Recognition: unknown
Enhancing Mental Health Counseling Support in Bangladesh using Culturally-Grounded Knowledge
Pith reviewed 2026-05-10 11:19 UTC · model grok-4.3
The pith
A manually built knowledge graph improves LLM counseling responses for Bangladesh over retrieval-augmented generation alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
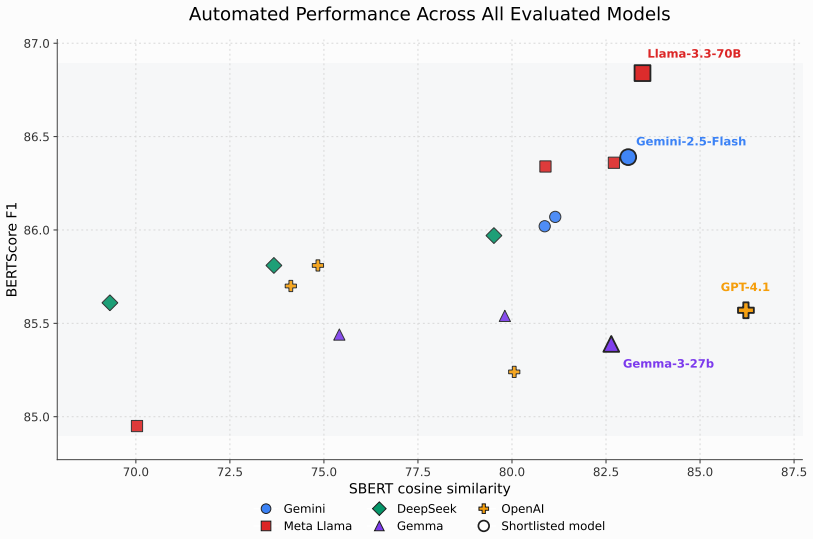
The central claim is that KG-based approaches using the manually constructed and clinically validated knowledge graph outperform RAG alone, as shown by higher BERTScore F1 and SBERT cosine similarity scores plus superior human evaluations on contextual relevance, clinical appropriateness, and practical usability. This demonstrates that structured, expert-validated knowledge plays a critical role in addressing LLMs' limitations in generating supportive responses for mental health counseling in the Bangladeshi cultural context.
What carries the argument
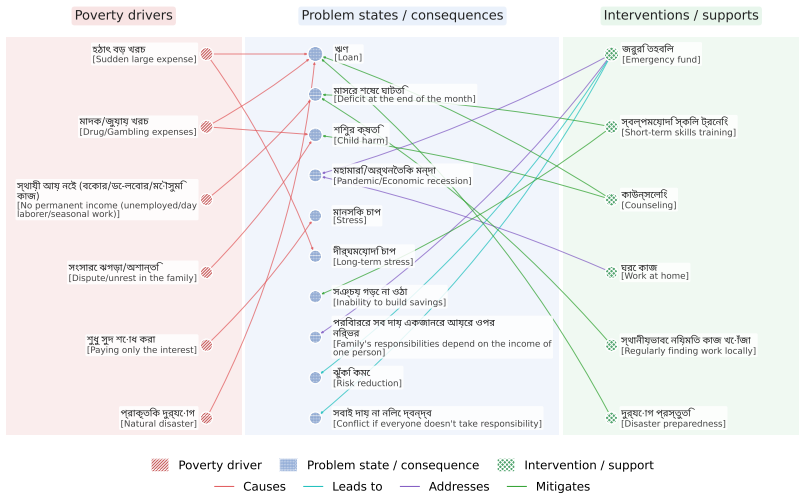
A manually constructed and clinically validated knowledge graph that encodes causal relationships between stressors, interventions, and outcomes in the Bangladeshi cultural context.
If this is right
- KG-enhanced responses score higher on automated similarity metrics and human-rated counseling effectiveness than RAG responses.
- Structured expert knowledge mitigates LLMs' lack of cultural sensitivity and clinical grounding in mental health tasks.
- Para-counselors gain access to more reliable AI-generated guidance when the validated knowledge graph is used.
