Recognition: unknown
Awakening Dormant Experts:Counterfactual Routing to Mitigate MoE Hallucinations
Pith reviewed 2026-05-10 14:19 UTC · model grok-4.3
The pith
Counterfactual routing activates dormant experts in MoE models to improve factual accuracy by 3.1 percent without added compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
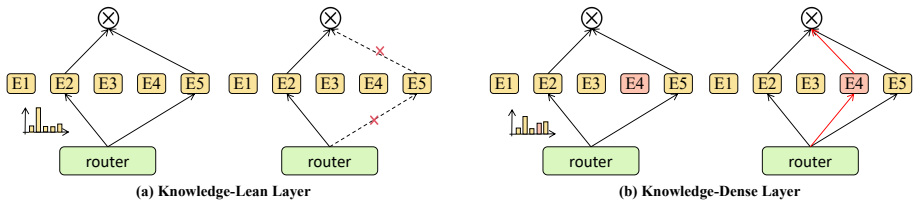
The paper claims that layer-wise perturbation analysis combined with the Counterfactual Expert Impact metric can identify and activate dormant experts that are causally decisive for long-tail factual associations, thereby mitigating hallucinations in MoE models while preserving the original total activation count and inference budget.
What carries the argument
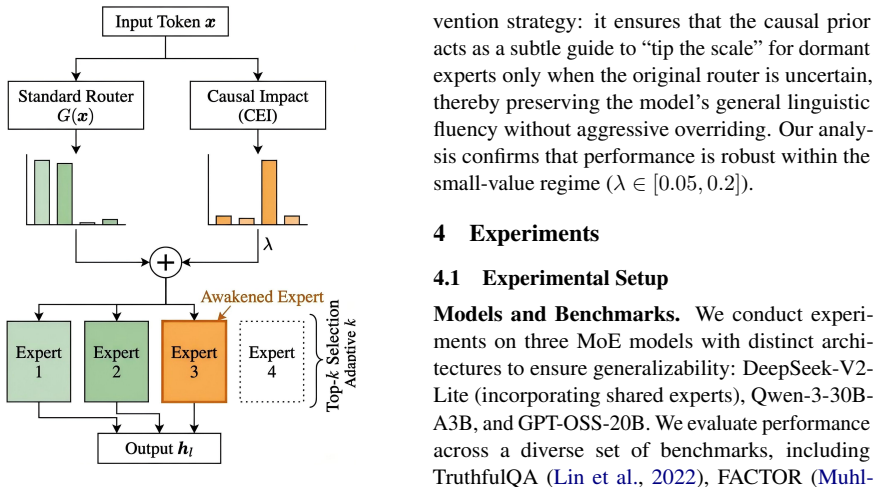
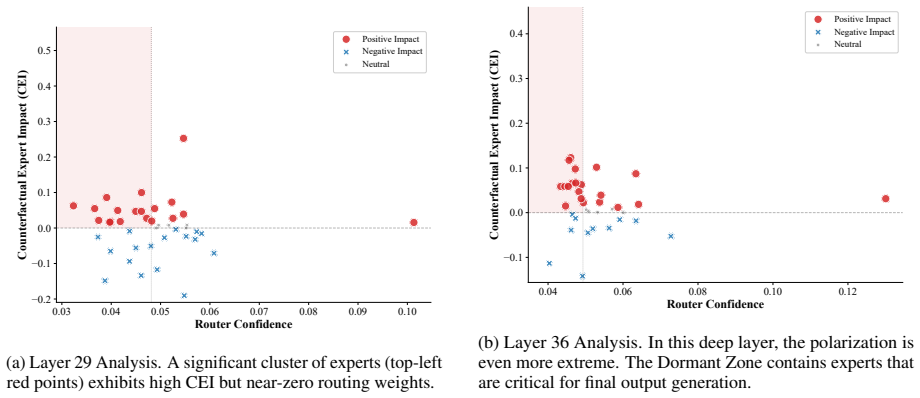
Counterfactual Expert Impact (CEI) metric obtained via layer-wise virtual ablation to measure each expert's causal contribution to the output.
If this is right
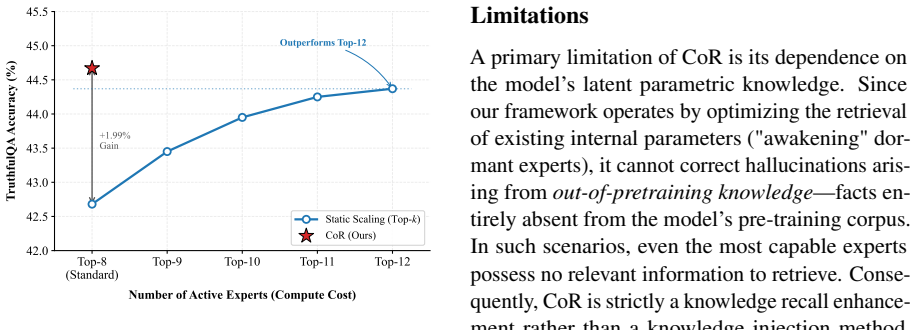
- Factual accuracy rises by 3.1 percent on average across TruthfulQA, FACTOR, and TriviaQA.
