Recognition: unknown
Learning to Draw ASCII Improves Spatial Reasoning in Language Models
Pith reviewed 2026-05-10 10:49 UTC · model grok-4.3
The pith
Training language models to construct ASCII layouts from text improves their spatial reasoning on text-only tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training large language models on the task of generating ASCII grid layouts from natural language spatial descriptions, their ability to perform spatial reasoning directly from text descriptions is enhanced. This improvement occurs even when the model does not generate any ASCII output during evaluation. The benefit is larger when construction training is combined with training on comprehension of such layouts, and it transfers successfully to three external spatial reasoning benchmarks.
What carries the argument
The Text2Space dataset consisting of text-to-ASCII layout pairs and QA pairs, used to train models on explicit layout construction to instill spatial representations.
Load-bearing premise
The observed improvements in spatial reasoning come from the models acquiring genuine spatial understanding via layout construction rather than from other factors like increased training data or task memorization.
What would settle it
A controlled experiment training models on the construction task but testing on spatial questions with novel spatial configurations and relations not seen in training data, to check whether performance gains remain.
Figures




read the original abstract
When faced with complex spatial problems, humans naturally sketch layouts to organize their thinking, and the act of drawing further sharpens their understanding. In this work, we ask whether a similar principle holds for Large Language Models (LLMs): can learning to construct explicit visual layouts from spatial descriptions instill genuine spatial understanding? We introduce Text2Space, a dataset that pairs natural language descriptions with ground-truth ASCII grid layouts and spatial QA pairs, enabling us to separate failures in constructing spatial representations from failures in reasoning over them. We adopt ASCII because it is human-readable, operates entirely within the token space of language models, and encodes spatial relations in a structurally verifiable form. Our evaluation reveals a pronounced "Read-Write Asymmetry": LLMs interpret ASCII representations effectively but struggle to produce them from text, and these construction errors propagate to incorrect answers downstream. To address this limitation, we train models on layout construction (Text$\rightarrow$ASCII) and find that it significantly improves spatial reasoning from text alone, even without producing any ASCII at inference time. Combining construction with comprehension training further amplifies these gains. Crucially, these improvements transfer to three external spatial reasoning benchmarks, demonstrating that, much as sketching sharpens human spatial thinking, learning to construct explicit layouts instills spatial understanding that generalizes beyond the training format.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Text2Space dataset pairing natural language spatial descriptions with ground-truth ASCII grid layouts and QA pairs. It identifies a read-write asymmetry in LLMs (strong ASCII interpretation but weak construction from text) and shows that fine-tuning on layout construction (Text→ASCII) improves text-only spatial reasoning even without ASCII output at inference; combining it with comprehension training amplifies gains, which transfer to three external spatial reasoning benchmarks.
Significance. If the results hold after proper controls, the work demonstrates that auxiliary training on explicit, verifiable spatial construction can instill generalizable spatial representations in LLMs without multimodal inputs or inference-time sketching. The ASCII format provides a practical, token-space mechanism for separating representation construction from reasoning, which could guide future auxiliary-task designs for spatial and structured reasoning.
major comments (3)
- [Experimental setup and results] The central claim that Text→ASCII construction training produces transferable spatial understanding (rather than generic benefits from extra supervised fine-tuning) requires explicit controls for total training tokens and a non-spatial baseline of matched volume. No such controls are described, leaving open the possibility that observed lifts on in-distribution and external tasks arise from increased optimization steps or incidental vocabulary overlap.
- [Transfer experiments] The abstract states that improvements transfer to three external spatial reasoning benchmarks, yet provides no details on evaluation protocol (zero-shot vs. few-shot, whether models see benchmark data during training, or overlap analysis between Text2Space and the benchmarks). This information is load-bearing for the generalization claim.
- [Read-Write Asymmetry analysis] The pronounced read-write asymmetry and the claim that construction errors propagate to downstream reasoning are central, but the manuscript does not report quantitative ablations (e.g., error rates on construction vs. reasoning subtasks, or performance when construction training is replaced by an equivalent-volume non-spatial task).
minor comments (2)
- [Abstract] The abstract refers to 'three external spatial reasoning benchmarks' without naming them; naming the benchmarks (and briefly characterizing their spatial demands) would improve readability and allow immediate assessment of transfer scope.
- [Results] Ensure that all quantitative claims in the full text are accompanied by effect sizes, confidence intervals, or statistical tests, as the current abstract description leaves the magnitude of improvements unspecified.
