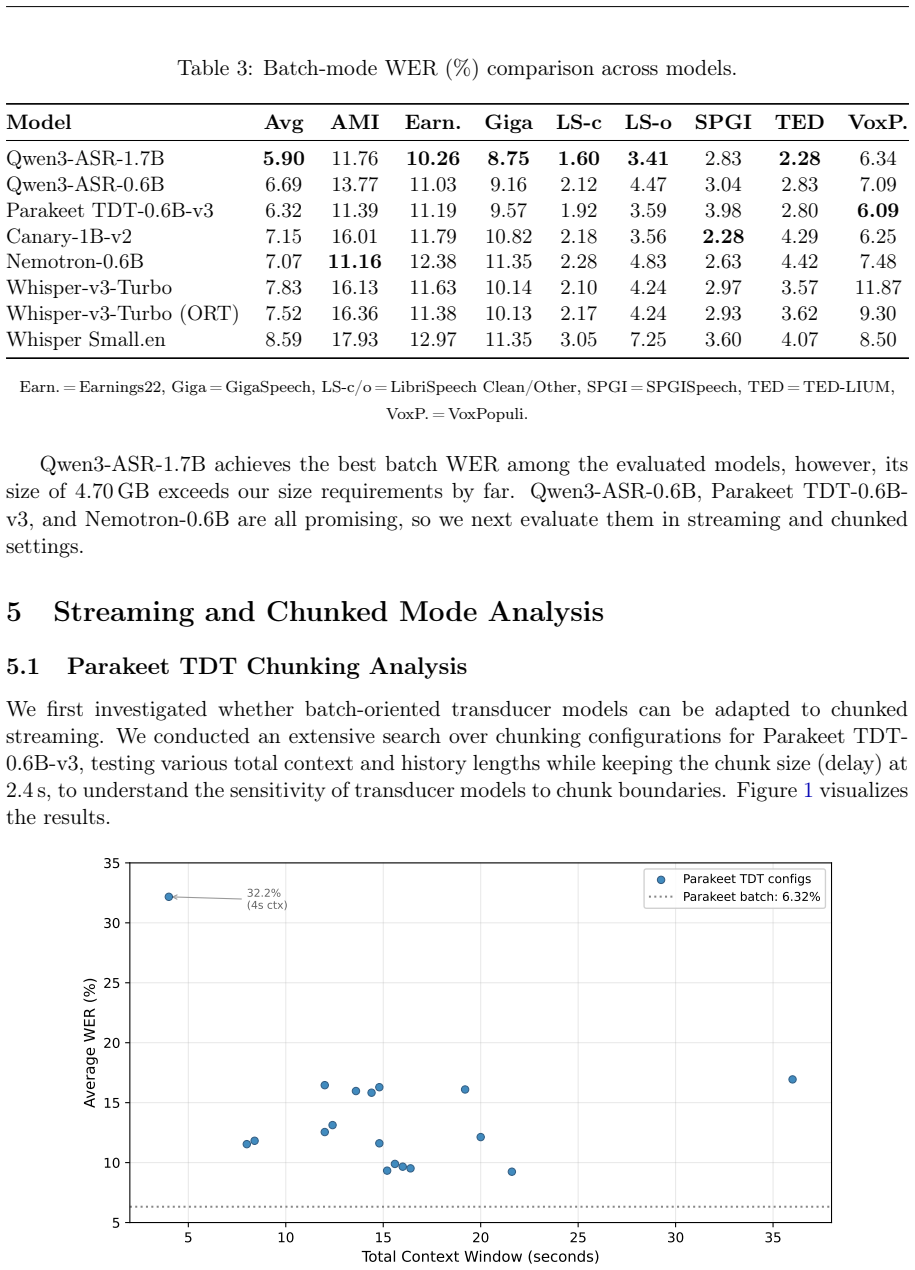
Recognition: unknown
Pushing the Limits of On-Device Streaming ASR: A Compact, High-Accuracy English Model for Low-Latency Inference
Pith reviewed 2026-05-10 12:00 UTC · model grok-4.3
The pith
Re-implementing and int4-quantizing Nemotron yields a 0.67 GB streaming ASR model with 8.2 percent WER and 0.56 second CPU latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
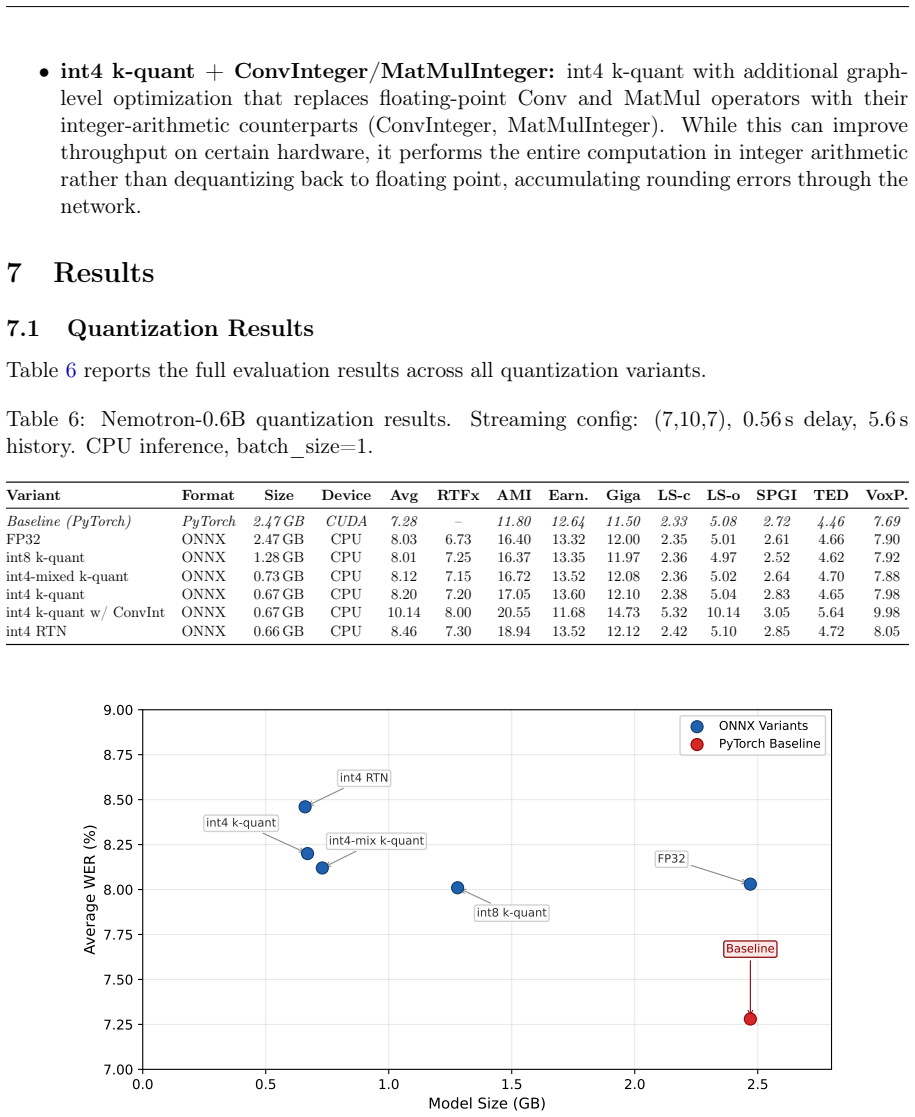
After systematic comparison the authors establish that NVIDIA Nemotron Speech Streaming, once reimplemented in ONNX Runtime and optimized with int4 k-quantization plus operator fusion, reduces model size to 0.67 GB and achieves an average streaming word error rate of 8.20 percent across eight standard benchmarks while maintaining 0.56 seconds algorithmic latency and running comfortably faster than real time on CPU.
What carries the argument
The int4 k-quant variant of the ONNX Runtime streaming inference pipeline, which applies importance-weighted quantization and graph-level operator fusion to the Nemotron transducer.
If this is right
- High-accuracy streaming ASR becomes feasible on standard CPUs without GPU support.
- Model memory footprint can be cut by more than 70 percent with less than 1 percent absolute WER increase.
- The eight-benchmark average of 8.20 percent WER sets a concrete quality target for future on-device systems.
- Quantization combined with operator fusion preserves transducer accuracy better than round-to-nearest alone.
Where Pith is reading between the lines
- Similar re-implementation and quantization steps could be tested on other transducer or LLM-based ASR models to locate additional Pareto improvements.
- The low algorithmic latency opens the possibility of tighter integration with on-device language models for end-to-end voice agents.
- If the same pipeline scales to non-English languages, the approach would directly address multilingual on-device ASR gaps.
Load-bearing premise
The ONNX Runtime re-implementation exactly reproduces the original PyTorch model's streaming behavior under all tested conditions.
