Recognition: unknown
Reinforcement Learning via Value Gradient Flow
Pith reviewed 2026-05-10 13:14 UTC · model grok-4.3
The pith
Value Gradient Flow reframes behavior-regularized reinforcement learning as an optimal transport problem solved by moving particles with value gradients.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VGF casts behavior-regularized RL as an optimal transport problem that maps the reference distribution to the value-induced optimal policy distribution. We solve this transport problem via discrete gradient flow, where value gradients guide particles initialized from the reference distribution. Our analysis shows that VGF imposes regularization implicitly by controlling the transport budget. VGF eliminates explicit policy parameterization while remaining expressive and flexible.
What carries the argument
Discrete gradient flow on particles guided by value gradients to approximate the optimal transport map from reference distribution to optimal policy distribution.
If this is right
- VGF scales to large generative models by removing the need for reparameterized policy gradients.
- Regularization strength is controlled solely through the transport budget for flexible and adaptive behavior.
- Test-time scaling becomes possible by increasing transport steps without retraining a policy.
- The method outperforms prior approaches on D4RL and OGBench offline RL benchmarks as well as LLM RL tasks.
Where Pith is reading between the lines
- The particle transport view may allow borrowing sampling techniques from generative models to improve convergence in high dimensions.
- Varying the transport budget at deployment time could provide a direct knob for trading compute against policy performance in deployed systems.
- The same framing might apply to other distribution-matching problems in sequential decision making beyond standard RL.
Load-bearing premise
Discrete particle updates driven by value gradients can reliably approximate the optimal transport map, and the transport budget alone suffices to enforce the desired regularization without additional constraints or explicit policy parameterization.
What would settle it
An experiment on a low-dimensional environment with known optimal policy distribution in which particles guided by value gradients converge to a different distribution even after many steps and large budget, or in which performance shows no clear trade-off when budget is varied.
Figures


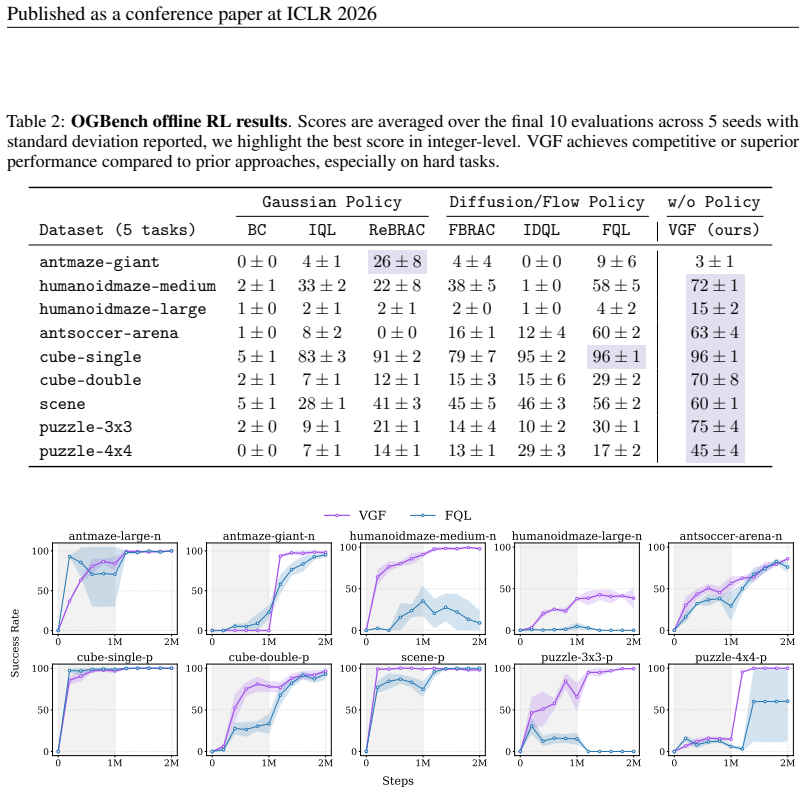
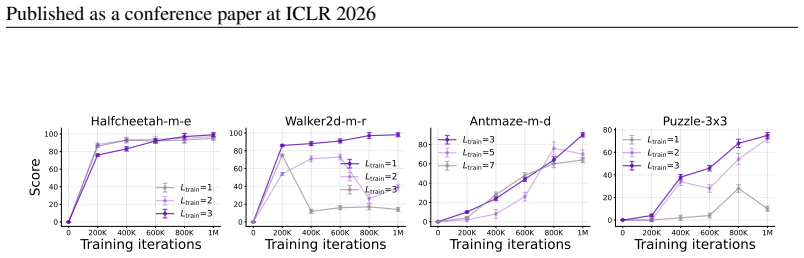
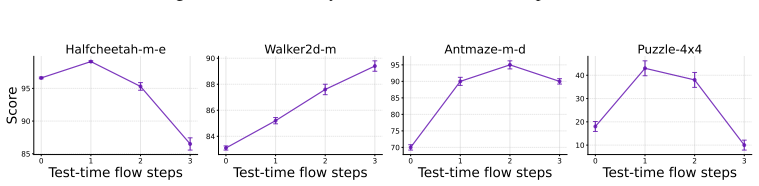


read the original abstract
