaling, highlighting the trade-offs between explicit expectation-based optimization and trajectory-based learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper provides a systematic comparison between Fitted Dynamic Programming (DP), with demand estimated from data, and Reinforcement Learning (RL) methods for finite-horizon dynamic pricing problems. It evaluates their performance in simulated environments of increasing structural complexity, from single-typology benchmarks to multi-typology settings with heterogeneous demand and inter-temporal revenue constraints, using metrics such as revenue performance, stability, constraint satisfaction, and computational scaling.
Significance. If the results hold, this study offers important insights into the practical trade-offs between model-based DP and model-free RL in dynamic pricing, particularly by demonstrating the applicability of DP in higher-dimensional settings with constraints. This can inform algorithm selection in revenue management and contributes to bridging theoretical optimization and learning-based approaches in operations research.
minor comments (1)
- [Abstract] The abstract describes the experimental setup and metrics but does not report any specific numerical results, effect sizes, or key findings from the comparisons, making it difficult for readers to immediately gauge the outcomes.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The assessment correctly identifies the paper's focus on systematic comparisons of fitted DP (with estimated demand) versus RL across increasing problem complexity in finite-horizon dynamic pricing.
Circularity Check
No significant circularity in empirical benchmark
full rationale
This is an empirical comparative study of Fitted DP (with data-estimated demand) versus RL across simulated pricing environments of increasing complexity. The central claim is performance evaluation on revenue, stability, constraints, and scaling; no derivation chain, first-principles prediction, or fitted quantity is presented that reduces by construction to its own inputs. No self-definitional equations, load-bearing self-citations, or ansatz smuggling appear in the abstract or framing. The work is self-contained as a controlled simulation benchmark and does not invoke uniqueness theorems or rename known results as new derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dynamic pric- ing without knowing the demand function: Risk bounds and near-optimal algorithms.Op- erations Research, 57(6):1407–1420, 2009
Omar Besbes and Assaf Zeevi. Dynamic pric- ing without knowing the demand function: Risk bounds and near-optimal algorithms.Op- erations Research, 57(6):1407–1420, 2009
2009
-
[2]
den Boer
Arnoud V. den Boer. Dynamic pricing and learning: Historical origins, current research, and new directions.Surveys in Operations Re- search and Management Science, 20(1):1–18, 2015
2015
-
[3]
den Boer and Bert Zwart
Arnoud V. den Boer and Bert Zwart. Simulta- neously learning and optimizing by controlled variance pricing.Management Science, 60:770– 783, 2014
2014
-
[4]
Farias and Benjamin Van Roy
Vivek F. Farias and Benjamin Van Roy. Dy- namic pricing with a prior on market response. Operations Research, 58(1):16–29, 2010
2010
-
[5]
Analytics for an online retailer: Demand fore- casting and price optimization.Manufacturing & Service Operations Management, 20(1):69– 88, 2018
Kris Johnson Ferreira and David Simchi-Levi. Analytics for an online retailer: Demand fore- casting and price optimization.Manufacturing & Service Operations Management, 20(1):69– 88, 2018
2018
-
[6]
Optimal dynamic pricing of inventories with stochastic demand over finite horizons.Man- agement Science, 40(8):999–1020, 1994
Guillermo Gallego and Garrett van Ryzin. Optimal dynamic pricing of inventories with stochastic demand over finite horizons.Man- agement Science, 40(8):999–1020, 1994
1994
-
[7]
Dy- namic pricing in high-dimensions.Journal of Machine Learning Research, 20(9):1–49, 2019
Adel Javanmard and Hamid Nazerzadeh. Dy- namic pricing in high-dimensions.Journal of Machine Learning Research, 20(9):1–49, 2019
2019
-
[8]
Dy- namic pricing under competition using rein- forcement learning.Journal of Revenue and Pricing Management, 21(1):50–63, 2022
Alexander Kastius and Rainer Schlosser. Dy- namic pricing under competition using rein- forcement learning.Journal of Revenue and Pricing Management, 21(1):50–63, 2022
2022
-
[9]
Reinforcement learning versus data- driven dynamic programming: A comparison for finite horizon dynamic pricing markets
Fabian Lange, Leonard Dreessen, and Rainer Schlosser. Reinforcement learning versus data- driven dynamic programming: A comparison for finite horizon dynamic pricing markets. Journal of Revenue and Pricing Management, 24:584–600, 2025
2025
-
[10]
Stanford University Press, Stanford, 2005
Robert Phillips.Pricing and Revenue Opti- mization. Stanford University Press, Stanford, 2005. 11
2005
-
[11]
Oliveira
Rahul Rana and Flavio S. Oliveira. Real-time dynamic pricing in a non-stationary environ- ment using model-free reinforcement learning. Omega, 47:116–126, 2014
2014
-
[12]
Talluri and Garrett J
Kalyan T. Talluri and Garrett J. van Ryzin. The Theory and Practice of Revenue Manage- ment. Springer, New York, 2004. Lev Razumovskiy ,RAMAX Group E-mail address: lev.razumovskiy@ramax.com Nikolay Karenin,RAMAX Group E-mail address: nikolay.karenin@ramax.com 12
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.