Recognition: unknown
CoCoDiff: Optimizing Collective Communications for Distributed Diffusion Transformer Inference Under Ulysses Sequence Parallelism
Pith reviewed 2026-05-10 10:19 UTC · model grok-4.3
The pith
CoCoDiff reduces latency for distributed Diffusion Transformer inference by overlapping V communication with Q/K computation and using selective transmission based on tensor similarity across steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
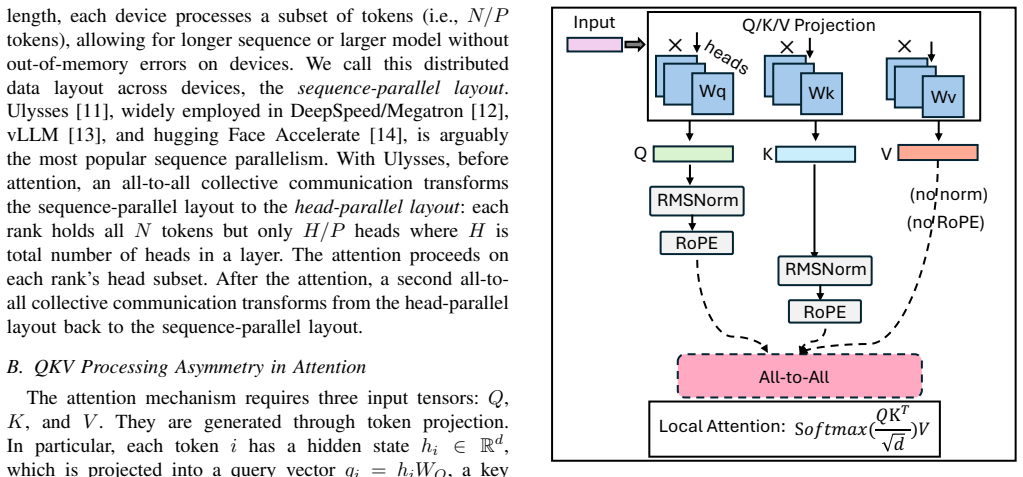
CoCoDiff is a distributed DiT inference engine that exploits the asymmetry where V needs only linear projection while Q/K require normalization and RoPE, plus temporal redundancy in adjacent denoising steps. It uses Tile-Aware Parallel All-to-all decomposition, V-First scheduling to hide V communication behind Q/K work, and V-Major selective communication to limit data on slow interconnects, delivering average 3.6x speedup and peak 8.4x across 1-8 nodes with up to 96 GPU tiles.
What carries the argument
V-First scheduling paired with V-Major selective communication, which overlaps V's all-to-all behind Q/K computation and transmits only active projections by leveraging similarity between consecutive denoising steps.
Load-bearing premise
Adjacent denoising steps produce sufficiently similar tensors to allow selective V communication without degrading output quality, and the data dependencies permit reliable overlap of V communication behind Q/K computation.
What would settle it
Measuring image quality degradation or failure of communication overlap when CoCoDiff is applied to a DiT model where consecutive denoising steps produce dissimilar V tensors on hardware with asymmetric interconnect bandwidth.
