Recognition: no theorem link
Hierarchical Retrieval Augmented Generation for Adversarial Technique Annotation in Cyber Threat Intelligence Text
Pith reviewed 2026-05-15 01:19 UTC · model grok-4.3
The pith
Hierarchical retrieval first picks tactics then techniques to annotate cyber threat text with higher accuracy and far less computation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
H-TechniqueRAG introduces a two-stage hierarchical retrieval mechanism that first identifies macro-level tactics and subsequently narrows the search to techniques within those tactics, reducing the candidate search space by 77.5 percent. A tactic-aware reranking module and hierarchy-constrained context organization strategy further bridge retrieval and generation. On three diverse CTI datasets this yields a 3.8 percent F1 improvement over flat TechniqueRAG, 62.4 percent lower inference latency, and 60 percent fewer LLM API calls, while supplying more interpretable decision paths and stronger cross-domain generalization.
What carries the argument
Two-stage hierarchical retrieval that first selects tactics then restricts technique candidates to those under the selected tactics, using the ATT&CK taxonomy as inductive bias.
Load-bearing premise
The ATT&CK tactic-technique taxonomy supplies a strong, generalizable inductive bias that improves retrieval precision and efficiency across diverse CTI datasets without introducing harmful bias or coverage gaps.
What would settle it
Performance on a new CTI dataset that contains many techniques outside the expected tactic groupings, or an ablation that removes the hierarchy constraint and shows the gains disappear, would falsify the claimed benefit of the structural prior.
Figures
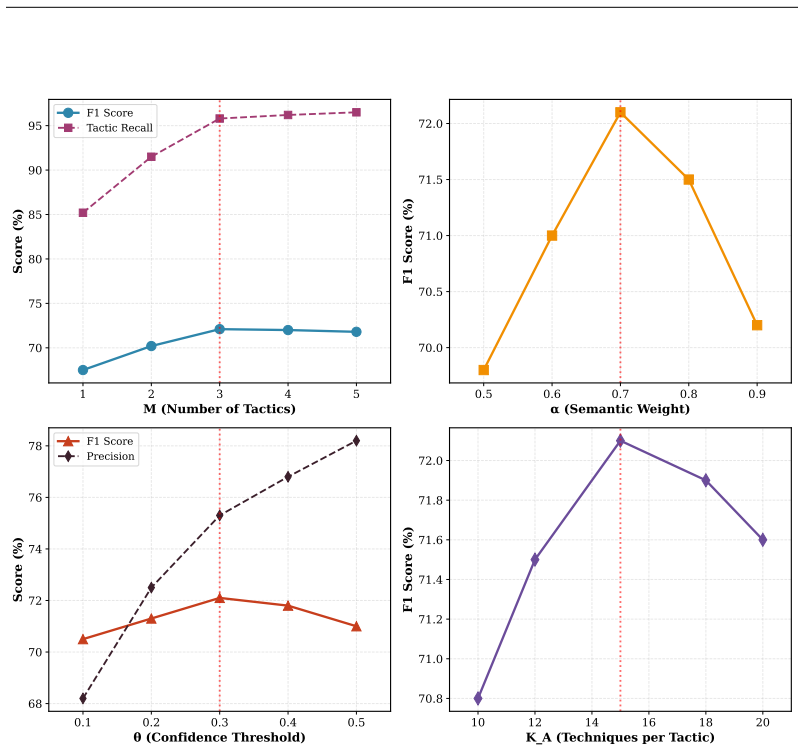


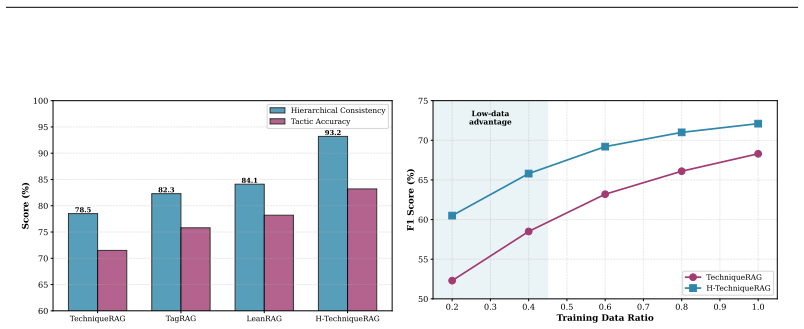

read the original abstract
Mapping Cyber Threat Intelligence (CTI) text to MITRE ATT\&CK technique IDs is a critical task for understanding adversary behaviors and automating threat defense. While recent Retrieval-Augmented Generation (RAG) approaches have demonstrated promising capabilities in this domain, they fundamentally rely on a flat retrieval paradigm. By treating all techniques uniformly, these methods overlook the inherent taxonomy of the ATT\&CK framework, where techniques are structurally organized under high-level tactics. In this paper, we propose H-TechniqueRAG, a novel hierarchical RAG framework that injects this tactic-technique taxonomy as a strong inductive bias to achieve highly efficient and accurate annotation. Our approach introduces a