Recognition: unknown
From Weights to Activations: Is Steering the Next Frontier of Adaptation?
Pith reviewed 2026-05-10 12:49 UTC · model grok-4.3
The pith
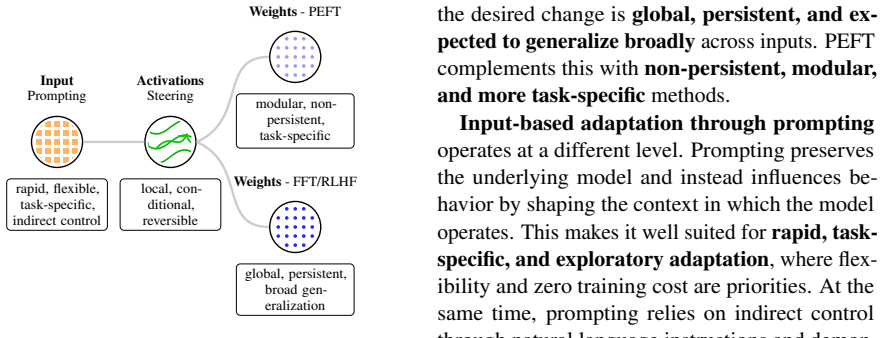
Steering language models by editing internal activations at inference time qualifies as a distinct form of adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under functional criteria that emphasize targeted, reversible effects without parameter updates, steering qualifies as model adaptation because it intervenes in activation space at inference time to produce localized behavioral changes, thereby fitting alongside established methods and calling for a single taxonomy that covers both weight-based and activation-based techniques.
What carries the argument
The functional criteria for adaptation, which classify methods according to whether they produce local, reversible behavioral changes without updating parameters.
If this is right
- Model customization becomes possible without the cost or permanence of retraining weights.
- Changes can target specific behaviors and be undone without side effects on unrelated outputs.
- Methods can be compared and combined under shared functional properties rather than by their implementation details.
- New adaptation techniques can be designed by focusing on activation interventions that meet the same criteria.
Where Pith is reading between the lines
- The taxonomy could help practitioners select adaptation strategies based on constraints like compute budget or need for reversibility.
- Steering research might benefit from borrowing evaluation protocols already used for fine-tuning.
- Similar functional criteria could be applied to adaptation in vision or multimodal models to test whether the pattern holds.
Load-bearing premise
The chosen functional criteria fully and neutrally separate adaptation methods from one another and that steering satisfies them in a way no prior method does.
What would settle it
An experiment that shows steering either produces non-local or non-reversible effects or that an existing method like prompting already satisfies every criterion in exactly the same manner.
Figures



read the original abstract
Post-training adaptation of language models is commonly achieved through parameter updates or input-based methods such as fine-tuning, parameter-efficient adaptation, and prompting. In parallel, a growing body of work modifies internal activations at inference time to influence model behavior, an approach known as steering. Despite increasing use, steering is rarely analyzed within the same conceptual framework as established adaptation methods. In this work, we argue that steering should be regarded as a form of model adaptation. We introduce a set of functional criteria for adaptation methods and use them to compare steering approaches with classical alternatives. This analysis positions steering as a distinct adaptation paradigm based on targeted interventions in activation space, enabling local and reversible behavioral change without parameter updates. The resulting framing clarifies how steering relates to existing methods, motivating a unified taxonomy for model adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that activation-based steering should be classified as a distinct form of post-training model adaptation for language models. It introduces a set of functional criteria to compare steering with parameter-update methods (fine-tuning, PEFT) and input-based methods (prompting), claiming that steering enables local, reversible behavioral changes through targeted interventions in activation space without any parameter updates, and that this framing motivates a unified taxonomy of adaptation techniques.
Significance. If the functional criteria prove robust and non-circular, the work could help organize the growing literature on inference-time interventions by providing a shared conceptual lens, clarifying trade-offs between activation editing and weight-based adaptation, and guiding more systematic empirical comparisons across paradigms.
major comments (2)
- [Section introducing the functional criteria (following the abstract)] The functional criteria for adaptation are presented as the basis for classifying steering as distinct, yet they are introduced qualitatively without explicit formalization, derivation from first principles, or proof of exhaustiveness and invariance under re-framing (e.g., whether activation editing can be equivalently described as input-conditioned prompting). This makes the distinct-paradigm claim dependent on the untested sufficiency of the chosen criteria rather than on derived properties.