- Total expert activations per token stay constant, so inference cost remains unchanged.
- The method yields a superior performance-compute frontier compared with static increases in the number of active experts.
- Existing trained MoE models can use the technique at inference time with no retraining required.
Where Pith is reading between the lines
- Routing biases may be a broader source of unreliability across other sparse conditional-computation architectures.
- The approach could be combined with targeted continued pretraining on long-tail data for additive gains.
- Similar dormant-expert effects may appear in non-factual tasks such as reasoning or code generation.
- The technique suggests that hallucinations often reflect under-use of existing knowledge rather than absence of that knowledge.
Load-bearing premise
Layer-wise perturbation analysis and the Counterfactual Expert Impact metric reliably identify causally important dormant experts for long-tail knowledge without introducing new errors or degrading other capabilities.
What would settle it
On a held-out factual benchmark, applying the suggested expert activations produces no accuracy gain or causes measurable degradation on fluency or non-factual tasks.
Figures


read the original abstract
Sparse Mixture-of-Experts (MoE) models have achieved remarkable scalability, yet they remain vulnerable to hallucinations, particularly when processing long-tail knowledge. We identify that this fragility stems from static Top-$k$ routing: routers tend to favor high-frequency patterns over rare factual associations. Consequently, ``specialist experts'' possessing critical long-tail knowledge are often assigned low gating scores and remain ``dormant'' -- under-prioritized for specific tokens despite their proven causal importance on other inputs. To address this, we propose Counterfactual Routing (CoR), a training-free inference framework designed to awaken these dormant experts. CoR integrates layer-wise perturbation analysis with the Counterfactual Expert Impact (CEI) metric to dynamically shift computational resources from syntax-dominant to knowledge-intensive layers while maintaining a constant total activation count, effectively retrieving causally decisive experts via virtual ablation. Extensive experiments on TruthfulQA, FACTOR, and TriviaQA demonstrate that CoR improves factual accuracy by 3.1\% on average without increasing the inference budget, establishing a superior Pareto frontier compared to static scaling strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Counterfactual Routing (CoR), a training-free inference-time framework for sparse MoE models. It identifies dormant specialist experts for long-tail knowledge via layer-wise perturbation analysis and the Counterfactual Expert Impact (CEI) metric, then dynamically reallocates a fixed activation budget away from syntax-dominant layers to activate those experts. Experiments on TruthfulQA, FACTOR, and TriviaQA are reported to yield a 3.1% average factual-accuracy gain while preserving inference budget, thereby improving the accuracy-compute Pareto frontier relative to static scaling.
Significance. If the central empirical claim holds under rigorous controls, the work would be significant: it offers a practical, post-training intervention that improves factual reliability in already-deployed MoE models without extra compute or retraining. The training-free character and explicit constant-activation-count constraint are notable strengths that distinguish it from scaling or fine-tuning approaches.
major comments (3)
- [§3] §3 (Method), paragraph on virtual ablation and CEI computation: the claim that layer-wise perturbation analysis can be performed while strictly preserving the total activation count is load-bearing for the Pareto-superiority assertion, yet the text supplies no concrete accounting of forward-pass cost, amortization across tokens, or elimination of extra passes. If any per-layer analysis requires even one additional forward pass, the constant-budget guarantee collapses.
- [§4] §4 (Experiments), results on TruthfulQA/FACTOR/TriviaQA: the reported 3.1% average gain is presented without baseline details, number of runs, statistical significance tests, or controls for routing variance. This information is required to evaluate whether the observed improvement is attributable to CEI-guided expert activation rather than incidental routing changes.
- [§3.1] §3.1, definition of CEI: the metric is introduced as identifying 'causally decisive' experts, but no ablation or correlation analysis is shown demonstrating that CEI scores specifically predict long-tail factual recall (as opposed to general performance shifts). This correlation is necessary to support the causal interpretation underlying the method.
minor comments (2)
- [Abstract] Abstract and §1: the phrase 'without increasing the inference budget' is repeated but never quantified (e.g., FLOPs or activation count per token); a single sentence or table entry stating the exact constant activation count used would improve clarity.
- [§3] Notation: the manuscript introduces 'Counterfactual Expert Impact (CEI)' without an explicit equation number or boxed definition; adding Eq. (X) for CEI would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment in detail below, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [§3] §3 (Method), paragraph on virtual ablation and CEI computation: the claim that layer-wise perturbation analysis can be performed while strictly preserving the total activation count is load-bearing for the Pareto-superiority assertion, yet the text supplies no concrete accounting of forward-pass cost, amortization across tokens, or elimination of extra passes. If any per-layer analysis requires even one additional forward pass, the constant-budget guarantee collapses.
