Recognition: unknown
Geometric Routing Enables Causal Expert Control in Mixture of Experts
Pith reviewed 2026-05-10 12:49 UTC · model grok-4.3
The pith
Cosine-similarity routing makes individual MoE experts monosemantic and causally controllable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
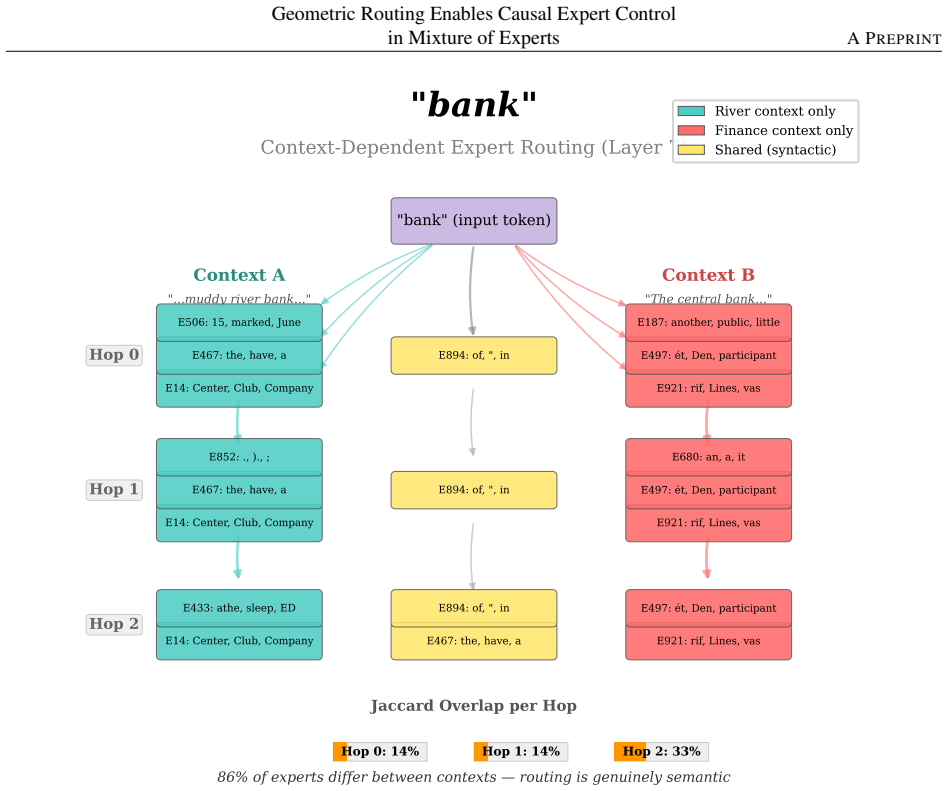
Individual rank-1 experts are monosemantic by construction, and cosine-similarity routing in a low-dimensional metric space makes their specialization directly inspectable. Projecting expert output vectors through the unembedding matrix yields a Semantic Dictionary in which 15% of experts are monosemantic specialists spanning 10 categories. Routing exhibits a frequency-to-syntax gradient across layers. Causal interventions validate the labels: steering toward a temporal expert centroid increases P(temporal) by +321%, suppressing a geographic expert drops P(geographic) by -23%, and rewriting an expert output vector halves target-category probability, with additive effects across layers. The 1
What carries the argument
Cosine-similarity routing to low-dimensional centroids, which selects experts by vector similarity and allows specialization to be read directly from the centroid matrix.
If this is right
- 15 percent of experts function as monosemantic specialists in categories including temporal, geographic, cardinal, discourse, emotional, financial, military, and scientific.