What would settle it
A side-by-side run of the original PyTorch model and the ONNX version on identical streaming audio would show a word error rate difference larger than one percent absolute.
Figures



read the original abstract
Deploying high-quality automatic speech recognition (ASR) on edge devices requires models that jointly optimize accuracy, latency, and memory footprint while operating entirely on CPU without GPU acceleration. We conduct a systematic empirical study of state-of-the-art ASR architectures, encompassing encoder-decoder, transducer, and LLM-based paradigms, evaluated across batch, chunked, and streaming inference modes. Through a comprehensive benchmark of over 50 configurations spanning OpenAI Whisper, NVIDIA Nemotron, Parakeet TDT, Canary, Conformer Transducer, and Qwen3-ASR, we identify NVIDIA's Nemotron Speech Streaming as the strongest candidate for real-time English streaming on resource-constrained hardware. We then re-implement the complete streaming inference pipeline in ONNX Runtime and conduct a controlled evaluation of multiple post-training quantization strategies, including importance-weighted k-quant, mixed-precision schemes, and round-to-nearest quantization, combined with graph-level operator fusion. These optimizations reduce the model from 2.47 GB to as little as 0.67 GB while maintaining word error rate (WER) within 1% absolute of the full-precision PyTorch baseline. Our recommended configuration, the int4 k-quant variant, achieves 8.20% average streaming WER across eight standard benchmarks, running comfortably faster than real-time on CPU with 0.56 s algorithmic latency, establishing a new quality-efficiency Pareto point for on-device streaming ASR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper benchmarks over 50 configurations of ASR models (Whisper, Nemotron, Parakeet TDT, Canary, Conformer Transducer, Qwen3-ASR) in batch, chunked, and streaming modes on CPU. It selects NVIDIA Nemotron Speech Streaming as the strongest candidate, re-implements its full streaming inference pipeline in ONNX Runtime, applies post-training quantization (importance-weighted k-quant, mixed-precision, round-to-nearest) plus operator fusion, and reports that the int4 k-quant variant reduces size from 2.47 GB to 0.67 GB while achieving 8.20% average streaming WER across eight standard benchmarks, 0.56 s algorithmic latency, and performance within 1% absolute WER of the full-precision PyTorch baseline, establishing a new quality-efficiency Pareto frontier for on-device streaming ASR.
Significance. If the ONNX re-implementation faithfully reproduces PyTorch behavior, the work supplies a concrete, reproducible reference point for efficient on-device English streaming ASR with measured trade-offs in WER, size, and latency. The systematic architecture comparison and controlled quantization study would be useful for practitioners deploying ASR on edge hardware.
major comments (1)
- [ONNX re-implementation and quantization evaluation sections] The equivalence between the original PyTorch Nemotron streaming model and the authors' ONNX Runtime re-implementation is not demonstrated with side-by-side WER or token-level metrics on the eight benchmarks prior to quantization. Streaming transducers are sensitive to state carry-over, chunk overlap, and operator ordering; without this verification, the reported 1% WER delta cannot be confidently attributed to the int4 k-quant and fusion steps rather than implementation differences. This verification is load-bearing for the central claim in the abstract and results.
minor comments (3)
- [Results] The abstract and results do not report error bars, standard deviations, or statistical significance tests on the WER numbers across the eight benchmarks or across multiple runs.
- [Methods] Exact quantization parameters (e.g., calibration dataset size, importance weighting details, bit allocation in mixed-precision) and the precise definition of 'algorithmic latency' are not fully specified, limiting reproducibility.
- [Experimental setup] The selection criteria and characteristics of the eight 'standard benchmarks' are not detailed; it is unclear how representative they are of real-world streaming conditions with varying utterance lengths and noise.
Simulated Author's Rebuttal
Thank you for the referee's insightful comments on our manuscript. We have carefully considered the major concern regarding the verification of our ONNX re-implementation and provide our response below. We will make the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [ONNX re-implementation and quantization evaluation sections] The equivalence between the original PyTorch Nemotron streaming model and the authors' ONNX Runtime re-implementation is not demonstrated with side-by-side WER or token-level metrics on the eight benchmarks prior to quantization. Streaming transducers are sensitive to state carry-over, chunk overlap, and operator ordering; without this verification, the reported 1% WER delta cannot be confidently attributed to the int4 k-quant and fusion steps rather than implementation differences. This verification is load-bearing for the central claim in the abstract and results.