Simulated Author's Rebuttal
We thank the referee for the insightful and constructive comments. We address each major point below and will revise the manuscript to incorporate the requested controls, protocol details, and ablations, thereby strengthening the evidence for our claims.
read point-by-point responses
-
Referee: [Experimental setup and results] The central claim that Text→ASCII construction training produces transferable spatial understanding (rather than generic benefits from extra supervised fine-tuning) requires explicit controls for total training tokens and a non-spatial baseline of matched volume. No such controls are described, leaving open the possibility that observed lifts on in-distribution and external tasks arise from increased optimization steps or incidental vocabulary overlap.
Authors: We agree that explicit controls are necessary to isolate the contribution of spatial construction training. In the revised manuscript we will add experiments that train on an equivalent number of tokens using a non-spatial baseline task (continued next-token prediction on unrelated general text). Direct comparison to these controls will demonstrate that performance gains arise from the spatial layout objective rather than additional optimization steps or vocabulary effects. revision: yes
-
Referee: [Transfer experiments] The abstract states that improvements transfer to three external spatial reasoning benchmarks, yet provides no details on evaluation protocol (zero-shot vs. few-shot, whether models see benchmark data during training, or overlap analysis between Text2Space and the benchmarks). This information is load-bearing for the generalization claim.
Authors: We will add a dedicated subsection detailing the transfer evaluation protocol. All reported results use zero-shot prompting; the models receive no training data from the external benchmarks; and we include an explicit overlap analysis (token-level and structural) between Text2Space and each benchmark. These additions will make the generalization claim fully transparent and reproducible. revision: yes
-
Referee: [Read-Write Asymmetry analysis] The pronounced read-write asymmetry and the claim that construction errors propagate to downstream reasoning are central, but the manuscript does not report quantitative ablations (e.g., error rates on construction vs. reasoning subtasks, or performance when construction training is replaced by an equivalent-volume non-spatial task).
Authors: We acknowledge the value of quantitative ablations. The revised manuscript will include tables that separately report construction error rates and downstream reasoning accuracy. We will also present an ablation replacing construction training with an equivalent-volume non-spatial task, allowing direct quantification of the unique benefit of learning explicit spatial layout construction. revision: yes
Circularity Check
No circularity; empirical results on held-out and external benchmarks are self-contained
full rationale
The paper's central claims rest on dataset construction (Text2Space), supervised fine-tuning for ASCII layout generation, and quantitative evaluation of spatial reasoning gains on both in-distribution held-out sets and three independent external benchmarks. No equations, uniqueness theorems, ansatzes, or first-principles derivations are presented that reduce to the training inputs by construction. The observed improvements are reported as measured outcomes of training, not as predictions forced by fitting or self-citation chains. External benchmark transfer provides independent falsifiability outside the fitted values, satisfying the criteria for a non-circular empirical result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Faithful reasoning using large language models.arXiv preprint arXiv:2208.14271, 2022
Textworld: A learning environment for text- based games. InWorkshop on Computer Games, pages 41–75. Springer. Antonia Creswell and Murray Shanahan. 2022. Faith- ful reasoning using large language models.arXiv preprint arXiv:2208.14271. Junlin Han, Shengbang Tong, David Fan, Yufan Ren, Koustuv Sinha, Philip Torr, and Filippos Kokkinos
-
[2]
arXiv preprint arXiv:2509.26625 , year=
Learning to see before seeing: Demystifying llm visual priors from language pre-training.arXiv preprint arXiv:2509.26625. Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. 2024. Training large language models to reason in a contin- uous latent space.arXiv preprint arXiv:2412.06769. 9 Edward J. Hu, Yelong Shen...
-
[3]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Fangyu Liu, Guy Emerson, and Nigel Collier. 2023. Visual spatial reasoning.Transactions of the Associ- ation for Computational Linguistics, 11:635–651. Li Liu, Diji Yang, Sijia Zhong, Kalyana Suma Sree Tholeti, Lei Ding, Yi Zhang, and Leilani Gilpin. 2024. Rig...
-
[4]
Evidence for a unitary structure of spatial cognition beyond general intelligence.npj Science of Learning, 5(1):9. Sourab Mangrulkar, Sylvain Gugger, Lysandre De- but, Younes Belkada, Sayak Paul, Benjamin Bossan, and Marian Tietz. 2022. PEFT: State-of-the-art parameter-efficient fine-tuning methods. https: //github.com/huggingface/peft. Roshanak Mirzaee, ...
