Recognition: unknown
Timescale Separation Enables Deep Reinforcement Learning Control of Rotating Detonation Engine Mode Transitions
Pith reviewed 2026-05-10 11:40 UTC · model grok-4.3
The pith
Moving reference frame reformulation enables reliable deep reinforcement learning control of rotating detonation engine modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
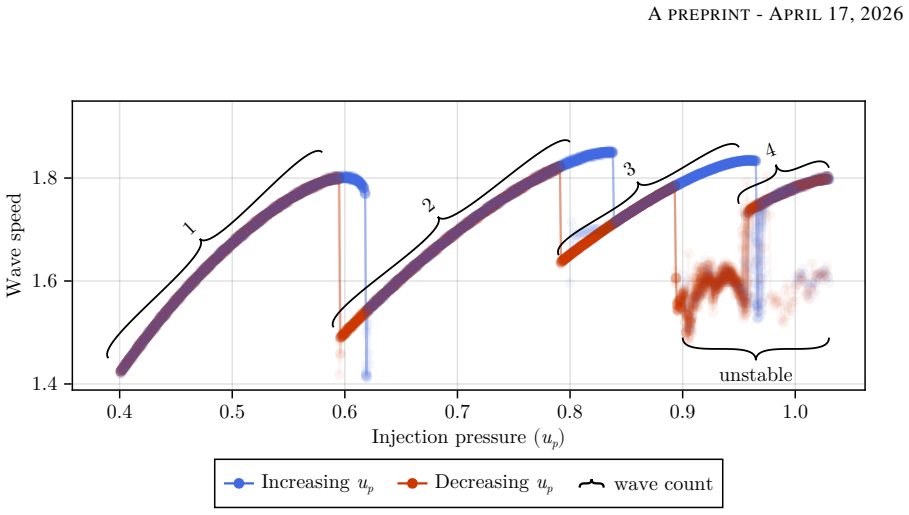
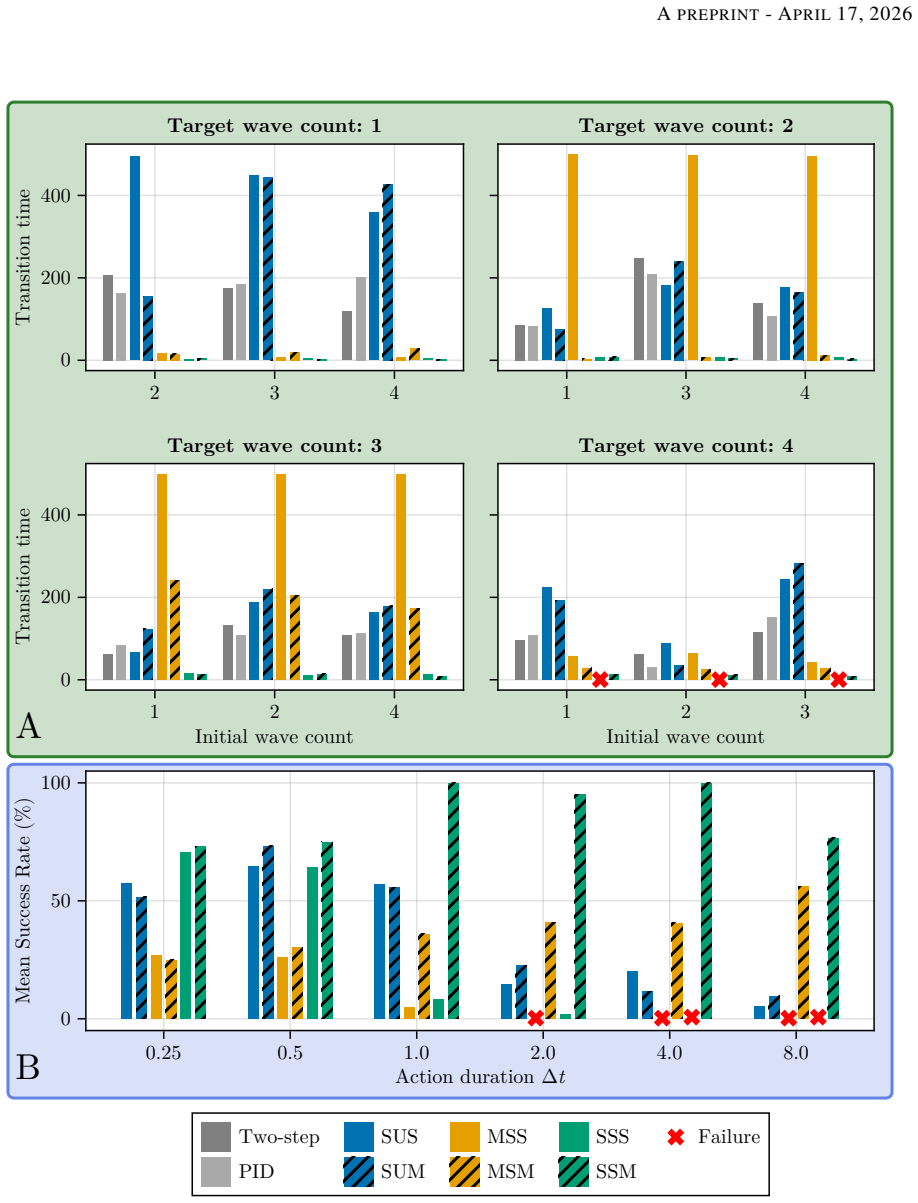
By reformulating the DRL problem in a moving reference frame that follows the detonation-wave pattern, making the wave structure appear quasi-steady to the agent, this enables scale separation between fast detonation propagation and slower operating-mode dynamics. Controllers trained this way modulate spatially segmented injection pressure in a one-dimensional reduced-order RDE model to induce rapid transitions between different mode-locked states. Across a range of actuation periods, initial states, and target modes, controllers trained in the moving frame learn more reliably than those trained in a stationary frame and remain effective over a broader range of actuation periods.