- Expert validation of the graph is essential for the observed improvements over unstructured retrieval methods.
Where Pith is reading between the lines
- The same manual KG construction process could be repeated in other cultural settings to adapt LLM counseling tools locally.
- Partial automation of graph building combined with clinical validation steps might allow wider deployment without losing reliability.
- Real-world trials with actual clients would test whether the measured improvements in response quality lead to better support outcomes.
Load-bearing premise
The manually constructed and clinically validated knowledge graph accurately captures causal relationships between stressors, interventions, and outcomes in the Bangladeshi cultural context.
What would settle it
A controlled comparison in which para-counselors use both systems in real sessions and the KG version shows no advantage or produces more inappropriate suggestions according to client feedback or expert review of transcripts.
Figures



read the original abstract
Large language models (LLMs) show promise in generating supportive responses for mental health and counseling applications. However, their responses often lack cultural sensitivity, contextual grounding, and clinically appropriate guidance. This work addresses the gap of how to systematically incorporate domain-specific, clinically validated knowledge into LLMs to improve counseling quality. We utilize and compare two approaches, retrieval-augmented generation (RAG) and a knowledge graph (KG)-based method, designed to support para-counselors. Our KG is constructed manually and clinically validated, capturing causal relationships between stressors, interventions, and outcomes, with contributions from multidisciplinary people. We evaluated multiple LLMs in both settings using BERTScore F1 and SBERT cosine similarity, as well as human evaluation across five metrics, which is designed to directly measure the effectiveness of counseling beyond similarity at the surface level. The results show that KG-based approaches consistently improve contextual relevance, clinical appropriateness, and practical usability compared to RAG alone, demonstrating that structured, expert-validated knowledge plays a critical role in addressing LLMs limitations in counseling tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes enhancing LLM-based mental health counseling for Bangladesh by comparing retrieval-augmented generation (RAG) against a knowledge graph (KG)-based approach. The KG is manually constructed and clinically validated by a multidisciplinary team to encode causal relationships among stressors, interventions, and outcomes. Evaluations using BERTScore F1, SBERT cosine similarity, and human ratings on five metrics (contextual relevance, clinical appropriateness, practical usability, and two others) are reported to show consistent gains for the KG method over RAG, supporting the claim that structured expert knowledge mitigates LLM limitations in culturally sensitive counseling tasks.
Significance. If the central claim holds after addressing evaluation gaps, the work would demonstrate a practical route for injecting culturally grounded, clinically validated structure into LLMs for mental-health support in low-resource settings. The combination of automatic similarity metrics with human evaluations explicitly targeting counseling effectiveness (rather than surface similarity alone) and the multidisciplinary KG construction are positive elements that strengthen the contribution.
major comments (2)
- [Abstract] Abstract: The claim of consistent improvements via BERTScore F1, SBERT similarity, and five human metrics is presented without any reported sample sizes, statistical tests, baseline controls, or inter-rater reliability statistics. These omissions are load-bearing for the central claim that KG-based methods outperform RAG in contextual relevance, clinical appropriateness, and practical usability.
- [Abstract] Abstract: The KG is described as 'constructed manually and clinically validated' with multidisciplinary contributions, yet no quantitative validation details (inter-rater agreement, coverage statistics, or external review process) are supplied. This directly affects the weakest assumption that the KG accurately captures causal relationships in the Bangladeshi context; without such measures it remains possible that observed gains arise from curated content rather than the structured KG methodology itself.
minor comments (1)
- [Abstract] The abstract sentence 'five metrics, which is designed to directly measure' contains a subject-verb agreement error and should read 'which are designed'.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify important gaps in how the evaluation evidence is summarized. We address each point below and will revise the manuscript to improve transparency and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of consistent improvements via BERTScore F1, SBERT similarity, and five human metrics is presented without any reported sample sizes, statistical tests, baseline controls, or inter-rater reliability statistics. These omissions are load-bearing for the central claim that KG-based methods outperform RAG in contextual relevance, clinical appropriateness, and practical usability.
