Recognition: unknown
Zero-Ablation Overstates Register Content Dependence in DINO Vision Transformers
Pith reviewed 2026-05-10 12:53 UTC · model grok-4.3
The pith
Zero-ablation overstates how much DINO vision transformers rely on exact register content.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
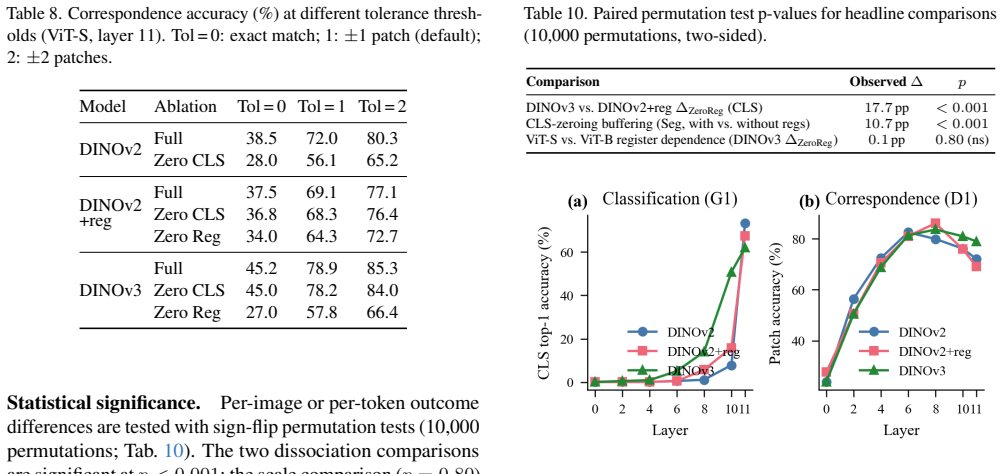
Zero-ablation of register tokens in DINOv2 and DINOv3 produces large drops in classification and segmentation performance, but mean-substitution, noise-substitution, and cross-image register-shuffling keep performance within about 1 percentage point of the unmodified baseline. Internal representation perturbations are measured via per-patch cosine similarity, showing that zeroing causes disproportionately large changes while the other methods perturb but do not degrade tasks. The conclusion is that in these frozen-feature setups, performance depends on plausible register-like activations rather than exact image-specific values. Registers still help buffer dense features from [CLS] token 1.0,
What carries the argument
Comparison of zero-ablation against mean, noise, and cross-image shuffle replacements for register tokens, combined with cosine similarity analysis of internal activations.
If this is right
- Performance relies on the presence of register-like activations rather than their precise values from the input.
- Zero-ablation is an unreliable method for assessing token importance because it introduces extreme perturbations.
- Registers serve to buffer [CLS] dependence and influence patch geometry in these models.
- These patterns replicate consistently at larger ViT-B scales.
Where Pith is reading between the lines
- This implies that in deployed systems, one could potentially use generic or averaged register values without much loss.
- Probing techniques in transformers should incorporate multiple control conditions to distinguish necessary presence from specific content.
- Similar overstatement risks may exist when zero-ablation is applied to other special tokens in vision or language models.
Load-bearing premise
The mean, noise, and cross-image shuffle replacements isolate the effect of removing exact register content without adding compensating artifacts or altering task-relevant statistics.
What would settle it
If a new evaluation task or architecture shows that mean or shuffled register replacements cause performance drops comparable to zero-ablation, this would indicate the replacements do not preserve the necessary properties.
Figures








read the original abstract
Zero-ablation -- replacing token activations with zero vectors -- is widely used to probe token function in vision transformers. Register zeroing in DINOv2+registers and DINOv3 produces large drops (up to $-36.6$\,pp classification, $-30.9$\,pp segmentation), suggesting registers are functionally indispensable. However, three replacement controls -- mean-substitution, noise-substitution, and cross-image register-shuffling -- preserve performance across classification, correspondence, and segmentation, remaining within ${\sim}1$\,pp of the unmodified baseline. Per-patch cosine similarity shows these replacements genuinely perturb internal representations, while zeroing causes disproportionately large perturbations, consistent with why it alone degrades tasks. We conclude that zero-ablation overstates dependence on exact register content. In the frozen-feature evaluations we test, performance depends on plausible register-like activations rather than on exact image-specific values. Registers nevertheless buffer dense features from \texttt{[CLS]} dependence and are associated with compressed patch geometry. These findings, including the replacement-control results, replicate at ViT-B scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that zero-ablation overstates register content dependence in DINO vision transformers. Experiments show that replacing register token activations with zero vectors causes large performance drops (up to -36.6 pp classification, -30.9 pp segmentation), but three controls—mean-substitution, noise-substitution, and cross-image register shuffling—preserve performance within ~1 pp of baseline across classification, correspondence, and segmentation. Cosine similarity analysis confirms that the non-zero replacements perturb internal representations (though less than zeroing), supporting the conclusion that frozen-feature performance depends on plausible register-like activations rather than exact image-specific values. Registers are still shown to buffer dense features from [CLS] dependence and associate with compressed patch geometry; all findings replicate at ViT-B scale.
