Recognition: no theorem link
Correcting Suppressed Log-Probabilities in Language Models with Post-Transformer Adapters
Pith reviewed 2026-05-15 00:35 UTC · model grok-4.3
The pith
A small post-transformer adapter corrects suppressed factual log-probabilities in aligned language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A 786K-parameter post-transformer adapter trained on frozen hidden states corrects log-probability suppression on 31 ideology-discriminating facts, memorizes all training examples, generalizes to a portion of held-out facts across random splits, and supports coherent generation only when applied exclusively at the current prediction position.
What carries the argument
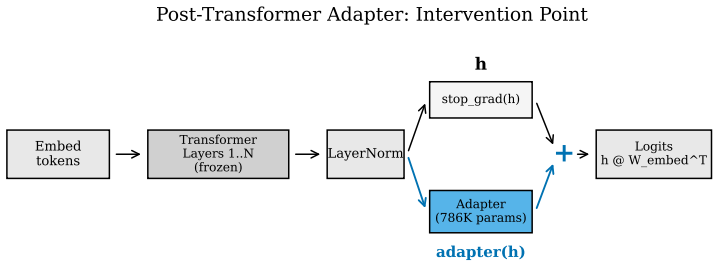
The post-transformer adapter that receives frozen hidden states and selectively adjusts output log-probabilities at the final token position.
If this is right
- Hidden-state intervention at the prediction position alone is sufficient for coherent probability correction.
- Anchored training keeps unrelated knowledge intact while fixing specific suppressions.
- Both gated and linear adapters achieve similar correction rates.
- Logit-space adapters applied after token projection fail to produce coherent generation.
Where Pith is reading between the lines
- Suppression from alignment occurs primarily at the output-probability stage rather than by erasing internal knowledge.
- Selective last-position application could be tested on other forms of output editing such as style or safety constraints.
- The same small adapter size might work on additional model families if the hidden states preserve the relevant facts.
Load-bearing premise
Factual knowledge stays fully accessible inside the frozen hidden representations and the adapter can boost the right probabilities without creating incoherence or regressions.
What would settle it
An experiment in which the adapter leaves the target log-probabilities unchanged or produces incoherent text when applied at the prediction position would show the correction claim does not hold.
Figures


read the original abstract
Alignment-tuned language models frequently suppress factual log-probabilities on politically sensitive topics despite retaining the knowledge in their hidden representations. We show that a 786K-parameter (approximately 0.02% of the base model) post-transformer adapter, trained on frozen hidden states, corrects this suppression on 31 ideology-discriminating facts across Qwen3-4B, 8B, and 14B. The adapter memorizes all 15 training facts and generalizes to 11--39% of 16 held-out facts across 5 random splits per scale, with zero knowledge regressions via anchored training. Both gated (SwiGLU) and ungated (linear bottleneck) adapters achieve comparable results; neither consistently outperforms the other (Fisher exact p > 0.09 at all scales). On instruct models, the adapter corrects log-probability rankings. When applied at all token positions during generation, the adapter produces incoherent output; however, when applied only at the current prediction position (last-position-only), the adapter produces coherent, less censored text. A logit-space adapter operating after token projection fails to produce coherent generation at any application mode, suggesting hidden-state intervention is the correct level for generation correction. A previously undocumented silent gradient bug in Apple MLX explains all null results in earlier iterations of this work: the standard pattern nn.value_and_grad(model, fn)(model.parameters()) returns zero gradients without error; the correct pattern nn.value_and_grad(model, fn)(model, data) resolves this. We provide a minimal reproduction and discuss implications for other adapter research using MLX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that alignment-tuned LMs suppress factual log-probabilities on politically sensitive topics while retaining the knowledge in hidden representations, and that a 786K-parameter post-transformer adapter (0.02% of base model size) trained on frozen hidden states can correct this suppression. It reports full memorization of 15 training facts, 11-39% generalization to 16 held-out facts across 5 splits and three Qwen3 scales (4B/8B/14B), zero regressions via anchored training, comparable performance for gated and ungated adapters, coherent generation under last-position-only application, and failure of logit-space baselines. A silent MLX gradient bug is also documented.
Significance. If the results hold, the work demonstrates a lightweight, hidden-state-level intervention that can mitigate output suppression without full fine-tuning or logit-space changes, while preserving coherence under restricted application. The scale comparisons, anchored training to avoid regressions, and explicit MLX bug disclosure are concrete strengths that could inform adapter research in MLX and related frameworks.
major comments (3)
- [Experiments and Results] The central claim that ideology-discriminating facts remain fully accessible in the frozen hidden states (and thus recoverable by the small adapter) lacks direct verification such as linear probing or activation analysis of the pre-adapter representations. Without this, the modest 11-39% generalization rates could reflect exploitation of training-specific directions rather than a general correction for suppression.
