Recognition: unknown
Psychological Steering of Large Language Models
Pith reviewed 2026-05-10 12:41 UTC · model grok-4.3
The pith
Mean-difference injections outperform prompting for steering OCEAN personality traits in most LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that mean-difference (MD) injections derived from the IPIP-NEO-120 personality questionnaire outperform Personality Prompting (P²) in open-ended generation tasks for OCEAN traits in 11 of 14 LLMs, achieving gains between 3.6% and 16.4%. A hybrid method combining P² and MD injections surpasses both individual methods in 13 of 14 LLMs. MD injections are shown to align with the Linear Representation Hypothesis, acting as approximately linear control mechanisms, while also producing trait covariance patterns that differ from the human Big Two model.
What carries the argument
Mean-difference (MD) injections: additive vectors in the residual stream calculated as the difference in activations between high- and low-scoring responses on OCEAN questionnaire items, calibrated for semantic meaning and fluency.
If this is right
- MD injections deliver superior trait steering compared to prompting in the majority of evaluated models.
- Hybrid steering combining injections and prompts achieves the highest performance gains.
- These injections provide roughly linear control over individual traits as predicted by representation hypotheses.
- Steered models exhibit covariance among OCEAN traits that does not match standard human psychology models.
Where Pith is reading between the lines
- Similar injection techniques might extend to steering other behavioral attributes like decision-making styles or emotional responses.
- Developers could use this to create LLMs with more consistent and targeted personalities for specific applications such as customer service or education.
- The observed differences in trait covariances could point to unique ways LLMs organize psychological concepts compared to humans.