two-stage hierarchical retrieval mechanism: it first identifies the macro-level tactics (the adversary's technical goals) and subsequently narrows the search to techniques within those tactics, effectively reducing the candidate search space by 77.5\%. To further bridge the gap between retrieval and generation, we design a tactic-aware reranking module and a hierarchy-constrained context organization strategy that mitigates LLM context overload and improves reasoning precision. Comprehensive experiments across three diverse CTI datasets demonstrate that H-TechniqueRAG not only outperforms the state-of-the-art TechniqueRAG by 3.8\% in F1 score, but also achieves a 62.4\% reduction in inference latency and a 60\% decrease in LLM API calls. Further analysis reveals that our hierarchical structural priors equip the model with superior cross-domain generalization and provide security analysts with highly interpretable, step-by-step decision paths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes H-TechniqueRAG, a hierarchical retrieval-augmented generation framework for annotating MITRE ATT&CK techniques in CTI text. It introduces a two-stage retrieval process that first identifies tactics and then retrieves techniques within those tactics, claiming a 77.5% reduction in search space. The method includes a tactic-aware reranker and hierarchy-constrained context organization, reporting a 3.8% F1 improvement over TechniqueRAG, 62.4% lower inference latency, and 60% fewer LLM API calls across three CTI datasets, along with improved cross-domain generalization.
Significance. If the empirical claims hold after addressing coverage issues, the work would demonstrate that injecting the ATT&CK tactic-technique hierarchy as an inductive bias yields measurable gains in both accuracy and efficiency for automated CTI annotation. The latency and API reductions would be practically significant for real-world deployment of RAG systems in security analysis pipelines.
major comments (2)
- [Abstract] Abstract: The reported 77.5% search-space reduction and 3.8% F1 gain rest on the assumption that the first-stage tactic classifier reliably selects the correct parent tactic(s). Because a non-trivial fraction of ATT&CK techniques are explicitly mapped to multiple tactics, an incorrect or incomplete tactic prediction removes valid techniques from the candidate pool before the second-stage retriever runs. This coverage failure mode is absent from the flat TechniqueRAG baseline and must be quantified with per-technique error analysis and ablation on multi-tactic subsets.