Authors: We agree that the abstract should more explicitly support the reported gains. The full manuscript details the evaluation protocol, including the number of test queries, the RAG baseline, and human ratings by multiple experts. We will revise the abstract to report sample sizes for both automatic and human evaluations, note the statistical tests performed, and include inter-rater reliability. This will make the strength of the evidence clearer without changing the underlying results. revision: yes
-
Referee: [Abstract] Abstract: The KG is described as 'constructed manually and clinically validated' with multidisciplinary contributions, yet no quantitative validation details (inter-rater agreement, coverage statistics, or external review process) are supplied. This directly affects the weakest assumption that the KG accurately captures causal relationships in the Bangladeshi context; without such measures it remains possible that observed gains arise from curated content rather than the structured KG methodology itself.
Authors: We acknowledge that quantitative validation metrics for the KG are not currently reported. We will expand both the abstract and the methods section to include inter-rater agreement among the multidisciplinary contributors, coverage statistics for stressors and interventions, and details of the external review process. These additions will better substantiate that the structured causal relationships, rather than curation alone, drive the improvements. revision: yes
Circularity Check
No circularity; empirical comparison rests on independent metrics and evaluations
full rationale
The paper describes an empirical study: a manually constructed, clinically validated KG is used to augment LLMs, then compared to RAG baselines via BERTScore F1, SBERT cosine similarity, and separate human ratings on five metrics. No equations, fitted parameters, or first-principles derivations appear. The central claim (KG-based methods outperform RAG on contextual relevance, clinical appropriateness, and usability) is supported by external automatic and human evaluations rather than reducing to any self-defined quantity or self-citation chain. The KG construction and validation steps are methodological inputs, not outputs that the results are forced to match by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert multidisciplinary input produces a clinically valid knowledge graph for Bangladeshi mental health
- domain assumption BERTScore F1, SBERT cosine similarity, and the five human metrics correlate with real counseling quality
Reference graph
Works this paper leans on
-
[1]
Yasmina Al Ghadban, Huiqi Lu, Uday Adavi, Ankita Sharma, Sridevi Gara, Neelanjana Das, Bhaskar Kumar, Renu John, Praveen Devarsetty, and Jane E Hirst. 2023. Transforming healthcare education: Harnessing large language models for frontline health worker capacity building using retrieval-augmented generation. medRxiv, pages 2023--12
2023
-
[2]
Mahwish Aleem, Imama Zahoor, and Mustafa Naseem. 2024. Towards culturally adaptive large language models in mental health: Using ChatGPT as a case study. In Companion Publication of the 2024 Conference on Computer-Supported Cooperative Work and Social Computing, pages 240--247, New York, NY, USA. ACM
2024
-
[3]
Jiale Cheng, Sahand Sabour, Hao Sun, Zhuang Chen, and Minlie Huang. 2023. Pal: Persona-augmented emotional support conversation generation. In Findings of the Association for Computational Linguistics: ACL 2023, pages 535--554
2023
-
[4]
Young Min Cho, Sunny Rai, Lyle Ungar, Jo \ a o Sedoc, and Sharath Guntuku. 2023. An integrative survey on mental health conversational agents to bridge computer science and medical perspectives. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11346--11369
2023
-
[5]
Jacinthe Flore. 2023. The artefacts of digital mental health. Springer
2023
-
[6]
Sarah Harrison, Alex Ssimbwa, Mohamed Elshazly, Mahmuda Mahmuda, Mohamed Zahidul Islam, Hasna Akter Sumi, and Olga Alexandra Rebolledo. 2019. Strategic priorities for mental health and psychosocial support services for rohingya refugees in bangladesh: a field report. Intervention Journal of Mental Health and Psychosocial Support in Conflict Affected Areas...
