Recognition: unknown
DVFace: Spatio-Temporal Dual-Prior Diffusion for Video Face Restoration
Pith reviewed 2026-05-10 11:33 UTC · model grok-4.3
The pith
A one-step diffusion model extracts separate spatial and temporal face priors to restore video with higher quality and stability than generic multi-step methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
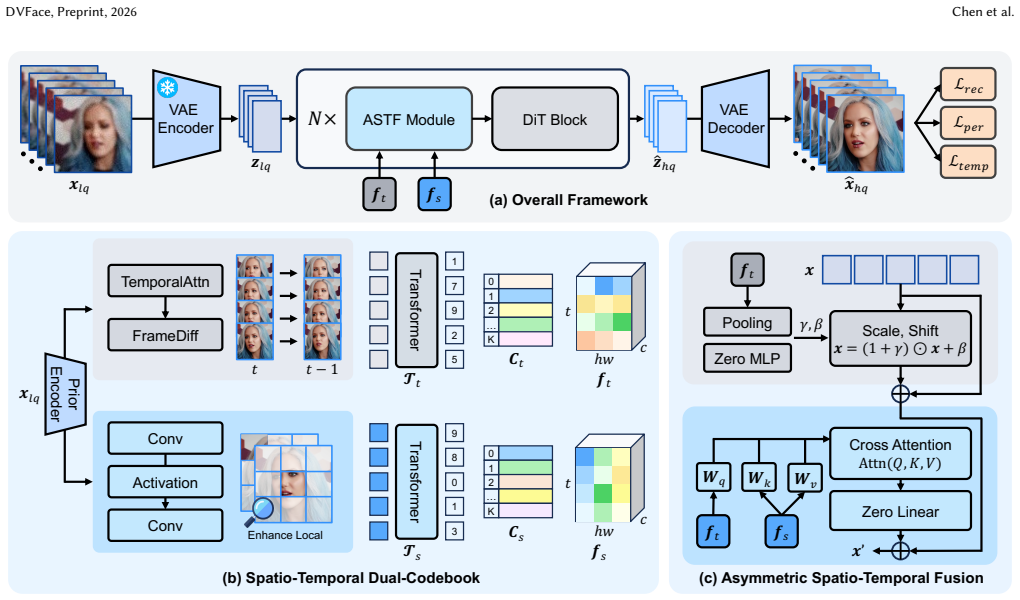
DVFace is a one-step diffusion framework that introduces a spatio-temporal dual-codebook design to extract complementary spatial and temporal facial priors from degraded videos and an asymmetric spatio-temporal fusion module to inject these priors into the diffusion backbone according to their distinct roles, delivering superior restoration quality, temporal consistency, and identity preservation on benchmarks compared with recent methods.
What carries the argument
Spatio-temporal dual-codebook design that extracts complementary spatial and temporal facial priors from the degraded input, paired with an asymmetric fusion module that injects each prior according to its role in the diffusion process.
If this is right
- Video face restoration becomes feasible in a single diffusion step instead of many, lowering inference time.
- Dedicated spatial and temporal priors produce more realistic facial details while avoiding common artifacts.
- Temporal consistency across frames improves because a separate temporal prior is injected at the right stage.
- Face identity is preserved more reliably than when using only generic diffusion priors.
- Overall performance exceeds that of recent methods on standard video face restoration benchmarks.
Where Pith is reading between the lines
- The same dual-prior extraction pattern could be adapted to restore other video content such as full-body motion or scene backgrounds.
- One-step sampling opens the door to real-time enhancement pipelines on consumer hardware where multi-step diffusion is currently too slow.
- Role-specific asymmetric fusion may prove useful in other diffusion tasks that combine multiple distinct information sources.
- Testing the codebooks on extreme degradations like severe motion blur or compression artifacts would reveal the limits of the current prior design.
Load-bearing premise
That the dual-codebook extraction and asymmetric fusion can reliably supply complementary priors that support faithful one-step recovery without artifacts or temporal instability.
What would settle it
On the paper's evaluation benchmarks, a result showing lower perceptual quality scores, visible temporal flickering between frames, or measurable identity drift compared with recent multi-step methods would falsify the central performance claim.