We study behavior-regularized reinforcement learning (RL), where regularization toward a reference distribution (the dataset in offline RL or the base model in LLM RL finetuning) is essential to prevent value over-optimization caused by erroneous out-of-distribution extrapolation. Existing methods either rely on reparameterized policy gradient, which are difficult to scale to large generative models, or on reject sampling, which can be overly conservative when attempting to move beyond the behavior support. In this paper, we propose Value Gradient Flow (VGF), a scalable new paradigm for behavior-regularized RL. VGF casts behavior-regularized RL as an optimal transport problem that maps the reference distribution to the value-induced optimal policy distribution. We solve this transport problem via discrete gradient flow, where value gradients guide particles initialized from the reference distribution. Our analysis shows that VGF imposes regularization implicitly by controlling the transport budget. VGF eliminates explicit policy parameterization while remaining expressive and flexible, this enables adaptive test-time scaling by adjusting the transport budget. Extensive experiments demonstrate that VGF significantly outperforms prior methods, achieving state-of-the-art results on offline RL benchmarks (D4RL, OGBench) and LLM RL tasks. Code and runs can be found at https://ryanxhr.github.io/vgf.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Value Gradient Flow (VGF) for behavior-regularized RL. It casts the problem as an optimal transport task mapping a reference distribution (dataset or base model) to the value-induced optimal policy distribution, solved by discrete gradient flow where value gradients drive particles initialized from the reference. The central claim is that controlling the transport budget provides implicit regularization, eliminating explicit policy parameterization while remaining expressive; this enables adaptive test-time scaling. Experiments report SOTA results on D4RL, OGBench, and LLM RL finetuning tasks, with code available.
Significance. If the analysis of implicit regularization via the transport budget and the convergence properties of the discrete flow hold, VGF offers a scalable alternative to reparameterized policy gradients or reject sampling for large generative models. It provides a new OT-based paradigm with a single explicit control knob and includes reproducible code, which is a strength for verification.
major comments (3)
- [Abstract and analysis section] Abstract and analysis section: The claim that 'analysis shows that VGF imposes regularization implicitly by controlling the transport budget' is load-bearing for the central contribution. The discrete first-order particle updates driven by approximate value gradients may not preserve the continuous Wasserstein gradient flow properties, and the manuscript must provide explicit bounds or derivations showing that the budget alone prevents out-of-distribution drift without auxiliary constraints.
- [Method section on discrete gradient flow] Method section on discrete gradient flow: The weakest assumption—that value-gradient-driven particle updates reliably approximate the OT map—requires verification under finite data and noisy value estimates. Without showing stability of the flow (e.g., via step-size conditions or projection-free guarantees), the equivalence to behavior-regularized RL may not hold in practice.