Figures









read the original abstract
Diffusion Transformers (DiTs) are increasingly adopted in scientific computing, yet growing model sizes and resolutions make distributed multi-GPU inference essential. Ulysses sequence parallelism scales DiT inference but introduces frequent all-to-all collectives that dominate latency. Overlapping these with computation is difficult due to tight data dependencies, large message volumes, and asymmetric interconnect bandwidths. We introduce CoCoDiff, a distributed DiT inference engine exploiting two observations: (1) V requires only linear projection while Q/K need additional normalization and RoPE, creating opportunities to overlap V's communication with Q/K computation; (2) adjacent denoising steps produce similar tensors, yielding temporal redundancy. CoCoDiff introduces three mechanisms: Tile-Aware Parallel All-to-all (TAPA) decomposes collectives into topology-aligned phases; V-First scheduling hides V's communication behind Q/K computation; and V-Major selective communication transmits only active projections on slow interconnects. On the Aurora supercomputer with four DiT models across 1-8 nodes (up to 96 Intel GPU tiles), CoCoDiff achieves an average speedup of 3.6x, peaking at 8.4x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoCoDiff, a distributed inference engine for Diffusion Transformers (DiTs) under Ulysses sequence parallelism. It exploits two observations—V projections require only linear projection while Q/K need normalization and RoPE, and adjacent denoising steps yield similar tensors—to propose three mechanisms: Tile-Aware Parallel All-to-all (TAPA) for topology-aligned collectives, V-First scheduling to overlap V all-to-all behind Q/K computation, and V-Major selective communication that transmits only active V projections over slow links. On the Aurora supercomputer with four DiT models across 1-8 nodes (up to 96 Intel GPU tiles), it reports an average 3.6x speedup peaking at 8.4x.
Significance. If the performance claims are substantiated with quality-preserving ablations and schedulability analysis, CoCoDiff would address a key latency bottleneck in scaling DiT inference for scientific computing on systems with asymmetric interconnects. The combination of computation-communication asymmetry exploitation and temporal redundancy is a practical contribution that could extend to other transformer workloads; the concrete supercomputer measurements are a positive aspect.
major comments (2)
- [Abstract] Abstract: The headline speedups (3.6x average, 8.4x peak) rest on V-Major selective communication and V-First overlap, yet the abstract supplies neither the selection threshold for 'active' V projections, quality-ablation results (e.g., FID or perceptual metrics showing statistical indistinguishability from full communication), nor dependency analysis confirming that normalization/RoPE asymmetry permits reliable overlap without stalls.
- [Abstract] Abstract: No baselines, error bars, ablation studies, or experimental configuration details (model sizes, exact tile/node mappings, interconnect bandwidths) are provided to allow verification of the reported speedups or to isolate the contribution of each mechanism (TAPA, V-First, V-Major).
minor comments (1)
- The abstract refers to 'four DiT models' without naming the specific architectures or parameter counts, which would help readers assess generalizability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment on the abstract below and will revise the abstract to supply additional context while preserving its brevity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline speedups (3.6x average, 8.4x peak) rest on V-Major selective communication and V-First overlap, yet the abstract supplies neither the selection threshold for 'active' V projections, quality-ablation results (e.g., FID or perceptual metrics showing statistical indistinguishability from full communication), nor dependency analysis confirming that normalization/RoPE asymmetry permits reliable overlap without stalls.
Authors: We agree the abstract would benefit from more specifics. The selection threshold for active V projections and the dependency analysis confirming reliable overlap (due to V requiring only linear projection while Q/K require normalization and RoPE) are detailed in Sections 3 and 4 of the manuscript. We will revise the abstract to briefly summarize these elements and the basis for stall-free overlap. The manuscript does not include quality-ablation results such as FID or perceptual metrics. revision: partial
-
Referee: [Abstract] Abstract: No baselines, error bars, ablation studies, or experimental configuration details (model sizes, exact tile/node mappings, interconnect bandwidths) are provided to allow verification of the reported speedups or to isolate the contribution of each mechanism (TAPA, V-First, V-Major).
Authors: We acknowledge that the abstract omits these details. The paper uses the standard Ulysses sequence parallelism as baseline, with ablations isolating TAPA, V-First, and V-Major presented in the evaluation section. Experimental configuration (four DiT models, 1-8 nodes up to 96 GPU tiles on Aurora) is described in Section 5, including interconnect details. We will revise the abstract to reference the baseline, experimental scale, and ablations. Error bars from repeated runs are not reported in the current manuscript. revision: yes
- The manuscript does not include quality-ablation results (e.g., FID or perceptual metrics) or error bars; while the mechanisms are designed around temporal redundancy and computation asymmetry to preserve quality and enable overlap, these specific quantifications are absent.