- Further experiments might explore whether these methods reduce unwanted side effects like reduced fluency or coherence in long generations.
Load-bearing premise
That the OCEAN trait scores derived from analyzing LLM responses to the IPIP-NEO-120 questionnaire validly reflect the actual personality traits being steered, without distortions caused by the steering process itself.
What would settle it
A study that measures the steered traits using an independent method, such as direct behavioral tasks or a different questionnaire not used in the calibration, and finds no advantage for MD injections over prompting would disprove the main performance claims.
Figures



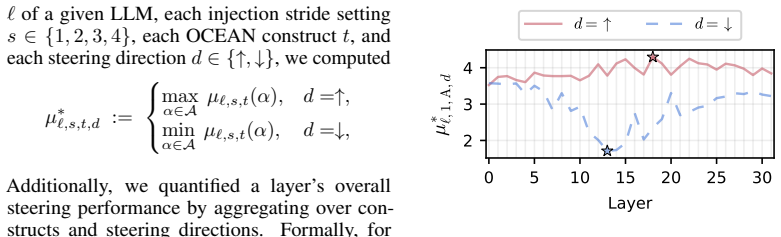
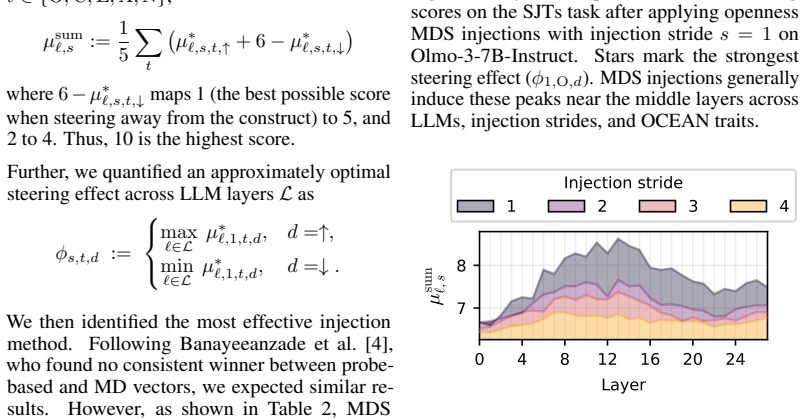
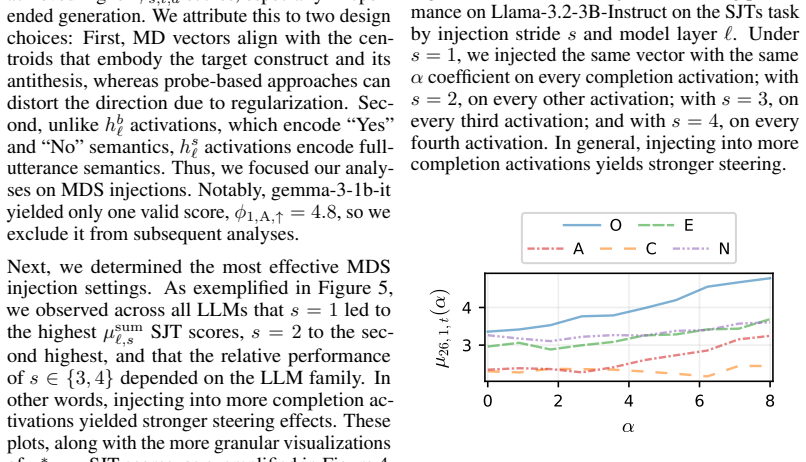






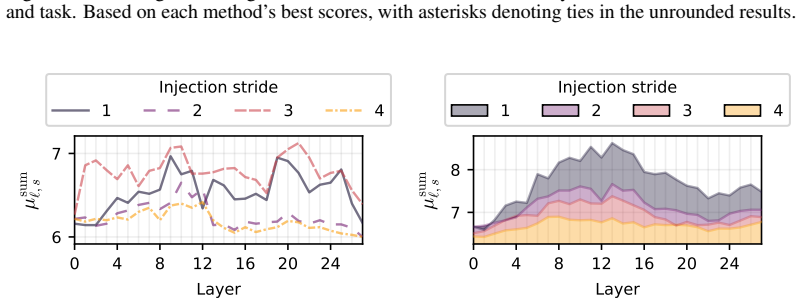

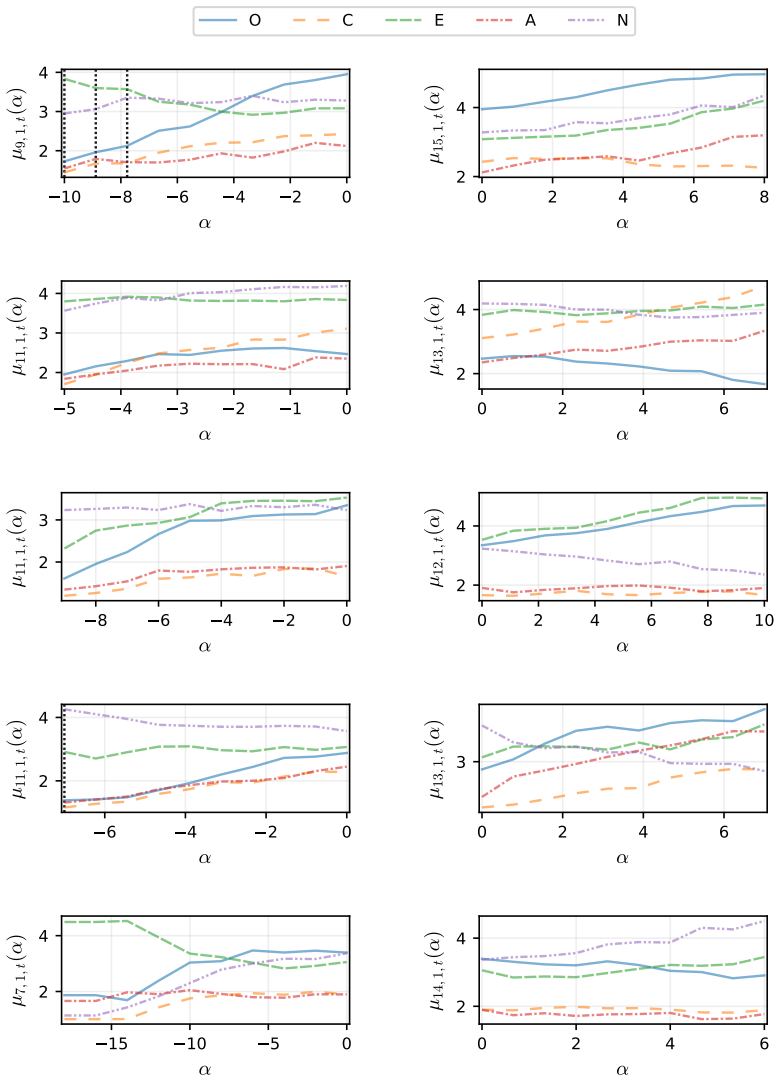

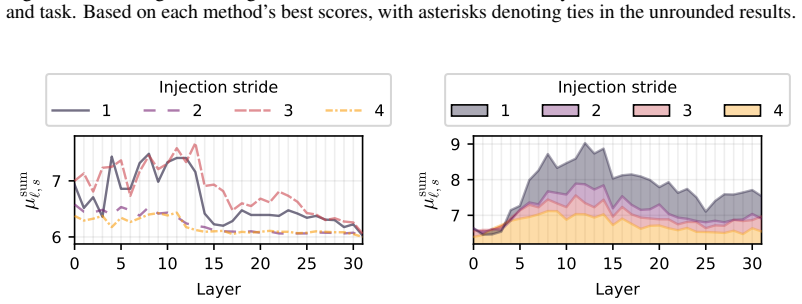








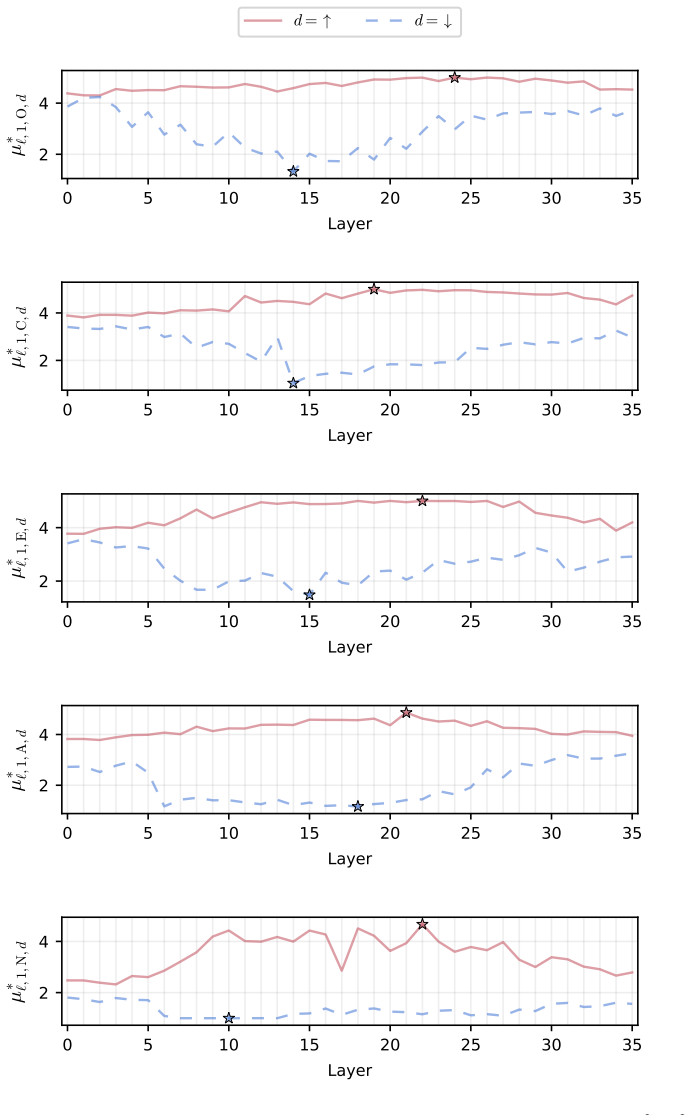

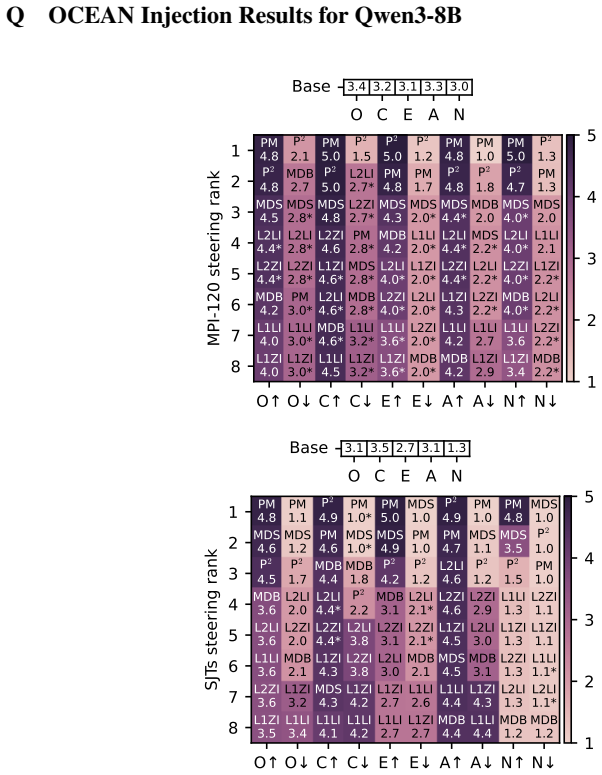
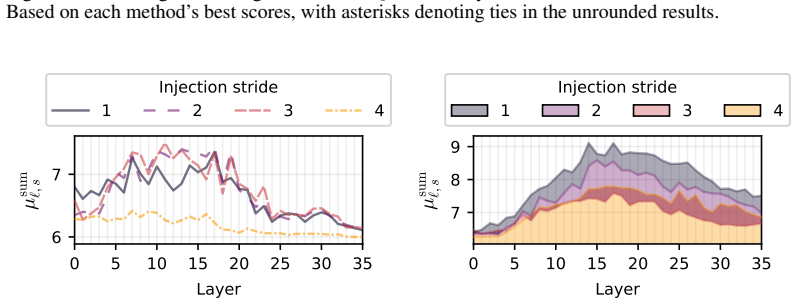
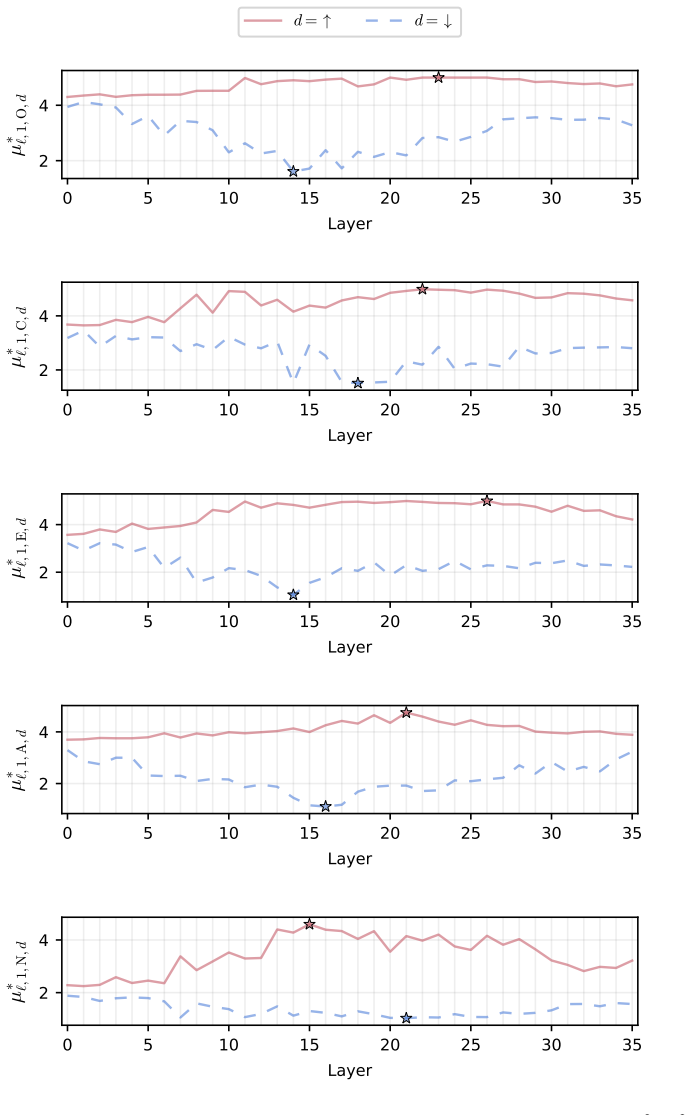






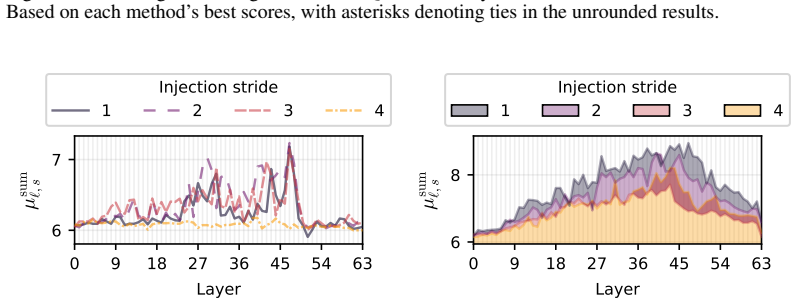

















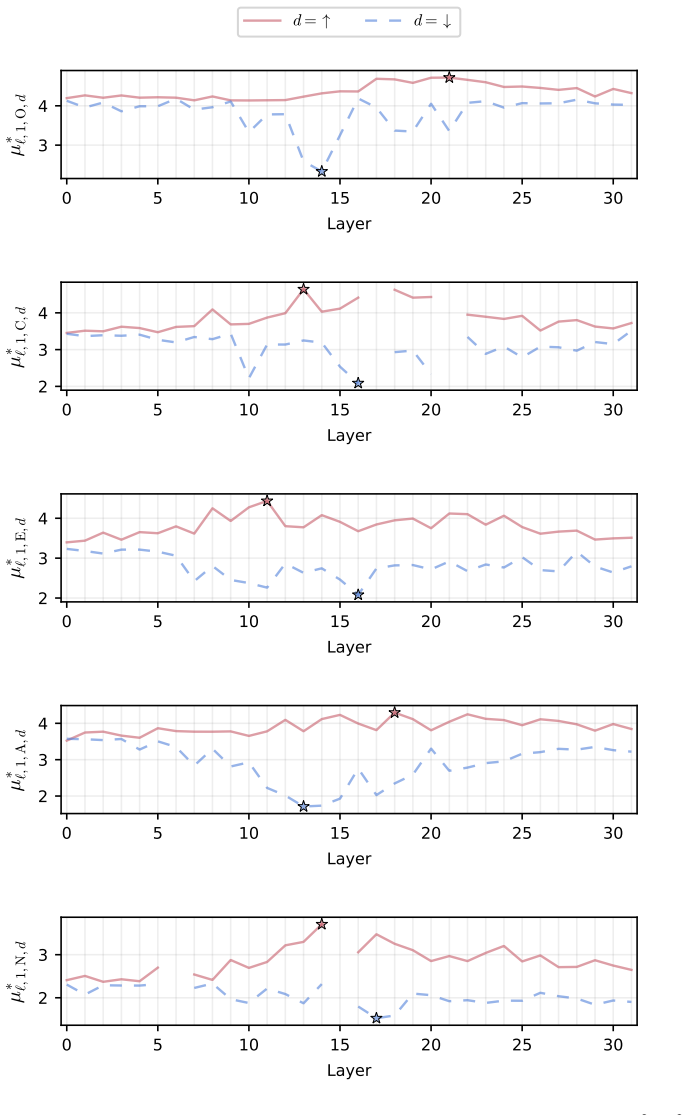





read the original abstract
Large language models (LLMs) emulate a consistent human-like behavior that can be shaped through activation-level interventions. This paradigm is converging on additive residual-stream injections, which rely on injection-strength sweeps to approximate optimal intervention settings. However, existing methods restrict the search space and sweep in uncalibrated activation-space units, potentially missing optimal intervention conditions. Thus, we introduce a psychological steering framework that performs unbounded, fluency-constrained sweeps in semantically calibrated units. Our method derives and calibrates residual-stream injections using psychological artifacts, and we use the IPIP-NEO-120, which measures the OCEAN personality model, to