Figures



read the original abstract
Video face restoration aims to enhance degraded face videos into high-quality results with realistic facial details, stable identity, and temporal coherence. Recent diffusion-based methods have brought strong generative priors to restoration and enabled more realistic detail synthesis. However, existing approaches for face videos still rely heavily on generic diffusion priors and multi-step sampling, which limit both facial adaptation and inference efficiency. These limitations motivate the use of one-step diffusion for video face restoration, yet achieving faithful facial recovery alongside temporally stable outputs remains challenging. In this paper, we propose, DVFace, a one-step diffusion framework for real-world video face restoration. Specifically, we introduce a spatio-temporal dual-codebook design to extract complementary spatial and temporal facial priors from degraded videos. We further propose an asymmetric spatio-temporal fusion module to inject these priors into the diffusion backbone according to their distinct roles. Evaluation on various benchmarks shows that DVFace delivers superior restoration quality, temporal consistency, and identity preservation compared to recent methods. Code: https://github.com/zhengchen1999/DVFace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DVFace, a one-step diffusion framework for real-world video face restoration. It introduces a spatio-temporal dual-codebook to extract complementary spatial and temporal facial priors from degraded videos and an asymmetric spatio-temporal fusion module to inject these priors into the diffusion backbone according to their distinct roles. The authors report quantitative improvements on standard benchmarks (PSNR, SSIM, LPIPS, warping error for temporal consistency, and ArcFace for identity) along with qualitative results showing reduced artifacts compared to recent baselines.
Significance. If the reported gains hold under scrutiny, the work offers a meaningful advance in efficient video face restoration by adapting diffusion priors specifically for facial and temporal structure rather than relying on generic multi-step sampling. The dual-codebook and asymmetric fusion address documented limitations in prior diffusion-based methods, and the provision of code, diagrams, and pseudocode strengthens reproducibility. This could influence subsequent research on one-step generative models for video tasks.
major comments (2)
- [§3.3] §3.3 (asymmetric fusion module): The mechanism for differentially injecting spatial versus temporal priors is described at a high level but lacks an explicit equation or pseudocode for the fusion weights and attention routing; this is load-bearing for the central claim that the module enables faithful recovery without artifacts or temporal instability.
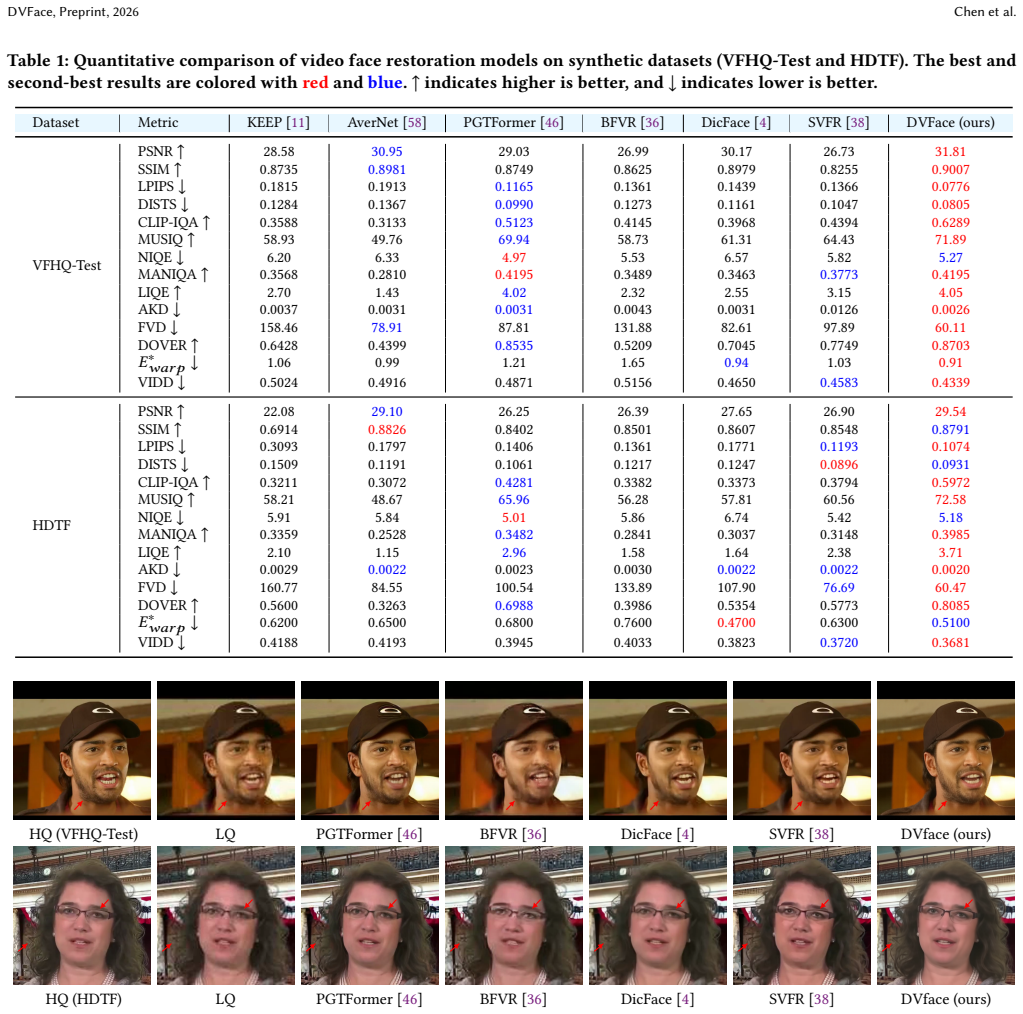
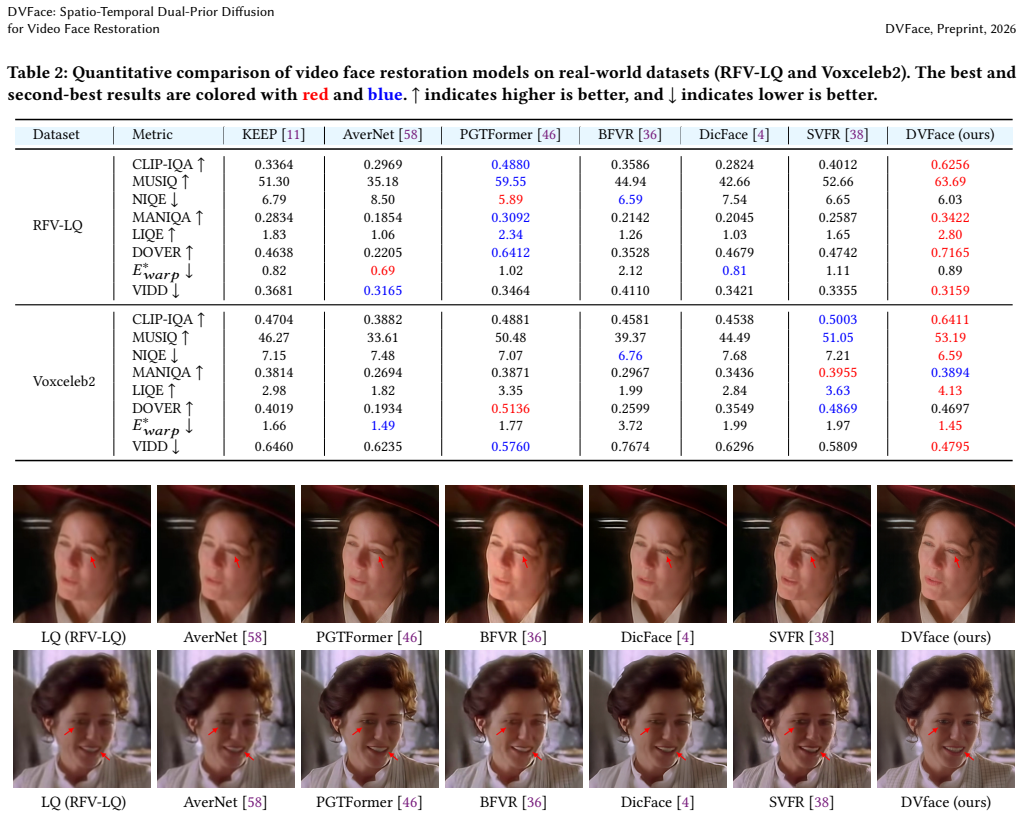
- [Table 1] Table 1 and §4.3 (quantitative results): Gains are reported across metrics, yet no standard deviations, number of independent runs, or statistical significance tests are provided; without these, the superiority claim over baselines cannot be fully assessed for robustness.