What carries the argument
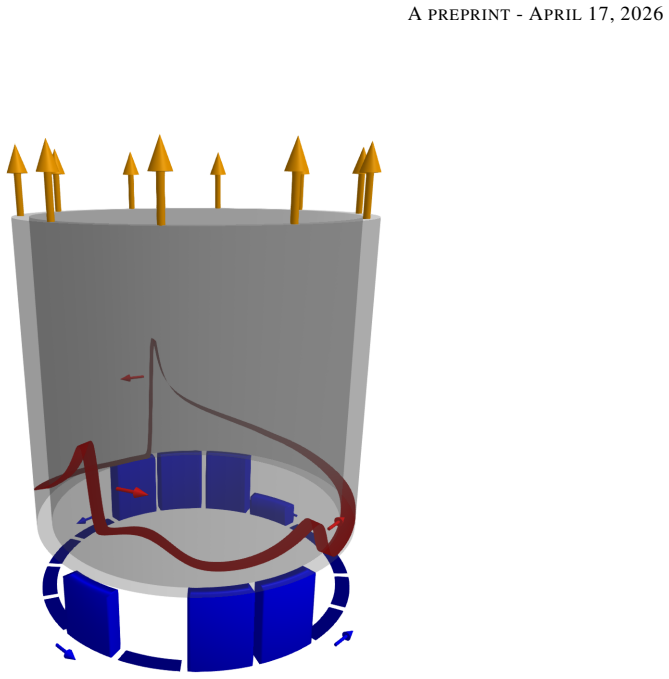
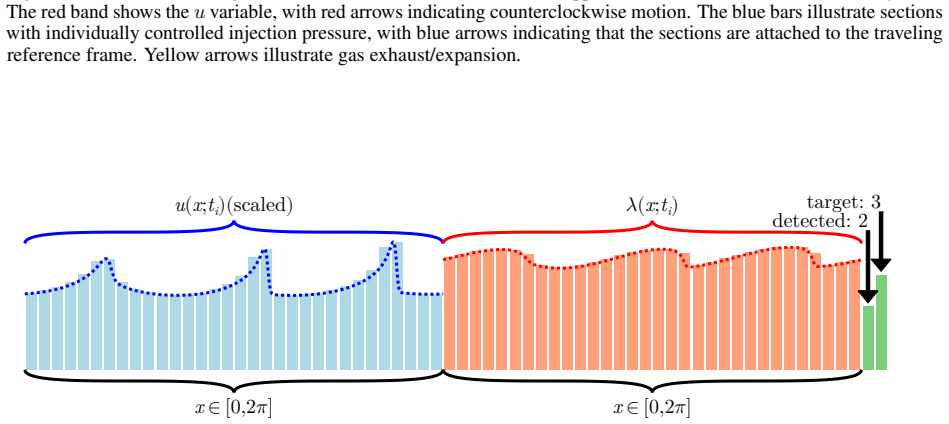
The moving reference frame reformulation that follows the detonation-wave pattern, which separates fast detonation propagation from slower operating-mode dynamics by rendering the wave structure quasi-steady to the learning agent.
Load-bearing premise
The one-dimensional reduced-order model accurately captures the essential nonlinear dynamics and mode-transition behavior of real three-dimensional rotating detonation engines.
What would settle it
Running the trained moving-frame and stationary-frame controllers on a three-dimensional rotating detonation engine simulation and measuring which set achieves higher rates of successful, rapid mode transitions across varied initial conditions and actuation periods.
