Recognition: unknown
Equifinality in Mixture of Experts: Routing Topology Does Not Determine Language Modeling Quality
Pith reviewed 2026-05-10 12:58 UTC · model grok-4.3
The pith
Routing topology does not determine asymptotic perplexity in Mixture-of-Experts language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
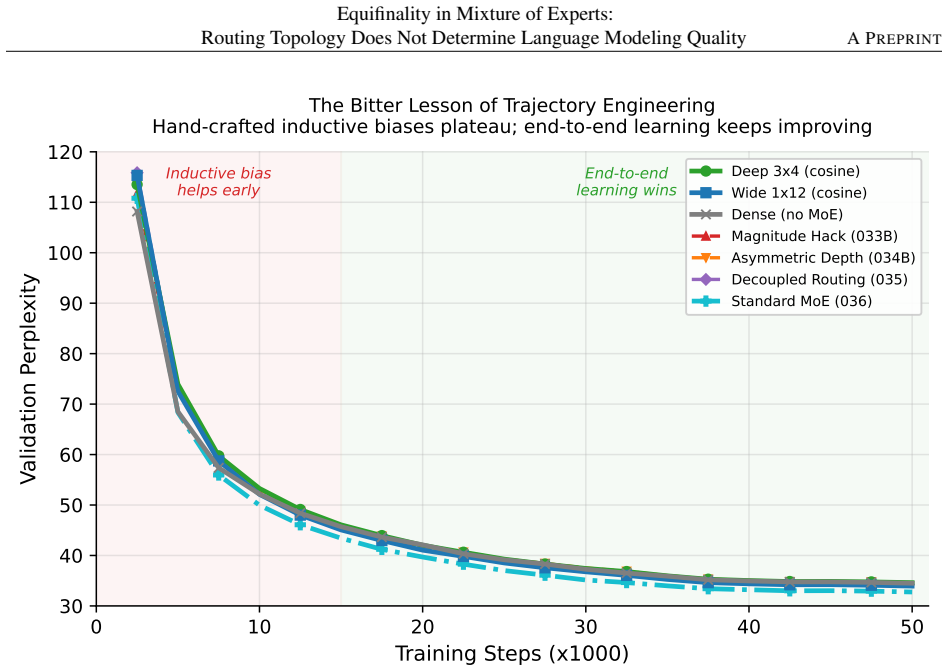
In a geometric ST-MoE using cosine-similarity routing to learned centroids in 64-dimensional space, five routing variants achieve asymptotic perplexities that are statistically equivalent within a 1-PPL margin on WikiText-103, confirmed by TOST tests with p < 0.05 across all pairwise comparisons after 50K training steps. The equivalence extends to hash, random-fixed, and top-1 routing with 1.1-2.2 PPL degradation. A standard linear router with 5.3 times more routing parameters reaches 32.76 PPL, but matched cosine routing closes 67 percent of the gap, leaving a true mechanism advantage of about 1.2 percent. Multi-hop updates prove collinear with cosine similarity 0.805, acting as magnitude放大
What carries the argument
Cosine-similarity routing to learned centroids in a 64-dimensional space, which reduces routing parameters by 80 percent while allowing direct comparison of topology variants under controlled training.
If this is right
- Multi-hop routing trajectories are largely collinear and implement magnitude amplification rather than compositional reasoning.
- A single learnable scalar multiplier can replicate the performance of multi-hop updates.
- Zero-shot relative-norm halting reduces MoE FLOPs by 25 percent at a cost of only 0.12 percent PPL.
- Expert-level specialization and causal controllability can coexist with topology-level equifinality.
Where Pith is reading between the lines
- At this model scale the limiting factor for performance may be total capacity or training compute rather than routing sophistication.
- Future designs could safely adopt simpler, lower-parameter routers without quality loss.
- The result leaves open whether equifinality persists at much larger scales where routing efficiency might matter more.
Load-bearing premise
The 62 controlled experiments on WikiText-103 fully isolate routing topology effects from other training variables such as optimization dynamics, expert capacity, or initialization.