minor comments (2)
- [Figure 4] Figure 4: The qualitative comparison panels would be clearer with explicit callouts or zoomed insets highlighting the claimed reductions in artifacts and improved identity preservation.
- [§2] §2 (related work): A few recent one-step diffusion restoration papers for images are omitted; adding them would better situate the video-specific contributions.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The comments are constructive, and we address each major point below with specific plans for the revised manuscript.
read point-by-point responses
-
Referee: [§3.3] §3.3 (asymmetric fusion module): The mechanism for differentially injecting spatial versus temporal priors is described at a high level but lacks an explicit equation or pseudocode for the fusion weights and attention routing; this is load-bearing for the central claim that the module enables faithful recovery without artifacts or temporal instability.
Authors: We agree that the current description of the asymmetric spatio-temporal fusion module would benefit from greater mathematical precision. In the revised manuscript, we will add an explicit equation in §3.3 defining the fusion weights and attention routing (e.g., the differential scaling and routing between spatial and temporal codebook features). We will also include pseudocode in the supplementary material that details the injection process into the diffusion backbone. These additions will directly support the claim regarding artifact reduction and temporal stability. revision: yes
-
Referee: [Table 1] Table 1 and §4.3 (quantitative results): Gains are reported across metrics, yet no standard deviations, number of independent runs, or statistical significance tests are provided; without these, the superiority claim over baselines cannot be fully assessed for robustness.
Authors: We acknowledge that reporting standard deviations and statistical tests would allow a more rigorous assessment of robustness. Due to the substantial computational cost of training and inference for diffusion-based video models, we followed the standard single-run protocol used by prior work in this area. In the revision, we will add an explicit statement in §4.3 clarifying the evaluation protocol and noting that the reported gains are consistent across all benchmarks and qualitative comparisons. While we cannot retroactively add multiple independent runs without new experiments, the multi-metric and multi-dataset improvements provide supporting evidence for the claims. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new one-step diffusion framework with a spatio-temporal dual-codebook design and asymmetric fusion module to address limitations of generic diffusion priors for video face restoration. These are presented as novel architectural contributions motivated by the challenges of facial adaptation and temporal stability, without any equations, predictions, or central claims reducing by construction to fitted inputs, self-citations, or prior ansatzes from the authors. Evaluation relies on standard external benchmarks and metrics (PSNR, SSIM, LPIPS, warping error, ArcFace) against recent baselines, with no load-bearing steps that equate outputs to inputs via definition or self-reference. The derivation remains self-contained against external validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023. Align your latents: High-resolution video synthesis with latent diffusion models. InCVPR
2023
-
[2]
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. 2022. Basicvsr++: Improving video super-resolution with enhanced propagation and alignment. InCVPR
2022
-
[3]
Kelvin CK Chan, Shangchen Zhou, Xiangyu Xu, and Chen Change Loy. 2022. Investigating tradeoffs in real-world video super-resolution. InCVPR
2022
- [4]
-
[5]