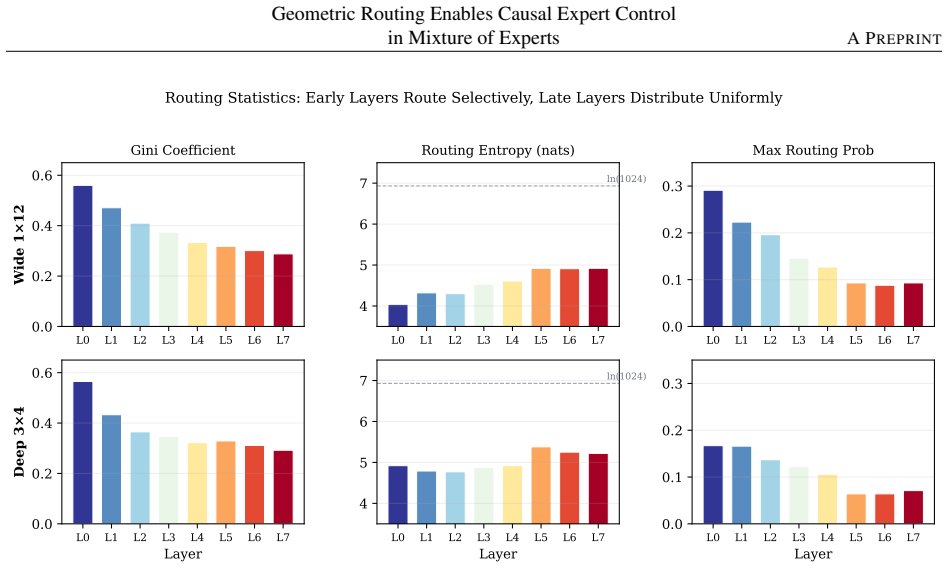
- Early layers route tokens primarily by word frequency while deeper layers route by syntactic class, with statistical significance.
- Steering an expert's output toward its centroid increases the probability of its associated semantic category by a median of 321 percent across prompts.
- Suppressing or rewriting an expert's output vector decreases the probability of target categories, and these effects compose additively when applied across multiple layers.
- Linear routers permit similar causal control, yet only the cosine approach enables direct inspection of expert identities from geometry alone.
Where Pith is reading between the lines
- If the geometric transparency holds, then MoE architectures could be designed from the start to support built-in interpretability rather than requiring post-training analysis.
- The frequency-to-syntax progression in routing might reflect a natural hierarchy in how information is processed in language models.
- Testing whether other sparse activation methods produce similar monosemantic experts when given geometric routing would extend the finding.
- Such direct control suggests applications in safe model deployment where specific expert behaviors can be modulated without retraining.
Load-bearing premise
That projecting expert output vectors through the unembedding matrix yields faithful semantic labels rather than artifacts of the projection or training data distribution.
What would settle it
Finding that causal interventions on the identified experts produce no significant change in the predicted probabilities for the corresponding semantic categories, or that the projected labels do not align with actual token distributions.
Figures
read the original abstract
Sparse Mixture-of-Experts (MoE) models scale parameters while fixing active computation per token, but the specialization of individual experts remains opaque. In a companion paper we showed that routing topology is quality-neutral: five structurally different configurations converge to statistically equivalent language modeling quality. Here we show that expert identity is nonetheless causally meaningful: individual rank-1 experts are monosemantic by construction, and cosine-similarity routing in a low-dimensional metric space makes their specialization directly inspectable. We present four lines of evidence. First, projecting expert output vectors through the unembedding matrix yields a Semantic Dictionary: 15% of experts are monosemantic specialists spanning 10 categories (temporal, geographic, cardinal, discourse, emotional, financial, military, scientific). Second, routing exhibits a frequency-to-syntax gradient: early layers separate tokens by word frequency, deeper layers by syntactic class (Zipf-confound controls, all $p < 0.001$). Third, causal interventions confirm these labels: steering toward a temporal expert's centroid increases P(temporal) by +321% (median across 44 prompts); suppressing a geographic expert drops P(geographic) by -23%; rewriting an expert's output vector halves target-category probability, and effects compose additively across layers. Fourth, the interventions are not unique to cosine routing: linear routers support comparable steering, but only cosine routing provides geometric transparency -- expert specialization is readable directly from the centroid matrix. MoE expert-level specialization is a first-class interpretability primitive: architecturally monosemantic, causally validated, and controllable at inference with zero overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that sparse Mixture-of-Experts (MoE) models possess causally meaningful expert identities, with rank-1 experts being monosemantic by construction. Cosine-similarity routing in a low-dimensional metric space renders specialization directly inspectable via a Semantic Dictionary obtained by projecting expert output vectors through the unembedding matrix (identifying 15% of experts as specialists across 10 categories such as temporal and geographic). Routing exhibits a frequency-to-syntax gradient (early layers by token frequency, deeper by syntactic class, with Zipf-confound controls at p<0.001). Causal interventions (centroid steering, suppression, vector rewriting) validate the labels with large effects (+321% median increase in P(temporal) across 44 prompts; -23% drop in P(geographic); additive composition across layers) and show that linear routers support comparable steering while cosine routing uniquely provides geometric transparency.