- [Experiments section] Experiments section: SOTA claims on D4RL and OGBench are reported, but the manuscript lacks detailed ablation on particle count, step size, and gradient estimation noise; these are critical because any mismatch with the continuous OT formulation could undermine the implicit-regularization claim.
minor comments (2)
- [Abstract] The code link is provided but the paper should specify the exact repository commit or version tag to ensure reproducibility of the reported runs.
- [Method] Notation for the transport budget and particle initialization should be introduced with a clear equation early in the method section to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important points about the theoretical grounding of the discrete flow and the strength of the empirical support. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract and analysis section] Abstract and analysis section: The claim that 'analysis shows that VGF imposes regularization implicitly by controlling the transport budget' is load-bearing for the central contribution. The discrete first-order particle updates driven by approximate value gradients may not preserve the continuous Wasserstein gradient flow properties, and the manuscript must provide explicit bounds or derivations showing that the budget alone prevents out-of-distribution drift without auxiliary constraints.
Authors: We agree that the implicit-regularization claim requires stronger support than currently provided. The manuscript contains a high-level argument linking the transport budget to a Wasserstein-ball constraint around the reference, but it does not yet contain explicit finite-step bounds that survive approximate value gradients. In the revision we will add a dedicated subsection deriving a bound on the Wasserstein-2 distance between the particle distribution after T steps and the reference, showing that this distance is controlled by the cumulative budget parameter even under bounded gradient noise. The derivation will rely on a discrete Gronwall-type inequality adapted to the value-gradient flow. revision: yes
-
Referee: [Method section on discrete gradient flow] Method section on discrete gradient flow: The weakest assumption—that value-gradient-driven particle updates reliably approximate the OT map—requires verification under finite data and noisy value estimates. Without showing stability of the flow (e.g., via step-size conditions or projection-free guarantees), the equivalence to behavior-regularized RL may not hold in practice.
Authors: The current method section presents the discrete update as a first-order Euler discretization of the continuous Wasserstein gradient flow but does not supply step-size restrictions or stability guarantees under noisy value estimates. We will revise the section to include (i) a sufficient condition on the step size relative to the Lipschitz constant of the value function that guarantees non-expansiveness of the map, and (ii) an empirical stability plot (already present in the appendix) that we will promote to the main text showing that the particle trajectories remain within the support of the reference for the chosen hyper-parameters across the reported benchmarks. revision: partial
-
Referee: [Experiments section] Experiments section: SOTA claims on D4RL and OGBench are reported, but the manuscript lacks detailed ablation on particle count, step size, and gradient estimation noise; these are critical because any mismatch with the continuous OT formulation could undermine the implicit-regularization claim.
Authors: We accept that the current experimental section does not contain systematic ablations on these three axes. In the revision we will add a new table (and corresponding figures) that varies particle count (from 10^3 to 10^5), step size (over an order of magnitude), and value-estimate noise level (by injecting controlled Gaussian noise into the critic). These ablations will be reported on the same D4RL and OGBench tasks used for the main results, together with a short discussion of the regime in which the implicit-regularization effect remains intact. revision: yes
Circularity Check
No significant circularity; derivation applies standard OT theory independently
full rationale
The paper frames behavior-regularized RL as an optimal transport problem between a reference distribution and a value-induced target, then solves it with discrete particle updates driven by value gradients while controlling the transport budget for implicit regularization. This construction draws on established Wasserstein gradient flow results and does not reduce any central claim to a quantity defined by the paper's own equations or to a self-citation chain. The analysis of implicit regularization follows directly from the OT formulation and budget constraint rather than from fitted parameters or renamed empirical patterns. No load-bearing step collapses to self-definition or fitted-input-as-prediction.
