Recognition: unknown
Pushing the Boundaries of Multiple Choice Evaluation to One Hundred Options
Pith reviewed 2026-05-10 12:09 UTC · model grok-4.3
The pith
Multiple-choice benchmarks with few options can overstate large language model competence because performance often drops when candidate sets scale to one hundred.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
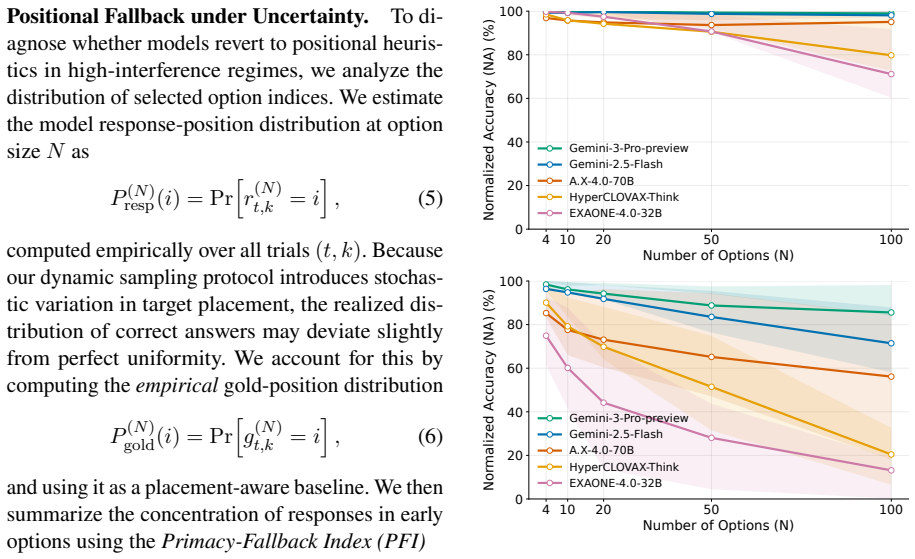
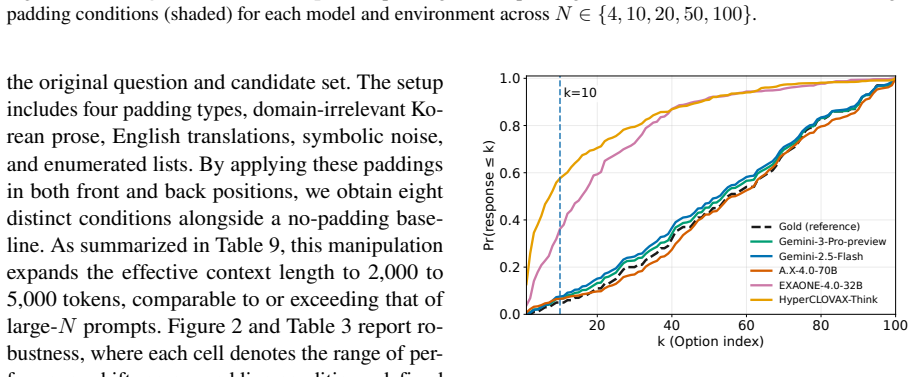
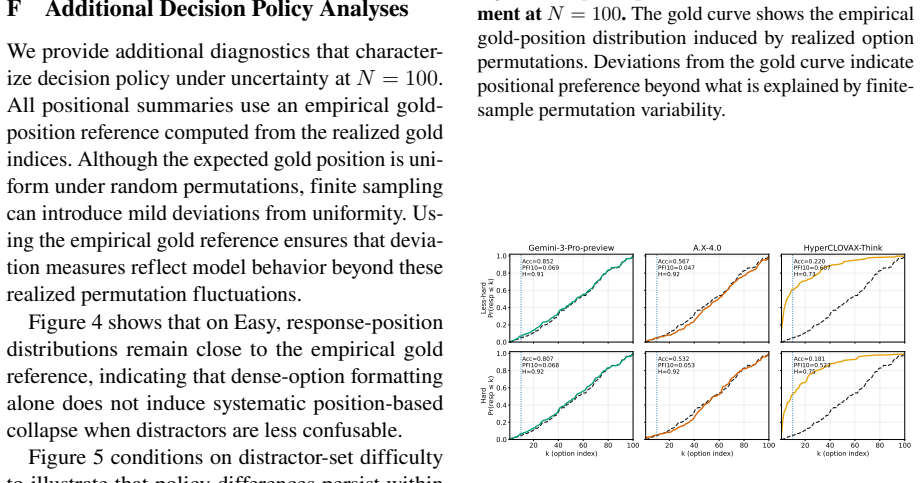
By scaling candidate sets to 100 options in a Korean orthography error detection task with fixed targets and repeated resampling plus shuffling, strong low-option performance weakens under dense interference, exposing semantic confusion and position bias toward early options as primary failure modes while showing that candidate ranking rather than context length is the main bottleneck.