Circularity Check
No circularity: purely empirical system measurements with no derivations or self-referential reductions
full rationale
The paper contains no equations, mathematical derivations, or predictive models. Its core contributions are three engineering mechanisms (TAPA, V-First scheduling, V-Major selective communication) motivated by two stated observations about tensor properties and data dependencies. Performance claims consist exclusively of direct wall-clock measurements on Aurora hardware across multiple DiT models and node counts. These results do not reduce to fitted parameters, self-citations, or inputs by construction; they are independent experimental outcomes. The absence of any load-bearing derivation chain makes circularity analysis inapplicable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ulysses sequence parallelism for DiT inference introduces frequent all-to-all collectives that dominate latency
Reference graph
Works this paper leans on
-
[1]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M ¨uller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” inForty-first International Conference on Machine Learning, ICML 2024, ser. Proceedings of Machine Learning Research. ...
2024
-
[2]
Black Forest Labs, “FLUX,” https://github.com/black-forest-labs/flux, 2024
2024
-
[3]
A. Yang, B. Li, B. Yanget al., “Qwen2.5-VL technical report,” arXiv preprint arXiv:2502.13923, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2502.13923
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[4]
Video generation models as world simulators,
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh, “Video generation models as world simulators,” OpenAI Technical Report, 2024. [Online]. Available: https://openai.com/index/ video-generation-models-as-world-simulators/
2024
-
[5]
AERIS: Argonne earth systems model for reliable and skillful predictions,
V . Hatanp ¨a¨a, E. Ku, J. Stock, M. Emani, S. Foreman, C. Jung, S. Madireddy, T. Nguyen, V . Sastry, R. A. O. Sinurat, H. Zheng, S. Wheeler, T. Arcomano, V . Vishwanath, and R. Kotamarthi, “AERIS: Argonne earth systems model for reliable and skillful predictions,” inProceedings of the International Conference for High Performance Computing, Networking, S...
2025
-
[6]
40 Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel
J. Fang and S. Zhao, “USP: A unified sequence parallelism approach for long context generative AI,”CoRR, vol. abs/2405.07719, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.07719
-
[7]
Ring Attention with blockwise transformers for near-infinite context,
H. Liu, M. Zaharia, and P. Abbeel, “Ring Attention with blockwise transformers for near-infinite context,” inThe Twelfth International Conference on Learning Representations, ICLR 2024. OpenReview.net,
2024
-
[8]
Ring Attention with Blockwise Transformers for Near-Infinite Context
[Online]. Available: https://doi.org/10.48550/arXiv.2310.01889
work page internal anchor Pith review doi:10.48550/arxiv.2310.01889
-
[9]
Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Train- ing,
J. Liu, D. Li, G. Kestor, and J. Vetter, “Runtime Concurrency Control and Operation Scheduling for High Performance Neural Network Train- ing,” inInternational Parallel and Distributed Processing Symposium (IPDPS), 2019
2019
-
[10]
Intel Data Center GPU Max Series product brief,
Intel Corporation, “Intel Data Center GPU Max Series product brief,” https://www.intel.com/content/www/us/en/products/sku/232873/ intel-data-center-gpu-max-1550/specifications.html, 2023
2023
-
[11]
Aurora system overview,
Argonne Leadership Computing Facility, “Aurora system overview,” https://docs.alcf.anl.gov/aurora/getting-started-on-aurora/, 2024
2024
-
[12]
S. A. Jacobs, M. Tanaka, C. Zhang, M. Zhang, S. L. Song, S. Rajbhandari, and Y . He, “Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models,” arXiv preprint arXiv:2309.14509, 2023. [Online]. Available: https: //doi.org/10.48550/arXiv.2309.14509