What would settle it
A replication at the same scale and training budget that finds a perplexity gap larger than 1 point between any two cosine-routing variants reaching statistical significance would falsify the equifinality result.
Figures









read the original abstract
Sparse Mixture-of-Experts (MoE) architectures employ increasingly sophisticated routing mechanisms -- learned routers, multi-hop trajectories, token-dependent gating. We ask: does routing topology actually determine language modeling quality? We build a geometric MoE (ST-MoE) using cosine-similarity routing against learned centroids in a low-dimensional space ($d_{space} = 64$), requiring 80% fewer routing parameters than standard linear routers. Through 62 controlled experiments on WikiText-103 at 76--84M parameters trained to convergence (50K steps, 1.64B tokens), we find that routing topology does not determine asymptotic perplexity (PPL): five cosine-routing variants are statistically equivalent within a 1-PPL margin (Two One-Sided Tests [TOST], $p < 0.05$ for all 10 pairwise comparisons; 15 runs across 3 seeds, observed range 33.93--34.72). The finding extends to hash, random-fixed, and top-1 routing (single-seed; graceful 1.1--2.2 PPL degradation) and replicates on OpenWebText (0.03 PPL gap, 6 runs, 3 seeds each). A standard linear router with 5.3$\times$ more routing parameters reaches PPL 32.76, but iso-parameter cosine routing closes 67% of this gap -- the true mechanism advantage is $\sim$1.2%. The mechanistic explanation is convergent redundancy: multi-hop updates are collinear ($\cos(\Delta h_0, \Delta h_1) = 0.805$), implementing magnitude amplification rather than compositional reasoning; a single learnable scalar replicates multi-hop performance. As a practical payoff, zero-shot relative-norm halting saves 25% of MoE FLOPs at +0.12% PPL. Expert-level specialization and causal controllability -- which coexist with topology-level equifinality -- are explored in a companion paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that routing topology in sparse Mixture-of-Experts (MoE) models does not determine asymptotic language modeling quality. Using a geometric ST-MoE with cosine-similarity routing against learned centroids in a 64-dimensional space (80% fewer routing parameters than linear routers), the authors report 62 controlled experiments on WikiText-103 (76-84M parameters, 50K steps to 1.64B tokens) showing five cosine-routing variants are statistically equivalent within a 1-PPL margin via TOST tests (p<0.05 for all 10 pairs, 15 runs across 3 seeds, PPL range 33.93-34.72). The result extends to hash/random/top-1 routing (minor degradation) and replicates on OpenWebText; a linear router is only ~1.2% better after iso-parameter adjustment. They attribute equifinality to convergent redundancy (multi-hop updates collinear with cos=0.805) and demonstrate 25% FLOP savings via zero-shot relative-norm halting.
Significance. If the equifinality result holds, it would be significant for MoE research by shifting emphasis away from routing sophistication toward expert specialization and other factors, while highlighting practical gains in parameter efficiency and compute. The work earns credit for its scale (62 experiments to convergence, TOST equivalence testing, 15-run seed replication, OpenWebText replication, and mechanistic collinearity measurement), which provides stronger empirical grounding than typical MoE ablations. The finding that topology-level differences yield negligible PPL impact (with graceful degradation for simpler routers) is falsifiable and could influence design choices at this scale.
major comments (2)
- [Experimental design (results and methods sections)] Experimental design (results and methods sections): The central claim that PPL equivalence is attributable to routing topology requires explicit isolation from optimization dynamics. The manuscript does not report expert utilization histograms, load-balancing statistics, or per-variant gradient norm distributions, even though different routing functions alter token-to-expert assignments and thus effective batch composition at the 76-84M scale. The narrow observed PPL band (33.93-34.72) means modest confounding in convergence behavior could produce the reported TOST equivalence without proving topology independence.
- [§ on mechanistic explanation] § on mechanistic explanation: The collinearity measurement (cos(Δh0, Δh1)=0.805) is presented as explanatory but is post-hoc; the manuscript should clarify whether this was measured on the same runs used for the main equivalence claim or on a separate set, and whether a single scalar multiplier was ablated against the full multi-hop router in the same controlled setup.
minor comments (2)
- [Abstract and results] Clarify in the abstract and results whether the 33.93-34.72 PPL range is the min-max across all 62 runs or the per-variant means; also state the exact TOST equivalence margin and power calculation.