Figures




read the original abstract
Rotating detonation engines (RDEs) are a promising propulsion concept that may offer higher thermodynamic efficiency and specific impulse than conventional systems, but nonlinear phenomena, including transitions to oscillatory or chaotic propagation modes, can hinder practical operation. Deep Reinforcement Learning (DRL) has emerged as a promising method for controlling complex nonlinear dynamics such as those observed in RDEs. However, the multi-timescale nature of the RDE system makes direct application of DRL challenging. We address this challenge by reformulating the DRL problem in a moving reference frame that follows the detonation-wave pattern, making the wave structure appear quasi-steady to the agent. This reformulation enables scale separation between fast detonation propagation and slower operating-mode dynamics. We train DRL controllers to modulate spatially segmented injection pressure in a one-dimensional reduced-order RDE model and induce rapid transitions between different mode-locked states. Across a range of actuation periods, initial states, and target modes, controllers trained in the moving frame learn more reliably than those trained in a stationary frame and remain effective over a broader range of actuation periods. These results suggest that symmetry-aware moving reference frame formulations may be useful for related multiscale flow-control problems and that scale separation should be exploited whenever possible to enable DRL control of multi-timescale systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that reformulating deep reinforcement learning (DRL) control of rotating detonation engine (RDE) mode transitions in a moving reference frame attached to the detonation wave achieves timescale separation between fast wave propagation and slower mode dynamics. In a one-dimensional reduced-order RDE model, this enables controllers to modulate segmented injection pressure for rapid transitions between mode-locked states; moving-frame agents learn more reliably and remain effective over a wider range of actuation periods and initial conditions than stationary-frame agents.
Significance. If the 1D results generalize, the symmetry-aware moving-frame formulation offers a practical route to applying DRL to other multi-timescale fluid systems by exploiting invariance. The direct use of simulation-based training provides a reproducible experimental protocol, but the absence of quantitative performance metrics and higher-fidelity validation restricts the immediate engineering significance for real RDE hardware.
major comments (2)
- [Abstract] Abstract and results: the central claim that moving-frame controllers 'learn more reliably' and 'remain effective over a broader range of actuation periods' is stated without any quantitative metrics (success rates, training curves, convergence statistics, or error bars), statistical tests, or tabulated comparisons, leaving the strength of evidence for the reported advantage unassessable.
- [Model and Results] Model formulation and results sections: all reported training reliability and mode-transition success are obtained exclusively inside the one-dimensional reduced-order RDE model; no comparison of mode-locked states, transition thresholds, or wave speeds against 2D/3D simulations or experiments is provided, rendering the modeling assumption that the 1D formulation captures the essential nonlinear dynamics load-bearing for the conclusions.
minor comments (2)
- [Abstract] The abstract does not specify the numerical range of actuation periods tested or the DRL algorithm and state/action representations employed.
- [Methods] Figure captions and text should clarify how the moving-frame transformation is implemented numerically and whether any additional filtering or state estimation is required for the agent.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major point below and have revised the manuscript to strengthen the evidence and clarify limitations where possible.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: the central claim that moving-frame controllers 'learn more reliably' and 'remain effective over a broader range of actuation periods' is stated without any quantitative metrics (success rates, training curves, convergence statistics, or error bars), statistical tests, or tabulated comparisons, leaving the strength of evidence for the reported advantage unassessable.
Authors: We agree that the original presentation would benefit from explicit quantitative support. In the revised manuscript, we have added success rates (fraction of converged trainings across random seeds), mean reward curves with standard deviation bands from multiple independent runs, tabulated performance metrics (e.g., transition time, success percentage) for varying actuation periods and initial conditions, and statistical significance tests comparing moving-frame versus stationary-frame agents. These additions directly substantiate the claims of improved reliability and broader effectiveness. revision: yes
-
Referee: [Model and Results] Model formulation and results sections: all reported training reliability and mode-transition success are obtained exclusively inside the one-dimensional reduced-order RDE model; no comparison of mode-locked states, transition thresholds, or wave speeds against 2D/3D simulations or experiments is provided, rendering the modeling assumption that the 1D formulation captures the essential nonlinear dynamics load-bearing for the conclusions.
Authors: The one-dimensional model is a standard reduced-order framework in the RDE literature that isolates the essential wave propagation, injection coupling, and mode-locking dynamics. We have expanded the model section with additional citations to prior studies validating its use for these phenomena and added a dedicated limitations paragraph in the conclusions that explicitly discusses the 1D assumptions and the need for future higher-fidelity validation. Direct 2D/3D comparisons are not feasible within the present scope due to computational cost, but the revised text clarifies that the reported results are specific to this modeling level. revision: partial
- Direct quantitative comparisons of mode-locked states, transition thresholds, and wave speeds against 2D/3D simulations or experiments, as these lie outside the scope of the current 1D-focused study.
Circularity Check
No circularity; results from direct simulation experiments in 1D model
full rationale
The paper demonstrates DRL controller performance (moving-frame vs stationary-frame reliability and actuation-period robustness) exclusively through numerical experiments inside a one-dimensional reduced-order RDE model. The moving-frame reformulation is introduced as an independent modeling choice that exploits timescale separation; no derivation, equation, or claim reduces to a fitted parameter, self-definition, or load-bearing self-citation. All reported outcomes are obtained by running the trained policies on the model, not by algebraic construction from the inputs.
Axiom & Free-Parameter Ledger
free parameters (2)
- DRL training hyperparameters
- Actuation period range
axioms (2)
- domain assumption The 1D reduced-order model captures the essential nonlinear phenomena and mode transitions of RDEs.