work page internal anchor Pith review doi:10.48550/arxiv.2309.14509 2023
-
[13]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
M. Shoeybi, M. Patwary, R. Puri, P. LeGresley, J. Casper, and B. Catanzaro, “Megatron-LM: Training multi-billion parameter language models using model parallelism,”arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review arXiv 1909
-
[14]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
[Online]. Available: https://doi.org/10.48550/arXiv.1909.08053
work page internal anchor Pith review doi:10.48550/arxiv.1909.08053 1909
-
[15]
Efficient memory management for large language model serving with pagedattention
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inProceedings of the 29th Symposium on Operating Systems Principles, 2023, pp. 611–626. [Online]. Available: https://doi.org/10.1145/3600006.3613165
-
[16]
Accelerate: Training and infer- ence at scale made simple, efficient and adaptable,
S. Gugger, L. Debut, T. Wolfet al., “Accelerate: Training and infer- ence at scale made simple, efficient and adaptable,” https://github.com/ huggingface/accelerate, 2022
2022
-
[17]
RoFormer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[18]
T-VSL: text-guided visual sound source localization in mixtures
X. Ma, G. Fang, and X. Wang, “DeepCache: Accelerating diffusion models for free,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 15 762– 15 772. [Online]. Available: https://doi.org/10.1109/CVPR52733.2024. 01492
-
[19]
P. Chen, M. Shen, P. Ye, J. Cao, C. Tu, C. Bouganis, Y . Zhao, and T. Chen, “∆-dit: A training-free acceleration method tailored for diffusion transformers,”CoRR, vol. abs/2406.01125, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.01125
-
[20]
Learning-to-cache: Accelerating diffusion transformer via layer caching,
X. Ma, G. Fang, M. B. Mi, and X. Wang, “Learning-to-cache: Accelerating diffusion transformer via layer caching,” inAdvances in Neural Information Processing Systems 37 (NeurIPS), 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.01733
-
[21]
AttMEMO : Accelerating Transformers with Memoization on Big Memory Systems,
Y . Feng, H. Jeon, F. Blagojevic, C. Guyot, Q. Li, and D. Li, “AttMEMO : Accelerating Transformers with Memoization on Big Memory Systems,”
-
[22]
Available: https://arxiv.org/abs/2301.09262
[Online]. Available: https://arxiv.org/abs/2301.09262
-
[23]
NCCL: NVIDIA collective communications library,
NVIDIA, “NCCL: NVIDIA collective communications library,” https: //github.com/NVIDIA/nccl, 2025
2025
-
[24]
Optimization of collective communication operations in MPICH,
R. Thakur, R. Rabenseifner, and W. Gropp, “Optimization of collective communication operations in MPICH,”The International Journal of High Performance Computing Applications, vol. 19, no. 1, pp. 49–66,
-
[25]
Available: https://doi.org/10.1177/1094342005051521
[Online]. Available: https://doi.org/10.1177/1094342005051521
-
[26]
Blueconnect: Decomposing all-reduce for deep learning on heterogeneous network hierarchy,
M. Cho, U. Finkler, D. S. Kung, and H. C. Hunter, “Blueconnect: Decomposing all-reduce for deep learning on heterogeneous network hierarchy,” inProceedings of Machine Learning and Systems, SysML
- [27]
-
[28]
MPICH: A high performance and widely portable implementation of the MPI standard,
MPICH Team, “MPICH: A high performance and widely portable implementation of the MPI standard,” https://www.mpich.org/, 2025
2025
-
[29]
Intel oneAPI Collective Communications Library (oneCCL),
Intel Corporation, “Intel oneAPI Collective Communications Library (oneCCL),” https://github.com/oneapi-src/oneCCL, 2025
2025
-
[30]
CCCL: Node-Spanning GPU Collectives with CXL Memory Pooling