Significance. If the central claims hold after addressing validation gaps, this work would establish expert-level specialization as a first-class, architecturally grounded interpretability primitive in MoE models, enabling zero-overhead causal control at inference and direct geometric inspection of specialization. The large, statistically significant intervention deltas, additive effects, and contrast with linear routers provide concrete, falsifiable evidence for controllability that builds directly on the companion paper's topology-neutrality result; this could shift MoE analysis from opaque scaling to explicit expert manipulation.
major comments (3)
- [Abstract] Abstract (Semantic Dictionary paragraph): The monosemanticity claim and all downstream causal interventions rest on the unembedding projection yielding faithful category labels, yet no independent verification (activation patching on held-out features, alternative projection methods, or probe-based validation) is described to distinguish intrinsic expert semantics from artifacts of the unembedding matrix, residual stream statistics, or training co-occurrences. This is load-bearing because the reported P(category) measurements and intervention targets are derived from the same labeling procedure.
- [Abstract] Abstract (causal interventions paragraph): The median effects (+321% for temporal steering, -23% for geographic suppression) are presented without error bars, without details on the 44 prompts (selection criteria, diversity, or stratification), and without an ablation of the low-dimensional projection step. These omissions prevent assessment of whether the p<0.001 significance and large deltas are robust or sensitive to prompt choice and projection artifacts.
- [Routing gradient] Routing gradient description: The frequency-to-syntax gradient is supported by Zipf-confound controls, but the manuscript provides no explicit description of how prompt selection or token sampling enforces the confound controls, nor the precise statistical test used to establish layer-wise separation (p<0.001). This detail is required to confirm the gradient is not an artifact of residual frequency correlations.
minor comments (2)
- [Abstract] The companion paper on topology neutrality is referenced without a full citation or arXiv identifier in the text.
- [General] Notation for the low-dimensional metric space, centroid matrix, and P(category) probability should be introduced with a brief formal definition or equation in the main text for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback. We agree that additional validation and details are needed to strengthen the manuscript, particularly regarding the robustness of the Semantic Dictionary and the causal intervention results. Below we address each major comment point by point, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (Semantic Dictionary paragraph): The monosemanticity claim and all downstream causal interventions rest on the unembedding projection yielding faithful category labels, yet no independent verification (activation patching on held-out features, alternative projection methods, or probe-based validation) is described to distinguish intrinsic expert semantics from artifacts of the unembedding matrix, residual stream statistics, or training co-occurrences. This is load-bearing because the reported P(category) measurements and intervention targets are derived from the same labeling procedure.
Authors: We agree that independent verification of the Semantic Dictionary labels would strengthen the claims. The unembedding projection is motivated by the logit lens approach commonly used in interpretability literature to read out semantic information from residual stream activations. However, to address potential artifacts, in the revised manuscript we will include an ablation study using linear probes trained on held-out data to validate the category assignments independently of the unembedding matrix. We will also report agreement rates between the projection-based labels and probe predictions. This will help distinguish intrinsic semantics from projection artifacts. revision: yes
-
Referee: [Abstract] Abstract (causal interventions paragraph): The median effects (+321% for temporal steering, -23% for geographic suppression) are presented without error bars, without details on the 44 prompts (selection criteria, diversity, or stratification), and without an ablation of the low-dimensional projection step. These omissions prevent assessment of whether the p<0.001 significance and large deltas are robust or sensitive to prompt choice and projection artifacts.