- domain assumption The moving reference frame transformation decouples fast detonation propagation from slower mode dynamics without altering the underlying control problem.
Reference graph
Works this paper leans on
-
[1]
Analysis of Development Trends for Rotating Detonation Engines Based on Experimental Studies.Aerospace, 11(7):570, July 2024
Min-Sik Yun, Tae-Seong Roh, and Hyoung Jin Lee. Analysis of Development Trends for Rotating Detonation Engines Based on Experimental Studies.Aerospace, 11(7):570, July 2024. ISSN 2226-4310. doi: 10.3390/ aerospace11070570
2024
-
[2]
Detonative propulsion.Proceedings of the Combustion Institute, 34(1):125–158, 2013
Piotr Wola´nski. Detonative propulsion.Proceedings of the Combustion Institute, 34(1):125–158, 2013. ISSN 15407489. doi: 10.1016/j.proci.2012.10.005
-
[3]
Heister, John Smallwood, Alexis Harroun, Kevin Dille, Ariana Martinez, and Nathan Ballintyn
Stephen D. Heister, John Smallwood, Alexis Harroun, Kevin Dille, Ariana Martinez, and Nathan Ballintyn. Rotating Detonation Combustion for Advanced Liquid Propellant Space Engines.Aerospace, 9(10), October 2022. ISSN 2226-4310. doi: 10.3390/aerospace9100581
-
[4]
Eric M. Braun, Frank K. Lu, Donald R. Wilson, and José A. Camberos. Airbreathing rotating detonation wave engine cycle analysis.Aerospace Science and Technology, 27(1):201–208, June 2013. ISSN 1270-9638. doi: 10.1016/j.ast.2012.08.010
-
[5]
Qiaodong Bai, Jiaxiang Han, Han Qiu, Shijian Zhang, and Chunsheng Weng. Study on initiation charac- teristics of rotating detonation by auto-initiation and pre-detonation method with high-temperature hydro- gen gas.International Journal of Hydrogen Energy, 49:450–461, January 2024. ISSN 0360-3199. doi: 10.1016/j.ijhydene.2023.08.138
-
[6]
Venkat Raman, Supraj Prakash, and Mirko Gamba. Nonidealities in Rotating Detonation Engines.Annual Review of Fluid Mechanics, 55(V olume 55, 2023):639–674, January 2023. ISSN 0066-4189, 1545-4479. doi: 10.1146/annurev-fluid-120720-032612
-
[7]
Keisuke Goto, Ken Matsuoka, Koichi Matsuyama, Akira Kawasaki, Hiroaki Watanabe, Noboru Itouyama, Kazuki Ishihara, Valentin Buyakofu, Tomoyuki Noda, Jiro Kasahara, Akiko Matsuo, Ikkoh Funaki, Daisuke Nakata, Masaharu Uchiumi, Hiroto Habu, Shinsuke Takeuchi, Satoshi Arakawa, Junichi Masuda, Kenji Maehara, Tatsuro Nakao, and Kazuhiko Yamada. Space Flight Dem...
-
[8]
Development of Gasturbine with Detonation Chamber
Piotr Wola´nski, Piotr Kalina, Włodzimierz Balicki, Artur Rowi´nski, Witold Perkowski, Michał Kawalec, and Borys Łukasik. Development of Gasturbine with Detonation Chamber. In Jiun-Ming Li, Chiang Juay Teo, Boo Cheong Khoo, Jian-Ping Wang, and Cheng Wang, editors,Detonation Control for Propulsion: Pulse Detonation and Rotating Detonation Engines, pages 23...