What carries the argument
The massive option evaluation protocol that scales to 100 candidates with fixed targets, repeated resampling, and shuffling to produce stable estimates of ranking performance under high distractor density.
If this is right
- High-N tests produce more reliable estimates of model competence than low-N benchmarks.
- Apparent strengths in standard evaluations may require downward adjustment when distractor density increases.
- Ranking among many candidates forms the core limit rather than processing longer inputs.
- Semantic confusion and early-position bias emerge as distinct failure modes only visible at high option counts.
Where Pith is reading between the lines
- Similar high-N protocols could be applied to other tasks or languages to check whether overstatement occurs more broadly in model evaluations.
- Training methods focused on distractor discrimination might improve robustness in dense option settings.
- Benchmark suites could incorporate variable option counts to give more graded assessments of reliability.
Load-bearing premise
The Korean orthography error detection task with fixed targets and repeated resampling provides a representative probe of general model ranking ability rather than being dominated by language-specific or task-specific artifacts.
What would settle it
Observing that models maintain high accuracy from low-option to 100-option versions of the task without increased semantic confusion or position bias would challenge the claim that low-option results overstate competence.
Figures


read the original abstract
Multiple choice evaluation is widely used for benchmarking large language models, yet near ceiling accuracy in low option settings can be sustained by shortcut strategies that obscure true competence. Therefore, we propose a massive option evaluation protocol that scales the candidate set to one hundred options and sharply reduces the impact of chance performance. We apply this framework to a Korean orthography error detection task where models must pick the single incorrect sentence from a large candidate set. With fixed targets and repeated resampling and shuffling, we obtain stable estimates while separating content driven failures from positional artifacts. Across experiments, results indicate that strong performance in low option settings can overstate model competence. This apparent advantage often weakens under dense interference at high $N$, revealing gaps that conventional benchmarks tend to obscure. We identify two failure modes, semantic confusion and position bias toward early options under uncertainty. To isolate the effect of context length, we run padding controlled and length matched tests, which suggest that the main bottleneck is candidate ranking rather than context length. Together, these findings support massive option evaluation as a general framework for stress testing model reliability under extreme distractor density, beyond what low option benchmarks can reveal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes scaling multiple-choice evaluation to 100 options as a protocol to reduce the impact of chance performance and shortcut strategies in LLM benchmarking. Using a Korean orthography error detection task with fixed incorrect targets, repeated resampling, shuffling, and controls for position bias and context length (via padding and length-matched tests), the authors report that strong low-N accuracy often weakens under high distractor density. They identify semantic confusion and early-position bias as primary failure modes, concluding that the framework better reveals competence gaps obscured by conventional low-option benchmarks.
Significance. If the protocol generalizes, it could strengthen LLM evaluation by providing a denser stress test that isolates ranking ability from positional or length artifacts. The empirical controls and focus on failure modes are constructive contributions to benchmarking methodology. However, the single-task, language-specific design limits immediate broader impact on the field.
major comments (2)
- Abstract and introduction: The central claim that high-N results expose general gaps in model competence (rather than task-specific effects) is load-bearing. The Korean orthography error detection task involves Hangul-specific character confusions, spelling rules, and potential training-data imbalances absent in other languages or tasks; without cross-lingual or cross-task validation experiments, the conclusion that conventional benchmarks obscure true competence is not yet supported.