compare six injection methods. We find that mean-difference (MD) injections outperform Personality Prompting (P$^2$), an established baseline for OCEAN steering, in open-ended generation in 11 of 14 LLMs, with gains of 3.6\% to 16.4\%, overturning prior reports favoring prompting and positioning representation engineering as a new frontier in open-ended psychological steering. Further, we find that a hybrid of P$^2$ and MD injections outperforms both methods in 13 of 14 LLMs, with gains over P$^2$ ranging from 5.6\% to 21.9\% and from 3.3\% to 26.7\% over MD injections. Finally, we show that MD injections align with the Linear Representation Hypothesis and provide reliable, approximately linear control knobs for psychological steering. Nevertheless, they also induce OCEAN trait covariance patterns that depart from the Big Two model, suggesting a gap between learned representations and human psychology.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a psychological steering framework for LLMs that performs unbounded, fluency-constrained sweeps of additive residual-stream injections in semantically calibrated units derived from psychological artifacts. Using scores from the IPIP-NEO-120 questionnaire extracted from open-ended generations, it compares six injection methods across 14 LLMs and reports that mean-difference (MD) injections outperform Personality Prompting (P²) in 11 of 14 models (gains 3.6%–16.4%), while a hybrid of P² and MD outperforms both in 13 of 14 models (gains 5.6%–21.9% over P² and 3.3%–26.7% over MD). The work further claims that MD injections align with the Linear Representation Hypothesis, provide approximately linear control, and induce OCEAN trait covariance patterns that depart from the Big Two model.