Axiom & Free-Parameter Ledger
free parameters (1)
- transport budget
axioms (2)
- domain assumption Value gradients can be used to define a potential that drives particles toward higher-value regions in distribution space.
- standard math Discrete gradient flow on particles approximates the solution to the underlying optimal transport problem.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.06863 , year=
Bhavya Agrawalla, Michal Nauman, Khush Agrawal, and Aviral Kumar. floq: Training critics via flow-matching for scaling compute in value-based rl. arXiv preprint arXiv:2509.06863, 2025
-
[2]
(2005).Gradient Flows in Metric Spaces and in the Space of Probability Measures
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savar \'e . Gradient Flows: In Metric Spaces and in the Space of Probability Measures. Birkh \"a user, Basel, 2nd edition, 2008. doi:10.1007/978-3-7643-8722-8
-
[3]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Man \'e . Concrete problems in ai safety. arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review arXiv 2016
-
[4]
Rethinking optimal transport in offline reinforcement learning
Arip Asadulaev, Rostislav Korst, Aleksandr Korotin, Vage Egiazarian, Andrey Filchenkov, and Evgeny Burnaev. Rethinking optimal transport in offline reinforcement learning. Advances in Neural Information Processing Systems, 37: 0 123592--123607, 2024
2024
-
[5]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, et al. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Theoretical guarantees on the best-of-n alignment policy
Ahmad Beirami, Alekh Agarwal, Jonathan Berant, Alexander D'Amour, Jacob Eisenstein, Chirag Nagpal, and Ananda Theertha Suresh. Theoretical guarantees on the best-of-n alignment policy. arXiv preprint arXiv:2401.01879, 2024
-
[7]
Infinite time horizon maximum causal entropy inverse reinforcement learning
Michael Bloem and Nicholas Bambos. Infinite time horizon maximum causal entropy inverse reinforcement learning. In Proceedings of the 53rd IEEE Conference on Decision and Control (CDC), pp.\ 4911--4916, 2014. doi:10.1109/CDC.2014.7040156
-
[8]
Rank analysis of incomplete block designs: I
Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39 0 (3/4): 0 324--345, 1952
1952
-
[9]
Offline reinforcement learning via high-fidelity generative behavior modeling
Huayu Chen, Cheng Lu, Chengyang Ying, Hang Su, and Jun Zhu. Offline reinforcement learning via high-fidelity generative behavior modeling. In International Conference on Learning Representations (ICLR), 2023
2023
-
[10]
Decision transformer: Reinforcement learning via sequence modeling
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. Proc. of NeurIPS, 2021
2021
-
[11]
Reward model ensembles help mitigate overoptimization.arXiv preprint arXiv:2310.02743, 2023
Thomas Coste, Usman Anwar, Robert Kirk, and David Krueger. Reward model ensembles help mitigate overoptimization. arXiv preprint arXiv:2310.02743, 2023. URL https://arxiv.org/abs/2310.02743
-
[12]
Bellemare, and R \'e mi Munos
Will Dabney, Mark Rowland, Marc G. Bellemare, and R \'e mi Munos. Distributional reinforcement learning with quantile regression. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[13]
Primal wasserstein imitation learning
Robert Dadashi, L \'e onard Hussenot, Matthieu Geist, and Olivier Pietquin. Primal wasserstein imitation learning. In International Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/pdf?id=TtYSU29zgR
2021
-
[14]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025. doi:10.48550/arXiv.2501.12948. URL https://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[15]
Zihan Ding and Chi Jin. Consistency models as a rich and efficient policy class for reinforcement learning. arXiv preprint arXiv:2309.16984, 2023
-
[16]
arXiv preprint arXiv:2510.07650 , year=
Perry Dong, Chongyi Zheng, Chelsea Finn, Dorsa Sadigh, and Benjamin Eysenbach. Value flows. arXiv preprint arXiv:2510.07650, 2025
-
[17]
Perry Dong, Kuo-Han Hung, Alexander Swerdlow, Dorsa Sadigh, and Chelsea Finn. Tql: Scaling q-functions with transformers by preventing attention collapse. arXiv preprint arXiv:2602.01439, 2026
-
[18]
Maximum entropy RL (provably) solves some robust RL problems
Benjamin Eysenbach and Sergey Levine. Maximum entropy rl (provably) solves some robust rl problems. arXiv preprint arXiv:2103.06257, 2021
-
[19]