Significance. If the results hold, the work offers a useful methodological caution for ablation studies in vision transformers, showing that zero-ablation can exaggerate token importance when plausible alternatives suffice. Strengths include multiple independent replacement controls, verification of representation perturbation via cosine similarity, replication across three tasks, and confirmation at ViT-B scale. These elements provide solid empirical grounding for the scoped claim without circularity or post-hoc exclusions.
minor comments (1)
- The abstract and methods would benefit from an explicit statement of the precise layers at which register replacements and cosine-similarity measurements are performed, to aid exact replication.
Simulated Author's Rebuttal
We thank the referee for their positive summary, significance assessment, and recommendation to accept the manuscript. The review accurately captures the core claim and the empirical controls.
Circularity Check
No significant circularity
full rationale
The paper reports direct experimental comparisons of zero-ablation versus mean-, noise-, and cross-image-shuffle replacements on frozen DINOv2/v3 features for classification, correspondence, and segmentation tasks. No mathematical derivations, equations, fitted parameters, or self-referential definitions appear in the provided text. Performance deltas are measured against unmodified baselines and supported by per-patch cosine-similarity checks; these are externally replicable measurements rather than quantities defined in terms of themselves. No load-bearing premise reduces to a self-citation chain or an ansatz smuggled via prior work by the same authors. The scoped claim that zero-ablation overstates exact-content dependence follows from the observed pattern that plausible register-like activations suffice, without circular reduction to the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen-feature evaluations on classification, correspondence, and segmentation tasks are representative of register function in DINO models
Reference graph
Works this paper leans on
-
[1]
Could a neuroscientist understand a microprocessor?PLoS Computational Biology, 13(1):e1005268, 2017
Eric Jonas and Konrad Paul Kording. Could a neuroscientist understand a microprocessor?PLoS Computational Biology, 13(1):e1005268, 2017. 1, 6
2017
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 1, 2
2021
-
[3]
DINOv2: Learning robust visual features without supervision
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´e Jegou, Julien Mairal, Patrick...
2024
-
[4]
Melanie Segado, Felipe Parodi, Jordan K. Matelsky, Michael L. Platt, Eva B. Dyer, and Konrad P. Kord- ing. Grounding intelligence in movement.arXiv preprint arXiv:2507.02771, 2025. 1
-
[5]
Matelsky, Alessandro P
Felipe Parodi, Jordan K. Matelsky, Alessandro P. Lamacchia, Melanie Segado, Yaoguang Jiang, Alejandra Regla-Vargas, Liala Sofi, Clare Kimock, Bridget M. Waller, Michael L. Platt, and Konrad P. Kording. PrimateFace: A machine learning re- source for automated face analysis in human and non-human primates.bioRxiv, 2025. 1
2025
-
[6]
Vision transformers need registers
Timoth´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InICLR,
-
[7]
Oriane Sim´eoni, Huy V . V o, Maximilian Seitzer, Federico Bal- dassarre, Maxime Oquab, Timoth´ee Darcet, Herv´e J´egou, Pi- otr Bojanowski, Julien Mairal, et al. DINOv3.arXiv preprint arXiv:2508.10104, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Efros, and Yossi Gandelsman
Nicholas Jiang, Amil Dravid, Alexei A. Efros, and Yossi Gandelsman. Vision transformers don’t need trained registers. InNeurIPS, 2025. 2, 3
2025
-
[9]
Alexander Lappe and Martin A. Giese. Register and [CLS] tokens induce a decoupling of local and global features in large ViTs. InNeurIPS, 2025. 2, 3
2025
-
[10]
Alexis Marouani, Oriane Sim ´eoni, Herv ´e J ´egou, Piotr Bo- janowski, and Huy V . V o. Revisiting [CLS] and patch token interaction in vision transformers. InICLR, 2026. 3
2026
-
[11]
Lepori, Matthew Kowal, Andrew Lee, Randall Balestriero, Sonia Joseph, Ekdeep Singh Lubana, Talia Konkle, Demba E
Thomas Fel, Binxu Wang, Michael A. Lepori, Matthew Kowal, Andrew Lee, Randall Balestriero, Sonia Joseph, Ekdeep Singh Lubana, Talia Konkle, Demba E. Ba, and Mar- tin Wattenberg. Into the rabbit hull: From task-relevant con- cepts in DINO to Minkowski geometry. InICLR, 2026. 2, 3
