Recognition: unknown
ConfLayers: Adaptive Confidence-based Layer Skipping for Self-Speculative Decoding
Pith reviewed 2026-05-10 11:36 UTC · model grok-4.3
The pith
Confidence scores guide dynamic layer skipping to form draft models that speed up LLM generation by up to 1.4 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
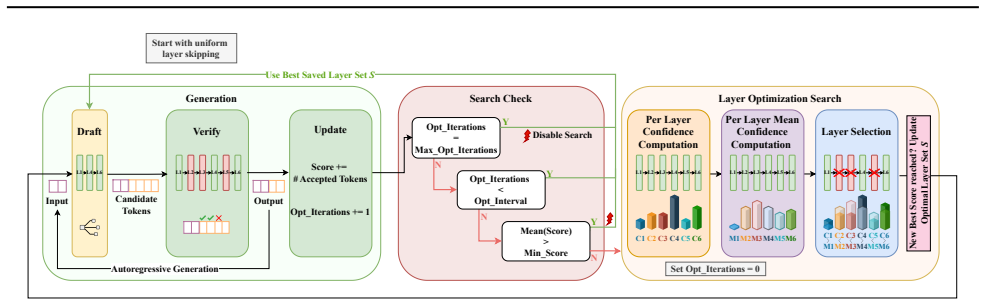
ConfLayers creates the draft model for self-speculative decoding by iteratively calculating confidence scores across layers, applying an adaptive threshold to choose which layers to skip, evaluating the quality and speed of the resulting subnetwork, and refining the selection until no further improvement occurs or a maximum iteration count is reached. This produces an adaptive draft without any separate training step for the skipping decisions.
What carries the argument
The iterative confidence-score computation and adaptive-threshold selection loop that optimizes which layers to skip when forming the draft model.
If this is right
- The method reaches up to 1.4x speedup over ordinary LLM generation on the tested models and datasets.
- It delivers steadier speed versus quality results than fixed heuristics or separately trained skipping policies.
- No training run is required to learn which layers to skip, removing that source of overhead.
- The draft model remains able to adjust to new tasks and data distributions through the runtime selection process.
Where Pith is reading between the lines
- The same confidence-driven loop could be applied to other model components such as attention heads or embedding layers for additional gains.
- Hardware-specific tuning of the iteration limit or threshold might further reduce latency on edge devices.
- The approach may combine with existing speculative decoding variants that use different draft sources to compound the speed benefit.
Load-bearing premise
That confidence scores computed at intermediate layers will point to skip choices that keep the draft model close enough to the full model for efficient correction during verification.
What would settle it
A direct comparison on a held-out model or dataset where ConfLayers either produces no net speedup, runs slower than standard generation, or yields lower output quality than vanilla self-speculative decoding or other skipping heuristics.
Figures







read the original abstract
Self-speculative decoding is an inference technique for large language models designed to speed up generation without sacrificing output quality. It combines fast, approximate decoding using a compact version of the model as a draft model with selective re-evaluation by the full target model. Some existing methods form the draft model by dynamically learning which layers to skip during inference, effectively creating a smaller subnetwork to speed up computation. However, using heuristic-based approaches to select layers to skip can often be simpler and more effective. In this paper, we propose ConfLayers, a dynamic plug-and-play approach to forming the draft model in self-speculative decoding via confidence-based intermediate layer skipping. The process iteratively computes confidence scores for all layers, selects layers to skip based on an adaptive threshold, evaluates the performance of the resulting set, and updates the best selection until no further improvement is achieved or a maximum number of iterations is reached. This framework avoids the overhead and complexity of training a layer skipping policy and can provide more consistent speed-quality trade-offs while preserving the adaptivity of the draft model to diverse tasks and datasets. The performance evaluation of ConfLayers across different models and datasets shows that our novel approach offers up to 1.4x speedup over vanilla LLM generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ConfLayers, a plug-and-play method for self-speculative decoding that forms an adaptive draft model by iteratively computing per-layer confidence scores, applying an adaptive threshold to select layers to skip, evaluating the resulting subnetwork's performance, and retaining the best selection until convergence or an iteration limit. It claims this training-free approach yields more consistent speed-quality trade-offs than learned policies and delivers up to 1.4x speedup over vanilla LLM generation across models and datasets.
Significance. If the net speedup claim holds after rigorous accounting for search overhead and with proper baselines, the work could offer a practical alternative to trained layer-skipping policies for LLM inference acceleration, emphasizing adaptivity without training costs.
major comments (2)
- [Method] Method section (iterative selection procedure): the 'evaluate performance' step in the loop is described only at a high level; it is unclear whether this requires extra forward passes, token generation, or quality metrics on candidate drafts at inference time. Without explicit cost accounting, the 1.4x speedup cannot be confirmed as a net gain over vanilla or fixed-heuristic baselines.
- [Experiments] Experiments section: the central claim of 'up to 1.4x speedup' is stated without reported models, datasets, exact baselines (including the heuristic methods the abstract itself calls 'simpler and more effective'), measurement protocol (tokens/s including search cost), or error analysis. This renders the performance evaluation unverifiable from the provided details.
minor comments (1)
- [Abstract] Abstract: the phrase 'preserving the adaptivity of the draft model to diverse tasks and datasets' is repeated without concrete examples or metrics; move supporting evidence to the experiments section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below and will revise the paper to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Method] Method section (iterative selection procedure): the 'evaluate performance' step in the loop is described only at a high level; it is unclear whether this requires extra forward passes, token generation, or quality metrics on candidate drafts at inference time. Without explicit cost accounting, the 1.4x speedup cannot be confirmed as a net gain over vanilla or fixed-heuristic baselines.