Significance. If the empirical comparisons hold after addressing measurement concerns, the paper would be significant for establishing representation engineering as a competitive or superior alternative to prompting for open-ended psychological steering in LLMs. The large-scale evaluation across 14 models, the hybrid method's consistent gains, and the explicit linkage to the Linear Representation Hypothesis provide concrete evidence that could shift research focus toward activation-level interventions. The observation of non-human-like covariance patterns also offers a useful cautionary note on the limits of mapping LLM representations to human psychological models.
major comments (3)
- [Results section (performance tables and extraction procedure)] The headline results (MD outperforming P² in 11/14 models and hybrid in 13/14) depend entirely on IPIP-NEO-120 trait scores extracted from steered open-ended generations. The manuscript provides no consistency checks, cross-method validation, or external corroboration (e.g., human ratings) to demonstrate that the extraction procedure yields unbiased scores rather than method-specific artifacts that could systematically favor MD injections over P². This is load-bearing for the central claim.
- [Method section (steering framework and calibration)] The method section describes unbounded sweeps in 'semantically calibrated units' derived from psychological artifacts, but does not specify the exact calibration procedure, the fluency constraint implementation, or how the search avoids post-hoc selection effects. Without these details, it is unclear whether the reported superiority of MD and hybrid methods is robust or sensitive to implementation choices.
- [Discussion section (trait covariance analysis)] The discussion notes that MD injections produce OCEAN trait covariance patterns departing from the Big Two model, yet provides no quantitative measure of this departure (e.g., correlation matrices or statistical tests) or analysis of whether this undermines the use of OCEAN as the evaluation target.
minor comments (2)
- [Abstract] The abstract refers to 'six injection methods' without enumerating them; a brief list would improve readability.