Kevin Frans, Seohong Park, Pieter Abbeel, and Sergey Levine. Diffusion guidance is a controllable policy improvement operator. arXiv preprint arXiv:2505.23458, 2025
-
[20]
D4rl: Datasets for deep data-driven reinforcement learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning. ArXiv preprint, 2020
2020
-
[21]
A minimalist approach to offline reinforcement learning
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning. ArXiv preprint, 2021
2021
-
[22]
Off-policy deep reinforcement learning without exploration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without exploration. In Proc. of ICML, pp.\ 2052--2062, 2019
2052
-
[23]
Scalinglawsforrewardmodeloveroptimization,2022
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, 2023. URL https://proceedings.mlr.press/v202/gao23h.html. See also arXiv:2210.10760
-
[24]
Iq-learn: Inverse soft-q learning for imitation
Divyansh Garg, Shuvam Chakraborty, Chris Cundy, Jiaming Song, and Stefano Ermon. Iq-learn: Inverse soft-q learning for imitation. Advances in Neural Information Processing Systems, 34: 0 4028--4039, 2021
2021
-
[25]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. In Proc. of ICML, pp.\ 1352--1361, 2017
2017
-
[26]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In Proc. of ICML, pp.\ 1856--1865, 2018
2018
-
[27]
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. Idql: Implicit q-learning as an actor-critic method with diffusion policies. arXiv preprint arXiv:2304.10573, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[29]
The variational formulation of the fokker–planck equation
Richard Jordan, David Kinderlehrer, and Felix Otto. The variational formulation of the fokker–planck equation. SIAM Journal on Mathematical Analysis, 29 0 (1): 0 1--17, 1998. doi:10.1137/S0036141096303359
-
[30]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Proc. of ICLR, 2015
2015
-
[31]
Tomasz Korbak, Ethan Perez, and Christopher L Buckley. Rl with kl penalties is better viewed as bayesian inference. arXiv preprint arXiv:2205.11275, 2022
-
[32]
Offline reinforcement learning with fisher divergence critic regularization
Ilya Kostrikov, Rob Fergus, Jonathan Tompson, and Ofir Nachum. Offline reinforcement learning with fisher divergence critic regularization. In Proc. of ICML, pp.\ 5774--5783, 2021 a
2021
-
[33]
Offline reinforcement learning with implicit q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. ArXiv preprint, 2021 b
2021
-
[34]
Solomon Kullback and Richard A. Leibler. On information and sufficiency. Annals of Mathematical Statistics, 22 0 (1): 0 79--86, 1951. doi:10.1214/aoms/1177729694
-
[35]
Stabilizing off-policy q-learning via bootstrapping error reduction
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. In Proc. of NeurIPS, pp.\ 11761--11771, 2019
2019
-
[36]
Conservative q-learning for offline reinforcement learning
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Proc. of NeurIPS, 2020
2020
-
[37]
End-to-end training of deep visuomotor policies
Sergey Levine, Chelsea Finn, Trevor Darrell, and Pieter Abbeel. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 2016
2016
-
[38]
Q-learning with adjoint matching,
Qiyang Li and Sergey Levine. Q-learning with adjoint matching. arXiv preprint arXiv:2601.14234, 2026
work page internal anchor Pith review arXiv 2026
-
[39]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[40]
Stein variational gradient descent as gradient flow
Qiang Liu. Stein variational gradient descent as gradient flow. Advances in neural information processing systems, 30, 2017
2017
-
[41]
Stein variational gradient descent: A general purpose bayesian inference algorithm
Qiang Liu and Dilin Wang. Stein variational gradient descent: A general purpose bayesian inference algorithm. Advances in neural information processing systems, 29, 2016
2016
-
[42]
Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning
Liyuan Mao, Haoran Xu, Weinan Zhang, Xianyuan Zhan, and Amy Zhang. Diffusion-dice: In-sample diffusion guidance for offline reinforcement learning. arXiv preprint arXiv:2407.20109, 2024
-
[43]
Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone,
Max Sobol Mark, Tian Gao, Georgia Gabriela Sampaio, Mohan Kumar Srirama, Archit Sharma, Chelsea Finn, and Aviral Kumar. Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone. arXiv preprint arXiv:2412.06685, 2024
-
[44]
Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, and Martin Riedmiller. Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013