2019
-
[7]
Rubina Jahan, Md Ashiquir Rahaman, and Arun Das. 2024. Ngos working on mental health in bangladesh. In Mental Health in Bangladesh: From Bench to Community, pages 323--342. Springer
2024
-
[8]
Swanie Juhng, Matthew Matero, Vasudha Varadarajan, Johannes Eichstaedt, Adithya V Ganesan, and H Andrew Schwartz. 2023. Discourse-level representations can improve prediction of degree of anxiety. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 1500--1511
2023
-
[9]
Henrique A Lima, Pedro HFS Trocoli-Couto, Marzia Zaman, D \'e bora C Engelmann, Rosalind Parkes-Ratanshi, Leah Junck, Brenda Hendry, Amelia Taylor, Michelle El Kawak, Nirmal Ravi, and 1 others. 2025. Spotlighting healthcare frontline workers \' perceptions on artificial intelligence across the globe. npj Health Systems, 2(1):28
2025
-
[10]
Chen Cecilia Liu, Hiba Arnaout, Nils Kova c i \'c , Dana Atzil-Slonim, and Iryna Gurevych. 2026. Tailored emotional llm-supporter: Enhancing cultural sensitivity. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 535--574
2026
-
[11]
Daniel Lozoya, Alejandro Berazaluce, Juan Perches, Eloy L \'u a, Mike Conway, and Simon D’Alfonso. 2024. Generating mental health transcripts with sape (spanish adaptive prompt engineering). In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pape...
2024
-
[12]
Zilin Ma, Yiyang Mei, Yinru Long, Zhaoyuan Su, and Krzysztof Z Gajos. 2024. Evaluating the experience of LGBTQ+ people using large language model based chatbots for mental health support. arXiv [cs.HC]
2024
-
[13]
Zafarullah Mahmood, Soliman Ali, Jiading Zhu, Mohamed Abdelwahab, Michelle Yu Collins, Sihan Chen, Yi Cheng Zhao, Jodi Wolff, Osnat C Melamed, Nadia Minian, and 1 others. 2025. A fully generative motivational interviewing counsellor chatbot for moving smokers towards the decision to quit. In Findings of the Association for Computational Linguistics: ACL 2...
2025
-
[14]
Subhankar Maity and Manob Jyoti Saikia. 2025. Large language models in healthcare and medical applications: a review. Bioengineering, 12(6):631
2025
-
[15]
Erum Mariam and Sarah Tabassum. 2023. Sisters of peace: Para-counselors lead psychosocial support for rohingya children and families during covid-19. In Young Children in Humanitarian and COVID-19 Crises, pages 197--210. Routledge
2023
-
[16]
Pierrette MAHORO MASTEL, Jean de Dieu Nyandwi, Samuel Rutunda, and Kleber Kabanda. 2025. Mbaza rbc: Deploying and evaluation of an llm powered chatbot for community health workers in rwanda. In Workshop on Large Language Models and Generative AI for Health at AAAI 2025
2025
-
[17]
Shervin Minaee, Tomas Mikolov, Narjes Nikzad, Meysam Chenaghlu, Richard Socher, Xavier Amatriain, and Jianfeng Gao. 2024. Large language models: A survey. arXiv preprint arXiv:2402.06196
work page internal anchor Pith review arXiv 2024
-
[18]
Jared Moore, Declan Grabb, William Agnew, Kevin Klyman, Stevie Chancellor, Desmond C Ong, and Nick Haber. 2025. Expressing stigma and inappropriate responses prevents llms from safely replacing mental health providers. In Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 599--627
2025
-
[19]
Maria Moosa, Oluwaseyi Malumi, Solomon Chinedu, Wilson Okah, Ayoposi Ogboye, Chiagozie Abiakam, Peter Onyenemerem, Imo Etuk, and Nneka Mobisson. 2025. Evaluating frontline health workers’ responses to patient inquiries with and without large language model support in nigeria: An observational study. VeriXiv, 2:324
2025
-
[20]
Md Ashiquir Rahaman. 2025. Mental health of handloom weavers in bangladesh: A call for culturally adapted interventions. Cambridge Prisms: Global Mental Health, 12:e123
2025
-
[21]
Pragnya Ramjee, Mehak Chhokar, Bhuvan Sachdeva, Mahendra Meena, Hamid Abdullah, Aditya Vashistha, Ruchit Nagar, and Mohit Jain. 2025. Ashabot: An llm-powered chatbot to support the informational needs of community health workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1--22
2025
-
[22]
Samuel Rutunda, Gwydion Williams, Kleber Kabanda, Francis Nkurunziz, Solange Uwiduhaye, Eulade Rugegamanzi, Cyprien Nshimiyimana, Vaishnavi Menon, Mira Emmanuel-Fabula, Alastair K Denniston, and 1 others. 2025. How good are large language models at supporting frontline healthcare workers in low-resource settings--a benchmarking study & dataset. medRxiv, p...
