Recognition: unknown
Neural architectures for resolving references in program code
Pith reviewed 2026-05-10 13:28 UTC · model grok-4.3
The pith
New sequence-to-sequence architectures for reference resolution in code handle ten times longer examples and reduce errors by 42% in decompilation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We abstract reference rewriting into the problems of direct and indirect indexing by permutation. We create synthetic benchmarks for these tasks and show that well-known sequence-to-sequence machine learning architectures are struggling on these benchmarks. We introduce new sequence-to-sequence architectures for both problems. Our measurements show that our architectures outperform the baselines in both robustness and scalability: our models can handle examples that are ten times longer compared to the best baseline. We measure the impact of our architecture in the real-world task of decompiling switch statements, which has an indexing subtask. According to our measurements, the extended m
What carries the argument
Custom sequence-to-sequence architectures for direct and indirect indexing by permutation that abstract and solve reference rewriting in program code.
If this is right
- The architectures process inputs ten times longer than the strongest baseline while remaining accurate.
- Error rates fall by 42% when decompiling switch statements using the extended model.
- Ablation experiments demonstrate that each component of the architectures is necessary.
- Common sequence-to-sequence models lack robustness and scalability on these permutation tasks.
Where Pith is reading between the lines
- These permutation-focused designs may extend to other code manipulation problems like register allocation or loop invariant code motion.
- If the benchmarks represent real code well, the methods could enhance tools for binary analysis and malware detection.
- Integrating the architectures into larger transformer-based models might further boost performance on full programs.
Load-bearing premise
The synthetic benchmarks for direct and indirect indexing by permutation faithfully capture the distribution and difficulty of reference-resolution subtasks that appear in real program decompilation.
What would settle it
Running the new architectures on a larger set of real decompiled programs with diverse reference patterns and finding no improvement in accuracy or scalability would disprove the main claims.
Figures



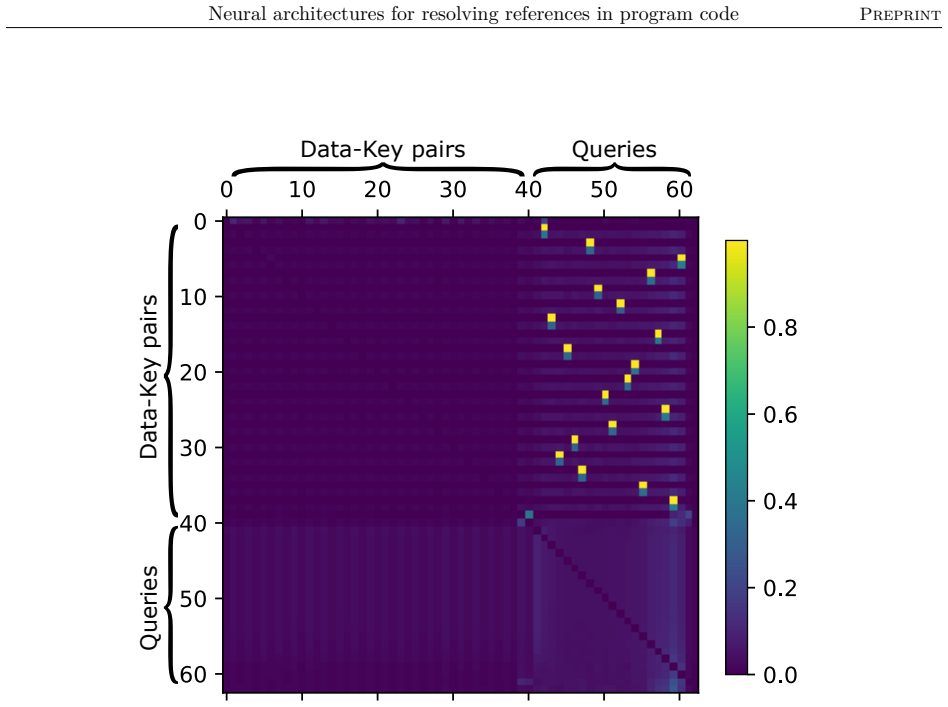

read the original abstract
Resolving and rewriting references is fundamental in programming languages. Motivated by a real-world decompilation task, we abstract reference rewriting into the problems of direct and indirect indexing by permutation. We create synthetic benchmarks for these tasks and show that well-known sequence-to-sequence machine learning architectures are struggling on these benchmarks. We introduce new sequence-to-sequence architectures for both problems. Our measurements show that our architectures outperform the baselines in both robustness and scalability: our models can handle examples that are ten times longer compared to the best baseline. We measure the impact of our architecture in the real-world task of decompiling switch statements, which has an indexing subtask. According to our measurements, the extended model decreases the error rate by 42%. Multiple ablation studies show that all components of our architectures are essential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper abstracts reference rewriting in code to direct and indirect indexing by permutation. It generates synthetic benchmarks where standard seq2seq models struggle, introduces new architectures claimed to handle inputs ten times longer than baselines, and reports a 42% error-rate reduction when applied to decompiling switch statements, with ablations showing all components are essential.