D. Xu, H. Meng, X. Chen, D. Zhu, W. Tang, F. Liu, L. Xie, W. Xiang, R. Shi, Y . Li, H. Hu, H. Zhang, J. Jiang, and D. Li, “Cccl: Node-spanning gpu collectives with cxl memory pooling,” 2026. [Online]. Available: https://arxiv.org/abs/2602.22457
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
cmpi: Using cxl memory sharing for mpi one-sided and two-sided inter-node com- munications,
X. Wang, B. Ma, J. Kim, B. Koh, H. Kim, and D. Li, “cmpi: Using cxl memory sharing for mpi one-sided and two-sided inter-node com- munications,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2025
2025
-
[32]
Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express Link,
D. Xu, Y . Feng, K. Shin, D. Kim, H. Jeon, and D. Li, “Efficient Tensor Offloading for Large Deep-Learning Model Training based on Compute Express Link,” in36th ACM/IEEE International Conference for High Performance Computing, Performance Measurement, Modeling and Tools (SC), 2024
2024
-
[33]
Timestep embedding tells: It’s time to cache for video diffusion model,
F. Liu, S. Zhang, X. Wang, Y . Wei, H. Qiu, Y . Zhao, Y . Zhang, Q. Ye, and F. Wan, “Timestep embedding tells: It’s time to cache for video diffusion model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025, pp. 7353–
2025
-
[34]
Timestep embedding tells: It’s time to cache for video diffusion model
[Online]. Available: https://doi.org/10.48550/arXiv.2411.19108
-
[35]
Machine Learning-Guided Memory Optimization for DLRM Inference on Tiered Memory,
B. Ma, J. Ren, S. Yang, B. Francis, E. Ardestani, M. Si, and D. Li, “Machine Learning-Guided Memory Optimization for DLRM Inference on Tiered Memory,” inInternational Symposium on High Performance Computer Architecture (HPCA), 2025
2025
-
[36]
Sentinel: Efficient Tensor Migration and Allocation on Heterogeneous Memory Systems for Deep Learning,
J. Ren, J. Luo, K. Wu, M. Zhang, H. Jeon, and D. Li, “Sentinel: Efficient Tensor Migration and Allocation on Heterogeneous Memory Systems for Deep Learning,” inInternational Symposium on High Performance Computer Architecture (HPCA), 2020
2020
-
[37]
xdit: an inference engine for diffusion transformers (dits) with massive parallelism,
J. Fang, J. Pan, J. Wang, A. Li, and X. Sun, “xDiT: An inference engine for diffusion transformers (DiTs) with massive parallelism,” arXiv preprint arXiv:2411.01738, 2024. [Online]. Available: https: //doi.org/10.48550/arXiv.2411.01738
-
[38]
Diffusers: State-of-the-art diffusion models,
P. von Platen, S. Patil, A. Lozhkovet al., “Diffusers: State-of-the-art diffusion models,”GitHub, 2022
2022
-
[39]
Black Forest Labs, “FLUX.2,” https://blackforestlabs.ai/flux-2/, 2025
2025
-
[40]
2010 20th International Conference on Pattern Recognition , author =
A. Hore and D. Ziou, “Image quality metrics: PSNR vs. SSIM,” in International Conference on Pattern Recognition (ICPR), 2010, pp. 2366–2369. [Online]. Available: https://doi.org/10.1109/ICPR.2010.579
-
[41]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,”IEEE Transactions on Image Processing, vol. 13, no. 4, pp. 600–612, 2004. [Online]. Available: https://doi.org/10.1109/TIP.2003.819861 11
-
[42]
Demystifying the resilience of large language model infer- ence: An end-to-end perspective,
B. Ma, V . Nikitin, X. Wang, T. Bicer, and D. Li, “mlr: Scalable laminography reconstruction based on memoization,” ser. SC ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 265–280. [Online]. Available: https://doi.org/10.1145/3712285.3759805
-
[43]
T-VSL: text-guided visual sound source localization in mixtures
M. Li, T. Cai, J. Cao, Q. Zhang, H. Cai, J. Bai, Y . Jia, M. Liu, K. Li, and S. Han, “DistriFusion: Distributed parallel inference for high-resolution diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 7183–7193. [Online]. Available: https://doi.org/10.1109/CVPR52733.2024.00686
-
[44]
PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
