Recognition: unknown
MARCA: A Checklist-Based Benchmark for Multilingual Web Search
Pith reviewed 2026-05-10 12:51 UTC · model grok-4.3
The pith
MARCA uses 52 checklist-scored questions to test how well LLMs seek and synthesize web information in English and Portuguese.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
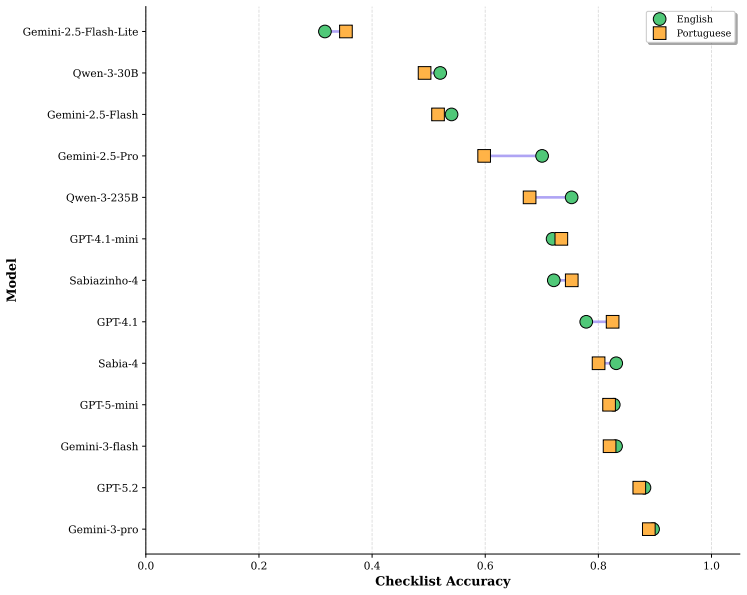
MARCA consists of 52 manually authored multi-entity questions in English and Portuguese, each accompanied by manually validated checklist-style rubrics that measure answer completeness and correctness. When 14 models are run under both a basic web-search framework and an orchestrator framework that delegates subtasks, the benchmark records large performance spreads, frequent gains from orchestration, and inconsistent transfer of capability between the two languages.
What carries the argument
Checklist-style rubrics paired with multi-entity questions that explicitly score completeness and correctness of web-sourced answers.
If this is right
- Orchestration that breaks tasks into delegated subagents improves answer coverage on web search questions.
- Models exhibit large differences in overall performance and in how reliably they move from English to Portuguese.
- Run-level repetition with uncertainty reporting makes performance differences more visible than single-run tests.
- Checklist rubrics give finer-grained signals on completeness than typical accuracy-only metrics.
Where Pith is reading between the lines
- The same checklist method could be applied to additional languages to test broader multilingual coverage.
- Manual rubrics may lower evaluator bias compared with free-form human judgments of open-ended answers.
- The gap between basic and orchestrated settings suggests agent-style decomposition is especially helpful when language transfer is weak.
Load-bearing premise
The 52 questions and their rubrics give a reliable, unbiased, and sufficiently broad picture of how LLMs handle real-world multilingual web information seeking.
What would settle it
A fresh set of questions or an automated rubric system that produces markedly different model rankings or coverage scores would indicate the current benchmark does not generalize.