- [Results tables] Performance tables reporting percentage gains would benefit from accompanying statistical significance tests or confidence intervals to support the cross-model claims.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation for major revision. We address each of the three major comments below, providing clarifications where possible and committing to specific revisions that will strengthen the empirical rigor and transparency of the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Results section (performance tables and extraction procedure)] The headline results (MD outperforming P² in 11/14 models and hybrid in 13/14) depend entirely on IPIP-NEO-120 trait scores extracted from steered open-ended generations. The manuscript provides no consistency checks, cross-method validation, or external corroboration (e.g., human ratings) to demonstrate that the extraction procedure yields unbiased scores rather than method-specific artifacts that could systematically favor MD injections over P². This is load-bearing for the central claim.
Authors: We agree that the validity of the IPIP-NEO-120 extraction from open-ended text is critical to the headline comparisons. The same extraction pipeline is applied uniformly to all methods, which preserves the validity of relative performance differences, but we acknowledge that method-specific artifacts cannot be ruled out without further checks. In the revised manuscript we will add: (1) consistency checks via repeated sampling with different seeds and reporting of score variance; (2) cross-validation against an alternative inventory (e.g., a short-form Big Five measure) on a subset of generations; and (3) a discussion of why semantic calibration of the injection vectors makes systematic bias toward MD unlikely. We will also note the absence of human ratings as a limitation and outline how future work could obtain them. revision: yes
-
Referee: [Method section (steering framework and calibration)] The method section describes unbounded sweeps in 'semantically calibrated units' derived from psychological artifacts, but does not specify the exact calibration procedure, the fluency constraint implementation, or how the search avoids post-hoc selection effects. Without these details, it is unclear whether the reported superiority of MD and hybrid methods is robust or sensitive to implementation choices.
Authors: We accept that the method section was insufficiently detailed. The calibration derives injection vectors as the mean-difference of residual-stream activations on high- versus low-trait psychological artifact prompts, normalized to unit length; the fluency constraint thresholds generations by a perplexity-based fluency score computed on a held-out set of neutral prompts; and the search reports the strength that maximizes the target trait score subject to the fluency threshold, with the threshold itself fixed before seeing test results. In the revision we will insert a dedicated subsection with the exact procedure, pseudocode, and all hyperparameters (including the fluency threshold value and validation-set size) so that the experiments are fully reproducible. revision: yes
-
Referee: [Discussion section (trait covariance analysis)] The discussion notes that MD injections produce OCEAN trait covariance patterns departing from the Big Two model, yet provides no quantitative measure of this departure (e.g., correlation matrices or statistical tests) or analysis of whether this undermines the use of OCEAN as the evaluation target.
Authors: We will expand the discussion with the requested quantitative analysis. The revised version will include: (i) the full 5×5 OCEAN correlation matrix for MD-steered generations across the 14 models; (ii) the corresponding human-norm matrix from the IPIP-NEO-120 validation data; and (iii) a statistical comparison (e.g., a test of matrix equality or Mantel test) quantifying the departure. We will also discuss the implications for OCEAN as an evaluation target, noting that while the departure indicates LLM representations do not perfectly mirror human trait structure, OCEAN remains a useful, standardized metric for measuring steering efficacy. revision: yes
Circularity Check
No circularity: empirical comparisons rest on external instrument
full rationale
The paper's load-bearing results are direct empirical comparisons (MD outperforming P² in 11/14 LLMs, hybrid in 13/14) obtained by applying the independent IPIP-NEO-120 questionnaire to open-ended generations. No equations, fitted parameters, or self-citations are shown that would make the reported gains reduce to quantities defined in terms of the steering methods themselves. The calibration procedure and linear-representation finding are presented as methodological choices and observations, not as premises that tautologically produce the performance ordering. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The IPIP-NEO-120 can be validly scored on LLM-generated text to measure OCEAN traits
- domain assumption Residual-stream injections can be meaningfully calibrated in semantically meaningful units
Reference graph
Works this paper leans on
-
[1]
Wiles, and Vlad Grankovsky
Rumi Allbert, James K. Wiles, and Vlad Grankovsky. Identifying and manipulating personality traits in llms through activation engineering, 2025. URL https://arxiv.org/abs/2412. 10427
2025
-
[2]
Empirical, theoretical, and practical advantages of the hexaco model of personality structure.Personality and social psychology review, 11(2):150–166, 2007
Michael C Ashton and Kibeom Lee. Empirical, theoretical, and practical advantages of the hexaco model of personality structure.Personality and social psychology review, 11(2):150–166, 2007
2007
-
[3]
The hexaco–60: A short measure of the major dimensions of personality.Journal of personality assessment, 91(4):340–345, 2009
Michael C Ashton and Kibeom Lee. The hexaco–60: A short measure of the major dimensions of personality.Journal of personality assessment, 91(4):340–345, 2009
2009
-
[4]
Tak, Fatemeh Bahrani, Anahita Bolourani, Leonardo Blas, Emilio Ferrara, Jonathan Gratch, and Sai Praneeth Karimireddy
Amin Banayeeanzade, Ala N. Tak, Fatemeh Bahrani, Anahita Bolourani, Leonardo Blas, Emilio Ferrara, Jonathan Gratch, and Sai Praneeth Karimireddy. Psychological steering in llms: An evaluation of effectiveness and trustworthiness, 2025. URL https://arxiv.org/abs/2510. 04484
2025
-
[5]
Pranav Bhandari, Nicolas Fay, Sanjeevan Selvaganapathy, Amitava Datta, Usman Naseem, and Mehwish Nasim. Activation-space personality steering: Hybrid layer selection for stable trait control in llms.arXiv preprint arXiv:2511.03738, 2025
-
[6]
Behavioral confirmation of everyday sadism.Psychological science, 24(11):2201–2209, 2013
Erin E Buckels, Daniel N Jones, and Delroy L Paulhus. Behavioral confirmation of everyday sadism.Psychological science, 24(11):2201–2209, 2013
2013
-
[7]
Persona Vectors: Monitoring and Controlling Character Traits in Language Models
Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, and Jack Lindsey. Persona vectors: Monitoring and controlling character traits in language models, 2025. URL https://arxiv. org/abs/2507.21509
work page internal anchor Pith review arXiv 2025
-
[8]
Moral foun- dations vignettes: A standardized stimulus database of scenarios based on moral foundations theory.Behavior research methods, 47(4):1178–1198, 2015
Scott Clifford, Vijeth Iyengar, Roberto Cabeza, and Walter Sinnott-Armstrong. Moral foun- dations vignettes: A standardized stimulus database of scenarios based on moral foundations theory.Behavior research methods, 47(4):1178–1198, 2015
2015
-
[9]
P-react: Synthesizing topic- adaptive reactions of personality traits via mixture of specialized LoRA experts
Yuhao Dan, Jie Zhou, Qin Chen, Junfeng Tian, and Liang He. P-react: Synthesizing topic- adaptive reactions of personality traits via mixture of specialized LoRA experts. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 6342–6362, Vienna, Austria, July
2025
-
[11]
Neuron based personality trait induction in large language models
Jia Deng, Tianyi Tang, Yanbin Yin, Wenhao Yang, Xin Zhao, and Ji-Rong Wen. Neuron based personality trait induction in large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URLhttps://openreview.net/forum?id=LYHEY783Np
2025
-
[12]
Higher-order factors of the big five predict conformity: Are there neuroses of health?Personality and Individual differences, 33(4):533–552, 2002
Colin G DeYoung, Jordan B Peterson, and Daniel M Higgins. Higher-order factors of the big five predict conformity: Are there neuroses of health?Personality and Individual differences, 33(4):533–552, 2002
2002
-
[13]
Higher-order factors of the big five.Journal of personality and social psychology, 73(6):1246, 1997
John M Digman. Higher-order factors of the big five.Journal of personality and social psychology, 73(6):1246, 1997
1997
-
[14]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review arXiv 2022
-
[15]
Shangbin Feng, Chan Young Park, Yuhan Liu, and Yulia Tsvetkov. From pretraining data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, editors,Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1:...
-
[16]
PERSONA: Dynamic and compositional inference-time personality control via activation vector algebra
Xiachong Feng, Liang Zhao, Weihong Zhong, Yichong Huang, Yuxuan Gu, Lingpeng Kong, Xiaocheng Feng, and Bing Qin. PERSONA: Dynamic and compositional inference-time personality control via activation vector algebra. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=QZvGqaNBlU
2026
-
[17]
Measurement of character.Fortnightly review, May 1865-June 1934, 36(212): 179–185, 08 1884
Francis Galton. Measurement of character.Fortnightly review, May 1865-June 1934, 36(212): 179–185, 08 1884
1934
-
[18]
The structure of phenotypic personality traits.American psychologist, 48 (1):26, 1993
Lewis R Goldberg. The structure of phenotypic personality traits.American psychologist, 48 (1):26, 1993
1993
-
[19]
A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several five-factor models.Personality psychology in Europe, 7(1): 7–28, 1999
Lewis R Goldberg et al. A broad-bandwidth, public domain, personality inventory measuring the lower-level facets of several five-factor models.Personality psychology in Europe, 7(1): 7–28, 1999
1999
-
[20]
Mapping the moral domain.Journal of personality and social psychology, 101(2):366, 2011
Jesse Graham, Brian A Nosek, Jonathan Haidt, Ravi Iyer, Spassena Koleva, and Peter H Ditto. Mapping the moral domain.Journal of personality and social psychology, 101(2):366, 2011
2011
-
[21]
Moral foundations theory: The pragmatic validity of moral pluralism
Jesse Graham, Jonathan Haidt, Sena Koleva, Matt Motyl, Ravi Iyer, Sean P Wojcik, and Peter H Ditto. Moral foundations theory: The pragmatic validity of moral pluralism. InAdvances in experimental social psychology, volume 47, pages 55–130. Elsevier, 2013
2013
-
[22]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ah- mad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
STEER: Unified style transfer with expert reinforcement
Skyler Hallinan, Faeze Brahman, Ximing Lu, Jaehun Jung, Sean Welleck, and Yejin Choi. STEER: Unified style transfer with expert reinforcement. In Houda Bouamor, Juan Pino, 12 and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 7546–7562, Singapore, December 2023. Association for Computational Linguis- tics...
-
[24]
How do transformers learn to associate to- kens: Gradient leading terms bring mechanistic interpretability
Shawn Im, Changdae Oh, Zhen Fang, and Sharon Li. How do transformers learn to associate to- kens: Gradient leading terms bring mechanistic interpretability. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=A4Us8jxVGq
2026
-
[25]
Evaluating and inducing personality in pre-trained language models.Advances in Neural Information Processing Systems, 36:10622–10643, 2023
Guangyuan Jiang, Manjie Xu, Song-Chun Zhu, Wenjuan Han, Chi Zhang, and Yixin Zhu. Evaluating and inducing personality in pre-trained language models.Advances in Neural Information Processing Systems, 36:10622–10643, 2023
2023
-
[26]
Hang Jiang, Xiajie Zhang, Xubo Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. Per- sonaLLM: Investigating the ability of large language models to express personality traits. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Findings of the Association for Com- putational Linguistics: NAACL 2024, pages 3605–3627, Mexico City, Mexico, June 2024. Ass...
-
[27]
Ai as a partner in assessment: generating situational judgment tests with large language models.BMC psychology, 13(1):1315, 2025
Liming Jiang, Fang Luo, and Xuetao Tian. Ai as a partner in assessment: generating situational judgment tests with large language models.BMC psychology, 13(1):1315, 2025
2025
-
[28]
Measuring thirty facets of the five factor model with a 120-item public domain inventory: Development of the ipip-neo-120.Journal of research in personality, 51:78–89, 2014
John A Johnson. Measuring thirty facets of the five factor model with a 120-item public domain inventory: Development of the ipip-neo-120.Journal of research in personality, 51:78–89, 2014
2014
-
[29]
Introducing the short dark triad (sd3) a brief measure of dark personality traits.Assessment, 21(1):28–41, 2014
Daniel N Jones and Delroy L Paulhus. Introducing the short dark triad (sd3) a brief measure of dark personality traits.Assessment, 21(1):28–41, 2014
2014
-
[30]
Estimating the personality of white-box language models, 2023
Saketh Reddy Karra, Son The Nguyen, and Theja Tulabandhula. Estimating the personality of white-box language models, 2023. URLhttps://arxiv.org/abs/2204.12000
-
[31]
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav)
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning, pages 2668–2677. PMLR, 2018
2018
-
[32]
Prometheus 2: An open source language model specialized in evaluating other language models
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods i...