- [Methods] The claim of '80% fewer routing parameters' should include the exact parameter count for the linear baseline versus the cosine router (including centroid storage) to allow direct verification.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of experimental rigor and mechanistic clarity. We address each major comment below, agreeing where revisions are warranted to better isolate the effects of routing topology and to clarify the supporting analyses.
read point-by-point responses
-
Referee: Experimental design (results and methods sections): The central claim that PPL equivalence is attributable to routing topology requires explicit isolation from optimization dynamics. The manuscript does not report expert utilization histograms, load-balancing statistics, or per-variant gradient norm distributions, even though different routing functions alter token-to-expert assignments and thus effective batch composition at the 76-84M scale. The narrow observed PPL band (33.93-34.72) means modest confounding in convergence behavior could produce the reported TOST equivalence without proving topology independence.
Authors: We agree that reporting these diagnostics would strengthen the claim by more explicitly ruling out optimization confounds. Although the 15-run, multi-seed design and TOST tests already provide statistical safeguards against minor convergence differences, we will add expert utilization histograms, load-balancing statistics (including per-expert token counts and imbalance metrics), and per-variant gradient norm distributions to the revised results and methods sections. These will be computed from the existing training logs to demonstrate that token-to-expert assignment differences do not produce systematically divergent optimization trajectories within the observed PPL range. revision: yes
-
Referee: § on mechanistic explanation: The collinearity measurement (cos(Δh0, Δh1)=0.805) is presented as explanatory but is post-hoc; the manuscript should clarify whether this was measured on the same runs used for the main equivalence claim or on a separate set, and whether a single scalar multiplier was ablated against the full multi-hop router in the same controlled setup.
Authors: The collinearity measurement (cos(Δh0, Δh1)=0.805) was obtained from the identical set of runs underlying the main equivalence results to maintain experimental consistency. The ablation demonstrating that a single learnable scalar multiplier replicates multi-hop performance was likewise performed within the same controlled 76-84M parameter setup on WikiText-103. We will revise the mechanistic explanation section to explicitly state these details, including the exact experimental conditions and that the scalar ablation used the same training hyperparameters and seeds. revision: yes
Circularity Check
No significant circularity: central claim rests on direct experimental measurements
full rationale
The paper's load-bearing claim—that routing topology does not determine asymptotic perplexity—is established through 62 controlled training runs on WikiText-103 (and replications on OpenWebText), with TOST statistical equivalence tests applied to observed PPL values across variants. No mathematical derivation chain, equations, or first-principles results are presented that reduce to their own inputs by construction. The collinearity observation (cos=0.805) and single-scalar replication are reported as post-hoc measurements from the same runs, not as fitted parameters renamed as predictions. No self-citation load-bearing steps, uniqueness theorems, or ansatzes imported via citation appear in the provided text. The work is self-contained against external benchmarks (fixed datasets, fixed training budgets) and does not rely on internal definitions that presuppose the target equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- d_space =
64
axioms (1)
- domain assumption 50K training steps on 1.64B tokens reaches asymptotic perplexity for 76-84M parameter models
Forward citations
Cited by 1 Pith paper
-
Mixture of Layers with Hybrid Attention
Mixture of Layers replaces monolithic transformer blocks with routed thin parallel blocks using hybrid attention that combines a shared softmax block for global context with Gated DeltaNet linear attention in the rout...