Authors: We acknowledge that the equivalence between the PyTorch and ONNX implementations was not explicitly demonstrated with side-by-side metrics in the submitted manuscript. Our ONNX re-implementation was intended to faithfully reproduce the PyTorch streaming behavior, but to address this valid point, we will add a comparison table in the revised manuscript showing the WER results for the full-precision models on all eight benchmarks. This will allow readers to verify that any observed differences post-quantization are due to the quantization process rather than implementation discrepancies. We believe this addition will resolve the concern and support the central claims. revision: yes
Circularity Check
No circularity; purely empirical benchmarking and optimization results
full rationale
The paper conducts an empirical study: it benchmarks over 50 configurations of existing ASR models (Whisper, Nemotron, etc.) across inference modes, selects Nemotron as strongest, re-implements its streaming pipeline in ONNX Runtime, applies post-training quantization variants, and reports measured WER, latency, and size on eight benchmarks. No equations, derivations, fitted parameters, or predictions are defined in terms of themselves. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. All headline claims (8.20% WER, 0.56 s latency, size reduction to 0.67 GB) are direct experimental outcomes, not reductions to inputs by construction. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- quantization scheme and bit-width
axioms (1)
- domain assumption The ONNX Runtime streaming pipeline faithfully reproduces the original PyTorch model's inference outputs and latency characteristics.
Reference graph
Works this paper leans on
-
[1]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inProc. ICML,https://arxiv.org/ abs/2212.04356, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
NVIDIA NeMo: a toolkit for building new AI models,
NVIDIA NeMo, “NVIDIA NeMo: a toolkit for building new AI models,”https://github. com/NVIDIA/NeMo, 2024
2024
-
[3]
Qwen Team, “Qwen3-ASR Technical Report,”https://arxiv.org/abs/2601.21337, 2026
work page internal anchor Pith review arXiv 2026
-
[4]
Olive: a hardware-aware model optimization tool for ONNX models,
Microsoft, “Olive: a hardware-aware model optimization tool for ONNX models,”https: //github.com/microsoft/Olive, 2024
2024
-
[5]
Faster-Whisper: faster inference for OpenAI’s Whisper using CTranslate2,
SYSTRAN, “Faster-Whisper: faster inference for OpenAI’s Whisper using CTranslate2,” https://github.com/SYSTRAN/faster-whisper, 2024
2024
-
[6]
Parakeet TDT-0.6B-v3,
NVIDIA, “Parakeet TDT-0.6B-v3,”https://huggingface.co/nvidia/parakeet-tdt-0. 6b-v3, 2025
2025
-
[7]
Conformer Transducer XL,
NVIDIA, “Conformer Transducer XL,”https://huggingface.co/nvidia/stt_en_ conformer_transducer_xlarge, 2022
2022
-
[8]
Nemotron Speech Streaming,
NVIDIA, “Nemotron Speech Streaming,”https://huggingface.co/nvidia/ nemotron-speech-streaming-en-0.6b, 2025
2025
-
[9]
Open ASR Leaderboard
Hugging Face, “Open ASR Leaderboard”,https://huggingface.co/spaces/hf-audio/ open_asr_leaderboard, 2024
2024
-
[10]
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator,
ONNX Runtime Contributors, “ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator,”https://onnxruntime.ai/, 2024
2024
-
[11]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
J. Lin, J. Tang, H. Tang, S. Yang, X. Dang, and S. Han, “AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration,”https://arxiv.org/abs/ 2306.00978, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers,”https://arxiv.org/abs/2210. 17323, 2022
2022
-
[13]
2-bit Conformer Quantization for Automatic Speech Recognition,
J. Yu, Y. Park, and S. Watanabe, “2-bit Conformer Quantization for Automatic Speech Recognition,”https://arxiv.org/abs/2305.16619, 2023
-
[14]
Voxtral.arXiv preprint arXiv:2507.13264,
Mistral AI Team, “Voxtral,”https://arxiv.org/abs/2507.13264, 2025
-
[15]
Moonshine v2: Ergodic Streaming Encoder ASR for Latency-Critical Speech Applications,
M. Kudlur, E. King, J. Wang, and P. Warden, “Moonshine v2: Ergodic Streaming Encoder ASR for Latency-Critical Speech Applications,”https://arxiv.org/abs/2602. 12241, 2026. 15 A Complete Evaluation Results This appendix reports all configurations evaluated during this study, including incomplete runs and configurations not featured in the main text. All WE...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.