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Sparc and sparp: Spatial reasoning characteri- zation and path generation for understanding spatial reasoning capability of large language models. In Proceedings of the 62nd Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 4750–4767. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Jun- Mei Song, Mingchuan Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2501.07301 , year=
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Hongjie Zhang, Hourui Deng, Jie Ou, and Chaosheng Feng. 2025a. Mitigating spatial hallucination in large language models for path planning via prompt engi- neering.Scientific Reports, 15(1):8881. Zhenru Zhang, Chujie Z...
-
[7]
Select Parameters 7: Identify imbalanced categories usingT racker 8:P←select parameters (e.g., node count) to balance
-
[8]
Build Connected Structure 9:V← {A, B, C, . . .} 10:G←(V, E=∅) 11:C← {Random(V)} 12:whileV\C̸=∅do 13:u←Random(V\C) 14:v←Random(C) 15:dir←Random(8 Compass Directions) 16:ifedge(u, v, dir)is validthen 17:E←E∪ {(u, v, dir)} 18:C←C∪ {u} 19:end if 20:end while 21: Add extra relations toEto reach target complexity
-
[9]
Generate Description 22:S←Random({Spatial, Cardinal, Clock}) 23:Desc←GRAPHTONATURALLANGUAGE(G, S)
-
[10]
Inferred
Create Query 24:P inf er ←Identify uniquely inferable pairs inG 25:(Q, A)←Sample pair and Type fromP inf er 26: Determine if relationship is Direct vs. Inferred
-
[11]
Render Visualizations 27:V is←RENDERASCII(G,{Simple, Grid, Panel})
-
[12]
verify_ascii
Apply Rejection Sampling 28:I← {G, Desc, Q, A, V is, S} 29:∆←CALCBALANCEDEVIATION(I, T racker) 30:ifIworsens balancethen 31:Rejectwith probabilityP∝∆ 2 32:else 33:D ← D ∪ {I} 34: UpdateT rackerwith instanceI 35:end if 36:end while 37:returnD G Evaluation Algorithm for ASCII and Descriptions Pseudo-code for evaluating generated descriptions and ASCII layou...
-
[13]
A is left of B
Parse Description 5:Segs←Split(D,{., ,}) 6:Claims← ∅, Bad← ∅ 7:fors∈Segsdo 8: Matchswith patterns (e.g., "A is left of B") 9:ifmatch foundthen 10:(u, v, dir)←Extract(s) 11:Claims.add((u, v, dir)) 12:else 13:Bad.add(s) 14:end if 15:end for 16:Objs T ←UniqueObjects(Claims)
-
[14]
Build Grid Graph 17:P os←ScanCoordinates(G) 18: NormalizeP os(top-left at 0,0) 19:T ruth← ∅ 20:for(u, v)∈P osdo 21: ⃗d←P os[u]−P os[v] 22:T ruth[u, v]←VectorToDir( ⃗d) 23:end for
-
[15]
Validate Relations 24:Corr← ∅, Err← ∅ 25:for(u, v, dir)∈Claimsdo 26:ifu /∈P osorv /∈P osthen 27:Err.add((u, v,"Missing")) 28:else 29:ifdir==T ruth[u, v]then 30:Corr.add((u, v, dir)) 31:else 32:Err.add((u, v, T ruth[u, v])) 33:end if 34:end if 35:end for
-
[16]
verify_desc
Final Scoring 36:ifM ode=="verify_desc"then▷ASCII is Truth 37:P ass←(Err=∅) 38:else▷Text is Truth 39:Extra←P os.keys\Objs T 40:P ass←(Err=∅ ∧Bad=∅ ∧Extra=∅) 41:end if 42:Acc← |Corr|/|Claims| 43:return{P ass, Acc, Corr, Err, Bad} 16 H Evaluation Algorithm for Consistency Pseudo-code for evaluating the consistency be- tween generated ASCII layouts and query...