- [Analysis and comparison sections] The comparisons with fine-tuning, PEFT, and prompting rely on qualitative contrasts that assume the criteria are unbiased and sufficient; no quantitative validation, sensitivity analysis, or counter-examples are provided to show that the classification remains stable if the criteria are adjusted or if alternative taxonomies are considered.
minor comments (1)
- [Abstract] The abstract summarizes the argument but does not define or exemplify the functional criteria, making it difficult for readers to assess the central claim without reading further sections.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which highlight important aspects of how our functional criteria are presented and used. We address each major comment below and propose targeted revisions to clarify the conceptual scope of the work.
read point-by-point responses
-
Referee: [Section introducing the functional criteria (following the abstract)] The functional criteria for adaptation are presented as the basis for classifying steering as distinct, yet they are introduced qualitatively without explicit formalization, derivation from first principles, or proof of exhaustiveness and invariance under re-framing (e.g., whether activation editing can be equivalently described as input-conditioned prompting). This makes the distinct-paradigm claim dependent on the untested sufficiency of the chosen criteria rather than on derived properties.
Authors: We agree that the criteria are introduced qualitatively and are not derived from first principles or accompanied by a formal proof of exhaustiveness. They are proposed as a practical set of observable functional properties (parameter-free operation, locality of intervention, reversibility, and inference-time applicability) drawn from how methods are actually used in the literature, with the aim of organizing existing work rather than establishing an axiomatic taxonomy. We do not claim invariance under all possible re-framings; the example of equivalence to input-conditioned prompting is a fair point, and steering's direct manipulation of internal activations cannot be replicated solely through input reformulation without model access. In revision we will add a subsection explicitly discussing the criteria's heuristic nature, limitations, and potential alternative framings to make these boundaries clearer. revision: partial
-
Referee: [Analysis and comparison sections] The comparisons with fine-tuning, PEFT, and prompting rely on qualitative contrasts that assume the criteria are unbiased and sufficient; no quantitative validation, sensitivity analysis, or counter-examples are provided to show that the classification remains stable if the criteria are adjusted or if alternative taxonomies are considered.
Authors: The comparisons are intentionally qualitative because the paper's primary contribution is a conceptual framing rather than an empirical benchmark. We support the distinctions with concrete examples from published steering work. To strengthen robustness, we will incorporate a short sensitivity discussion and several counter-examples (such as cases where certain steering vectors could be approximated by carefully engineered prompts or where fine-tuning effects partially overlap with activation edits) in a revised section. A comprehensive quantitative stability analysis across all conceivable criteria adjustments would require a separate large-scale empirical study, which lies beyond the scope of this position paper but could be motivated as future work. revision: partial
Circularity Check
Self-defined functional criteria classify steering as distinct adaptation paradigm
specific steps
-
self definitional
[Abstract]
"we argue that steering should be regarded as a form of model adaptation. We introduce a set of functional criteria for adaptation methods and use them to compare steering approaches with classical alternatives. This analysis positions steering as a distinct adaptation paradigm based on targeted interventions in activation space, enabling local and reversible behavioral change without parameter updates."
The criteria are introduced by the paper without external derivation or validation. They are then invoked to establish that steering meets the definition of a distinct adaptation method, rendering the central claim dependent on the authors' choice of criteria rather than an independent property of the methods.
full rationale
The paper's core contribution is a proposed taxonomy: it introduces functional criteria for what counts as model adaptation and then applies those criteria to conclude that steering qualifies as a distinct paradigm (local, reversible, activation-space interventions without parameter updates). This matches the self-definitional pattern because the criteria are not derived from first principles, external benchmarks, or exhaustive enumeration but are presented as the authors' own framework, after which the classification follows by construction. No equations, fitted parameters, or self-citation chains appear in the provided text; the argument is purely conceptual and qualitative. The circularity is therefore limited to the definitional move rather than a mathematical reduction or load-bearing self-reference, warranting a moderate score rather than 0 or 6+.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Functional criteria can be defined to classify and compare model adaptation methods including steering
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Mohammadreza Salehi, Matthew Pe- ters, and Hannaneh Hajishirzi
Refusal in language models is mediated by a single direction.Advances in Neural Information Processing Systems, 37:136037–136083. Akari Asai, Mohammadreza Salehi, Matthew Pe- ters, and Hannaneh Hajishirzi. 2022. ATTEMPT: Parameter-efficient multi-task tuning via attentional mixtures of soft prompts. InProceedings of the 2022 Conference on Empirical Method...
2022
-
[2]
On the Opportunities and Risks of Foundation Models
Enhanced language model truthfulness with learnable intervention and uncertainty expression. In Findings of the Association for Computational Lin- guistics: ACL 2024, pages 12388–12400. Reza Bayat, Ali Rahimi-Kalahroudi, Mohammad Pezeshki, Sarath Chandar, and Pascal Vincent. 2025. Steering large language model activations in sparse spaces. InSecond Confer...
work page internal anchor Pith review arXiv 2024
-
[3]
Cheng-Ting Chou, George Liu, Jessica Sun, Cole Blondin, Kevin Zhu, Vasu Sharma, and Sean O’Brien
A fine-grained self-adapting prompt learn- ing approach for few-shot learning with pre-trained language models.Knowledge-Based Systems, 299:111968. Cheng-Ting Chou, George Liu, Jessica Sun, Cole Blondin, Kevin Zhu, Vasu Sharma, and Sean O’Brien
-
[4]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Mar- tic, Shane Legg, and Dario Amodei
Causal language control in multilingual transformers via sparse feature steering.Preprint, arXiv:2507.13410. Paul F Christiano, Jan Leike, Tom Brown, Miljan Mar- tic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences.Ad- vances in neural information processing systems, 30. Daniel Commey. 2026. When" better" prompts hur...