2026
-
[12]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InICCV,
-
[13]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InICLR, 2024
2024
-
[14]
Thiagarajan
Srikar Yellapragada, Kowshik Thopalli, Vivek Narayanaswamy, Wesam Sakla, Yang Liu, Yamen Mubarka, Dimitris Samaras, and Jayaraman J. Thiagarajan. Leveraging registers in vision transformers for robust adaptation. In ICASSP, 2025. 2
2025
-
[15]
Vision transformers need more than registers
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision transformers need more than registers. InCVPR, 2026. 3
2026
-
[16]
Zipeng Yan, Yinjie Chen, Chong Zhou, Bo Dai, and Andrew F. Luo. Vision transformers with self-distilled registers. In NeurIPS, 2025. 3
2025
-
[17]
What do self-supervised vision transform- ers learn? InICLR, 2023
Namuk Park, Wonjae Kim, Byeongho Heo, Taekyung Kim, and Sangdoo Yun. What do self-supervised vision transform- ers learn? InICLR, 2023. 3, 5
2023
-
[18]
Burgh- outs, Francesco Locatello, and Yuki M
Valentinos Pariza, Mohammadreza Salehi, Gertjan J. Burgh- outs, Francesco Locatello, and Yuki M. Asano. Near, far: Patch-ordering enhances vision foundation models’ scene understanding. InICLR, 2025. 3
2025
-
[19]
Weinberger, Yon- glong Tian, and Yue Wang
Jiawei Yang, Katie Z Luo, Jiefeng Li, Congyue Deng, Leonidas Guibas, Dilip Krishnan, Kilian Q. Weinberger, Yon- glong Tian, and Yue Wang. Denoising vision transformers. InECCV, 2024. 3
2024
-
[20]
SINDER: Repairing the singular defects of DINOv2
Haoqi Wang, Tong Zhang, and Mathieu Salzmann. SINDER: Repairing the singular defects of DINOv2. InECCV, 2024. 3
2024
-
[21]
iBOT: Image BERT pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. iBOT: Image BERT pre-training with online tokenizer. InICLR, 2022. 3
2022
-
[22]
Are sixteen heads really better than one? InNeurIPS, 2019
Paul Michel, Omer Levy, and Graham Neubig. Are sixteen heads really better than one? InNeurIPS, 2019. 3
2019
-
[23]
Token merging: Your ViT but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your ViT but faster. InICLR, 2023. 3
2023
-
[24]
The out-of- distribution problem in explainability and search methods for feature importance explanations
Peter Hase, Harry Xie, and Mohit Bansal. The out-of- distribution problem in explainability and search methods for feature importance explanations. InNeurIPS, 2021. 3 7
2021
-
[25]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InICML, 2017. 3
2017
-
[26]
Causal abstractions of neural networks
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. Causal abstractions of neural networks. InNeurIPS,
-
[27]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in GPT. In NeurIPS, 2022. 3
2022
-
[28]
How to use and interpret activation patching.arXiv preprint arXiv:2404.15255,
Stefan Heimersheim and Neel Nanda. How to use and inter- pret activation patching.arXiv preprint arXiv:2404.15255,
-
[29]
Towards best practices of acti- vation patching in language models: Metrics and methods
Fred Zhang and Neel Nanda. Towards best practices of acti- vation patching in language models: Metrics and methods. In ICLR, 2024. 3
2024
-
[30]
Optimal ablation for inter- pretability
Maximilian Li and Lucas Janson. Optimal ablation for inter- pretability. InNeurIPS, 2024. 3
2024
-
[31]
arXiv prepreint arXiv:1908.10543 (2019) 10
Juhong Min, Jongmin Lee, Jean Ponce, and Minsu Cho. SPair- 71k: A large-scale benchmark for semantic correspondence. arXiv preprint arXiv:1908.10543, 2019. 4, 6
-
[32]
The effective rank: A mea- sure of effective dimensionality
Olivier Roy and Martin Vetterli. The effective rank: A mea- sure of effective dimensionality. InEuropean Signal Process- ing Conference (EUSIPCO), pages 606–610, 2007. 5
2007
-
[33]
Training data-efficient image transformers & distillation through atten- tion
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv´e J´egou. Training data-efficient image transformers & distillation through atten- tion. InICML, 2021. 6
2021
-
[34]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022. 6 8 Zero-Ablation Overstates Register Content Dependence in DINO Vision Transformers Supplementary Material Table 5. ViT-B task× ablation matrix (layer 11). CLS: probe top-1 (%). Corr: correspondence (%). Seg:...