Zeyuan Chen, Yinbo Chen, Jingwen Liu, Xingqian Xu, Vidit Goel, Zhangyang Wang, Humphrey Shi, and Xiaolong Wang. 2022. Videoinr: Learning video implicit neural representation for continuous space-time super-resolution. In CVPR
2022
-
[6]
Ziyan Chen, Jingwen He, Xinqi Lin, Yu Qiao, and Chao Dong. 2024. Towards real-world video face restoration: A new benchmark. InCVPR
2024
-
[7]
Zheng Chen, Zichen Zou, Kewei Zhang, Xiongfei Su, Xin Yuan, Yong Guo, and Yulun Zhang. 2025. DOVE: Efficient One-Step Diffusion Model for Real-World Video Super-Resolution. InNeurIPS
2025
- [8]
-
[9]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P Simoncelli. 2020. Image quality assessment: Unifying structure and texture similarity.TPAMI(2020)
2020
-
[10]
Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. 2025. TSD-SR: One-Step Diffusion with Target Score Distillation for Real-World Image Super-Resolution. InCVPR
2025
-
[11]
Ruicheng Feng, Chongyi Li, and Chen Change Loy. 2024. Kalman-inspired feature propagation for video face super-resolution. InECCV
2024
-
[12]
Yuchao Gu, Xintao Wang, Liangbin Xie, Chao Dong, Gen Li, Ying Shan, and Ming-Ming Cheng. 2022. Vqfr: Blind face restoration with vector-quantized dictionary and parallel decoder. InECCV
2022
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. InNeurIPS
2020
-
[14]
Xiaobin Hu, Wenqi Ren, John LaMaster, Xiaochun Cao, Xiaoming Li, Zechao Li, Bjoern Menze, and Wei Liu. 2020. Face super-resolution guided by 3d facial priors. InECCV
2020
-
[15]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. Musiq: Multi-scale image quality transformer. InICCV
2021
-
[16]
Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. 2018. Learning blind video temporal consistency. InECCV
2018
- [17]
- [18]
- [19]
-
[20]
Senmao Li, Kai Wang, Joost van de Weijer, Fahad Shahbaz Khan, Chun-Le Guo, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng. 2025. InterLCM: Low- quality images as intermediate states of latent consistency models for effective blind face restoration.arXiv preprint arXiv:2502.02215(2025)
-
[21]
Wenjie Li, Mei Wang, Kai Zhang, Juncheng Li, Xiaoming Li, Yuhang Zhang, Guangwei Gao, and Zhanyu Ma. 2025. Survey on deep face restoration: From non-blind to blind and beyond.Comput. Surveys(2025)
2025
-
[22]
Xiaohui Li, Yihao Liu, Shuo Cao, Ziyan Chen, Shaobin Zhuang, Xiangyu Chen, Yinan He, Yi Wang, and Yu Qiao. 2025. DiffVSR: Enhancing Real-World Video Super-Resolution with Diffusion Models for Advanced Visual Quality and Tem- poral Consistency.arXiv preprint arXiv:2501.10110(2025)
-
[23]
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. 2024. Diffbir: Toward blind image restoration with generative diffusion prior. InECCV
2024
-
[24]
Jinshan Pan, Haoran Bai, Jiangxin Dong, Jiawei Zhang, and Jinhui Tang. 2021. Deep blind video super-resolution. InCVPR
2021
-
[25]
Wenqi Ren, Jiaolong Yang, Senyou Deng, David Wipf, Xiaochun Cao, and Xin Tong. 2019. Face video deblurring using 3D facial priors. InICCV
2019
-
[26]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In CVPR
2022
-
[27]
Claudio Rota, Marco Buzzelli, Simone Bianco, and Raimondo Schettini. 2023. Video restoration based on deep learning: a comprehensive survey.AIR(2023)
2023
-
[28]
Yujing Sun, Lingchen Sun, Shuaizheng Liu, Rongyuan Wu, Zhengqiang Zhang, and Lei Zhang. 2025. One-step diffusion for detail-rich and temporally consistent video super-resolution. InNeurIPS Workshop
2025
-
[29]
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. 2019. FVD: A new metric for video genera- tion. InICLR Workshop
2019
-
[30]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. 2023. Exploring clip for assessing the look and feel of images. InAAAI
2023
-
[32]
Jingkai Wang, Jue Gong, Lin Zhang, Zheng Chen, Xing Liu, Hong Gu, Yutong Liu, Yulun Zhang, and Xiaokang Yang. 2025. OSDFace: One-Step Diffusion Model for Face Restoration. InCVPR
2025
-
[33]