Reference graph
Works this paper leans on
-
[1]
Geometric routing enables causal expert control in mixture of experts.arXiv preprint, 2026
Ivan Ternovtsii and Yurii Bilak. Geometric routing enables causal expert control in mixture of experts.arXiv preprint, 2026
2026
-
[2]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
GShard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021
2021
-
[4]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[5]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. ST-MoE: Designing stable and transferable sparse expert models.arXiv preprint arXiv:2202.08906, 2022
work page internal anchor Pith review arXiv 2022
-
[6]
Janus: A unified framework for evaluating and training sparse expert models.arXiv preprint, 2023
Zirui Liu et al. Janus: A unified framework for evaluating and training sparse expert models.arXiv preprint, 2023
2023
-
[7]
RoFormer: Enhanced trans- former with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced trans- former with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[8]
Using the output embedding to improve language models
Ofir Press and Lior Wolf. Using the output embedding to improve language models. InProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, 2017
2017
-
[9]
Sigmoid loss for language image pre-training, 2023
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre- training.arXiv preprint arXiv:2303.15343, 2023
-
[10]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2017
work page internal anchor Pith review arXiv 2017
-
[11]
Training compute-optimal large lan- guage models.Advances in Neural Information Processing Systems, 35, 2022
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large lan- guage models.Advances in Neural Information Processing Systems, 35, 2022
2022
-
[12]
Scaling laws for fine-grained mixture of experts
Jakub Ludziejewski, Jakub Krajewski, Kamil Adamczewski, Sebastian Jaszczur, Szymon Nowak, and Piotr Sankowski. Scaling laws for fine-grained mixture of experts. InInternational Conference on Machine Learning (ICML), 2024. 18 Equifinality in Mixture of Experts: Routing Topology Does Not Determine Language Modeling QualityA PREPRINT
2024
-
[13]
Donald J Schuirmann. A comparison of the two one-sided tests procedure and the power approach for assessing the equivalence of average bioavailability.Journal of Pharmacokinetics and Biopharmaceutics, 15(6):657–680, 1987
1987
-
[14]
Deep networks with stochastic depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. InEuropean Conference on Computer Vision, 2016
2016
-
[15]
Mixture of layers: Decomposing MoE transformers into parallel thin blocks
Ivan Ternovtsii and Yurii Bilak. Mixture of layers: Decomposing MoE transformers into parallel thin blocks. Manuscript in preparation, 2026
2026
-
[16]
Alibaba Research. Routing matters in MoE: Scaling diffusion transformers with explicit routing guidance.arXiv preprint arXiv:2510.24711, 2025. ICLR 2026
-
[17]
Ziyang Xiao et al. Chain-of-experts: When LLMs meet complex operations research problems.arXiv preprint arXiv:2501.07218, 2025
-
[18]
RoMA: Routing manifold alignment improves generalization of mixture-of-experts LLMs
Tianyi Zhou et al. RoMA: Routing manifold alignment improves generalization of mixture-of-experts LLMs. arXiv preprint arXiv:2511.07419, 2025
-
[19]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
OLMoE: Open mixture-of-experts language models
Niklas Muennighoff et al. OLMoE: Open mixture-of-experts language models. InProceedings of the Interna- tional Conference on Learning Representations, 2025
2025
-
[21]
arXiv preprint arXiv:2509.23678 , year=
Guoliang Zhao, Yuhan Fu, Shuaipeng Li, et al. Towards a comprehensive scaling law of mixture-of-experts. arXiv preprint arXiv:2509.23678, 2025
-
[22]
arXiv preprint arXiv:2507.17702 , year=
Changxin Tian, Kunlong Chen, Jia Liu, Ziqi Liu, Zhiqiang Zhang, and Jun Zhou. Towards greater leverage: Scaling laws for efficient mixture-of-experts language models.arXiv preprint arXiv:2507.17702, 2025
-
[23]
MoE lens – an expert is all you need.arXiv preprint arXiv:2603.05806, 2026
Marmik Chaudhari, Idhant Gulati, Nishkal Hundia, Pranav Karra, and Shivam Raval. MoE lens – an expert is all you need.arXiv preprint arXiv:2603.05806, 2026