2025
-
[23]
Sahand Sabour, Siyang Liu, Zheyuan Zhang, June Liu, Jinfeng Zhou, Alvionna Sunaryo, Tatia Lee, Rada Mihalcea, and Minlie Huang. 2024. Emobench: Evaluating the emotional intelligence of large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5986--6004
2024
-
[24]
Miner, Theresa Nguyen, and Tim Althoff
Ashish Sharma, Kevin Rushton, Inna Wanyin Lin, David Wadden, Khendra Lucas, Adam S. Miner, Theresa Nguyen, and Tim Althoff. 2023. https://api.semanticscholar.org/CorpusID:258480165 Cognitive reframing of negative thoughts through human-language model interaction . In Annual Meeting of the Association for Computational Linguistics
2023
-
[25]
Daisy R Singla, Sabrina Hossain, Nicole Andrejek, Matthew J Cohen, Cindy-Lee Dennis, Jo Kim, Laura La Porte, Samantha E Meltzer-Brody, Angie Puerto Nino, Paula Ravitz, and 1 others. 2022. Culturally sensitive psychotherapy for perinatal women: A mixed methods study. Journal of Consulting and Clinical Psychology, 90(10):770
2022
-
[26]
Hoyun Song, Huije Lee, Jisu Shin, Sukmin Cho, Changgeon Ko, and Jong C Park. 2025 a . Does rationale quality matter? enhancing mental disorder detection via selective reasoning distillation. In Findings of the Association for Computational Linguistics: ACL 2025, pages 21738--21756
2025
-
[27]
Inhwa Song, Sachin R Pendse, Neha Kumar, and Munmun De Choudhury. 2025 b . The typing cure: Experiences with large language model chatbots for mental health support. Proceedings of the ACM on Human-Computer Interaction, 9(7):1--29
2025
-
[28]
Ming Wang, Peidong Wang, Lin Wu, Xiaocui Yang, Daling Wang, Shi Feng, Yuxin Chen, Bixuan Wang, and Yifei Zhang. 2025. Annaagent: Dynamic evolution agent system with multi-session memory for realistic seeker simulation. In Findings of the Association for Computational Linguistics: ACL 2025, pages 23221--23235
2025
-
[29]
Xuhai Xu, Bingsheng Yao, Yuanzhe Dong, Saadia Gabriel, Hong Yu, James Hendler, Marzyeh Ghassemi, Anind K Dey, and Dakuo Wang. 2024. Mental-llm: Leveraging large language models for mental health prediction via online text data. Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 8(1):1--32
2024
-
[30]
Kailai Yang, Shaoxiong Ji, Tianlin Zhang, Qianqian Xie, Ziyan Kuang, and Sophia Ananiadou. 2023. Towards interpretable mental health analysis with large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6056--6077
2023
-
[31]
Wei Zhai, Hongzhi Qi, Qing Zhao, Jianqiang Li, Ziqi Wang, Han Wang, Bing Yang, and Guanghui Fu. 2024. Chinese mentalbert: Domain-adaptive pre-training on social media for chinese mental health text analysis. In Findings of the Association for Computational Linguistics: ACL 2024, pages 10574--10585
2024
-
[32]
Xinzhe Zheng, Sijie Ji, Jiawei Sun, Renqi Chen, Wei Gao, and Mani Srivastava. 2025. https://doi.org/10.18653/v1/2025.findings-acl.1033 P ro M ind- LLM : Proactive mental health care via causal reasoning with sensor data . In Findings of the Association for Computational Linguistics: ACL 2025, pages 20150--20171, Vienna, Austria. Association for Computatio...
-
[33]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[34]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.