Jianyi Wang, Zhijie Lin, Meng Wei, Yang Zhao, Ceyuan Yang, Fei Xiao, Chen Change Loy, and Lu Jiang. 2025. Seedvr: Seeding infinity in diffusion transformer towards generic video restoration. InCVPR
2025
-
[34]
Xintao Wang, Kelvin CK Chan, Ke Yu, Chao Dong, and Chen Change Loy. 2019. Edvr: Video restoration with enhanced deformable convolutional networks. In CVPRW
2019
-
[35]
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. 2021. Towards real-world blind face restoration with generative facial prior. InCVPR
2021
-
[36]
Yutong Wang, Jiajie Teng, Jiajiong Cao, Yuming Li, Chenguang Ma, Hongteng Xu, and Dixin Luo. 2025. Efficient video face enhancement with enhanced spatial- temporal consistency. InCVPR
2025
-
[37]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.TIP(2004)
2004
-
[38]
Zhiyao Wang, Xu Chen, Chengming Xu, Junwei Zhu, Xiaobin Hu, Jiangning Zhang, Chengjie Wang, Yuqi Liu, Yiyi Zhou, and Rongrong Ji. 2025. Svfr: A unified framework for generalized video face restoration. InCVPR
2025
-
[39]
Zhouxia Wang, Jiawei Zhang, Tianshui Chen, Wenping Wang, and Ping Luo. 2023. Restoreformer++: Towards real-world blind face restoration from undegraded key-value pairs.TPAMI(2023)
2023
-
[40]
Zhouxia Wang, Jiawei Zhang, Xintao Wang, Tianshui Chen, Ying Shan, Wenping Wang, and Ping Luo. 2024. Analysis and benchmarking of extending blind face image restoration to videos.TIP(2024)
2024
-
[41]
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou, Annan Wang, Wenxiu Sun, Qiong Yan, and Weisi Lin. 2023. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InICCV
2023
-
[42]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. 2024. One-step effective diffusion network for real-world image super-resolution. InNeurIPS
2024
-
[43]
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. 2024. SeeSR: Towards Semantics-Aware Real-World Image Super- Resolution. InCVPR
2024
-
[44]
Liangbin Xie, Xintao Wang, Honglun Zhang, Chao Dong, and Ying Shan. 2022. Vfhq: A high-quality dataset and benchmark for video face super-resolution. In CVPR
2022
- [45]
- [46]
-
[47]
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. 2022. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPRW
2022
-
[48]
Tao Yang, Peiran Ren, Xuansong Xie, and Lei Zhang. 2021. Gan prior embedded network for blind face restoration in the wild. InCVPR
2021
- [49]
-
[50]
Zongsheng Yue and Chen Change Loy. 2024. Difface: Blind face restoration with diffused error contraction.TPAMI(2024)
2024
-
[51]
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. 2023. Adding Conditional Control to Text-to-Image Diffusion Models. InICCV
2023
-
[52]
Lin Zhang, Lei Zhang, and Alan C Bovik. 2015. A feature-enriched completely blind image quality evaluator.TIP(2015)
2015
-
[53]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric. In CVPR
- [55]
-
[56]
Weixia Zhang, Guangtao Zhai, Ying Wei, Xiaokang Yang, and Kede Ma. 2023. Blind image quality assessment via vision-language correspondence: A multitask learning perspective. InCVPR. DVFace, Preprint, 2026 Chen et al
2023
-
[57]
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. 2021. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. In CVPR
2021
- [58]
-
[59]
Haiyu Zhao, Lei Tian, Xinyan Xiao, Peng Hu, Yuanbiao Gou, and Xi Peng. 2024. AverNet: All-in-one video restoration for time-varying unknown degradations. InNeurIPS
2024
-
[60]
Shangchen Zhou, Kelvin Chan, Chongyi Li, and Chen Change Loy. 2022. Towards robust blind face restoration with codebook lookup transformer. InNeurIPS
2022
-
[61]
Shangchen Zhou, Peiqing Yang, Jianyi Wang, Yihang Luo, and Chen Change Loy
-
[62]
Upscale-a-video: Temporal-consistent diffusion model for real-world video super-resolution. InCVPR
-
[63]
Feida Zhu, Junwei Zhu, Wenqing Chu, Xinyi Zhang, Xiaozhong Ji, Chengjie Wang, and Ying Tai. 2022. Blind face restoration via integrating face shape and generative priors. InCVPR
2022
- [64]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.