J. Wang, J. Fang, J. Pan, A. Li, and P. Yang, “PipeFusion: Displaced patch pipeline parallelism for inference of diffusion transformer models,”arXiv preprint arXiv:2405.14430, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2405.14430
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.14430 2024
-
[45]
AsyncDiff: Parallelizing diffusion models by asynchronous denoising,
Z. Chen, X. Ma, G. Fang, Z. Tan, and X. Wang, “AsyncDiff: Parallelizing diffusion models by asynchronous denoising,”arXiv preprint arXiv:2406.06911, 2024. [Online]. Available: https://doi.org/ 10.48550/arXiv.2406.06911
-
[46]
Scale- Fusion: Scalable inference of spatial-temporal diffusion transformers for high-resolution long video generation,
H. Chen, Z. He, R. Chen, Z. Ye, J. Xue, C. Zhuo, and L. Ma, “Scale- Fusion: Scalable inference of spatial-temporal diffusion transformers for high-resolution long video generation,” inProceedings of Machine Learning and Systems (MLSys), 2025
2025
-
[47]
J. Luo, Y . Li, and C. Zhang, “StreamFusion: Scalable sequence parallelism for distributed inference of diffusion transformers on GPUs,”arXiv preprint arXiv:2601.20273, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2601.20273
-
[48]
CacheQuant: Comprehensively accelerated diffusion models,
J. Liu and Z. Wang, “CacheQuant: Comprehensively accelerated diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2503.01323
-
[49]
Kim, Y ., Jang, J., and Shin, S
K. Kahatapitiya, H. Zheng, M. Jia, X. Zhang, M. S. Ryoo, and T. Xie, “AdaCache: Adaptive caching for faster video generation with diffusion transformers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2411.02397
-
[50]
F. Liu, S. Huang, H. Liu, Y . Tang, K. Han, and Y . Wang, “From reusing to forecasting: Accelerating diffusion models with TaylorSeers,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2503.06923
-
[51]
SpeCa: Accelerating diffusion transformers with speculative feature caching,
J. Zhao, J. Pan, and H. Zhu, “SpeCa: Accelerating diffusion transformers with speculative feature caching,”arXiv preprint arXiv:2509.11628,
-
[52]
Available: https://doi.org/10.1145/3746027.3755331
[Online]. Available: https://doi.org/10.1145/3746027.3755331
-
[53]
MD-HM: Memoization-based Molecular Dynamics Simulations on Big Memory System,
Z. Xie, W. Dong, J. Liu, I. Peng, Y . Ma, and D. Li, “MD-HM: Memoization-based Molecular Dynamics Simulations on Big Memory System,” inInternational Conference on Supercomputing (ICS), 2021
2021
-
[54]
Reducing activation recomputation in large transformer models, 2022
V . A. Korthikanti, J. Casper, S. Lym, L. McAfee, M. Andersch, M. Shoeybi, and B. Catanzaro, “Reducing activation recomputation in large transformer models,” inProceedings of Machine Learning and Systems, vol. 5, 2023, pp. 341–353. [Online]. Available: https://doi.org/10.48550/arXiv.2205.05198
-
[55]
arXiv preprint arXiv:2311.09431 (2023)
W. Brandon, A. Nrusimha, K. Qian, Z. Ankner, T. Jin, Z. Song, and J. Ragan-Kelley, “Striped attention: Faster ring attention for causal transformers,”CoRR, vol. abs/2311.09431, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2311.09431
-
[56]
Xing, Xuezhe Ma, Ion Stoica, Joseph E
D. Li, R. Shao, A. Xie, E. P. Xing, J. E. Gonzalez, I. Stoica, X. Ma, and H. Zhang, “Lightseq: Sequence level parallelism for distributed training of long context transformers,”arXiv preprint arXiv:2310.03294, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2310.03294
-
[57]
D. Gu, P. Sun, Q. Hu, T. Huang, X. Chen, Y . Xiong, G. Wang, Q. Chen, S. Zhao, J. Fang, Y . Wen, T. Zhang, X. Jin, and X. Liu, “Loongtrain: Efficient training of long-sequence LLMs with head- context parallelism,”arXiv preprint arXiv:2406.18485, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.18485 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.