Authors: We acknowledge the need for more transparency in reporting the intervention results. In the revision, we will add error bars (e.g., interquartile range across prompts) to the median effects. We will provide details on the 44 prompts, including their selection criteria, diversity, and stratification by category. Additionally, we will include an ablation of the low-dimensional projection step to assess its impact on the results. We will also explicitly describe the statistical test used to obtain the p<0.001 significance and include the full distribution of effects. revision: yes
-
Referee: [Routing gradient] Routing gradient description: The frequency-to-syntax gradient is supported by Zipf-confound controls, but the manuscript provides no explicit description of how prompt selection or token sampling enforces the confound controls, nor the precise statistical test used to establish layer-wise separation (p<0.001). This detail is required to confirm the gradient is not an artifact of residual frequency correlations.
Authors: We will expand the manuscript to provide an explicit description of how prompt selection and token sampling enforce the Zipf-confound controls. We will also specify the precise statistical test used to establish the layer-wise separation (p<0.001). This will allow readers to confirm that the gradient is not an artifact of residual frequency correlations. revision: yes
Circularity Check
No significant circularity; derivation relies on independent causal tests
full rationale
The paper's central claims rest on four lines of evidence: semantic dictionary from unembedding projection, frequency-to-syntax routing gradient with statistical controls, causal interventions (steering, suppression, rewriting) that measure changes in category probabilities, and comparison to linear routers. The companion paper citation establishes only that topology is quality-neutral as background context; the present claims about monosemanticity and inspectability do not reduce to that citation or to any fitted parameter by construction. No equation or definition equates a reported effect to its own input, and the causal interventions provide an external check on the projection-derived labels rather than assuming them tautologically. The work is self-contained against its stated benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cosine similarity in the chosen low-dimensional space preserves semantic distinctions relevant to token routing.
- domain assumption The unembedding matrix maps expert outputs to human-interpretable token distributions without introducing spurious category alignments.
invented entities (1)
-
Semantic Dictionary
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Equifinality in mixture of experts: Routing topology does not determine language modeling quality.arXiv preprint, 2026
Ivan Ternovtsii and Yurii Bilak. Equifinality in mixture of experts: Routing topology does not determine language modeling quality.arXiv preprint, 2026
2026
-
[2]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv 9 Geometric Routing Enables Causal Expert Control in Mixture of ExpertsA PREPRINT preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai, Chengqi Deng, Chenggang Zhao, R.X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models.arXiv preprint arXiv:2401.06066, 2024
work page internal anchor Pith review arXiv 2024
-
[4]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
2023
-
[5]
interpreting GPT: the logit lens.LessWrong, 2020
nostalgebraist. interpreting GPT: the logit lens.LessWrong, 2020
2020
-
[6]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022
2022
-
[7]
Toy models of superposition.Transformer Circuits Thread, 2022
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield- Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.Transformer Circuits Thread, 2022
2022
-
[8]
What does BERT look at? an analysis of BERT’s attention
Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. What does BERT look at? an analysis of BERT’s attention. InProceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 276–286, 2019
2019
-
[9]
BERT Rediscovers the Classical NLP Pipeline , publisher =
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline.arXiv preprint arXiv:1905.05950, 2019
-
[10]
arXiv preprint arXiv:2509.23678 , year=