Figures




read the original abstract
Large language models (LLMs) are increasingly used as sources of information, yet their reliability depends on the ability to search the web, select relevant evidence, and synthesize complete answers. While recent benchmarks evaluate web-browsing and agentic tool use, multilingual settings, and Portuguese in particular, remain underexplored. We present \textsc{MARCA}, a bilingual (English and Portuguese) benchmark for evaluating LLMs on web-based information seeking. \textsc{MARCA} consists of 52 manually authored multi-entity questions, paired with manually validated checklist-style rubrics that explicitly measure answer completeness and correctness. We evaluate 14 models under two interaction settings: a Basic framework with direct web search and scraping, and an Orchestrator framework that enables task decomposition via delegated subagents. To capture stochasticity, each question is executed multiple times and performance is reported with run-level uncertainty. Across models, we observe large performance differences, find that orchestration often improves coverage, and identify substantial variability in how models transfer from English to Portuguese. The benchmark is available at https://github.com/maritaca-ai/MARCA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MARCA, a bilingual (English and Portuguese) benchmark for evaluating LLMs on web-based information seeking. MARCA consists of 52 manually authored multi-entity questions paired with manually validated checklist-style rubrics that measure answer completeness and correctness. The authors evaluate 14 models under two interaction settings (Basic direct web search and Orchestrator with delegated subagents), execute each question multiple times to capture stochasticity, and report performance with run-level uncertainty. They observe large performance gaps across models, benefits from orchestration for coverage, and variability in English-to-Portuguese transfer.
Significance. If the construction details hold, MARCA would fill an important gap by providing an explicit, checklist-based evaluation of completeness and correctness in multilingual web information seeking, with particular value for the underexplored Portuguese setting. The public release, use of uncertainty estimates, and comparison of two interaction frameworks strengthen its utility as a reproducible benchmark for the community.
major comments (1)
- [§3] §3 (Benchmark Construction): The paper states that questions were manually authored and rubrics manually validated but provides no details on the rubric validation process, question selection criteria, or inter-annotator agreement. These omissions leave the central measurement claim only partially supported, as the reliability of the checklists for assessing completeness and correctness cannot be fully assessed from the current description.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of MARCA's value for the underexplored Portuguese setting, and recommendation of minor revision. We address the single major comment below and will revise the manuscript accordingly to strengthen the description of benchmark reliability.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The paper states that questions were manually authored and rubrics manually validated but provides no details on the rubric validation process, question selection criteria, or inter-annotator agreement. These omissions leave the central measurement claim only partially supported, as the reliability of the checklists for assessing completeness and correctness cannot be fully assessed from the current description.
Authors: We agree that §3 would be strengthened by explicit details on construction and validation, as these directly support the reliability of the completeness and correctness measurements. In the revised manuscript we will expand §3 with: (1) question selection criteria, including the process for authoring the 52 multi-entity questions to ensure topical diversity, balanced entity counts, and parallel English/Portuguese coverage; (2) the rubric validation protocol, describing how checklists were iteratively reviewed and refined by the authors to confirm that each item captures all necessary facts without over- or under-specification; and (3) inter-annotator agreement statistics computed during validation (or a clear statement of the expert-driven single-pass protocol if full IAA was not applicable). These additions will make the central measurement claims more transparent and reproducible while preserving the existing experimental results. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark release paper. The central contribution is the manual creation of 52 multi-entity questions and associated checklist rubrics, followed by direct evaluation of 14 models under two interaction frameworks with run-level uncertainty. No equations, parameter fitting, predictions derived from inputs, or self-citation chains appear in the described construction or evaluation. The benchmark is presented as a new artifact whose validity rests on the transparency of its manual authoring and validation process, which does not reduce to any self-referential step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manually validated checklist rubrics can accurately and objectively measure answer completeness and correctness
Reference graph
Works this paper leans on
-
[1]
Poeta v2: Toward more robust evaluation of large language models in portuguese
Thales Rogério Sales Almeida, Ramon Pires, Hugo Abonizio, Rodrigo Nogueira, and Helio Pedrini. Poeta v2: Toward more robust evaluation of large language models in portuguese. IEEE Access, 13:214180–214200, 2025
2025
-
[2]
Thales Sales Almeida, Giovana Kerche Bonás, João Guilherme Alves Santos, Hugo Abonizio, and Rodrigo Nogueira. Tiebe: Tracking language model recall of notable worldwide events through time.arXiv preprint arXiv:2501.07482, 2025
-
[3]
Bluex: A benchmark based on brazilian leading universities entrance exams
Thales Sales Almeida, Thiago Laitz, Giovana K Bonás, and Rodrigo Nogueira. Bluex: A benchmark based on brazilian leading universities entrance exams. InBrazilian Conference on Intelligent Systems, pages 337–347. Springer, 2023
2023
-
[4]
Laura Winther Balling, Michael Carl, and Sharon O’Brian
Thales Sales Almeida, João Guilherme Alves Santos, Thiago Laitz, and Giovana Kerche Bonás. Ticket-bench: A kickoff for multilingual and regionalized agent evaluation.arXiv preprint arXiv:2509.14477, 2025. 11
-
[5]
arXiv preprint arXiv:2108.13897 , year=
Luiz Bonifacio, Vitor Jeronymo, Hugo Queiroz Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo Nogueira. mmarco: A multilingual version of the ms marco passage ranking dataset.arXiv preprint arXiv:2108.13897, 2021
-
[6]
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, et al. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent.arXiv preprint arXiv:2508.06600, 2025
-
[7]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[9]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents.arXiv preprint arXiv:2506.11763, 2025
-
[10]
Gemini 3 - Google DeepMind.https://deepmind.google/models/ gemini/, 2025
Google DeepMind. Gemini 3 - Google DeepMind.https://deepmind.google/models/ gemini/, 2025. Accessed: 2026-03-21
2025
-
[11]
Sabi\’a-4 technical report.arXiv preprint arXiv:2603.10213, 2026
ThiagoLaitz, ThalesSalesAlmeida, HugoAbonizio, RosevalMalaquiasJunior, GiovanaKerche Bonás, Marcos Piau, Celio Larcher, Ramon Pires, and Rodrigo Nogueira. Sabi\’a-4 technical report.arXiv preprint arXiv:2603.10213, 2026
-
[12]
Mm-browsecomp: A comprehensive benchmark for multimodal browsing agents, 2025b.URL https://arxiv
Shilong Li, Xingyuan Bu, Wenjie Wang, Jiaheng Liu, Jun Dong, Haoyang He, Hao Lu, Haozhe Zhang, Chenchen Jing, Zhen Li, et al. Mm-browsecomp: A comprehensive benchmark for multimodal browsing agents.arXiv preprint arXiv:2508.13186, 2025
-
[13]
Search arena: Analyzing search-augmented llms.arXiv preprint arXiv:2506.05334, 2025
Mihran Miroyan, Tsung-Han Wu, Logan King, Tianle Li, Jiayi Pan, Xinyan Hu, Wei-Lin Chiang, Anastasios N Angelopoulos, Trevor Darrell, Narges Norouzi, et al. Search arena: Analyzing search-augmented llms.arXiv preprint arXiv:2506.05334, 2025
-
[14]
Atsuyuki Miyai, Zaiying Zhao, Kazuki Egashira, Atsuki Sato, Tatsumi Sunada, Shota Ono- hara, Hiromasa Yamanishi, Mashiro Toyooka, Kunato Nishina, Ryoma Maeda, et al. Web- chorearena: Evaluating web browsing agents on realistic tedious web tasks.arXiv preprint arXiv:2506.01952, 2025
-
[15]
Worldbench: Quantifying geographic dispar- ities in llm factual recall