2024
-
[33]
Prometheus 2: An open source language model specialized in evaluating other language models
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.248. URLhttps://aclanthology.org/2024.emnlp-main.248/
-
[34]
Reformulating unsupervised style transfer as paraphrase generation
Kalpesh Krishna, John Wieting, and Mohit Iyyer. Reformulating unsupervised style transfer as paraphrase generation. InEmpirical Methods in Natural Language Processing, 2020
2020
-
[35]
Seungbeen Lee, Seungwon Lim, Seungju Han, Giyeong Oh, Hyungjoo Chae, Jiwan Chung, Minju Kim, Beong-woo Kwak, Yeonsoo Lee, Dongha Lee, Jinyoung Yeo, and Youngjae Yu. Do LLMs have distinct and consistent personality? TRAIT: Personality testset designed for LLMs with psychometrics. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Associati...
-
[36]
Development and evaluation of a new short form of the conformity to masculine norms inventory (cmni-30).Journal of Counseling Psychology, 67(5):622, 2020
Ronald F Levant, Ryon McDermott, Mike C Parent, Nuha Alshabani, James R Mahalik, and Joseph H Hammer. Development and evaluation of a new short form of the conformity to masculine norms inventory (cmni-30).Journal of Counseling Psychology, 67(5):622, 2020. 13
2020
-
[37]
Inference- time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model. InThirty-seventh Con- ference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/ forum?id=aLLuYpn83y
2023
-
[38]
Wenkai Li, Jiarui Liu, Andy Liu, Xuhui Zhou, Mona T. Diab, and Maarten Sap. BIG5-CHAT: Shaping LLM personalities through training on human-grounded data. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pa...
-
[39]
Style transfer with multi-iteration preference optimization
Shuai Liu and Jonathan May. Style transfer with multi-iteration preference optimization. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 2663–2681, Albuquerque, New Mexico, April
2025
-
[40]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/ 2025.naacl-long.135. URLhttps://aclanthology.org/2025.naacl-long.135/
-
[41]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach, 2019. URLhttps://arxiv.org/abs/1907.11692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
Development of the conformity to masculine norms inventory.Psychology of men & masculinity, 4(1):3, 2003
James R Mahalik, Benjamin D Locke, Larry H Ludlow, Matthew A Diemer, Ryan PJ Scott, Michael Gottfried, and Gary Freitas. Development of the conformity to masculine norms inventory.Psychology of men & masculinity, 4(1):3, 2003
2003
-
[43]
Development of the conformity to feminine norms inventory.Sex Roles, 52(7):417–435, 2005
James R Mahalik, Elisabeth B Morray, Aimée Coonerty-Femiano, Larry H Ludlow, Suzanne M Slattery, and Andrew Smiler. Development of the conformity to feminine norms inventory.Sex Roles, 52(7):417–435, 2005
2005
-
[44]
An introduction to the five-factor model and its applications
Robert R McCrae and Oliver P John. An introduction to the five-factor model and its applications. Journal of personality, 60(2):175–215, 1992
1992
-
[45]
Linguistic regularities in continuous space word representations
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Lucy Vanderwende, Hal Daumé III, and Katrin Kirchhoff, editors, Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 746–751, Atlanta, Georgia,...
2013
-
[46]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heine- man, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Development and validation of a hexaco situational judgment test.Human Performance, 32(1):1–29, 2019
Janneke K Oostrom, Reinout E de Vries, and Mariska De Wit. Development and validation of a hexaco situational judgment test.Human Performance, 32(1):1–29, 2019
2019
-
[48]
An abbreviated tool for assessing feminine norm conformity: Psychometric properties of the conformity to feminine norms inventory–45.Psychological assessment, 23(4):958, 2011
Mike C Parent and Bonnie Moradi. An abbreviated tool for assessing feminine norm conformity: Psychometric properties of the conformity to feminine norms inventory–45.Psychological assessment, 23(4):958, 2011. 14
2011
-
[49]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InInternational Conference on Machine Learning, pages 39643–39666. PMLR, 2024
2024
-
[50]
The dark triad of personality: Narcissism, machiavellianism, and psychopathy.Journal of Research in Personality, 36(6):556–563,
Delroy L Paulhus and Kevin M Williams. The dark triad of personality: Narcissism, machiavellianism, and psychopathy.Journal of Research in Personality, 36(6):556–563,
-
[51]
doi: https://doi.org/10.1016/S0092-6566(02)00505-6
ISSN 0092-6566. doi: https://doi.org/10.1016/S0092-6566(02)00505-6. URL https://www.sciencedirect.com/science/article/pii/S0092656602005056
-
[52]
Linguistic styles: language use as an individual difference.Journal of personality and social psychology, 77(6):1296, 1999
James W Pennebaker and Laura A King. Linguistic styles: language use as an individual difference.Journal of personality and social psychology, 77(6):1296, 1999
1999
-
[53]
In: Findings of the Association for Computational Linguistics: ACL 2023, pp
Ethan Perez, Sam Ringer, Kamile Lukosiute, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Benjamin Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Johnson, Guro Khundadze, Jackson Ke...
-
[54]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504–15522, Bangkok, Thailand, Augu...