-
[9]
Jorge Sousa, Guillermo Paniagua, and Elena Collado Morata. Thermodynamic analysis of a gas turbine engine with a rotating detonation combustor.Applied Energy, 195:247–256, June 2017. ISSN 0306-2619. doi: 10.1016/j.apenergy.2017.03.045
-
[10]
Li Deng, Hu Ma, Can Xu, Xiao Liu, and Changsheng Zhou. The feasibility of mode control in rotating detonation engine.Applied Thermal Engineering, 129:1538–1550, January 2018. ISSN 1359-4311. doi: 10.1016/j.applthermaleng.2017.10.146
-
[11]
Xingkui Yang, Feilong Song, Yun Wu, and Jianping Zhou. Experimental study of mode control in rotating detonation combustor using Tesla valve mode control configuration fueled by kerosene.Experimental Thermal and Fluid Science, 151:111075, February 2024. ISSN 0894-1777. doi: 10.1016/j.expthermflusci.2023.111075
-
[12]
Zhaohua Sheng, Miao Cheng, Dawen Shen, and Jian-Ping Wang. An active direction control method in rotating detonation combustor.International Journal of Hydrogen Energy, 47(55):23427–23443, June 2022. ISSN 0360-3199. doi: 10.1016/j.ijhydene.2022.05.135
-
[13]
Guangyao Rong, Miao Cheng, Zhaohua Sheng, Xiangyang Liu, Yunzhen Zhang, and Jianping Wang. Investigation of counter-rotating shock wave and wave direction control of hollow rotating detonation engine with Laval nozzle. Physics of Fluids, 34(5):056104, May 2022. ISSN 1070-6631. doi: 10.1063/5.0089207
-
[14]
Paul Garnier, Jonathan Viquerat, Jean Rabault, Aurélien Larcher, Alexander Kuhnle, and Elie Hachem. A review on deep reinforcement learning for fluid mechanics.Computers & Fluids, 225:104973, July 2021. ISSN 0045-7930. doi: 10.1016/j.compfluid.2021.104973
-
[15]
C. Vignon, J. Rabault, and R. Vinuesa. Recent advances in applying deep reinforcement learning for flow control: Perspectives and future directions.Physics of Fluids, 35(3):031301, March 2023. ISSN 1070-6631. doi: 10.1063/5.0143913
-
[16]
J. Rabault, Pol Suarez, Francisco Alcántara Ávila, Luca Guastoni, Joel Vasanth, and Ricardo Vinuesa.Deep Reinforcement Learning for Active Flow Control: Where Do We Stand, and What Are the Perspectives for Future Use in Physics and Fluid Mechanics?November 2023. doi: 10.13140/RG.2.2.26313.93289. 19 APREPRINT- APRIL17, 2026
-
[17]
Jean Rabault, Miroslav Kuchta, Atle Jensen, Ulysse Réglade, and Nicolas Cerardi. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control.Journal of Fluid Mechanics, 865:281–302, April 2019. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2019.62
-
[18]
Hongwei Tang, Jean Rabault, Alexander Kuhnle, Yan Wang, and Tongguang Wang. Robust active flow control over a range of Reynolds numbers using an artificial neural network trained through deep reinforcement learning. Physics of Fluids, 32(5):053605, May 2020. ISSN 1070-6631. doi: 10.1063/5.0006492
-
[19]
Feng Ren, Jean Rabault, and Hui Tang. Applying deep reinforcement learning to active flow control in weakly turbulent conditions.Physics of Fluids, 33(3):037121, March 2021. ISSN 1070-6631. doi: 10.1063/5.0037371
-
[20]
Wenjie Chen, Qiulei Wang, Lei Yan, Gang Hu, and Bernd R. Noack. Deep reinforcement learning-based active flow control of vortex-induced vibration of a square cylinder.Physics of Fluids, 35(5):053610, May 2023. ISSN 1070-6631. doi: 10.1063/5.0152777
-
[21]
Lei Yan, Yuerong Li, Gang Hu, Wen-li Chen, Wei Zhong, and Bernd R. Noack. Stabilizing the square cylinder wake using deep reinforcement learning for different jet locations.Physics of Fluids, 35(11):115104, November
- [22]
-
[23]
Lei Yan, Xingming Zhang, Jie Song, and Gang Hu. Active flow control of square cylinder adaptive to wind direction using deep reinforcement learning.Physical Review Fluids, 9(9):094607, September 2024. doi: 10.1103/PhysRevFluids.9.094607
-
[24]
Active Flow Control for Drag Reduction Through Multi-agent Reinforcement Learning on a Turbulent Cylinder at $$Re_D=3900$$.Flow, Turbulence and Combustion, March 2025
Pol Suárez, Francisco Alcántara-Ávila, Arnau Miró, Jean Rabault, Bernat Font, Oriol Lehmkuhl, and Ricardo Vinuesa. Active Flow Control for Drag Reduction Through Multi-agent Reinforcement Learning on a Turbulent Cylinder at $$Re_D=3900$$.Flow, Turbulence and Combustion, March 2025. ISSN 1573-1987. doi: 10.1007/ s10494-025-00642-x
2025
-
[25]
Luca Guastoni, Jean Rabault, Philipp Schlatter, Hossein Azizpour, and Ricardo Vinuesa. Deep reinforcement learning for turbulent drag reduction in channel flows.The European Physical Journal E, 46(4):27, April 2023. ISSN 1292-895X. doi: 10.1140/epje/s10189-023-00285-8
-