-
[17]
Vertical
Parse the Query 5: MatchQvs. patterns: "Vertical", "Horizontal", or "Full" 6: Extract target objectsXandYfromQ 7:ifno valid pattern foundthen 8:returnERROR("Query parsing failed") 9:end if
-
[18]
Queried object missing in grid
Parse the ASCII Grid 10: ScanGto find coordinates for all characters 11:P os← {(obj, x, y)|objfound inG} 12:ifX /∈P osorY /∈P osthen 13:returnERROR("Queried object missing in grid") 14:end if 15: NormalizeP osso top-left object is at(0,0)
-
[19]
Vertical
Infer Relation from Grid 16:(x 1, y1)←P os[X],(x 2, y2)←P os[Y] 17:Rel inf ← ∅ 18:ifType is "Vertical"then 19:ify 1 < y 2 thenRel inf ←"above" 20:else ify 1 > y 2 thenRel inf ←"below" 21:elseRel inf ←"same level" 22:end if 23:else ifType is "Horizontal"then 24:ifx 1 < x 2 thenRel inf ←"left" 25:else ifx 1 > x 2 thenRel inf ←"right" 26:elseRel inf ←"same c...
-
[20]
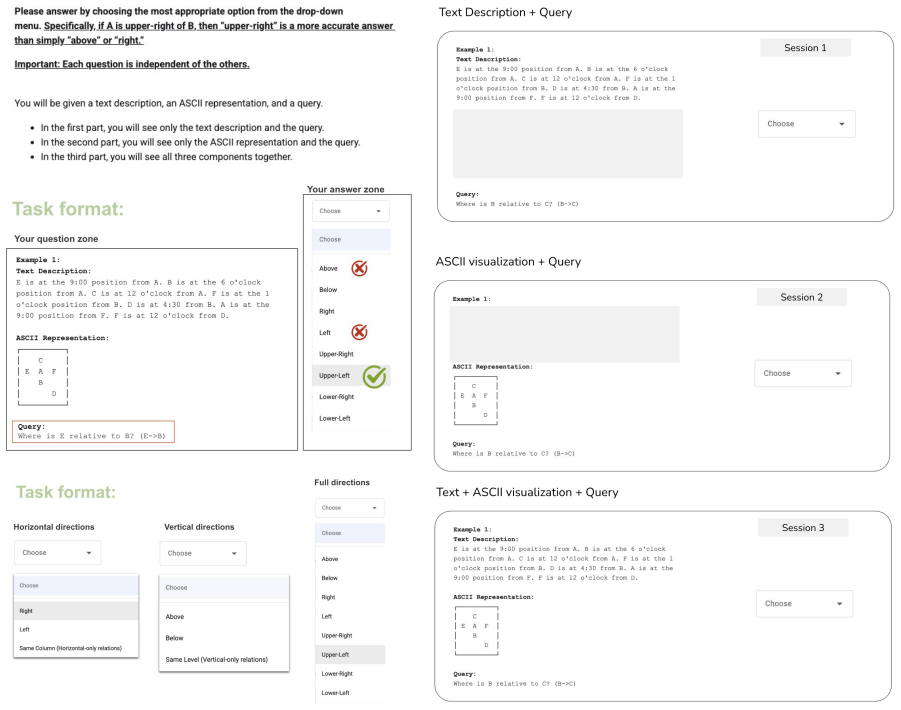
We curated three distinct problem sets (Set X, Set Y , and Set Z), each containing 10 spatially complex examples
Compare with Reference Label 32:M atch←(LowerCase(Rel inf) ==LowerCase(L)) 33:R← {Pass:M atch,Exp:L,Act:Rel inf } 34:returnR 17 I Human Validation Human Validation Setup.To quantify the im- pact of different input formats on spatial reasoning accuracy, we conducted a controlled human vali- dation study with 11 evaluators divided into two groups: Team A (n...
-
[21]
Per- formance was highly consistent across groups (Team A: 0.986, Team B: 0.950), confirming that both teams possessed comparable visual reasoning baselines
Session 2 (Visual Baseline):Both teams eval- uated Set Z using theASCII-onlyformat. Per- formance was highly consistent across groups (Team A: 0.986, Team B: 0.950), confirming that both teams possessed comparable visual reasoning baselines
-
[22]
AF ") . Relations are first -> second ( e . g . ,
Sessions 1 & 3 (Crossover):We swapped the assignment of problem sets and formats between teams. Team A solved Set X using Description-only(Session 1) and Set Y using Description+ASCII(Session 3). Conversely, Team B solved Set Y usingDescription- only(Session 1) and Set X usingDescrip- tion+ASCII(Session 3). This cross-over design ensures that Sets X and Y...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.