- [Results] The generalization results (11-39% across splits) are variable and relatively low; the manuscript should include per-fact breakdowns, analysis of failure modes, and stronger baselines (e.g., random adapters or probing classifiers) to establish that the adapter is selectively recovering suppressed knowledge rather than memorizing patterns.
- [Generation Experiments] Coherence under last-position-only application is asserted but not quantified (e.g., via perplexity, human ratings, or regression counts on non-sensitive facts); this is load-bearing for the claim that the method preserves model behavior during autoregressive generation.
minor comments (3)
- [Methods] Expand the methods section with exact adapter dimensions, training hyperparameters, and the precise definition of anchored training to improve reproducibility.
- [Results] Include error bars, confidence intervals, or per-split variance for all reported percentages and p-values; also list the 31 facts explicitly in an appendix.
- [Results] Clarify the distinction between instruct and base models in the ranking correction results and provide example generations for both application modes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the empirical support for our claims. We address each major point below and will revise the manuscript accordingly by adding the requested analyses, breakdowns, and quantifications. These changes will clarify the accessibility of facts in hidden states, improve transparency on generalization, and provide quantitative evidence for coherence preservation.
read point-by-point responses
-
Referee: The central claim that ideology-discriminating facts remain fully accessible in the frozen hidden states (and thus recoverable by the small adapter) lacks direct verification such as linear probing or activation analysis of the pre-adapter representations. Without this, the modest 11-39% generalization rates could reflect exploitation of training-specific directions rather than a general correction for suppression.
Authors: We agree that explicit linear probing of the pre-adapter hidden states would provide more direct verification of fact accessibility. The current evidence rests on the adapter's ability to recover suppressed log-probabilities from frozen representations on all 15 training facts, with generalization to held-out facts across independent splits and scales; anchored training further ensures we are not introducing regressions on non-sensitive content. This implies the information is linearly recoverable to some degree, but we acknowledge the gap. In revision we will add linear probing classifiers on the frozen hidden states (both before and after adapter training) to directly measure fact presence and separability, distinguishing general accessibility from split-specific directions. revision: yes
-
Referee: The generalization results (11-39% across splits) are variable and relatively low; the manuscript should include per-fact breakdowns, analysis of failure modes, and stronger baselines (e.g., random adapters or probing classifiers) to establish that the adapter is selectively recovering suppressed knowledge rather than memorizing patterns.
Authors: We concur that aggregate reporting obscures important variation and that stronger controls are needed. The observed range (11-39%) arises because different facts exhibit different degrees of suppression in the base models; some held-out facts generalize readily while others remain suppressed. We will add per-fact success tables and failure-mode categorization (e.g., by topic sensitivity or base-model log-prob gap) to the appendix. For baselines, we already show that logit-space adapters fail to yield coherent generation; we will further include (i) random-initialized adapters of identical architecture and (ii) linear probing classifiers trained on the same hidden states. These will demonstrate that performance exceeds both random and simple memorization controls, supporting selective recovery of suppressed knowledge. revision: yes
-
Referee: Coherence under last-position-only application is asserted but not quantified (e.g., via perplexity, human ratings, or regression counts on non-sensitive facts); this is load-bearing for the claim that the method preserves model behavior during autoregressive generation.
Authors: We recognize that qualitative examples alone are insufficient for a load-bearing claim. The manuscript shows that full-position application produces incoherent output while last-position-only yields coherent text, but we will quantify this in revision. Specifically, we will report (i) perplexity on a held-out set of non-sensitive factual prompts, (ii) regression counts (changes in log-probability) for a battery of non-ideology facts before and after adapter application, and (iii) a small-scale human preference rating on coherence and factuality for generated continuations. These metrics will confirm that last-position-only application preserves baseline behavior on unrelated content while correcting suppression on the target facts. revision: yes
Circularity Check
No significant circularity; results are empirical and self-contained
full rationale
The paper reports experimental outcomes from training a small post-transformer adapter on frozen hidden states using 15 ideology-discriminating facts, then measuring generalization (11-39%) on 16 held-out facts across 5 random splits per model scale, plus comparisons of gated vs. ungated adapters and last-position-only vs. full-position application modes. These quantities are direct measurements on held-out data rather than quantities derived by construction from the training inputs. No equations, self-citations, uniqueness theorems, or ansatzes are presented as load-bearing steps; the anchored training technique is explicitly a regularization method to avoid regressions, not a renamed prediction. The MLX gradient bug note is a methodological correction without circular implications. The central claims rest on standard train/test splits and cross-scale replication, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- adapter parameter count
axioms (2)
- domain assumption Hidden representations retain factual knowledge despite output suppression from alignment
- domain assumption Anchored training prevents knowledge regression on non-target facts
Reference graph
Works this paper leans on
-
[1]
G. N. Frank. Detection is cheap, routing is learned: Why refusal-based alignment evaluation fails. arXiv preprint arXiv:2603.18280,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv:2406.01563. Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-...
-
[3]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Mac- Diarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.