-
[55]
A psychometric framework for evaluating and shaping personality traits in large language models.Nature Machine Intelligence, pages 1–15, 2025
Gregory Serapio-García, Mustafa Safdari, Clément Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matari´c. A psychometric framework for evaluating and shaping personality traits in large language models.Nature Machine Intelligence, pages 1–15, 2025
2025
-
[56]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Personality vector: Modulating per- sonality of large language models by model merging
Seungjong Sun, Seo Yeon Baek, and Jang Hyun Kim. Personality vector: Modulating per- sonality of large language models by model merging. In Christos Christodoulopoulos, Tan- moy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Processing, pages 24656–24677, Suzhou, China, Nov...
2025
-
[58]
URL https://aclanthology.org/2025
doi: 10.18653/v1/2025.emnlp-main.1253. URL https://aclanthology.org/2025. emnlp-main.1253/
-
[59]
Tak, Amin Banayeeanzade, Anahita Bolourani, Mina Kian, Robin Jia, and Jonathan Gratch
Ala N. Tak, Amin Banayeeanzade, Anahita Bolourani, Mina Kian, Robin Jia, and Jonathan Gratch. Mechanistic interpretability of emotion inference in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 13090–13120, Vienna, Aus...
2025
-
[60]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etienne Pot, Ivo Penchev, Gaël Liu, Francesco Visin, Kathleen Kenealy, Lucas Bey...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering, 2024. URL https://arxiv.org/abs/2308.10248
work page internal anchor Pith review arXiv 2024
-
[62]
The general factor of personality: A meta-analysis of big five intercorrelations and a criterion-related validity study
Dimitri Van der Linden, Jan Te Nijenhuis, and Arnold B Bakker. The general factor of personality: A meta-analysis of big five intercorrelations and a criterion-related validity study. Journal of research in personality, 44(3):315–327, 2010. 17
2010
-
[63]
The assessment of psychological states through content analysis of verbal communications.Psychological Bulletin, 94(3):542, 1983
Linda L Viney. The assessment of psychological states through content analysis of verbal communications.Psychological Bulletin, 94(3):542, 1983
1983
-
[64]
arXiv preprint arXiv:2510.26243 (2025) 8
Hieu M. Vu and Tan M. Nguyen. Angular steering: Behavior control via rotation in activation space, 2025. URLhttps://arxiv.org/abs/2510.26243
-
[65]
Psychadapter: adapting llms to reflect traits, personality, and mental health.npj Artificial Intelligence, 2(1):26, 2026
Huy Vu, Huy Anh Nguyen, Adithya V Ganesan, Swanie Juhng, Oscar NE Kjell, Joao Sedoc, Margaret L Kern, Ryan L Boyd, Lyle Ungar, H Andrew Schwartz, et al. Psychadapter: adapting llms to reflect traits, personality, and mental health.npj Artificial Intelligence, 2(1):26, 2026
2026
-
[66]
Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. Neural network acceptability judgments.Transactions of the Association for Computational Linguistics, 7:625–641, 2019. doi: 10.1162/tacl_a_00290. URLhttps://aclanthology.org/Q19-1040/
-
[67]
Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi
Peter West, Chandra Bhagavatula, Jack Hessel, Jena D. Hwang, Liwei Jiang, Ronan Le Bras, Ximing Lu, Sean Welleck, and Yejin Choi. Symbolic knowledge distillation: from general language models to commonsense models. In Marine Carpuat, Marie-Catherine de Marneffe, and Iván Vladimir Meza Ruíz, editors,Proceedings of the 2022 Conference of the North Ameri- ca...
-
[68]
Axbench: Steering LLMs? even simple base- lines outperform sparse autoencoders
Zhengxuan Wu, Aryaman Arora, Atticus Geiger, Zheng Wang, Jing Huang, Dan Jurafsky, Christopher D Manning, and Christopher Potts. Axbench: Steering LLMs? even simple base- lines outperform sparse autoencoders. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=K2CckZjNy0
2025
-
[69]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Shu Yang, Shenzhe Zhu, Liang Liu, Lijie Hu, Mengdi Li, and Di Wang. Exploring the personality traits of llms through latent features steering, 2025. URL https://arxiv.org/ abs/2410.10863
-
[71]
FLASK: fine-grained language model eval- uation based on alignment skill sets
Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. FLASK: fine-grained language model eval- uation based on alignment skill sets. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openrev...
2024
-
[72]
Tracing moral foundations in large language models, 2026
Chenxiao Yu, Bowen Yi, Farzan Karimi-Malekabadi, Suhaib Abdurahman, Jinyi Ye, Shrikanth Narayanan, Yue Zhao, and Morteza Dehghani. Tracing moral foundations in large language models, 2026. URLhttps://arxiv.org/abs/2601.05437
work page internal anchor Pith review arXiv 2026
-
[73]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models, 2025. URL https: //arxiv.org/abs/2506.05176
work page internal anchor Pith review arXiv 2025
-
[74]
Zhaohui Zhang, Zhuoran Tu, Yulei Chen, Xiyao Xiao, Yi Feng, and Wen Zhang. Automated item generation for personality assessment: development and validation of large-language- model-derived hexaco situational judgment tests.Journal of Research in Personality, 120: 104680, 2026. ISSN 0092-6566. doi: https://doi.org/10.1016/j.jrp.2025.104680. URLhttps: //www...
-
[75]
Personality alignment of large language models
Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. Personality alignment of large language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview.net/ forum?id=0DZEs8NpUH
2025
-
[76]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to a...
work page internal anchor Pith review arXiv 2025
-
[77]
Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general
-
[78]
You should refer to the score rubric
After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric
-
[79]
(write a feedback for criteria) [RESULT] (an integer number between 1 and 5)
The output format should look as follows: "(write a feedback for criteria) [RESULT] (an integer number between 1 and 5)"
-
[80]
You {item}
Please do not generate any other opening, closing, and explanations. ###The instruction to evaluate: {instruction} ###Response to evaluate: {response} ###Score Rubrics: {rubric} ###Feedback: Lastly, the rubric, centered on coherence and fluency, was formulated by Ye et al.[66] and can be found athttps://github.com/kaistAI/FLASK: Is the response structured...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.