[26]
Takahiro Sonoda, Zhuchen Liu, Toshitaka Itoh, and Yosuke Hasegawa. Reinforcement learning of control strategies for reducing skin friction drag in a fully developed turbulent channel flow.Journal of Fluid Mechanics, 960:A30, April 2023. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2023.147
-
[27]
Zisong Zhou, Mengqi Zhang, and Xiaojue Zhu. Reinforcement-learning-based control of turbulent channel flows at high Reynolds numbers.Journal of Fluid Mechanics, 1006:A12, March 2025. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2025.27
-
[28]
Deep reinforcement learning for active flow control in a turbulent separation bubble.Nature Communications, 16(1):1422, February
Bernat Font, Francisco Alcántara-Ávila, Jean Rabault, Ricardo Vinuesa, and Oriol Lehmkuhl. Deep reinforcement learning for active flow control in a turbulent separation bubble.Nature Communications, 16(1):1422, February
-
[29]
doi: 10.1038/s41467-025-56408-6
ISSN 2041-1723. doi: 10.1038/s41467-025-56408-6
-
[30]
Gerben Beintema, Alessandro Corbetta, Luca Biferale, and Federico Toschi. Controlling Rayleigh–Bénard convection via reinforcement learning.Journal of Turbulence, 21(9-10):585–605, October 2020. ISSN null. doi: 10.1080/14685248.2020.1797059
-
[31]
Joongoo Jeon, Jean Rabault, Joel Vasanth, Francisco Alcántara-Ávila, Shilaj Baral, and Ricardo Vinuesa. Inductive biased-deep reinforcement learning methods for flow control: Group-invariant and positional-encoding networks improve learning reproducibility and quality.Physics of Fluids, 37(7):077189, July 2025. ISSN 1070-6631. doi: 10.1063/5.0276738
-
[32]
Colin Vignon, Jean Rabault, Joel Vasanth, Francisco Alcántara-Ávila, Mikael Mortensen, and Ricardo Vinuesa. Effective control of two-dimensional Rayleigh–Bénard convection: Invariant multi-agent reinforcement learning is all you need.Physics of Fluids, 35(6):065146, June 2023. ISSN 1070-6631. doi: 10.1063/5.0153181
-
[33]
Joel Vasanth, Jean Rabault, Francisco Alcántara-Ávila, Mikael Mortensen, and Ricardo Vinuesa. Multi-agent Reinforcement Learning for the Control of Three-Dimensional Rayleigh–Bénard Convection.Flow, Turbulence and Combustion, 115(3):1319–1355, September 2025. ISSN 1573-1987. doi: 10.1007/s10494-024-00619-2
-
[34]
meMIA: Multilevel Ensemble Membership Inference Attack
Junchang Huang, Weifeng Zeng, Hao Xiong, Bernd R. Noack, Gang Hu, Shugao Liu, Yuchen Xu, and Huanhui Cao. Symmetry-Informed Reinforcement Learning and its Application to Low-Level Attitude Control of Quadrotors. IEEE Transactions on Artificial Intelligence, 5(3):1147–1161, March 2024. ISSN 2691-4581. doi: 10.1109/TAI. 2023.3249683
work page doi:10.1109/tai 2024
-
[35]
Federica Tonti, Jean Rabault, and Ricardo Vinuesa. Navigation in a simplified urban flow through deep rein- forcement learning.Journal of Computational Physics, 538:114194, October 2025. ISSN 0021-9991. doi: 10.1016/j.jcp.2025.114194. 20 APREPRINT- APRIL17, 2026
-
[36]
Gunther Waxenegger-Wilfing, Kai Dresia, Jan Deeken, and Michael Oschwald. A Reinforcement Learning Approach for Transient Control of Liquid Rocket Engines.IEEE Transactions on Aerospace and Electronic Systems, 57(5):2938–2952, October 2021. ISSN 0018-9251, 1557-9603, 2371-9877. doi: 10.1109/TAES.2021. 3074134
-
[37]
Lei Yan, Huaiqiang Cai, Qiulei Wang, Lingwei Chen, Chao Li, and Gang Hu. Deep reinforcement learning-based active flow control for a tall building.Physics of Fluids, 37(4):045132, April 2025. ISSN 1070-6631. doi: 10.1063/5.0267175
-
[38]
Xuekai Guo, Pengfei Lin, Qiulei Wang, and Gang Hu. Intelligent control of structural vibrations based on deep reinforcement learning.Journal of Infrastructure Intelligence and Resilience, 4(2):100136, June 2025. ISSN 2772-9915. doi: 10.1016/j.iintel.2024.100136
-
[39]
Ricardo Vinuesa, Oriol Lehmkuhl, Adrian Lozano-Durán, and Jean Rabault. Flow Control in Wings and Discovery of Novel Approaches via Deep Reinforcement Learning.Fluids, 7(2):62, February 2022. ISSN 2311-5521. doi: 10.3390/fluids7020062
-
[40]
Yi-Zhe Wang, Yu-Fei Mei, Nadine Aubry, Zhihua Chen, Peng Wu, and Wei-Tao Wu. Deep reinforcement learning based synthetic jet control on disturbed flow over airfoil.Physics of Fluids, 34(3):033606, March 2022. ISSN 1070-6631. doi: 10.1063/5.0080922
-
[41]
Renn and Morteza Gharib
Peter I. Renn and Morteza Gharib. Machine learning for flow-informed aerodynamic control in turbulent wind conditions.Communications Engineering, 1(1):45, December 2022. ISSN 2731-3395. doi: 10.1038/ s44172-022-00046-z