Mazda Moayeri, Elham Tabassi, and Soheil Feizi. Worldbench: Quantifying geographic dispar- ities in llm factual recall. InProceedings of the 2024 ACM Conference on Fairness, Account- ability, and Transparency, pages 1211–1228, 2024
2024
-
[16]
Blend: Abenchmarkfor llms on everyday knowledge in diverse cultures and languages.Advances in Neural Information Processing Systems, 37:78104–78146, 2024
Junho Myung, Nayeon Lee, Yi Zhou, Jiho Jin, Rifki A Putri, Dimosthenis Antypas, Hsuvas Borkakoty, EunsuKim, CarlaPerez-Almendros, AbinewAAyele, etal. Blend: Abenchmarkfor llms on everyday knowledge in diverse cultures and languages.Advances in Neural Information Processing Systems, 37:78104–78146, 2024
2024
-
[17]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christo- pher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser- assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332, 2021. 12
work page internal anchor Pith review arXiv 2021
-
[18]
Introducing GPT-4.1.https://openai.com/index/gpt-4-1/, April 2025
OpenAI. Introducing GPT-4.1.https://openai.com/index/gpt-4-1/, April 2025. Accessed: 2025-03-21
2025
-
[19]
Introducing GPT-5.https://openai.com/index/introducing-gpt-5/, 2025
OpenAI. Introducing GPT-5.https://openai.com/index/introducing-gpt-5/, 2025. Ac- cessed: 2025-03-21
2025
-
[20]
Introducing GPT-5.2.https://openai.com/index/introducing-gpt-5-2/, Decem- ber 2025
OpenAI. Introducing GPT-5.2.https://openai.com/index/introducing-gpt-5-2/, Decem- ber 2025. Accessed: 2025-03-21
2025
-
[21]
Ramon Pires, Thales Sales Almeida, Hugo Abonizio, and Rodrigo Nogueira. Evaluating gpt-4’s vision capabilities on brazilian university admission exams.arXiv preprint arXiv:2311.14169, 2023
-
[22]
Automatic legal writing evalu- ation of llms
Ramon Pires, Roseval Malaquias Junior, and Rodrigo Nogueira. Automatic legal writing evalu- ation of llms. InProceedings of the Twentieth International Conference on Artificial Intelligence and Law, pages 420–424, 2025
2025
-
[23]
arXiv preprint arXiv:2411.19799 , year=
Angelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Mohamed A Haggag, Alfonso Amayue- las, et al. Include: Evaluating multilingual language understanding with regional knowledge. arXiv preprint arXiv:2411.19799, 2024
-
[24]
João Guilherme Alves Santos, Giovana Kerche Bonás, and Thales Sales Almeida. Bluex revisited: Enhancing benchmark coverage with automatic captioning.arXiv preprint arXiv:2508.21294, 2025
-
[25]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review arXiv 2025
-
[26]
All languages matter: Evaluating lmms on culturally diverse 100 languages
Ashmal Vayani, Dinura Dissanayake, Hasindri Watawana, Noor Ahsan, Nevasini Sasiku- mar, Omkar Thawakar, Henok Biadglign Ademtew, Yahya Hmaiti, Amandeep Kumar, Kartik Kukreja, et al. All languages matter: Evaluating lmms on culturally diverse 100 languages. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19565–19575, 2025
2025
-
[27]
LiveResearchBench: A Live Benchmark for User-Centric Deep Research in the Wild
Jiayu Wang, Yifei Ming, Riya Dulepet, Qinglin Chen, Austin Xu, Zixuan Ke, Frederic Sala, Aws Albarghouthi, Caiming Xiong, and Shafiq Joty. Liveresearchbench: A live benchmark for user-centric deep research in the wild.arXiv preprint arXiv:2510.14240, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
work page internal anchor Pith review arXiv 2025
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Miracl: A multilingual re- trievaldatasetcovering18diverselanguages.Transactions of the Association for Computational Linguistics, 11:1114–1131, 2023
Xinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, and Jimmy Lin. Miracl: A multilingual re- trievaldatasetcovering18diverselanguages.Transactions of the Association for Computational Linguistics, 11:1114–1131, 2023. 13
2023
-
[31]
Yunfan Zhang, Kathleen McKeown, and Smaranda Muresan. Livenewsbench: Evaluating llm web search capabilities with freshly curated news.arXiv preprint arXiv:2602.13543, 2026
-
[32]
Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, et al. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese.arXiv preprint arXiv:2504.19314, 2025
-
[33]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 14
work page Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.