-
[5]
Dual-attention based prompt generation and catalyzing for instance-wise continual learning.Pat- tern Recognition, page 112685. DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingx- uan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Da...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A survey on in-context learning. InProceed- ings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107–1128, Miami, Florida, USA. Association for Computational Linguistics. Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, and 1 others. ...
-
[7]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Clas-bench: A cross-lingual alignment and steering benchmark.Findings of the Association for Computational Linguistics: ACL 2026. Daniil Gurgurov, Katharina Trinley, Yusser Al Ghussin, Tanja Baeumel, Josef Van Genabith, and Simon Os- termann. 2025. Language arithmetics: Towards sys- tematic language neuron identification and manip- ulation. InProceedings ...
work page internal anchor Pith review arXiv 2026
-
[8]
Stefan Heimersheim and Neel Nanda
Llama scope: Extracting millions of features from llama-3.1-8b with sparse autoencoders.arXiv preprint arXiv:2410.20526. Roee Hendel, Mor Geva, and Amir Globerson. 2023. In- context learning creates task vectors.arXiv preprint arXiv:2310.15916. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mon...
-
[9]
Parameter- Efficient Transfer Learning for NLP .arXiv2019, arXiv:1902.00751
Parameter-efficient transfer learning for nlp. Preprint, arXiv:1902.00751. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models.Preprint, arXiv:2106.09685. Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. 2024....
-
[10]
Probing artificial neural networks: insights from neuroscience.Preprint, arXiv:2104.08197. Kai Konen, Sophie Jentzsch, Diaoulé Diallo, Peer Schütt, Oliver Bensch, Roxanne El Baff, Dominik Opitz, and Tobias Hecking. 2024. Style vectors for steering generative large language model.Preprint, arXiv:2402.01618. Suhas Kotha, Jacob Mitchell Springer, and Aditi R...
-
[11]
Revisiting catastrophic forgetting in large lan- guage model tuning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4297–4308, Miami, Florida, USA. Association for Computational Linguistics. Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. 2023. Inference- time intervention: Eliciting truthf...
-
[12]
InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024
In-context vectors: Making in context learning more effective and controllable through latent space steering. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun X...
2024
-
[13]
arXiv preprint arXiv:0902.3430 , year=
Rethinking machine unlearning for large lan- guage models.Nature Machine Intelligence, pages 1–14. Wei Lu, Rachel K Luu, and Markus J Buehler. 2025. Fine-tuning large language models for domain adap- tation: Exploration of training strategies, scaling, model merging and synergistic capabilities.npj Com- putational Materials, 11(1):84. Yun Luo, Zhen Yang, ...
-
[14]
InProceedings of the 2013 conference of the north american chapter of the as- sociation for computational linguistics: Human lan- guage technologies, pages 746–751
Linguistic regularities in continuous space word representations. InProceedings of the 2013 conference of the north american chapter of the as- sociation for computational linguistics: Human lan- guage technologies, pages 746–751. Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. 2024a. State of what art? a call for m...
2013
-
[15]
Steering Llama 2 via Contrastive Activation Addition
Steering llama 2 via contrastive activation addition.arXiv preprint arXiv:2312.06681. Kiho Park, Yo Joong Choe, and Victor Veitch
work page internal anchor Pith review arXiv
-
[16]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The linear representation hypothesis and the geometry of large language models.Preprint, arXiv:2311.03658. David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. Car- bon emissions and large neural network training. Preprint, arXiv:2104.10350. Branislav Pecher, Ivan Srba, ...
work page internal anchor Pith review arXiv 2021
-
[17]
Learning to Generate Reviews and Discovering Sentiment , publisher =
Learning to generate reviews and discovering sentiment.Preprint, arXiv:1704.01444. Alec Radford, Luke Metz, and Soumith Chintala. 2015. Unsupervised representation learning with deep con- volutional generative adversarial networks.CoRR, abs/1511.06434. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, and 1 others. 2019. Lan...
-
[18]
InICML 2025 Workshop on Methods and Opportunities at Small Scale
The necessity for intervention fidelity: Unin- tended side effects when steering LLMs. InICML 2025 Workshop on Methods and Opportunities at Small Scale. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christo- pher D Manning, Stefano Ermon, and Chelsea Finn
2025
-
[19]
arXiv preprint arXiv:2410.09087 , year=
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741. Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. 2024. Steer- ing llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the As- sociat...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.