Authors: We agree that the 'evaluate performance' step is described at a high level and requires explicit elaboration. In the revised manuscript we will expand the method section to detail exactly how performance is assessed (including any forward passes or metrics on candidate subnetworks), specify whether this occurs in an offline selection phase or online, and provide a full cost breakdown showing that the overhead is amortized such that the reported net speedup holds relative to vanilla generation and heuristic baselines. revision: yes
-
Referee: [Experiments] Experiments section: the central claim of 'up to 1.4x speedup' is stated without reported models, datasets, exact baselines (including the heuristic methods the abstract itself calls 'simpler and more effective'), measurement protocol (tokens/s including search cost), or error analysis. This renders the performance evaluation unverifiable from the provided details.
Authors: We acknowledge that the experiments section lacks sufficient detail for independent verification. The revised version will explicitly list the models and sizes tested, the datasets, the precise heuristic baselines referenced in the abstract, the full measurement protocol (tokens per second inclusive of all search and selection costs), and any error analysis or variance reporting. These additions will be presented in tables and text to substantiate the 1.4x speedup claim. revision: yes
Circularity Check
No circularity: heuristic procedure with empirical evaluation only
full rationale
The paper describes ConfLayers as a plug-and-play iterative procedure: compute per-layer confidence scores, apply adaptive threshold to select skips, evaluate the resulting subnetwork performance, and retain the best set until convergence or iteration limit. No equations, derivations, or first-principles results appear that reduce to their own inputs by construction. Speedup claims (up to 1.4x) rest on direct empirical measurement across models/datasets rather than any fitted parameter renamed as prediction or self-referential definition. The method is self-contained against external benchmarks and does not invoke load-bearing self-citations or uniqueness theorems.
Axiom & Free-Parameter Ledger
free parameters (2)
- adaptive threshold
- maximum number of iterations
axioms (1)
- domain assumption Confidence scores computed at intermediate layers indicate which layers can be skipped without substantial degradation of final output quality.
Forward citations
Cited by 2 Pith papers
-
Component-Aware Self-Speculative Decoding in Hybrid Language Models
Component-aware self-speculative decoding achieves high acceptance rates in parallel hybrid models like Falcon-H1 but fails in sequential ones like Qwen3.5, with the gap tied to how components are integrated.
-
BEAM: Binary Expert Activation Masking for Dynamic Routing in MoE
BEAM uses binary expert activation masks trained end-to-end to achieve dynamic sparsity in MoE models, cutting FLOPs by 85% with over 98% performance retention.
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. ISBN 979-8-89176-251-0. doi: 10.18653/v1/2025.acl-long
-
[2]
acl-long.1525/
URL https://aclanthology.org/2025. acl-long.1525/. Chen, Z., May, A., Svirschevski, R., Huang, Y .-H., Ryabinin, M., Jia, Z., and Chen, B. Sequoia: Scalable and robust speculative decoding. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems,
2025
-
[3]
LayerSkip: enabling early exit inference and self- speculative decoding
URL https://openreview.net/forum? id=rk2L9YGDi2. Elhoushi, M., Shrivastava, A., Liskovich, D., Hosmer, B., Wasti, B., Lai, L., Mahmoud, A., Acun, B., Agarwal, S., Roman, A., Aly, A., Chen, B., and Wu, C.-J. Layer- Skip: Enabling early exit inference and self-speculative decoding. In Ku, L.-W., Martins, A., and Srikumar, V . (eds.),Proceedings of the 62nd ...
-
[4]
findings-emnlp.668/
URL https://aclanthology.org/2025. findings-emnlp.668/. Liao, B., Xu, Y ., Dong, H., Li, J., Monz, C., Savarese, S., Sahoo, D., and Xiong, C. Reward-guided specula- tive decoding for efficient LLM reasoning. InF orty- second International Conference on Machine Learning,
2025
-
[5]
Liu, F., Tang, Y ., Liu, Z., Ni, Y ., Tang, D., Han, K., and Wang, Y
URL https://openreview.net/forum? id=AVeskAAETB. Liu, F., Tang, Y ., Liu, Z., Ni, Y ., Tang, D., Han, K., and Wang, Y . Kangaroo: Lossless self-speculative decoding for accelerating llms via double early exiting. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.), Advances in Neural Information Processing Sy...
-
[6]
LLM tropes: Revealing fine-grained values and opinions in large language models
URL https://proceedings.neurips. cc/paper_files/paper/2024/file/ 16336d94a5ffca8de019087ab7fe403f-Paper\ -Conference.pdf. Metel, M. R., Lu, P., Chen, B., Rezagholizadeh, M., and Kobyzev, I. Draft on the fly: Adaptive self- speculative decoding using cosine similarity. In Al- Onaizan, Y ., Bansal, M., and Chen, Y .-N. (eds.),Find- ings of the Association f...
-
[7]
Code Llama: Open Foundation Models for Code
URL https://aclanthology.org/2024. findings-emnlp.124/. Rozi`ere, B., Gehring, J., Gloeckle, F., Sootla, S., Gat, I., Tan, X. E., Adi, Y ., Liu, J., Sauvestre, R., Remez, T., Rapin, J., Kozhevnikov, A., Evtimov, I., Bitton, J., Bhatt, M., Ferrer, C. C., Grattafiori, A., Xiong, W., D ´efossez, 9 A., Copet, J., Azhar, F., Touvron, H., Martin, L., Usunier, N...
work page internal anchor Pith review arXiv 2024
-
[8]
Llama 2: Open Foundation and Fine-Tuned Chat Models
URL https://openreview.net/forum? id=vQubr1uBUw. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V ., Goyal, N., Hartshorn, A., Hosseini, S....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.607 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.