Authors: We acknowledge that the original manuscript does not provide a detailed breakdown of the forward-pass costs for the layer-wise perturbation analysis. The virtual ablation is computed by perturbing the router decisions post-forward-pass without requiring additional model evaluations, allowing us to maintain the exact activation count by reallocating the fixed budget of k experts per layer. To fully address this concern and support the constant-budget claim, we will add a dedicated paragraph and pseudocode in §3 explaining the amortization across tokens and confirming zero extra passes. This will include a table comparing the computational profile to standard inference. revision: yes
-
Referee: [§4] §4 (Experiments), results on TruthfulQA/FACTOR/TriviaQA: the reported 3.1% average gain is presented without baseline details, number of runs, statistical significance tests, or controls for routing variance. This information is required to evaluate whether the observed improvement is attributable to CEI-guided expert activation rather than incidental routing changes.
Authors: We agree with the referee that more rigorous experimental details are needed. In the revised manuscript, we will update §4 to report: full baseline comparisons including vanilla Top-k MoE, results averaged over 5 runs with standard deviations, p-values from statistical tests (paired t-test), and a control experiment with random expert reallocation to rule out incidental effects. These changes will allow readers to better assess the source of the 3.1% improvement. revision: yes
-
Referee: [§3.1] §3.1, definition of CEI: the metric is introduced as identifying 'causally decisive' experts, but no ablation or correlation analysis is shown demonstrating that CEI scores specifically predict long-tail factual recall (as opposed to general performance shifts). This correlation is necessary to support the causal interpretation underlying the method.
Authors: We recognize the importance of validating that CEI specifically targets long-tail factual recall. The current text derives CEI from perturbation analysis but lacks supporting ablations. We will revise §3.1 to include correlation plots between CEI scores and factual accuracy on long-tail subsets, as well as an ablation study contrasting CEI-based routing with frequency-based and random routing. This will provide evidence for the causal role in mitigating hallucinations on rare knowledge. revision: yes
Circularity Check
Training-free empirical method with no self-referential derivations or fitted predictions
full rationale
The paper presents CoR as a training-free inference-time framework that uses layer-wise perturbation analysis and the CEI metric to reallocate a fixed activation budget toward dormant experts. The 3.1% factual accuracy gain is reported as an empirical outcome on external benchmarks (TruthfulQA, FACTOR, TriviaQA). No equations, predictions, or first-principles claims are shown to reduce by construction to fitted parameters, self-citations, or renamed inputs. The central claims rest on benchmark measurements rather than tautological definitions or load-bearing self-citations. This is the expected non-circular outcome for a method paper whose value is demonstrated through independent evaluation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Static top-k routing systematically under-activates experts that hold long-tail factual knowledge.
- domain assumption Layer-wise virtual ablation can isolate the causal contribution of individual experts to factual outputs.
invented entities (1)
-
Counterfactual Expert Impact (CEI) metric
no independent evidence
Forward citations
Cited by 1 Pith paper
-
When Are Experts Misrouted? Counterfactual Routing Analysis in Mixture-of-Experts Language Models
Standard top-k routers in MoE language models often select suboptimal routes for difficult tokens, and updating only the final router layer raises pass@K on AIME and HMMT benchmarks across multiple models.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and effi- cient mixture-of-experts language model.Preprint, arXiv:2405.04434. Jesse Dodge, Maarten Sap, Ana Marasovi ´c, William Agnew, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and Matt Gardner. 2021. Documenting large webtext corpora: A case study on the colossal clean crawled corpus.Preprint, arXiv:2104.087...
work page internal anchor Pith review arXiv 2021
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Wentao Hu, Mingkuan Zhao, Shuangyong Song, Xi- aoyan Zhu, Xin Lai, and Jiayin Wang. 2025. Mo- saic pruning: A hierarchical framework for generaliz- able pruning of mixture-of-experts models.Preprint, arXiv:2511.19822. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zha...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
arXiv:2512.24157 [cs.CL] https://arxiv.org/abs/2512.24157
Training report of telechat3-moe.Preprint, arXiv:2512.24157. Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Hajishirzi. 2023. When not to trust language models: Investigating effectiveness of parametric and non-parametric mem- ories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguisti...
-
[4]
gpt-oss-120b & gpt-oss-20b Model Card
Generating benchmarks for factuality evalua- tion of language models. InProceedings of the 18th conference of the european chapter of the associa- tion for computational linguistics (volume 1: Long papers), pages 49–66. OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Ar- bus, Rahul K. Arora, Yu Bai, Bowen Baker, Haim- ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Technical report of telechat2, telechat2.5 and t1.Preprint, arXiv:2507.18013. Hongrui Xing, Xinzhang Liu, Zhuo Jiang, Zhihao Yang, Yitong Yao, Zihan Wang, Wenmin Deng, Chao Wang, Shuangyong Song, Wang Yang, Zhongjiang He, and Yongxiang Li. 2025. LLMSR@XLLM25: A lan- guage model-based pipeline for structured reasoning data construction. InProceedings of th...
-
[6]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
Siren’s song in the ai ocean: A survey on hallucination in large language models.Preprint, arXiv:2309.01219. Deji Zhao, Donghong Han, Jia Wu, Zhongjiang He, Bo Ning, Ye Yuan, Yongxiang Li, Chao Wang, and Shuangyong Song. 2025a. Enhancing math rea- soning ability of large language models via com- putation logic graphs.Knowledge-Based Systems, 325:113905. M...
work page internal anchor Pith review arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.