Guoliang Zhao, Yuhan Fu, Shuaipeng Li, et al. Towards a comprehensive scaling law of mixture-of-experts. arXiv preprint arXiv:2509.23678, 2025
-
[11]
arXiv preprint arXiv:2507.17702 , year=
Changxin Tian, Kunlong Chen, Jia Liu, Ziqi Liu, Zhiqiang Zhang, and Jun Zhou. Towards greater leverage: Scaling laws for efficient mixture-of-experts language models.arXiv preprint arXiv:2507.17702, 2025
-
[12]
Sparse autoencoders do not find canoni- cal units of analysis.Proceedings of the International Conference on Learning Representations, 2025
Patrick Leask, Joshua Mendel, Stepan Boettiger, Nikhil Mulligan, et al. Sparse autoencoders do not find canoni- cal units of analysis.Proceedings of the International Conference on Learning Representations, 2025
2025
-
[13]
David Chanin, James Wilken-Smith, Tomáš Dulka, Hardik Bhatnagar, and Joseph Bloom. A is for absorption: Studying feature splitting and absorption in sparse autoencoders.arXiv preprint arXiv:2409.14507, 2024
-
[14]
Decomposing the dark matter of sparse autoencoders.Transactions on Machine Learning Research, 2025
Joshua Engels, Isaac Liao, and Max Tegmark. Decomposing the dark matter of sparse autoencoders.arXiv preprint arXiv:2410.14670, 2024
-
[15]
Inference-time interven- tion: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time interven- tion: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, volume 36, 2024
2024
-
[16]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Pelrine. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review arXiv 2023
-
[18]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[19]
Mohsen Fayyaz et al. SteerMoE: Steering mixture-of-experts LLMs via expert (de)activation.arXiv preprint arXiv:2509.09660, 2025
-
[20]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[22]
GShard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021
2021
-
[23]
Scaling monosemanticity: Extracting interpretable features from Claude 3 Sonnet.Transformer Circuits Thread, 2024
Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, Hoagy Cunningham, Nicholas L Turner, Callum McDougall, Monte MacDiarmid, C Daniel Freeman, Theodore R Sumers, Edward Rees, Joshua Batson, Adam Jermyn, Shan 10 Geometric Routing Enables Causal Expert Control in Mi...
2024
-
[24]
Scaling and evaluating sparse autoencoders
Leo Gao, Tom Dupré la Tour, Henk Tillman, Gabriel Goh, Rajan Troll, Alec Radford, Ilya Sutskever, Jan Leike, and Jeffrey Wu. Scaling and evaluating sparse autoencoders.arXiv preprint arXiv:2406.04093, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
Sparsity and superposition in mixture of experts.arXiv preprint arXiv:2510.23671, 2025
Tianyi Chen et al. Sparsity and superposition in mixture of experts.arXiv preprint arXiv:2510.23671, 2025
-
[26]
MONET: Mixture of monosemantic experts for transformers
Jungwoo Park, Young Jin Ahn, Kee-Eung Kim, and Jaewoo Kang. MONET: Mixture of monosemantic experts for transformers. InProceedings of the International Conference on Learning Representations, 2025
2025
-
[27]
Understanding SAE features with the logit lens.LessWrong / Alignment F orum, 2024
Joseph Bloom and Curt Tigges Lin. Understanding SAE features with the logit lens.LessWrong / Alignment F orum, 2024
2024
-
[28]
SAEs are good for steering – if you select the right features
Ido Arad, Aaron Mueller, and Yonatan Belinkov. SAEs are good for steering – if you select the right features. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[29]
Why should I trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “Why should I trust you?”: Explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016
2016
-
[30]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[31]
Ronny Luss, Erik Miehling, and Amit Dhurandhar. CELL your model: Contrastive explanations for large lan- guage models.arXiv preprint arXiv:2406.11785, 2024
-
[32]
Explaining large language models with gSMILE.arXiv preprint arXiv:2505.21657, 2025
Zeinab Dehghani, Mohammed Naveed Akram, Koorosh Aslansefat, and Adil Khan. Explaining large language models with gSMILE.arXiv preprint arXiv:2505.21657, 2025
-
[33]
Yan Wang, Yitao Xu, Nanhan Shen, Jinyan Su, Jimin Huang, and Zining Zhu. The illusion of special- ization: Unveiling the domain-invariant “standing committee” in mixture-of-experts models.arXiv preprint arXiv:2601.03425, 2026. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.