Significance. If the results hold, the work offers targeted architectures for long-range reference resolution in code, which could improve decompilation and program analysis tools. The combination of isolating the indexing subtask synthetically and validating on a real decompilation task, plus ablation studies, is a positive aspect of the experimental design.
major comments (2)
- [Abstract] Abstract: the headline claims (10x longer inputs, 42% error drop on switch decompilation) are presented without details on how the synthetic benchmarks are generated, the precise model equations or architectural modifications, or any statistical tests/error bars. These omissions are load-bearing because the central claims of superior robustness and scalability cannot be assessed or reproduced from the given information.
- [Synthetic benchmarks] Synthetic benchmarks section: no comparison is provided between the distribution of reference patterns (aliasing, scoping, control-flow noise) in the generated permutation-indexing data and those appearing in actual decompiled binaries. Without this, the assumption that superior performance on the synthetic tasks implies transfer to the motivating switch-decompilation application remains unverified and weakens the real-world claim.
minor comments (1)
- [Abstract] The abstract refers to 'well-known sequence-to-sequence machine learning architectures' as baselines but does not name them; adding the specific models (e.g., standard LSTM or Transformer variants) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying details present in the full manuscript and indicating revisions where they strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (10x longer inputs, 42% error drop on switch decompilation) are presented without details on how the synthetic benchmarks are generated, the precise model equations or architectural modifications, or any statistical tests/error bars. These omissions are load-bearing because the central claims of superior robustness and scalability cannot be assessed or reproduced from the given information.
Authors: The abstract is intentionally concise as a high-level summary of contributions. Complete details on synthetic benchmark generation appear in Section 3, the model architectures with equations and modifications in Section 4, and all quantitative results including error bars and statistical tests in Section 5. These sections enable full assessment and reproduction. We have added a single sentence to the abstract directing readers to the relevant sections for the supporting details. revision: partial
-
Referee: [Synthetic benchmarks] Synthetic benchmarks section: no comparison is provided between the distribution of reference patterns (aliasing, scoping, control-flow noise) in the generated permutation-indexing data and those appearing in actual decompiled binaries. Without this, the assumption that superior performance on the synthetic tasks implies transfer to the motivating switch-decompilation application remains unverified and weakens the real-world claim.
Authors: The synthetic benchmarks isolate the core permutation-indexing operations that define the reference-resolution subtask. While we did not include an explicit statistical comparison of pattern distributions (e.g., aliasing or scoping frequencies), the transferability is directly evidenced by the 42% error-rate reduction achieved when the same architectures are applied to the real switch-decompilation task. We have inserted a short paragraph in the synthetic benchmarks section explaining the design choices and their relation to real code patterns. revision: partial
Circularity Check
No circularity: results are measured empirical performance on held-out data.
full rationale
The paper defines synthetic benchmarks for direct/indirect permutation indexing, trains sequence-to-sequence models on them, and reports measured accuracy/scalability on held-out test sets plus a separate real decompilation task. No equations, fitted parameters, or self-citations are shown that reduce the reported 10x length handling or 42% error reduction to quantities defined by the same inputs. Ablations and baseline comparisons are independent experimental outcomes. The motivating assumption that synthetic permutations proxy real reference patterns is a validity claim, not a definitional reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate.arXiv preprint arXiv:1409.0473, 2015. URLhttp://arxiv.org/abs/1409.0473
work page internal anchor Pith review arXiv 2015
- [2]
-
[3]
J. Gu, Z. Lu, H. Li, and V. O. Li. Incorporating copying mechanism in sequence-to-sequence learning. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1631–1640, 2016
2016
-
[4]
H. J. Levesque, E. Davis, and L. Morgenstern. The winograd schema challenge.KR, 2012(13th):3, 2012
2012
-
[5]
Mitkov.Anaphora resolution
R. Mitkov.Anaphora resolution. Routledge, 2014
2014
- [6]
-
[7]
Schuster and K
M. Schuster and K. K. Paliwal. Bidirectional recurrent neural networks.IEEE transactions on Signal Processing, 45(11):2673–2681, 1997
1997
-
[8]
A. See, P. J. Liu, and C. D. Manning. Get to the point: Summarization with pointer-generator networks. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1073–1083, 2017
2017
-
[9]
G. Szalay, M. B. Poór, B. Pintér, and T. Gregorics. Single-pass end-to-end neural decompila- tion using copying mechanism.Neural Computing and Applications, Dec 2024. ISSN 1433-3058. doi:10.1007/s00521-024-10735-9. URLhttps://doi.org/10.1007/s00521-024-10735-9
- [10]
-
[11]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polo- sukhin. Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, vol- ume 30. Curran Associates, Inc., 2017. URLhttps://proceedings.ne...
2017
-
[12]
Vinyals, M
O. Vinyals, M. Fortunato, and N. Jaitly. Pointer networks.Advances in neural information processing systems, 28, 2015
2015
-
[13]
L2 " is the key and
M. N. Wegman and F. K. Zadeck. Constant propagation with conditional branches.ACM Transactions on Programming Languages and Systems (TOPLAS), 13(2):181–210, 1991. 16 Neural architectures for resolving references in program codePreprint A A real-world example Below is an assembly code snippet corresponding to aCswitch statement. // in case of 87 as an argu...
1991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.