2022
-
[35]
5) complements the ViT-S matrix in the main text (Tab
Extended Results The ViT-B task × ablation matrix (Tab. 5) complements the ViT-S matrix in the main text (Tab. 2). Per-task breakdowns with confidence intervals follow. Segmentation. Synthetic correspondence.Table 7 provides per- condition correspondence with bootstrapped CIs. Register zeroing reduces correspondence from 69–79% to 58–64% (ViT-S; Tab. 7), ...
-
[36]
9), vs.−18.9 / −36.6 pp for register zeroing
Controls and Statistical Tests Random-patch negative control.Zeroing 4 random patch tokens (5 seeds) causes ≤1 pp CLS drop for ViT-S and ≤2.3 pp for ViT-B (Tab. 9), vs.−18.9 / −36.6 pp for register zeroing. Mean-substitution control.Replacing registers with per- layer dataset-mean activations (5,000 images; Tab. 1 in main text) has negligible effect (−0.3...
-
[37]
11 and 12 and Fig
Representation Geometry Effective rank across layers reveals when patch compression and register dependence emerge (Tabs. 11 and 12 and Fig. 9; see also Fig. 8). DINOv3 is already compressed at layer 6 (effective rank 6.4 vs. 32.3 for DINOv2), yet register depen- dence for classification emerges only at layers 10–11. In DINOv3, register zeroingimprovesCLS...
-
[38]
4 traces how attention mass distributes between token types at each of the 12 trans- former layers
Mechanistic Analysis Attention flow across layers.Fig. 4 traces how attention mass distributes between token types at each of the 12 trans- former layers. In DINOv2 (no registers), CLS self-attention dominates early layers then declines. In both register mod- els, register attention share buildsgraduallyfrom mid-layers: DINOv2+reg stabilizes at ∼20% CLS→r...
-
[39]
The full Figure 10.CLS attention (ViT-S, last layer, 200 images)
ViT-B Scale Validation We replicate the zero-ablation experiments at ViT-B scale: DINOv2-B (86.6M params), DINOv2-B+reg (with four reg- ister tokens), and DINOv3-B (85.7M params). The full Figure 10.CLS attention (ViT-S, last layer, 200 images). (a)CLS attention fraction per token type. DINOv2+reg: 17.9% to registers; DINOv3: 29.1%.(b)Per-register breakdo...
-
[40]
DINOv3 models are loaded via torch.hub with locally cached weights ( dinov3 vits16 and dinov3 vitb16)
Experimental Details Feature extraction.All features are ex- tracted using HuggingFace transformers (facebook/dinov2-small and facebook/dinov2-with-registers-small for ViT-S; facebook/dinov2-base and facebook/dinov2-with-registers-base 11 for ViT-B). DINOv3 models are loaded via torch.hub with locally cached weights ( dinov3 vits16 and dinov3 vitb16). Inp...
-
[41]
AdamW, weight decay 10−2, learning rate 10−3, constant, 100 epochs
per patch token; masks downsampled to the patch grid via nearest-neighbor interpolation. AdamW, weight decay 10−2, learning rate 10−3, constant, 100 epochs. Per-pixel cross-entropy, ignoring void (index 255). kNN retrieval.2,000 ImageNet val images, each pro- ducing two augmented views ( RandomResizedCrop, ColorJitter, RandomHorizontalFlip). Cosine simila...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.