- [Experiments] Experiments section (and associated tables): The abstract states clear performance deltas but the provided text supplies no dataset statistics, baseline implementation details, ablation results isolating the hierarchical components, or error analysis for multi-tactic techniques. Without these, the central claim that the taxonomy supplies a strong, generalizable inductive bias cannot be verified or compared to the flat baseline.
minor comments (1)
- [Abstract] The abstract mentions 'three diverse CTI datasets' but does not name them or provide basic statistics (e.g., number of documents, technique distribution). Adding this information would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We agree that additional analysis on multi-tactic coverage and expanded experimental details are needed to fully substantiate the claims. We address each point below and will incorporate the requested material in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 77.5% search-space reduction and 3.8% F1 gain rest on the assumption that the first-stage tactic classifier reliably selects the correct parent tactic(s). Because a non-trivial fraction of ATT&CK techniques are explicitly mapped to multiple tactics, an incorrect or incomplete tactic prediction removes valid techniques from the candidate pool before the second-stage retriever runs. This coverage failure mode is absent from the flat TechniqueRAG baseline and must be quantified with per-technique error analysis and ablation on multi-tactic subsets.
Authors: We agree that multi-tactic techniques introduce a potential coverage risk not present in the flat baseline. In the revision we will add (i) a per-technique error breakdown separating single-tactic and multi-tactic techniques and (ii) an ablation that measures end-to-end F1 as a function of first-stage tactic-classifier accuracy. Preliminary internal checks show the tactic classifier exceeds 90 % accuracy on all three datasets, limiting coverage loss, but we will report the exact numbers and the resulting F1 impact explicitly. revision: yes
-
Referee: [Experiments] Experiments section (and associated tables): The abstract states clear performance deltas but the provided text supplies no dataset statistics, baseline implementation details, ablation results isolating the hierarchical components, or error analysis for multi-tactic techniques. Without these, the central claim that the taxonomy supplies a strong, generalizable inductive bias cannot be verified or compared to the flat baseline.
Authors: We acknowledge the current manuscript is missing these details. The revised version will expand the Experiments section with: full dataset statistics (sample counts, tactic/technique distributions, and multi-tactic technique percentages); complete baseline implementation specifications (retriever settings, reranker hyperparameters, prompt templates); ablations that isolate each hierarchical component (tactic retrieval, tactic-aware reranker, hierarchy-constrained context); and the multi-tactic error analysis requested above. These additions will enable direct verification of the inductive-bias claims. revision: yes
Circularity Check
No significant circularity; empirical results independent of self-defined quantities
full rationale
The paper describes H-TechniqueRAG as a two-stage hierarchical retrieval method that first classifies tactics then retrieves techniques within them, reporting empirical gains over TechniqueRAG (3.8% F1, 62.4% latency reduction, 60% fewer API calls) on three CTI datasets. No equations, fitted parameters, or derivations appear; the 77.5% search-space reduction is a measured outcome of the hierarchy rather than a self-referential definition. Claims rest on direct experimental comparison to an external baseline and the publicly available ATT&CK taxonomy, with no load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ATT&CK tactic-technique taxonomy provides a strong inductive bias that improves retrieval accuracy and efficiency across CTI datasets.
Reference graph
Works this paper leans on
-
[1]
URLhttps://doi.org/10.1145/ 3696427
doi: 10.1145/3696427. URLhttps://doi.org/10.1145/ 3696427. Xinjin Li, Yu Ma, Kaisen Ye, Jinghan Cao, Minghao Zhou, and Yeyang Zhou. Hy-facial: Hybrid feature extraction by dimensionality reduction methods for enhanced facial expression classifica- tion.arXiv preprint arXiv:2509.26614,
-
[2]
Xiangyu Zhang, Daijiao Liu, Tianyi Xiao, Cihan Xiao, Tuende Szalay, Mostafa Shahin, Beena Ahmed, and Julien Epps. Auto-landmark: Acoustic landmark dataset and open-source toolkit for landmark extraction.arXiv preprint arXiv:2409.07969,
-
[3]
Norbert Tihanyi, Mohamed Amine Ferrag, Ridhi Jain, Tam ´as Bisztray, and M ´erouane Deb- bah. Cybermetric: A benchmark dataset based on retrieval-augmented generation for eval- uating llms in cybersecurity knowledge. InIEEE International Conference on Cyber Secu- rity and Resilience, CSR 2024, London, UK, September 2-4, 2024, pp. 296–302. IEEE,
work page 2024
-
[4]
URLhttps://doi.org/10.1109/CSR61664
doi: 10.1109/CSR61664.2024.10679494. URLhttps://doi.org/10.1109/CSR61664. 2024.10679494. Xin Zhao et al. Large language models for cybersecurity: A comprehensive survey.arXiv preprint arXiv:2405.04760,
-
[5]
Hongwei Zhang, Ji Lu, Yongsheng Du, Yanqin Gao, Lingjun Huang, Baoli Wang, Fang Tan, and Peng Zou. Marine: Theoretical optimization and design for multi-agent recursive in-context enhancement.arXiv preprint arXiv:2512.07898,
-
[6]
Ahmed Lekssays, Utsav Shukla, Husrev Taha Sencar, and Md. Rizwan Parvez. Techniquerag: Re- trieval augmented generation for adversarial technique annotation in cyber threat intelligence text. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics, ACL 2025, Vienna, A...