2022
-
[42]
Deep-reinforcement-learning-based separation control in a two-dimensional airfoil
Xavier Garcia, Arnau Miró, Pol Suárez, Francisco Alcántara-Ávila, Jean Rabault, Bernat Font, Oriol Lehmkuhl, and Ricardo Vinuesa. Deep-reinforcement-learning-based separation control in a two-dimensional airfoil. International Journal of Heat and Fluid Flow, 116:109913, December 2025. ISSN 0142-727X. doi: 10.1016/j.ijheatfluidflow.2025.109913
-
[43]
Romain Paris, Samir Beneddine, and Julien Dandois. Robust flow control and optimal sensor placement using deep reinforcement learning.Journal of Fluid Mechanics, 913:A25, April 2021. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2020.1170
-
[44]
Qiulei Wang, Lei Yan, Gang Hu, Wenli Chen, Jean Rabault, and Bernd R. Noack. Dynamic feature-based deep reinforcement learning for flow control of circular cylinder with sparse surface pressure sensing.Journal of Fluid Mechanics, 988:A4, June 2024. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2024.333
-
[45]
Triantafyllou, and George Em Karniadakis
Dixia Fan, Liu Yang, Zhicheng Wang, Michael S. Triantafyllou, and George Em Karniadakis. Reinforcement learning for bluff body active flow control in experiments and simulations.Proceedings of the National Academy of Sciences, 117(42):26091–26098, October 2020. doi: 10.1073/pnas.2004939117
-
[46]
Ziqi Fang, Haohua Zong, Yun Wu, Jinping Li, Zhi Su, and Biao Wei. Experimental deep reinforcement learning control of a turbulent boundary layer with plasma actuators for skin-friction drag reduction.Journal of Fluid Mechanics, 1027:A19, January 2026. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2025.11086
-
[47]
Jean Rabault and Alexander Kuhnle. Accelerating deep reinforcement learning strategies of flow control through a multi-environment approach.Physics of Fluids, 31(9):094105, September 2019. ISSN 1070-6631. doi: 10.1063/1.5116415
-
[48]
Vincent Belus, Jean Rabault, Jonathan Viquerat, Zhizhao Che, Elie Hachem, and Ulysse Reglade. Exploiting locality and translational invariance to design effective deep reinforcement learning control of the 1-dimensional unstable falling liquid film.AIP Advances, 9(12):125014, December 2019. ISSN 2158-3226. doi: 10.1063/1. 5132378
work page doi:10.1063/1 2019
-
[49]
Jie Chen, Haohua Zong, Huimin Song, Yun Wu, Hua Liang, and Jiawei Xiang. A field programmable gate array-based deep reinforcement learning framework for experimental active flow control and its application in airfoil flow separation elimination.Physics of Fluids, 36(9):091708, September 2024. ISSN 1070-6631. doi: 10.1063/5.0229981
-
[50]
Haohua Zong, Yun Wu, Jinping Li, Zhi Su, and Hua Liang. Closed-loop supersonic flow control with a high-speed experimental deep reinforcement learning framework.Journal of Fluid Mechanics, 1009:A3, April 2025. ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2025.160
-
[51]
Deep reinforcement learning control of supersonic cavity flow using a pulsed-arc plasma actuator matrix.Journal of Fluid Mechanics, 1029:A38, February
Yakang Kong, Haohua Zong, Jinping Li, Yun Wu, and Cheng Wang. Deep reinforcement learning control of supersonic cavity flow using a pulsed-arc plasma actuator matrix.Journal of Fluid Mechanics, 1029:A38, February
-
[52]
ISSN 0022-1120, 1469-7645. doi: 10.1017/jfm.2026.11212. 21 APREPRINT- APRIL17, 2026
-
[53]
James Koch, Mitsuru Kurosaka, Carl Knowlen, and J. Nathan Kutz. Multi-scale Physics of Rotating Detonation Engines: Autosolitons and Modulational Instabilities.Physical Review E, 104(2):024210, August 2021. ISSN 2470-0045, 2470-0053. doi: 10.1103/PhysRevE.104.024210
-
[54]
Towards the ultimate conservative difference scheme III
Bram Van Leer. Towards the ultimate conservative difference scheme III. Upstream-centered finite-difference schemes for ideal compressible flow.Journal of Computational Physics, 23(3):263–275, March 1977. ISSN 0021-9991. doi: 10.1016/0021-9991(77)90094-8
-
[55]
Efficient implementation of essentially non-oscillatory shock-capturing schemes
Chi-Wang Shu and Stanley Osher. Efficient implementation of essentially non-oscillatory shock-capturing schemes. Journal of Computational Physics, 77(2):439–471, August 1988. ISSN 0021-9991. doi: 10.1016/0021-9991(88) 90177-5
-
[56]
Christopher Rackauckas and Qing Nie. DifferentialEquations.jl – A Performant and Feature-Rich Ecosystem for Solving Differential Equations in Julia.Journal of Open Research Software, 5(1), May 2017. ISSN 2049-9647. doi: 10.5334/jors.151
-