-
[24]
BuddyMoE: Exploiting expert redundancy to accelerate memory-constrained mixture-of-experts inference
Yun Wang, Lingyun Yang, Senhao Yu, Yixiao Wang, Ruixing Li, Zhixiang Wei, James Yen, and Zhengwei Qi. BuddyMoE: Exploiting expert redundancy to accelerate memory-constrained mixture-of-experts inference. In Proceedings of the ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP), 2026
2026
-
[25]
Hash layers for large sparse models
Stephen Roller, Sainbayar Sukhbaatar, Arthur Szlam, and Jason Weston. Hash layers for large sparse models. Advances in Neural Information Processing Systems, 2021
2021
-
[26]
DEMix layers: Disentangling domains for modular language modeling
Suchin Gururangan, Mike Lewis, Anirudh Srivastava, Veselin Stoyanov, and Luke Zettlemoyer. DEMix layers: Disentangling domains for modular language modeling. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics, 2022
2022
-
[27]
arXiv preprint arXiv:2407.04153 , year=
Xu Owen He. Mixture of a million experts.arXiv preprint arXiv:2407.04153, 2024
-
[28]
ReMoE: Fully differentiable mixture-of-experts with ReLU routing
Ziteng Wang, Jun Zhu, and Jianfei Chen. ReMoE: Fully differentiable mixture-of-experts with ReLU routing. In Proceedings of the International Conference on Learning Representations, 2025
2025
-
[29]
Layerwise recurrent router for mixture-of-experts
Zihan Qiu, Zeyu Huang, Shuang Cheng, Yizhi Zhou, Zili Wang, Ivan Titov, and Jie Fu. Layerwise recurrent router for mixture-of-experts. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[30]
Statistical advantages of perturbing cosine router in mixture of experts
Huy Nguyen, Pedram Akbarian, Trang Pham, Trang Nguyen, Shujian Zhang, and Nhat Ho. Statistical advantages of perturbing cosine router in mixture of experts. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[31]
DirMoE: Dirichlet-routed mixture of experts.arXiv preprint arXiv:2602.09001, 2026
Amirhossein Vahidi, Hesam Asadollahzadeh, Navid Akhavan Attar, Marie Moullet, Kevin Ly, Xingyi Yang, and Mohammad Lotfollahi. DirMoE: Dirichlet-routed mixture of experts.arXiv preprint arXiv:2602.09001, 2026
-
[32]
Grouter: Decoupling routing from representation for accelerated moe training, 2026
Yuqi Xu, Rizhen Hu, Zihan Liu, Mou Sun, and Kun Yuan. Grouter: Decoupling routing from representation for accelerated MoE training.arXiv preprint arXiv:2603.06626, 2026
- [33]
-
[34]
Universal transformers
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal transformers. InInternational Conference on Learning Representations, 2019. 19 Equifinality in Mixture of Experts: Routing Topology Does Not Determine Language Modeling QualityA PREPRINT
2019
-
[35]
Keston Aquino-Michaels. Routing absorption in sparse attention: Why random gates are hard to beat.arXiv preprint arXiv:2603.02227, 2026
-
[36]
Viet-Hoang Tran, Van Hoan Trinh, Khanh Vinh Bui, and Tan M. Nguyen. On linear mode connectivity of mixture-of-experts architectures. InAdvances in Neural Information Processing Systems, 2025
2025
-
[37]
Yan Wang, Yitao Xu, Nanhan Shen, Jinyan Su, Jimin Huang, and Zining Zhu. The illusion of special- ization: Unveiling the domain-invariant “standing committee” in mixture-of-experts models.arXiv preprint arXiv:2601.03425, 2026
-
[38]
Dick, Yuan Cheng, Fan Yang, Tun Lu, Chun Zhang, and Li Shang
Researchers from Fudan, Tsinghua, Michigan, CMU. SD-MoE: Spectral decomposition for effective expert specialization.arXiv preprint arXiv:2602.12556, 2026
-
[39]
Understanding cross-layer contributions to MoE routing in LLMs.arXiv preprint, 2026
Wengang Li, Lingqi Zhang, Toshio Endo, and Mohamed Wahib. Understanding cross-layer contributions to MoE routing in LLMs.arXiv preprint, 2026
2026
-
[40]
Advancing expert specialization for better MoE
Hongcan Guo, Haolang Lu, et al. Advancing expert specialization for better MoE. InAdvances in Neural Information Processing Systems, 2025. A Training Configuration Table 12 provides all hyperparameters used in the convergence marathon (Exps 025–027) and all subsequent experi- ments. Table 12: Complete training configuration for Marathon-scale experiments....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.