work page internal anchor Pith review arXiv 2013
-
[45]
Ted Moskovitz, Aaditya K. Singh, DJ Strouse, Tuomas Sandholm, Ruslan Salakhutdinov, Anca D. Dragan, and Stephen McAleer. Confronting reward model overoptimization with constrained rlhf. In International Conference on Learning Representations, 2024. URL https://arxiv.org/abs/2310.04373
-
[46]
Bridging the gap between value and policy based reinforcement learning
Ofir Nachum, Mohammad Norouzi, Kelvin Xu, and Dale Schuurmans. Bridging the gap between value and policy based reinforcement learning. In Proc. of NeurIPS, pp.\ 2775--2785, 2017
2017
-
[47]
Accelerating online reinforcement learning with offline datasets
Ashvin Nair, Murtaza Dalal, Abhishek Gupta, and Sergey Levine. Accelerating online reinforcement learning with offline datasets. ArXiv preprint, 2020
2020
-
[48]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021
work page internal anchor Pith review arXiv 2021
-
[49]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review arXiv 2022
-
[50]
Reward gaming in conditional text generation
Richard Yuanzhe Pang, Vishakh Padmakumar, Thibault Sellam, Ankur Parikh, and He He. Reward gaming in conditional text generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pp.\ 4746--4763. Association for Computational Linguistics, 2023. doi:10.18653/v1/2023.acl-long.262
-
[51]
Ogbench: Benchmarking offline goal-conditioned rl
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. Ogbench: Benchmarking offline goal-conditioned rl. In International Conference on Learning Representations (ICLR), 2025 a
2025
-
[52]
Flow Q - Learning , May 2025 c
Seohong Park, Qiyang Li, and Sergey Levine. Flow q-learning. arXiv preprint arXiv:2502.02538, 2025 b
-
[53]
Advantage-weighted regression: Simple and scalable off-policy reinforcement learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning. ArXiv preprint, 2019
2019
-
[54]
Computational optimal transport.Found
Gabriel Peyr \'e and Marco Cuturi. Computational Optimal Transport, volume 11. Foundations and Trends in Machine Learning, 2019. doi:10.1561/2200000073
-
[55]
Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752,
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching. arXiv preprint arXiv:2312.11752, 2023
-
[56]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y. K. Li, Y. Wu, Daya Guo, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024. URL https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Mastering the game of go without human knowledge
David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human knowledge. nature, 2017
2017
-
[58]
Defining and characterizing reward hacking
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characterizing reward hacking. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/3d719fee332caa23d5038b8a90e81796-Abstract-Conference.html
2022
-
[59]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[60]
Maximum likelihood training of score-based diffusion models
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum likelihood training of score-based diffusion models. Advances in neural information processing systems, 34: 0 1415--1428, 2021
2021
-
[61]
Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[62]
Introduction to reinforcement learning
Richard S Sutton, Andrew G Barto, et al. Introduction to reinforcement learning. MIT press Cambridge, 1998
1998
-
[63]
Revisiting the minimalist approach to offline reinforcement learning
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning. In NeurIPS, 2023
2023
-
[64]
Revisiting the minimalist approach to offline reinforcement learning
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. Revisiting the minimalist approach to offline reinforcement learning. Advances in Neural Information Processing Systems, 36, 2024
2024
-
[65]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Aur \'e lien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023. doi:10.48550/arXiv.2...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[66]
Binghai Wang, Rui Zheng, Lu Chen, Yan Liu, Shihan Dou, Caishuang Huang, Senjie Jin, Enyu Zhou, Chenyu Shi, Songyang Gao, Nuo Xu, Yuhao Zhou, Xiaoran Fan, Zhiheng Xi, Jun Zhao, Xiao Wang, Tao Ji, Hang Yan, Lixing Shen, Zhan Chen, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. Secrets of rlhf in large language models part ii: R...