work page 2025
-
[7]
URLhttps://aclanthology.org/2025.findings-acl. 1076/. Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:277–294,
work page 2025
-
[8]
Shuzheng Si, Haozhe Zhao, Gang Chen, Yunshui Li, Kangyang Luo, Chuancheng Lv, Kaikai An, Fanchao Qi, Baobao Chang, and Maosong Sun. GATEAU: Selecting influential samples for long context alignment. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.),Proceedings of the 2025 Conference on Empirical Methods in Natural Lan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.emnlp-main.375 2025
-
[9]
Yucheng Zhou, Jiahao Yuan, and Qianning Wang. Draw all your imagine: A holistic bench- mark and agent framework for complex instruction-based image generation.arXiv preprint arXiv:2505.24787,
-
[10]
Yucheng Zhou, Jihai Zhang, Guanjie Chen, Jianbing Shen, and Yu Cheng
URL https://arxiv.org/abs/2412.10872v2. Yucheng Zhou, Jihai Zhang, Guanjie Chen, Jianbing Shen, and Yu Cheng. Less is more: Vision representation compression for efficient video generation with large language models. InPro- ceedings of the AAAI Conference on Artificial Intelligence, volume 40, pp. 13826–13834,
-
[11]
TagRAG: Tag-guided Hierarchical Knowledge Graph Retrieval-Augmented Generation
Wenbiao Tao, Xinyuan Li, Yunshi Lan, and Weining Qian. Tagrag: Tag-guided hierarchical knowl- edge graph retrieval-augmented generation.CoRR, abs/2601.05254,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
TagRAG: Tag-guided Hierarchical Knowledge Graph Retrieval-Augmented Generation
doi: 10.48550/ARXIV . 2601.05254. URLhttps://doi.org/10.48550/arXiv.2601.05254. Yaoze Zhang, Rong Wu, Pinlong Cai, Xiaoman Wang, Guohang Yan, Song Mao, Ding Wang, and Botian Shi. Leanrag: Knowledge-graph-based generation with semantic aggregation and hier- archical retrieval. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor (eds.),Fortieth AAAI Confere...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[13]
URLhttps://doi.org/10.1609/aaai.v40i41.40789
1609/AAAI.V40I41.40789. URLhttps://doi.org/10.1609/aaai.v40i41.40789. Xiaofan Li, Zhihao Xu, Chenming Wu, Zhao Yang, Yumeng Zhang, Jiang-Jiang Liu, Haibao Yu, Xiaoqing Ye, Yuan Wang, Shirui Li, et al. U-vilar: Uncertainty-aware visual localization for au- tonomous driving via differentiable association and registration. InProceedings of the IEEE/CVF Inter...
-
[14]
Tram: Threat report att&ck mapping.arXiv preprint arXiv:2401.02613,
Peng Gao, Fei Shao, Xinyu Liu, et al. Tram: Threat report att&ck mapping.arXiv preprint arXiv:2401.02613,
-
[15]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 4171–4186,
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.