[57]
Jeff Bezanson, Alan Edelman, Stefan Karpinski, and Viral B. Shah. Julia: A Fresh Approach to Numerical Computing.SIAM Review, 59(1):65–98, January 2017. ISSN 0036-1445. doi: 10.1137/141000671
-
[58]
F. Li, P. K. A. Wai, and J. N. Kutz. Geometrical description of the onset of multi-pulsing in mode-locked laser cavities.Journal of the Optical Society of America B : optical physics, 27(10):2068–2077, 2010. ISSN 0740-3224. doi: 10.1364/JOSAB.27.002068
-
[59]
James Koch, Mitsuru Kurosaka, Carl Knowlen, and J. Nathan Kutz. Mode-Locked Rotating Detonation Waves: Experiments and a Model Equation.Physical Review E, 101(1):013106, January 2020. ISSN 2470-0045, 2470-0053. doi: 10.1103/PhysRevE.101.013106
-
[60]
Frank Lu, Eric Braun, Luca Massa, and Donald Wilson. Rotating Detonation Wave Propulsion: Experimental Challenges, Modeling, and Engine Concepts (Invited). In47th AIAA/ASME/SAE/ASEE Joint Propulsion Confer- ence & Exhibit, San Diego, California, July 2011. American Institute of Aeronautics and Astronautics. ISBN 978-1-60086-949-5. doi: 10.2514/6.2011-6043
-
[61]
F. A. Bykovskii, S. A. Zhdan, and E. F. Vedernikov. Continuous spin detonation of fuel-air mixtures. Combustion, Explosion, and Shock Waves, 42(4):463–471, July 2006. ISSN 0010-5082, 1573-8345. doi: 10.1007/s10573-006-0076-9
-
[62]
Sutton and Andrew G
Richard S. Sutton and Andrew G. Barto.Reinforcement Learning: An Introduction. Adaptive Computation and Machine Learning Series. The MIT Press, Cambridge, Massachusetts, second edition edition, 2018. ISBN 978-0-262-03924-6
2018
-
[63]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal Policy Optimization Algorithms, August 2017. doi: 10.48550/arXiv.1707.06347
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[64]
A Survey of Temporal Credit Assignment in Deep Reinforcement Learning.Transactions on Machine Learning Research, December 2023
Eduardo Pignatelli, Johan Ferret, Matthieu Geist, Thomas Mesnard, Hado van Hasselt, and Laura Toni. A Survey of Temporal Credit Assignment in Deep Reinforcement Learning.Transactions on Machine Learning Research, December 2023. ISSN 2835-8856
2023
-
[65]
Bridging RL Theory and Practice with the Effective Horizon
Cassidy Laidlaw, Stuart Russell, and Anca Dragan. Bridging RL Theory and Practice with the Effective Horizon. InThirty-Seventh Conference on Neural Information Processing Systems, November 2023
2023
-
[66]
Stable- Baselines3: Reliable Reinforcement Learning Implementations.Journal of Machine Learning Research, 22(268): 1–8, 2021
Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable- Baselines3: Reliable Reinforcement Learning Implementations.Journal of Machine Learning Research, 22(268): 1–8, 2021. ISSN 1533-7928
2021
-
[67]
In: 2023 IEEE/RSJ Interna- tionalConferenceonIntelligentRobotsandSystems(IROS).pp.7742–7749(2023)
Amirmohammad Karimi, Jun Jin, Jun Luo, A. Rupam Mahmood, Martin Jagersand, and Samuele Tosatto. Dynamic Decision Frequency with Continuous Options. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7545–7552, Detroit, MI, USA, October 2023. IEEE. ISBN 978-1-6654-9190-7. doi: 10.1109/IROS55552.2023.10342408
-
[68]
Control Frequency Adaptation via Action Persistence in Batch Reinforcement Learning
Alberto Maria Metelli, Flavio Mazzolini, Lorenzo Bisi, Luca Sabbioni, and Marcello Restelli. Control Frequency Adaptation via Action Persistence in Batch Reinforcement Learning. InProceedings of the 37th International Conference on Machine Learning, pages 6862–6873. PMLR, November 2020
2020
-
[69]
Sutton and Doina Precup and Satinder Singh , keywords =
Richard S. Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1):181–211, August 1999. ISSN 0004-3702. doi: 10.1016/S0004-3702(99)00052-1
-
[70]
Marius Kurz, Rohan Kaushik, Marcel Blind, Patrick Kopper, Anna Schwarz, Felix Rodach, and Andrea Beck. Invariant control strategies for active flow control using graph neural networks.Computers & Fluids, 303:106854, December 2025. ISSN 0045-7930. doi: 10.1016/j.compfluid.2025.106854. 22 APREPRINT- APRIL17, 2026
-
[71]
James Koch and J. Nathan Kutz. Modeling thermodynamic trends of rotating detonation engines.Physics of Fluids, 32(12):126102, December 2020. ISSN 1070-6631. doi: 10.1063/5.0023972
-
[72]
Kristian Holme. DRL_RDE_data. April 2026. doi: 10.5281/zenodo.19557242
-
[73]
KristianHolme/DRL_RDE_paper_code
Kristian Holme. KristianHolme/DRL_RDE_paper_code. Zenodo, April 2026. doi: 10.5281/ZENODO.19495039. 23
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.