-
[67]
Offline multi-agent reinforcement learning with implicit global-to-local value regularization
Xiangsen Wang, Haoran Xu, Yinan Zheng, and Xianyuan Zhan. Offline multi-agent reinforcement learning with implicit global-to-local value regularization. In Thirty-seventh Conference on Neural Information Processing Systems, 2023 a
2023
-
[68]
Diffusion policies as an expressive policy class for offline reinforcement learning
Zhendong Wang, Jonathan J Hunt, and Mingyuan Zhou. Diffusion policies as an expressive policy class for offline reinforcement learning. In International Conference on Learning Representations (ICLR), 2023 b
2023
-
[69]
Reed, Bobak Shahriari, Noah Y
Ziyu Wang, Alexander Novikov, Konrad Zolna, Josh Merel, Jost Tobias Springenberg, Scott E. Reed, Bobak Shahriari, Noah Y. Siegel, C aglar G \" u l c ehre, Nicolas Heess, and Nando de Freitas. Critic regularized regression. In Proc. of NeurIPS, 2020
2020
-
[70]
arXiv preprint arXiv:2507.14843 , year=
Fang Wu, Weihao Xuan, Ximing Lu, Zaid Harchaoui, and Yejin Choi. The invisible leash: Why rlvr may not escape its origin. arXiv preprint arXiv:2507.14843, 2025
-
[71]
Behavior regularized offline reinforcement learning
Yifan Wu, George Tucker, and Ofir Nachum. Behavior regularized offline reinforcement learning. ArXiv preprint, 2019
2019
-
[72]
Haoran Xu, Li Jiang, Jianxiong Li, Zhuoran Yang, Zhaoran Wang, Victor Wai Kin Chan, and Xianyuan Zhan. Offline rl with no ood actions: In-sample learning via implicit value regularization. arXiv preprint arXiv:2303.15810, 2023
-
[73]
An optimal discriminator weighted imitation perspective for reinforcement learning
Haoran Xu, Shuozhe Li, Harshit Sikchi, Scott Niekum, and Amy Zhang. An optimal discriminator weighted imitation perspective for reinforcement learning. arXiv preprint arXiv:2504.13368, 2025 a
-
[74]
Uni-rl: Unifying online and offline rl via implicit value regularization
Haoran Xu, Liyuan Mao, Hui Jin, Weinan Zhang, Xianyuan Zhan, and Amy Zhang. Uni-rl: Unifying online and offline rl via implicit value regularization. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b
2025
-
[75]
Asymptotics of language model alignment
Joy Qiping Yang, Salman Salamatian, Ziteng Sun, Ananda Theertha Suresh, and Ahmad Beirami. Asymptotics of language model alignment. In 2024 IEEE International Symposium on Information Theory (ISIT), pp.\ 2027--2032. IEEE, 2024
2024
-
[76]
arXiv preprint arXiv:2305.13122 , year=
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning. arXiv preprint arXiv:2305.13122, 2023
-
[77]
Brian D. Ziebart. Modeling Purposeful Adaptive Behavior with the Principle of Maximum Causal Entropy. PhD thesis, Carnegie Mellon University, Pittsburgh, PA, 2010. CMU-ML-10-110
2010
-
[78]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[79]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[80]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.