- Results and methodology sections: The abstract supplies no quantitative accuracy figures, error bars, or statistical tests for the performance drop from low-N to N=100, nor details on the number of models, resampling iterations, or significance of the observed failure modes. This weakens assessment of whether the weakening is robust or magnitude is meaningful.
minor comments (1)
- The abstract would be strengthened by briefly stating key quantitative outcomes (e.g., accuracy ranges at N=10 vs. N=100) rather than only qualitative descriptions of weakening.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline targeted revisions to improve clarity and balance the claims.
read point-by-point responses
-
Referee: Abstract and introduction: The central claim that high-N results expose general gaps in model competence (rather than task-specific effects) is load-bearing. The Korean orthography error detection task involves Hangul-specific character confusions, spelling rules, and potential training-data imbalances absent in other languages or tasks; without cross-lingual or cross-task validation experiments, the conclusion that conventional benchmarks obscure true competence is not yet supported.
Authors: We agree that the study is confined to one task in Korean and lacks cross-lingual or cross-task experiments, so the broader claim requires qualification. The manuscript's core contribution is the massive-option protocol itself and the demonstration that it can surface shortcut-driven inflation in this setting. We will revise the abstract and introduction to present the work explicitly as a case study that illustrates the protocol's value, while adding a limitations paragraph that calls for future multi-language and multi-task validation. This change will prevent overstatement while retaining the empirical findings on failure modes such as semantic confusion and position bias. revision: partial
-
Referee: Results and methodology sections: The abstract supplies no quantitative accuracy figures, error bars, or statistical tests for the performance drop from low-N to N=100, nor details on the number of models, resampling iterations, or significance of the observed failure modes. This weakens assessment of whether the weakening is robust or magnitude is meaningful.
Authors: The full paper reports the models tested, repeated resampling (20 iterations per condition), position-bias controls, and qualitative analysis of failure modes. However, the abstract is currently too high-level. We will expand the abstract to include concrete figures (e.g., mean accuracy and standard deviation across resamples for N=4 versus N=100), state the number of models and iterations, and note that the observed drops are statistically significant under paired tests. These additions will make the magnitude and robustness of the results immediately visible to readers. revision: yes
Circularity Check
No significant circularity: empirical protocol with no derivation chain
full rationale
The paper proposes an evaluation protocol for scaling multiple-choice tests to 100 options and reports experimental results on a Korean orthography error detection task. It contains no mathematical derivations, fitted parameters, equations, or self-citations that reduce any claim to its own inputs by construction. All central claims rest on observed performance differences across low-N and high-N conditions, with controls for position bias and context length. This is a standard empirical contribution whose validity can be assessed directly against the reported experiments rather than any internal definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The orthography error detection task serves as a valid proxy for testing model discrimination under high distractor density.
Reference graph
Works this paper leans on
-
[1]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Y ao Fu, and 1 others
work page internal anchor Pith review arXiv 2009
-
[2]
arXiv preprint arXiv:1707.07328 , year=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in Neural Information Processing Systems, 36:62991– 63010. Robin Jia and Percy Liang. 2017. Adversarial examples for evaluating reading comprehension systems.arXiv preprint arXiv:1707.07328. Gregory Kamradt. 2023. Needle in a haystack - pressure testing LLMs. ht...
-
[3]
On the robustness of chatgpt: An adversarial and out-of-distribution perspective.arXiv preprint arXiv:2302.12095. Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, and 1 others. 2024. Large language mod- els are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association ...
-
[4]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. A Spell-Checker Ensemble Labeling Overview and retention.We label items using an ensemble of three Korean spell checkers (DAUM, SARAMIN, NARA) and keep only cases with unani- mous judgments. We further exclude convention- sensitive v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.